
软考高级系统架构师考试 32 小时通关指南
考试概述
系统架构设计师考试是全国计算机技术与软件专业技术资格(水平)考试(简称“软考”)中的高级资格考试,通过系统架构设计师考试可获得高级工程师职称资格。
本书基于2022年颁布的新考试大纲编写,在保证了知识的系统性与完整性的基础上,在易学性、学习有效性等方面进行了大幅度地改进和提高。
本书在全面分析知识点的基础上,对整个学习架构进行了科学重构,可以极大地提高学习的有效性。尤其是针对层次式架构设计、云原生架构设计、面向服务架构设计、嵌入式系统架构设计、通信系统架构设计、安全架构设计、大数据架构设计等核心考点,分别从理论与实践两个方面进行了重点梳理。考生可通过学习本书,掌握考试的重点,熟悉试题形式及解答问题的方法和技巧等。
本书可作为考生备考系统架构设计师考试的学习教材,也可作为各类培训班的教学用书。
核心特点
- 科学重构学习架构:基于2022年新考试大纲,对整个学习架构进行科学重构
- 32小时通关体系:精心设计的32小时学习路径,高效备考
- 6篇系统化知识架构:从基础到实践,层层递进的知识体系
- 理论与实践并重:针对核心考点,分别从理论与实践两个方面进行重点梳理
- 重点突出:聚焦层次式架构、云原生架构、SOA、嵌入式系统等核心考点
适用对象
- 准备参加系统架构设计师考试的考生
- 希望获得高级工程师职称资格的技术人员
- 各类培训班的学员和教师
- 从事系统架构设计工作的专业人员
- 希望提升架构设计能力的软件工程师
学习指南
本指南按照6篇32小时的结构组织,建议按以下方式学习:
- 第1篇(第1-3小时):架构设计基础 - 夯实计算机系统基础
- 第2篇(第4-8小时):架构设计专业知识 - 掌握专业理论基础
- 第3篇(第9-14小时):架构设计高级知识 - 深入架构设计理论
- 第4篇(第15-22小时):架构设计实践知识 - 重点掌握实践应用
- 第5篇(第23-26小时):架构设计补充知识 - 完善知识体系
- 第6篇(第27-32小时):架构设计模拟试题 - 实战演练提升
考试内容
重点章节: 【高】 软件架构设计 、软件工程 【中】 数据库系统、企业信息化战略与实施、操作系统 、计算机网络
| 知识点 | 分数 | 说明 | 比例 |
|---|---|---|---|
| 计算机组成原理与体系结构 | 2-4 | 中断、存储器、并/串转换、寄存器、内存存储计算、磁盘文件读取、异步传输、CISC与RISC、Cache存储、流水线、虚拟、查重位 | 2.7%~5.3% |
| 系统性能与性能评价 | 0-2 | 性能指标测试、计算机性能/性能评价、负载均衡、数据流、MIPS | 0~2.7% |
| 操作系统 | 3-6 | 进程、虚拟器与SP/调度、存储分配、文件系统、设备管理、磁盘调度、实时文件系统 | 4%~8% |
| 计算机网络 | 3-6 | 网络层次设计、逻辑/物理拓扑设计、协议、数据链路层、传输层、DNS服务 | 4%~8% |
| 数据库系统 | 4-9 | 数据库设计、ER模型、关系代数、规范化理论、数据库索引机制、事务管理、SQL语句 | 5.3%~12% |
| 企业信息化战略与实施 | 3-8 | 企业信息战略、企业应用集成、EDI、企业门户、CRM、企业信息化方法、信息管理 | 4%~10.7% |
| 软件工程 | 12-18 | 软件开发模型、需求方法论、逆向工程、用例分析方法、UML图、需求识别、需求捕捉、可行性研究、软件测试、验证、确认、维护、RUP、JSP、结构化方法、RAD、面向对象方法论 | 16%~24% |
| 项目管理 | 0-4 | 项目计划与组织、项目资源管理、需求变更 | 0~5.3% |
| 软件架构设计 | 22-28 | 软件架构风格与模式、架构设计技术、MVC模式、架构设计评价、形式化方法、ASD、架构文档、面向服务架构、组件技术、CORBA、“4+1"视图模型、体系结构风格 | 29.3%~37.3% |
| 系统安全与保密性设计 | 2-3 | 安全保密设计与实现、加密算法、ARP、SNMP v3、PGP、PKI | 2.7%~4% |
| 系统可靠性与容错性设计 | 3-4 | 系统可靠性指标、容错/冗余、失效模式、诊断理论、商容、系统可靠性分析 | 4.00% |
| 数学与经济基础 | 2 | 数学基础、概率、统计分析、线性规划、线性规划、函数规划、图模型 | 2.7% |
| 专业英语 | 4-5 | 软件架构风格、软件架构、信息系统设计、DFD | 6.67% |
第1篇 架构设计基础
第1小时 计算机系统基础知识
1.0 章节考点分析
第1小时主要学习计算机硬件基础知识、计算机软件基础知识、计算机语言、多媒体技术等内容。根据考试大纲,本小时知识点涉及单项选择题,按以往全国计算机技术与软件专业技术资格(水平)考试的出题规律约占 $2\sim 6$ 分。本小时内容属于基础知识范畴,一般不会在案例分析题中出现。本小时知识架构如图1.1所示。
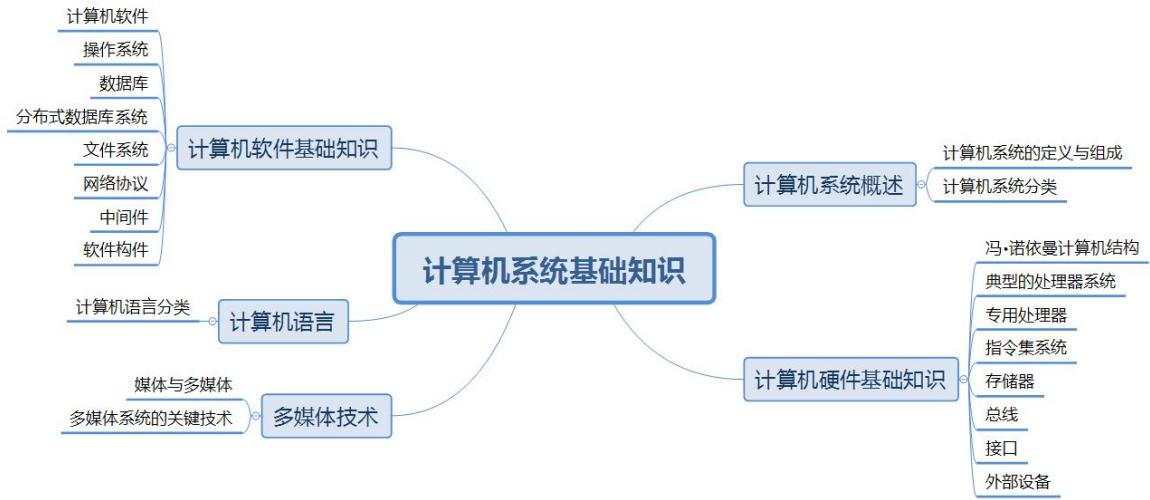
图1.1 本小时知识架构
【导读小贴士】
想成为一名合格的高级架构师,需要在计算机领域中“上知天文,下知地理”,所谓“万丈高楼平地起”,本小时所要讲述的计算机系统基础知识,属于需要掌握的庞杂的知识域中的一小部分,都是入门的基础知识,教材上言简意赅,这里我们会对教材进行补充,加以整理,力求让不同阶段的读者都能有所收益。
1.1 计算机系统概述
【基础知识点】
- 计算机系统的定义与组成
计算机系统(Computer System) 是指用于数据管理的计算机硬件、软件及网络组成的系统。计算机系统可划分为硬件(子系统) 和软件(子系统) 两部分。硬件由机械、电子元器件、磁介质和光介质等物理实体构成;软件是一系列按照特定顺序组织的数据和指令,并控制硬件完成指定的功能。
- 计算机系统分类
计算机系统的分类维度很多,也较为复杂,可以从硬件的结构、性能、规模上划分,亦可从软件的构成、特征上划分,或者从系统的整体用途、服务对象等进行分类。
1.2 计算机硬件基础知识
【基础知识点】
- 冯·诺依曼计算机结构
冯·诺依曼计算机结构将计算机硬件划分为运算器、控制器、存储器、输入设备、输出设备5个部分。但在现实的硬件中,控制单元和运算单元被集成为一体,封装为通常意义上的中央处理器(Central Processing Unit,CPU)。
CPU的工作频率(主频) 包括两个部分:外频与倍频,两者的乘积就是主频。所谓外频,就是外部频率,指的是系统总线频率。倍频的全称是倍频系数,倍频系数是指CPU主频与外频之间的相对比例关系。最初CPU主频和系统总线速度是样的,但CPU的速度越来越快,倍频系数也就相应产生。它的作用是使系统总线工作在相对较低的频率上,而CPU速度可以通过倍频来提升。
- 典型的处理器系统
典型的处理器系统结构如图1.2所示
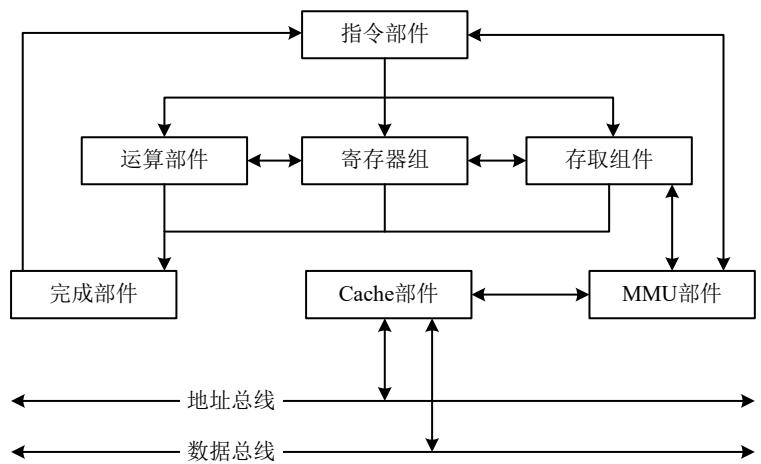
图1.2 典型的处理器体系结构示意图
- 专用处理器
除了通用的处理器,用于专用目的的专用处理器芯片不断涌现,常见的有图形处理器(Graphics Processing Unit,GPU)、信号处理器(Digital Signal Processor,DSP)以及现场可编程逻辑门阵列(Field Programmable Gate Array,FPGA)等。GPU常有数百个或数千个内核,经过优化可并行运行大量计算;DSP专用于实时的数字信号处理,常采用哈佛体系结构。
- 指令集系统
典型的处理器根据指令集的复杂程度可分为复杂指令集(Complex Instruction Set Computers,CISC)与精简指令集(Reduced Instruction Set Computers,RISC)两类。CISC以 Intel、AMD 的 x86 CPU为代表,RISC以 ARM 和 Power为代表。国产处理器目前有龙芯、飞腾、申威等品牌,常采用 RISC-V、MIPS、ARM等精简指令集架构。
| 项目 | CISC(复杂指令集计算机) | RISC(精简指令集计算机) |
|---|---|---|
| 指令 | 数量多,使用频率差别大,可变长格式 | 数量少,使用频率接近,定长格式,大部分为单周期指令,操作寄存器,只有Load/Store操作内存 |
| 寻址方式 | 支持多种寻址方式 | 支持方式少 |
| 实现方式 | 微程序控制技术(微码) | 增加通用寄存器;硬布线逻辑控制为主;适合采用流水线 |
| 其他特点 | 研制周期长 | 优化编译,有效支持高级语言 |
- 存储器
存储器是利用半导体、磁、光等介质制成用于存储数据的电子设备。根据存储器的硬件结构可分为 SRAM、DRAM、NVRAM、Flash、EPROM、Disk等。按照与处理器的物理距离可分为 4 个层次:片上缓存、片外缓存、主存(内存)、外存。其访问速度依次降低,而容量依次提高。
| 层次 | 示例 | 特点 |
|---|---|---|
| 片上缓存 | L1/L2/L3 Cache(CPU 内部) | 容量小,速度快,直接集成在 CPU 芯片上 |
| 片外缓存 | CPU 外部缓存(如独立的缓存芯片) | 容量稍大,速度稍慢 |
| 主存(内存) | DRAM(内存条) | 容量大,速度中等,CPU 直接访问 |
| 外存 | 硬盘(HDD)、固态硬盘(SSD)、光盘、磁带 | 容量最大,速度最慢,主要用于长期存储数据 |
嵌入式系统的存储结构 采用分级的方法来设计,从而使得整个存储系统分为四级,即寄存器组、高速缓冲 (Cache)、内存(包括 flash)和外存,它们在存取速度上依次递减,而在存储容量上逐级递增,寄存器速度快。 cache是一个高速小容量的临时存储器,可以用高速的静态存储器芯片实现,或者集成到CPU芯片内部存储CPU最经常访问的指令或者操作数据。 而寄存器不同,寄存器是内存阶层中的最顶端,也是系统获得操作资料的最快速途径寄存器存放的是当前CPU环境以及任务环境的数据,而cache则存放最近经常访问的指令和数据。
磁盘读取顺序: 1)同柱面内,先进行扇区调度,再进行磁头调度。 2)扇区不包含磁头,它们是磁盘定位的两个独立参数。 3)类似快递分拣:先选楼层(柱面),再按房间号(扇区)排序,最后找房间内的具体位置(磁头)。
存储管理方式
| 管理方式 | 核心思想 / 特点 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 分区式管理 | 将内存划分为若干固定大小或可变大小的分区,作业装入一个分区 | 实现简单 | 内存利用率低,容易产生碎片 | 早期操作系统 |
| 页式管理 | 把程序和内存都划分为等长的页和页框,通过页表映射 | 无外部碎片,内存利用率高 | 需要页表,存在页表开销;可能有内部碎片 | 现代操作系统(虚拟内存基础) |
| 段式管理 | 按程序的逻辑模块(段) 划分,每段有段名,段长可变 | 模块化好,保护和共享方便 | 会产生外部碎片 | 需要逻辑模块支持的系统 |
| 段页式管理 | 先分段再分页:段式便于模块化,页式便于消除碎片 | 兼顾两者优点,支持大程序 | 需要段表+页表,管理更复杂,开销大 | 现代复杂系统(如多道程序设计、虚拟存储系统) |
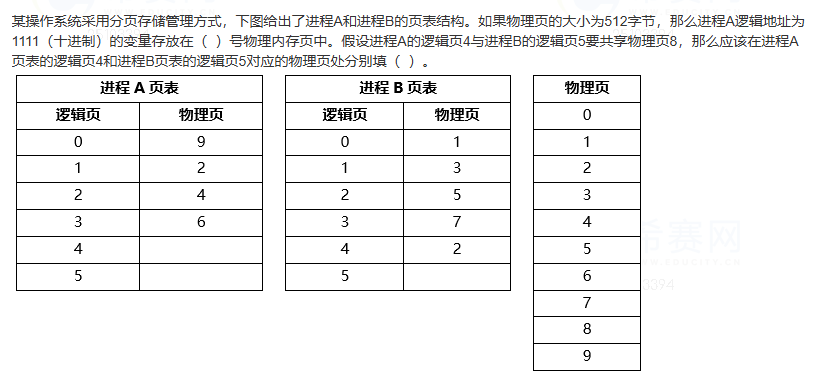
页式存储转换计算 逻辑地址=逻辑页号+页内地址,物理地址=物理块号+页内地址。它们的页内地址是相同的,变化的时候只需要将逻辑页号变换为物理块号就可以了。已知页面大小为4K,也就是212,所以页内地址有12位。
已知逻辑地址为:0010 0000 0000 0100 所以高4位为页号2,低12位为页内偏移量4,所以逻辑地址对应的逻辑页号为2(0010),由图可知对应的物理块号为110(6)。最后把物理块号和页内偏移地址拼合得:0110000000000100(6+4)。 (2,4)-> [2->6] -> (6,4)
十进制数1111转化为二进制数为:10001010111。物理页的大小为512字节,这说明页内地址为9个二进制位,进程A的逻辑地址中,右边的9位是页内地址,左边的2位是页号,即:10001010111。页号为二进制的10,即十进制的2,对应的物理页号为4。
直接存储器访问(Direct Memory Access,DMA)是指数据在主存与I/0设备间的直接成块传送,即在主存与I/O设备间传送数据块的过程中,不需要CPU作任何干涉,只需在过程开始启动(即向设备发出“传送一块数据”的命令)与过程结束CPU通过轮询或中断得知过程是否结束和下次操作是否准备就绪)时由CPU进行处理,实际操作由DMA硬件直接完成,CPU在传送过程中可做其他事情
虚拟存储器 (Virtual Memory):在具有层次结构存储器的计算机系统中,自动实现部分装入和部分替换功能,能从逻辑上为用户提供一个比物理贮存容量大得多、可寻址的“主存储器”。虚拟存储区的容量与物理主存大小无关,而受限于计算机的地址结构和可用磁盘容量。其页面的置换依据相应的页面置换算法进行,当页面失效时,需要进行数据交换,此时涉及逻辑地址(虚地址)到辅存物理地址的变换,所以本题应选D。
从内存中读指令操作码,总共要经历哪些步骤: 1)程序计数器(PC)将下一条指令的地址送至地址总线。 2)地址被送到内存,通过地址译码选中对应存储单元。 3)内存将该地址中的指令操作码读出,经数据总线送入CPU。 4)操作码进入指令寄存器(IR) 5)控制单元对操作码进行译码并执行相应操作。
- 总线
总线(Bus)是指计算机部件间遵循某一特定协议实现数据交换的形式,即以一种特定格式按照规定的控制逻辑实现部件间的数据传输。按照总线在计算机中所处的位置划分为内总线、系统总线和外部总线。目前,计算机总线存在许多种类,常见的有并行总线(PCI、IDE、SCSI)和串行总线(USB)。两者的区别见表 1.1。
总线是一个大家都能使用的数据传输通道,大家都可以使用这个通道,但发送数据时,是采用的分时机制,而接收数据时可以同时接收,也就是说,同一个数据,可以并行的被多个客户收取。如果该数据不是传给自己的,数据包将被丢弃。
表1.1并行总线与串行总线的区别
| 名称 | 数据线 | 特点 | 应用 |
|---|---|---|---|
| 并行总线 | 多条双向数据线 | - 有传输延迟,适合近距离连接 | 系统总线(计算机各部件) |
| 串行总线 | 一条双向数据线或两条单向数据线 | - 速率不高,但适合长距离连接 - 串行总线有半双工、全双工之分,全双工是一条线发一条线收。 - 串行总线传输的波特率在使用中可以改变 - 串行总线的数据发送和接收可以使用多种方式,程序査询方式和中断方式都可以 - 串行总线是按位(bit)传输数据的,其数据的正确性依赖于校验码纠正 | 通信总线(计算机之间或计算机与其他系统间) |
“半双工”与“全双工”对比
| 特性 | 半双工 | 全双工 |
|---|---|---|
| 数据传输方向 | 双向,但不能同时进行 | 双向,且可以同时进行 |
| 工作方式比喻 | 像对讲机,一方说完后,另一方才能说 | 像电话,双方可以同时讲话和收听 |
| 关键特点 | 在某一时刻,只能进行发送或接收中的一种操作 | 在某一时刻,可以同时进行发送和接收操作 |
| 线路要求 | 一条双向通道(但分时使用) | 需要两条独立的通道(或通过技术手段实现信道分离) |
| 性能 | 效率较低,存在传输延迟(需切换方向) | 效率高,无方向切换延迟 |
| 常见实例 | 传统对讲机、集线器(Hub)连接的局域网 | 电话网络、交换机(Switch)连接的现代局域网 |
- 接口
接口是指同一计算机不同功能层之间的通信规则。计算机接口有多种,常见的有输入输出接口如 HDMI、SATA、RS-232等;网络接口如 RJ45、FC等;以及 A/D 转换接口等非标准接口。
- 外部设备
外部设备也称为外围设备,是计算机结构中的非必要设备,但从功能上又常常不可缺少,例如键盘、鼠标、显示器等。虽然种类多样,但都是通过接口实现与计算机主体的连接,并通过指令、数据实现预期的功能。
1.3 计算机软件基础知识
【基础知识点】
- 计算机软件
计算机软件是指计算机系统中的程序及其文档,是计算任务的处理对象和处理规则的描述。软件系统是指在计算机硬件系统上运行的程序、相关的文档资料和数据的集合。计算机软件可用来扩充计算机系统的功能,提高计算机系统的效率。按照软件所起的作用和需要的运行环境不同,通常将计算机软件分为系统软件和应用软件两大类。
(1)系统软件。为整个计算机系统配置的不依赖特定应用领域的通用软件,对计算机系统的硬件和软件资源进行控制和管理,并提供运行服务支持。 (2)应用软件。是指为某类应用需要或解决某个特定问题而设计的软件,常与具体领域相关联,如教学软件。
- 操作系统
操作系统是计算机系统的资源管理者,包含对系统软、硬件资源实施管理的一组程序。操作系统通常由操作系统的内核(Kernel)和其他许多附加的配套软件所组成,如用户界面、管理工具、开发工具和常用应用程序等。操作系统的重要作用如下:
(1)管理计算机中运行的程序和分配各种软、硬件资源。 (2)为用户提供友善的人机界面。 (3)为应用程序的开发和运行提供一个高效率的平台。
操作系统具有并发性、共享性、虚拟性和不确定性的特征。
操作系统是管理计算机硬件与软件资源的程序,同时也是硬件与用户之间的接口。操作系统既提供了与用户交互的接口,也提供了与应用程序交互的接口。 1)用户可以通过菜单、命令、窗口与操作系统进行交互, 2)而应用程序可以通过系统调用(如调用系统API)来与操作系统交互。
1)CPU访问内存通常是同步方式,I/O接口 与CPU交换信息 通常是同步方式,CPU与PCI总线交换信息通常是同步方式, 2)I/0接口与打印机交换信息则通常采用基于缓存池的异步方式,因此答案为D。
操作系统的分类:
(1)批处理操作系统,根据同时执行的作业数又分为单道批处理和多道批处理。一个作业由用户程序、数据和作业说明书(作业控制语言) 3个部分组成。 (2)分时操作系统,将 CPU 的工作时间划分为许多很短的时间片,每个时间片分别为一个终端的用户提供服务或者执行一个作业。分时系统主要有 4 个特点:多路性、独立性、交互性和及时性。 (3)实时操作系统,对于外来信息能够以足够快的速度进行处理,并在被控对象允许的时间范围内快速做出反应,对可靠性要求很高,并且不强制要求用户交互。实时系统的应用非常广泛。 (4)网络操作系统,使联网计算机能有效地共享网络资源,为网络用户提供各种服务和接口。特征包括硬件独立性和多用户支持等。 (5)分布式操作系统,指为分布式计算机系统配置的操作系统。分布式操作系统是网络操作系统的更高级形式,它保持网络系统所拥有的全部功能,同时又有透明性、可靠性和高性能等特性。 (6)嵌入式操作系统,运行在嵌入式智能设备环境中,对整个智能硬件以及它所操作、控制的各种部件装置等资源进行统一协调、处理、指挥和控制,特点是微型化、可定制、可靠性和易移植性。常采用硬件抽象层(Hardware Abstraction Layer,HAL)和板级支撑包(Board Support Package,BSP)来提高易移植性,常见的嵌入式实时操作系统有VxWorks、 $\mu$ Clinux、PalmOS、WindowsCE、 $\mu$ C/OS-II和eCos等。
| 类别 | 特点/说明 | 补充要点 / 示例 | 对比说明 |
|---|---|---|---|
| 批处理操作系统 | - 按作业批量处理 - 分为 单道批处理 和 多道批处理 | 作业由 用户程序 + 数据 + 作业说明书(JCL) 组成 | 无交互性,效率高但灵活性差,与分时/实时系统形成对比 |
| 分时操作系统 | - CPU 时间片轮转 - 特点:多路性、独立性、交互性、及时性 | 用户体验像独占一台计算机 、Unix | 多用户;强调 交互性,与批处理/实时系统相比,用户参与度最高 |
| 实时操作系统 | - 快速响应外部事件 - 高可靠性,不强调用户交互 | 应用广泛:航空航天、工业控制 | 专用系统;强调 时间确定性、可靠性,与分时系统不同,不是为了公平共享CPU,而是保证时限 |
| 网络操作系统 | - 共享网络资源 - 硬件独立、多用户支持 | 提供各种网络服务和接口 | 面向 资源共享,比分时/实时更关注 通信,但没有全局统一调度 |
| 分布式操作系统 | - 网络操作系统的高级形式 - 特点:透明性、可靠性、高性能 | 协调多台计算机为统一系统 | 与网络操作系统相比,强调 整体统一性 和 透明性 |
| 嵌入式操作系统 | - 运行于嵌入式设备 - 特点:微型化、可定制、可靠、易移植 | 常用技术:HAL、BSP 常见OS:VxWorks、μClinux、PalmOS、WindowsCE、μC/OS-II、eCos | 与通用操作系统相比,功能精简,针对性强,但缺乏通用性 |
进程与线程 在同一进程中的各个线程都可以共享该进程所拥有的资源,如访问进程地址空间中的每一个虚地址;全局变量;访问进程所拥有的已打开文件、定时器、信号量等; 但是不能共享进程中某线程的栈指针、程序计数器、寄存器、状态字
线程共享的内容包括:进程代码段、进程的公有数据(利用这些共享的数据,线程很容易的实现相互之间的通讯)、进程打开的文件描述符、信号的处理器、进程的当前目录、进程用户ID与进程组ID。 线程独有的内容包括:线程ID、寄存器组的值、线程的堆栈、错误返回码、线程的信号屏蔽码。
进程控制块PCB的组织方式有:1)线性表方式,2)索引表方式,3)链接表方式。 1)线性表方式:不论进程的状态如何,将所有的PCB连续地存放在内存的系统区。这种方式适用于系统中进程数目不多的情况。 2)索引表方式:该方式是线性表方式的改进,系统按照进程的状态分别建立就绪索引表、阻塞索引表等。题中就是采用了索引表方式,由图中的索引表可以看出。 3)链接表方式:系统按照进程的状态将进程的PCB组成队列,从而形成就绪队列、阻塞队列、运行队列等。
任务一旦被加载到计算机内存后,通常会处于不同的工作状态,这种状态可随着计算机运行而转变。在嵌入式操作系统中,任务的工作状态最简单的可分为三种:执行态、就绪态和阻塞态。 1)执行态:当任务已获得处理机,其程序正在处理执行态机上执行,此时的任务状态称为执行状态。 2)就绪态:当任务已分配到除CPU以外的所有必要的资源,只要获得处理机便可立即执行,这时的任务状态称为就绪状态。 3)阻塞态:正在执行的任务,由于等待某个事件发生而无法执行时,便放弃处理机而处于阻塞状态。引起进程阻塞的事件可有多种,例如,等待I/0完成、申请缓冲区不能满足、等待信件(信号)等。二种基本状态转换: 就绪一执行:处于就绪状态的任务,当任务调度程序为之分配了处理机后,该任务便由就绪状态转变成执行状态。 执行一就绪:处于执行状态的任务在其执行过程中,因分配给它的一个时间片已用完而不得不让出处理机,于是任务从执行状态转变成就绪状态, 执行一阻塞:正在执行的任务因等待某种事件发生而无法继续执行时,便从执行状态变成阻塞状态 阻塞一就绪:处于阻塞状态的任务,若其等待的事件已经发生,于是任务由阻塞状态转变为就绪状态。
进程调度算法 1)高响应比优先:基本思想是把CPU分配给就绪队列中响应比最高的进程。高响应比优先调度算法既考虑作业的执行时间也考虑作业的等待时间,综合了先来先服务和最短作业优先两种算法的特点。 2)时间片轮转:是一种常见的进程调度算法,其目的是确保所有进程都能公平地获得CPU时间片。每个进程被分配-个固定大小的时间片,当一个进程用尽其时间片后,调度器将其移到队列的末尾,然后选择下一个进程执行。 3)先来先服务:按照进程到达的先后顺序进行调度,不考虑执行时间的长短。 4)短作业优先:选择执行时间最短的进程来先执行。这可能导致长作业等待时间过长,也无法保证所有进程都能公平地获得CPU时间。
死锁产生的4个必要条件: 1)互斥:某种资源一次只允许一个进程访问,即该资源一旦分配给某个进程,其他进程就不能再访问,直到该进程访问结束。 2)请求和保持:一个进程本身占有资源(一种或多种),同时还有资源未得到满足,正在等待其他进程释放该资源, 3)不剥夺:别人已经占有了某项资源,你不能因为自己也需要该资源,就去把别人的资源抢过来。 4)环路:存在一个进程链,使得每个进程都占有下一个进程所需的至少一种资源。 产生死锁需要四个条件,那么,只要这四个条件中至少有一个条件得不到满足,就不可能发生死锁了。由于互斥条件是非共享资源所必须的,不仅不能改变,还应加以保证,所以,主要是破坏产生死锁的其他三个条件。
中断 A.溢出中断:这通常是由于指令执行过程中的条件满足(如算术溢出等)而引发的中断。它与用户程序在用户态下使用特权指令引起的中断不同,因此可以排除。 B.外部中断:这是由外部事件引发的中断,如硬件设备的输入输出、定时器到达等。用户程序在用户态下使用特权指令引起的中断不属于外部事件引发的情况,因此也可以排除。 C.访管中断:这是一种特殊的中断,用于在用户态下请求操作系统内核提供服务或执行特权操作。当用户程序需要执行特权指令时,它会通过发起访管中断来请求操作系统执行这些操作。 D.信号中断:信号通常用于进程间的通信或通知进程某些事件的发生,而不是由于用户程序在用户态下使用特权指令引起的中断。
数据传输控制方式 在计算机中,常用的输入输出控制方式主要有4种,分别是程序查询方式(程序控制方式)、程序中断方式、DMA工作方式、通道方式。这4种方式占用主机CPU时间按多到少排序为:程序查询方式(程序控制方式)、程序中断方式、DMA工作方式、通道方式。
- 数据库
数据库(DataBase,DB)是指长期存储在计算机内、有组织的、统一管理的相关数据的集合。数据是按一定格式存放的,具有较小的冗余度、较高的数据独立性和易扩展性,可为多个用户共享。数据库可以分为:关系型数据库、键值(Key- Value)数据库、列存储数据库、文档数据库等。这里只做简单介绍,详细内容见第8小时。
- 分布式数据库系统
分布式数据库系统(Distributed DataBase System,DDBS)是针对地理上分散,而管理上又需要不同程度集中的需求而提出的一种数据管理信息系统。满足分布性、逻辑相关性、场地透明性和场地自治性的数据库系统被称为完全分布式数据库系统。分布式数据库系统的特点是数据的集中控制性、数据独立性、数据冗余可控性、场地自治性和存取的有效性。
- 文件系统
文件(File)是具有符号名的、在逻辑上具有完整意义的一组相关信息项的集合。文件系统是操作系统中实现文件统一管理的一组软件和相关数据的集合,是专门负责管理和存取文件信息的软件机构。
文件的类型如下: (1)按性质和用途分类可将文件分为系统文件、库文件和用户文件。 (2)按信息保存期限分类可将文件分为临时文件、档案文件和永久文件。 (3)按保护方式分类可将文件分为只读文件、读/写文件、可执行文件和不保护文件。 (4)UNIX系统将文件分为普通文件、目录文件和设备文件(特殊文件)。
文件的存取方法:通常有顺序存取和随机存取两种方法。
文件组织方法:有连续结构、链接结构和索引结构,还有多重索引方式。
文件存储空间的管理知道存储空间的使用情况,空间管理的数据结构通常称为磁盘分配表(Disk Allocation Table),有空闲区表、位示图和空闲块链3种。位示图用每一位的0和1表示一个区块空闲或被占用,如图1.3所示。
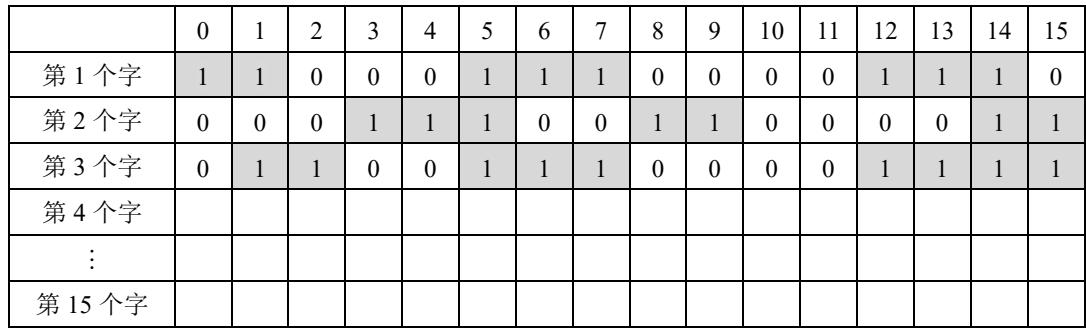
图1.3 位示图例
当文件处于“未打开”状态时,文件需占用三种资源:一个目录项;一个磁盘索引节点项;若干个盘块。当文件被引用或“打开”时,须再增加三种资源:一个内存索引节点项,它驻留在内存中;文件表中的一个登记项;用户文件描述符表中的一个登记项。由于对文件的读写管理,必须涉及上述各种资源,因而对文件的读写管理,又在很大程度上依赖于对这些资源的管理,故可从资源管理观点上来介绍文件系统。这样,对文件的管理就必然包括: ①对索引节点的管理; ②对空闲盘块的管理; ③对目录文件的管理; ④对文件表和描述符表的管理; ⑤对文件的使用。 因此如果目录文件在写回磁盘时发生异常,对系统的影响是很大的。对于空闲块、用户数据和程序并不影响系统的工作,因此不会有较大的影响。
- 网络协议
常用的网络协议包括局域网协议(Local Area Network,LAN)、广域网协议(Wide Area Network,WAN)、无线网协议和移动网协议。互联网使用的是TCP/IP协议簇。本知识点的详细内容将在第3小时中讲解。
- 中间件
中间件(Middleware)是应用软件与各种操作系统之间使用的标准化编程接口和协议,是基础中间件(分布式系统服务)软件的一大类,属于可复用软件的范畴。
常见中间件的分类如下:
(1)通信处理(消息)中间件,保证系统能在不同平台之间通信,例如MQSeries。 (2)事务处理(交易)中间件,实现协调处理顺序、监视和调度、负载均衡等功能,例如Tuxedo。 (3)数据存取管理中间件,为不同种类数据的读写和加解密提供统一的接口。 (4)Web服务器中间件,提供Web程序执行的运行时容器,例如Tomcat、JBOSS等。 (5)安全中间件,用中间件屏蔽操作系统的缺陷,提升安全等级。 (6)跨平台和架构的中间件,用于开发大型应用软件。 (7)专用平台中间件,为解决特定应用领域的开发设计问题提供构件库。 (8)网络中间件,包括网管工具、接入工具等。
- 软件构件
构件又称为组件,是一个自包容、可复用的程序集,这个集合整体向外提供统一的访问接口,构件外部只能通过接口来访问构件,而不能直接操作构件的内部。构件的两个最重要的特性是自包容与可重用,利用软件构件进行搭积木式地开发。优点:易扩展、可重用、并行开发。缺点:需要经验丰富的设计师、快速开发与质量属性之间需要妥协、构件质量影响软件整体的质量。
商用构件的标准规范有:
(1)OMG的公共对象请求代理架构(Common Object Request Broker Architecture,CORBA)是一个纯粹的规范而不是产品,主要分为3个层次:对象请求代理(Object Request Broker,ORB)、公共对象服务和公共设施。采用IDL定义接口,并易于转化为具体语言实现。
1)伺服对象(Servant): CORBA对象的真正实现,负责完成客户端请求。 2)对象适配器(0bject Adapter): 用于屏蔽ORB内核的实现细节,为服务器对象的实现者提供抽象接口,以便他们使用ORB内部的某些功能。 3)对象请求代理(ObjectRequest Broker): 解释调用并负责查找实现该请求的对象,将参数传给找到的对象,并调用方法返回结果。客户方不需要了解服务对象的位置、通信方式、实现、激活或存储机制。
对象管理组织(OMG)基于CORBA基础设施定义了4种构件标准:
1)实体(Entity) 构件需要长期持久化并主要用于事务性行为,由容器管理其持久化。 2)加工(Process)构件同样需要容器管理其持久化,但没有客户端可访问的主键。 3)会话(Session)构件不需要容器管理其持久化,其状态信息必须由构件自己管理。 4)服务(Service)构件是无状态的。
(2)SUN的J2EE,定义了完整的基于Java语言开发面向企业分布的应用规范,其中EJB是J2EE的构件标准,EJB中的构件称为Bean,可以分为会话Bean、实体Bean和消息驱动Bean,支持五种不同类型的构件模型,包括Applet、Servlet、 JSP、 EJB、Application Client。
(3)Microsoft的DNA2000,采用DCOM/COM/COM+ 作为标准的构件。
- 其他
(1)循环冗余校验(Cyclic Redundancy Check,CRC) 是一种根据网络数据包或电脑文件等数据产生简短固定位数校验码的一种散列函数,主要用来检测或校验数据传输或者保存后可能出现的错误。它是利用除法及余数的原理来作错误侦测的。 1)将生成多项式的系数作为除数(101011): 2)生成多项式的最高幂次数(5)作为检验码的位数。2 3)将信息码左移生成多项式的最高幂次数(5)位,作为被除数口 4)执行模2除法,即异或操作。 5)等到(5位)余数即为校验码。
示例 若信息码字为111000110,生成多项式G(x)=x^5^+x^3^+x+1,则计算出的CRC校验码为()。 解答 1)将生成多项式转为二进制,G=101011,长度是6位(因为最高次是5,所以CRC长度=5)。 2)在信息码字后面补5个0,CRC除法的规则是:信息码字后面补r个0(r=G(x)的次数)。信息码𝑀=111000110,补5个0后:11100011000000 3)用生成多项式做二进制模2除法,CRC步骤:用G对补零后的码字做异或除法(不同为1,相同为0),余数就是CRC校验码。11100011000000÷101011,逐位做 XOR,最终余数 = 11001
(2)流水线 1)流水线最大吞吐率计算基于最慢阶段时间3At,公式为1/3Δt,体现执行效率核心在瓶颈阶段。 2)加速比计算为不用流水线时间90Δt与用流水线时间36Δt之比,得5:2,体现流水并行优势。 3)流水线的吞吐率为:指令条数/流水线执行时间。 4)计算流水线执行时间的理论公式是:指令顺序执行时间+(指令条数-1)*周期,而周期是取各节点的最大处理时长。 10条指令不用流水线的执行时间=(2At+1Δt+3Δt+1Δt+2Δt)x10=90Δt。 10条指令使用流水线的执行时间=(2Δt+1At+3Δt+1Δt+2Δt)+(10-1)x3Δt=36Δt。
单缓冲区和双缓冲区都使用的是流水线技术,所以用流水线计算公式算就可以。计算流水线执行时间的理论公式是:第一条指令顺序执行时间+(指令条数-1)*周期,而周期是取各节点的最大处理时长。在本题中,单缓冲区的传送数据和输入数据是绑定在一起的,所以需要把它们结合起来视为流水线周期,构造成流水线后,整个过程划分为2个阶段,分别是16US,2US,根据流水线执行公式,流水线执行时间为:16us+2us+(10-1)“16US=162US。 而对于双缓冲区来说,它们有多余的缓冲区可以进行单独的传送和输入教据。读入缓冲区和电缙冲区送至用户区可以并行处理,对于这里构造成流水线后,整个过程划分为3个阶段,1、从磁盘读入到缓冲区(10us);2、从缓冲区读入到(内存)用户区(6us);3、处理(内存)用户区数据(2us)。根据流水线执行公式,流水线执行时间为:10us+6us+2us+(10-1)*10uS=108uS。
(3)死锁 操作系统和数据库系统中常见的一个问题,它发生在多个进程或线程互相等待对方持有的资源而无法继续执行的情况。在题目中,系统中有n个事务T,每个事务都在等待另一个事务所持有的数据项的锁。具体来说,T0等待T1的数据项A1,T1等待T2的数据项A2,以此类推,直到Tn-1等待T0的数据项A0,形成一个环状等待链。这种情况下,如果没有外力干涉(比如超时中断、死锁检测与解除机制等),每个事务都将永远等待下去,因为没有事务能够完成并释放其他事务所需的锁。因此,根据死锁的定义,系统处于死锁状态
(4)信号量和PV操作
| 操作 | 含义 | 作用 |
|---|---|---|
| P 操作 | S = S - 1如果 S < 0,则进程阻塞(进入等待队列) 如果 S ≥ 0 → 当前进程继续执行(不会唤醒别人) | 申请资源 / 进入临界区 |
| V 操作 | S = S + 1如果 S ≤ 0,则唤醒一个等待进程 | 释放资源 / 离开临界区 |
信号量S的物理意义为:当S≥0时,表示资源的可用数;当S<0时,其绝对值表示等待资源的进程数。信号量初值是资源数,初始情况下,3台打印机,信号量初值是等于3的,此时什么操作都没有。
V 操作:“发消息”—— 告诉后面的任务 “我做完了,你可以开始了”。 P 操作:“等消息”—— 等前面的任务 “发消息”,收到了才能开始。 箭头开始是发消息,箭头结束是等消息
举例 1)假设有一个信号量 S = 1 (表示一份可用资源,比如一台打印机): 2)进程 A 申请资源:执行 P(S) → S =1-1 =0 ≥ 0 → 成功进入临界区。 3)进程 B 再申请:执行 P(S) → S =0-1= -1 <0 → B 被阻塞,进入等待队列。 4)进程 A 用完资源:执行 V(S) → S = -1 +1 = 0 ≤ 0 → 唤醒 B,B 获得资源。 5)这样就保证了 同一时间只有一个进程使用打印机,避免冲突。
同步(Synchronization),指在一个系统中所发生的事件(event)之间进行协调,在时间上出现一致性与统一化的现象。
(5)性能评估 性能评估是为了一个目的,按照一定的步骤,选用一定的度量项目,通过建模和实验,对一个系统的性能进行各项检测,对测试结果作出解释,并形成一份文档的技术。性能评估的一个目的是为性能的优化提供参考。 在Web服务器的测试中,反映其性能的指标主要有:最大并发连接数、响应延迟、连接速度和吞吐量等。常见的Web服务器性能评测方法有基准性能测试、压力测试和可靠性测试。
系统监视 目标是为了评估系统性能。要监视系统性能,需要收集某个时间段内的3种不同类型的性能数据: (1)常规性能数据。该信息可帮助识别短期趋势如内存泄漏)。经过一两个月的数据收集后,可以求出结果的平均值并用更紧凑的格式保存这些结果。这种存档数据可帮助人们在业务增长时作出容量规划,并有助于在日后评 估上述规划的效果。 (2)比较基准的性能数据。该信息可帮助人们发现缓慢、历经长时间才发生的变化。通过将系统的当前状态与历史记录数据相比较,可以排除系统问题并调整系统。由于该信息只是定期收集的,所以不必对其进行压缩存储。 (3)服务水平报告数据。该信息可帮助人们确保系统能满足一定的服务或性能水平,也可能会将该信息提供给并不是性能分析人员的决策者。收集和维护该数据的频率取决于特定的业务需要。
进行系统监视通常有 3 种方式。 1)一是通过系统本身提供的命令,如 UNIX/Liunx 中的 W、ps、last,Windows 中的netstat等,第一空选择A选项。 2)二是通过系统记录文件查阅系统在特定时间内的运行状态; 3)三是集成命令,文件记录和可视化技术的监控工具,提供直观的界面,操作人员只需要进行一些可视化的设置,而不需要记忆繁杂的命令行参数,即可完成监视操作,如Windows的Perfmon应用程序。Linux 的top是基于命令行的,Linux 的iptables是基于包过滤的防火墙工具。
(6)性能指标 软、硬件的性能指标的集成。在硬件中,包括计算机、各种通信交换设备、各类网络设备等;在软件中,包括:操作系统、协议以及应用程序等。 1)计算机 对计算机评价的主要性能指标有:时钟频率(主频);运算速度;运算精度;内存的存储容量;存储器的存取周期;数据处理速率PDR(processing datarate);吞吐率;各种响应时间;各种利用率;RASIS特性(即:可靠性Reliability、可用性Availability、可维护性Serviceability、完整性和安全性Integrity and Security);平均故障响应时间;兼容性;可扩充性;性能价格比。 2)路由器 对路由器评价的主要性能指标有:设备吞吐量、端口吞吐量、全双工线速转发能力、背靠背帧数、路由表能力、背板能力、丢包率、时延、时延抖动、VPN支持能力、内部时钟精度、队列管理机制、端口硬件队列数、分类业务带宽保证、RSVP、IP DifServ、CAR支持、冗余、热插拔组件、路由器冗余协议、网管、基于Web的管理、网管类型、带外网管支持、网管粒度、计费能力协议、分组语音支持方式、协议支持、语音压缩能力、端口密度、信令支持。 3)交换机 对交筱逆黴幹傥嗬评价的主要性能指标有:交换机类型、配、支持的网络类型、最大ATM端口数、最大SONET端口数最大FDDI端口数、背板吞吐量、缓冲区大小、最大MAC地址表大小、最大电源数、支持协议和标准、路由信息协议RIP、RIP2、开放式最短路径优先第2版、边界网关协议BGP、无类别域间路由CIDR、互联网成组管理协议IGMP、距离矢量多播路由协议DVMRP、开放式最短路径优先多播路由协议MOSPF、协议无关的多播协议PIM、资源预留协议RSVP、802.1p优先级标记、多队列、路由、支持第3层交换、支持多层(4到7层交换)、支持多协议路由、支持路由缓存、可支持最大路由表数、VLAN、最大VLAN数量、网管、支持网管类型、支持端口镜像.Q0S、支持基于策略的第2层交换、每端口最大优先级队列数、支持基于策略的第3层交换、支持基于策略的应用级Q0S、支持最小最大带宽分配、兄余、热交换组件(管理卡,交换结构,接口模块,电源,冷却系统)、支持端釵璨着亏白口链路聚集协议、负载均衡。 4)网络 评价网络的性能指标有:设备级性能指标;网络级性能指标;应用级性能指标;用户级性能指标;吞吐量 5)操作系统 评价操作系统的性能指标有:系统上下文切换、系统的可靠性、系统的吞吐率(量)、系统响应时间、系统资源利用率、可移植性。 6)数据库管理系统 衡量数据库管理系统的主要性能指标包括数据库本身和管理系统两部分,有数据库的大小,数据库中表的数量单个表的大小,表中允许的记录(行)数量、单个记录(行)的大小、表上所允许的索引数量、数据库所允许的索引数量、最大并发事务处理能力、负载均衡能力、最大连接数等等。 7)Web服务器 评价Web服务器的主要性能指标有:最大并发连接数、响应延迟、吞量。常见的Web服务器性能评测方法有基准性能测试、压力测试和可靠性测试。
(7)性能评价方法 真实程序、核心程序、小型基准程序和合成基准程序,其评测准确程度依次递减。其中评测准确度最高的是真实程序,第一空选择A选项。把应用程序中用得最多、最频繁的那部分核心程序作为评估计算机系统性能的标准程序,称为基准测试程序(benchmark)。基准程序法是目前一致承认的测试系统性能的较好方法。
TPC(Transaction Processing Performance Council,事务处理性能委员会) 基准程序用以评测计算机在事务处理、数据库处理、企业管理与决策支持系统等方面的性能。该基准程序的评测结果用每秒完成的事务处理数TPC来表示。 1)TPC-A基准程序规范用于评价在OLTP环境下的数据库和硬件的性能,不同系统之间用性能价格比进行比较; 2)TPC-B测试的是不包括网络的纯事务处理量,用于模拟企业计算环境; 3)TPC-C是专门针对联机事务处理系统**(OLTP)** 的测试标准; 4)TPC-D、TPC-H和TPC-R测试的都是决策支持系统,其中TPC-R允许有附加的优化选项TPC-E测试的是大型企业信息服务系统。 5)TPC-W是基于Web 应用的基准程序,用来测试一些通过Intemet进行市场服务和销售的商业行为,所以TPC-W可以看作是一个服务器的测试标准。
1.4 计算机语言(UML)
【基础知识点】
计算机语言(Computer Language) 是指人与计算机之间用于交流的一种语言,主要由一套指令组成,而这套指令一般包括 表达式、流程控制和集合三大部分内容。
计算机语言的分类有:
(1)机器语言。机器语言是 第一代计算机语言,是计算机自身具有的本地语,由计算机所能直接理解和执行的所有指令组成。指令格式由 操作码和操作数两部分组成。 (2)汇编语言。汇编语言在机器语言的基础上采用英文字母和符号串来表达指令,是机器语言的 符号化描述。每条语句均由 名字、操作符、操作数和注释4个字段(Fields) 组成。伪指令语句包括数据定义伪指令DB、DW、DD,段定义伪指令SEGMENT,过程定义伪指令PROC等,编译后 不产生机器代码。 (3)高级语言。高级语言比汇编语言更 贴近于人类使用的语言,易于理解、记忆和使用。常见的高级语言包括 C、$\mathrm{C + + }$、Java、Python等。 (4)建模语言。建模语言主要指的是 统一建模语言(Unified Modeling Language,UML),UML2.0基础结构的设计目标是定义一个元语言的核心【infrastructureLibrany,基础架构库】,通过对此核心的复用,除了可以定义一个自展的UML元模型,也可以定义其他元模型,包括MOF和CWM(Common WarehouseModel,公共仓库模型)。由于共用核心库,所以UML和MOF、CWM在体系结构上更加一致。同时,InfrastructureLibrary还提供了定制UML更强有力的机制,允许用户定义针对不同平台(如.NET、J2EE等)和领域(如电信、金融、系统工程)的语言。UML由 3个要素构成:UML的 基本构造块(事物、关系)、图(支配基本构造块如何放置在一起的规则) 和运用于整个语言的 公用机制。
1)事物。UML中有 4种事物:结构事物、行为事物、分组事物和注释事物。
a.结构事物:名词、静态部分,用于描述概念或物理元素。结构事物包括 类(Class)、接口(Interface)、协作(Collaboration)、用例(UseCase)、主动类(Active Class)、构件(Component)、制品(Artifact)和节点(Node),如图1.4所示。
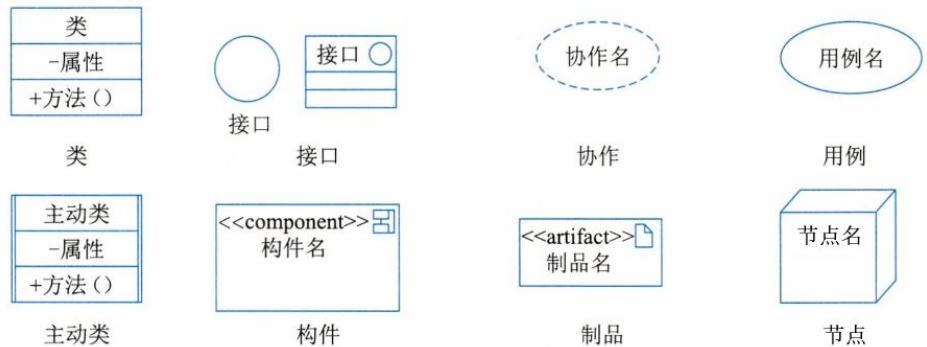
图1.4 结构事物
b.行为事物:动词,描述了跨越时间和空间的行为。行为事物包括 交互(Interaction)、状态机(StateMachine)和活动(Activity),如图1.5所示。

图1.5 行为事物
c.分组事物:包是最常用的分组事物,结构事物、行为事物甚至其他分组事物都可以放进包内,如图1.6所示。
图1.6 包
d.注释事物:注释即注解,用来描述、说明和标注模型的任何元素,如图1.7所示。

图1.7 注释
2)关系。UML中有 4种关系:依赖、关联、泛化和实现。4种关系如图1.8所示。
a.依赖关系。其中一个事物(独立事物)发生变化会影响另一个事物。依赖关系是一种 使用的关系。
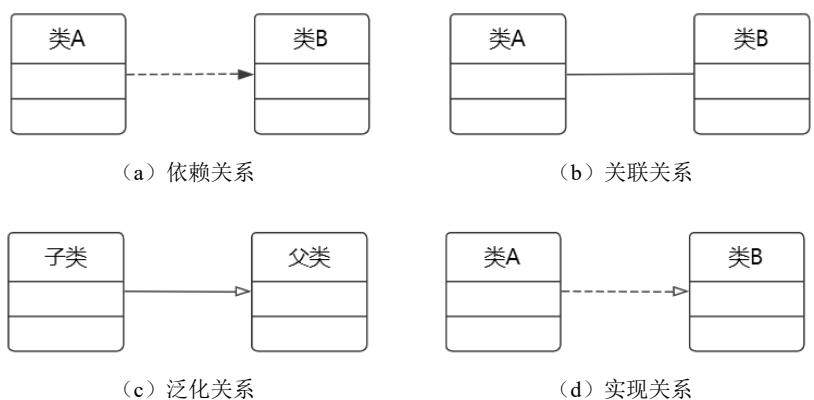
图1.8 UML中的4种关系
b.关联关系。是一种 拥有的关系,关联提供了不同类的对象之间的结构关系,它在一段时间内将多个类的实例连接在一起。一般认为关联关系有 2个特例:一个是 聚合关系,另一个是 组合关系。聚合关系表示类之间的 整体与部分的关系,其含义是部分可能同时属于多个整体,部分与整体的 生命周期可以不相同。组合关系也是表示类之间的整体与部分的关系。与聚合关系的区别在于,组合关系中的部分只能属于一个整体,部分与整体的 生命周期相同,部分随着整体的创建而创建,也随着整体的消亡而消亡。 c.泛化关系。泛化是一种 特殊/一般关系,特殊元素(子元素)的对象可替代一般元素(父元素)的对象。 d.实现关系。在 两种情况下会使用实现关系:一种是在 接口和实现它们的类或构件之间;另一种是在 用例和实现它们的协作之间。
3)图。图是一组元素的 图形表示,大多数情况下把图画成 顶点(代表事物)和弧(代表关系)的连通图。
UML2.0提供了14种图 1)静态结构图:类图、对象图、包图、构件图、部署图、制品图、组合结构图 2)行为图:用例图、状态图、活动图 3)交互图:序列图(顺序图)、通信图、交互概览图、计时图
(1)类图(class diagram)。类图描述一组类、接口、协作和它们之间的关系。在O0系统的建模中,最常见的图就是类图。类图给出了系统的静态设计视图,活动类的类图给出了系统的静态进程视图。 (2)对象图(object diagram)。对象图描述一组对象及它们之间的关系。对象图描述了在类图中所建立的事物实例的静态快照。和类图一样,这些图给出系统的静态设计视图或静态进程视图,但它们是从真实案例或原型案例 的角度建立的。 (3)构件图(component diagram)。构件图描述一个封装的类和它的接口、端口,以及由内嵌的构件和连接件构成的内部结构,构件图用于表示系统的静态设计实现视图。对于由小的部件构建大的系统来说,构件图是很重要的。构件图是类图的变体。 (4)组合结构图(composite structure diagram)。组合结构图描述结构化类(例如,构件或类)的内部结构包括结构化类与系统其余部分的交互点。组合结构图用于画出结构化类的内部内容。 (5)用例图(use case diagram)。用例图描述一组用例、参与者及它们之间的关系。用例图给出系统的静态用例视图。这些图在对系统的行为进行组织和建模时是非常重要的。 (6)顺序图(sequence diagram,序列图)。顺序图是一种交互图(interaction diagram),交互图展现了一种交互,它由一组对象或参与者以及它们之间可能发送的消息构成。交互图专注于系统的动态视图。顺序图是强调消 息的时间次序的交互图。 (7)通信图(communication diagram)。通信图也是一种交互图,它强调收发消息的对象或参与者的结构组织。顺序图和通信图表达了类似的基本概念,但它们所强调的概念不同,顺序图强调的是时序,通信图强调的是对象之间的组织结构(关系)。在UML1.X版本中,通信图称为协作图(collaboration diagram)。 (8)定时图(timing diagram,计时图)。定时图也是一种交互图,它强调消息跨越不同对象或参与者的实际时间,而不仅仅只是关心消息的相对顺序。 (9)状态图(state diagram)。状态图描述一个状态机,它由状态、转移、事件和活动组成。状态图给出了对象的动态视图。它对于接口、类或协作的行为建模尤为重要,而且它强调事件导致的对象行为,这非常有助于反应式系统建模。状态表示对象在特定时间点的行为模式;事件是导致状态转换的外部或内部刺激;转移表示对象在特定条件下从一种状态转移到另一种状态;动作则是与状态转换相关联的行为。因此,用于表示对象在特定条件下从一种状态转移到另一种状态的元素是转移。 (10)活动图(activity diagram)。活动图将进程或其他计算结构展示为计算内部一步步的控制流和数据流。活动图专注于系统的动态视图,它对系统的功能建模和业务流程建模特别重要,并强调对象间的控制流程。 (11)部署图(deployment diagram)。部署图描述对运行时的处理节点及在其中生存的构件的配置。部署图给出了架构的静态部署视图,通常一个节点包含一个或多个部署图。 (12)制品图(artifact diagram)。制品图描述计算机中一个系统的物理结构。制品包括文件、数据库和类似的物理比特集合。制品图通常与部署图一起使用。制品也给出了它们实现的类和构件。 (13)包图(package diagram)。包图描述由模型本身分解而成的组织单元,以及它们之间的依赖关系。 (14)交互概览图(interaction overview diagram)。交互概览图是活动图和顺序图的混合物。综上,答案选择B。
②状态图、活动图、顺序图和通信图可以用来对系统的动态行为进行建模。活动图展现了在系统内从一个活动到另一个活动的流程。活动图强调对象之间的控制流程。在活动图上可以表示分支和汇合。活动图与传统的程序流程图是不等价的。 ③面向对象的设计模型包含以包图表示的软件体系结构图,以交互图表示的用例实现图,完整精确的类图,针对复杂对象的状态图和用以描述流程化处理的活动图等。 ④序列图(顺序图) 是用来显示参与者如何以一系列顺序的步骤与系统的对象交互的模型。顺序图可以用来展示对象之间是如何进行交互的。顺序图将显示的重点放在消息序列上,即强调消息是如何在对象之间被发送和接收的,其中循环、选择等复杂交互使用序列片段表示,对象之间的消息类型包括同步消息、异步消息、返回消息、参与者创建消息、参与者销毁消息,其中同步消息的发送者等待消息接收对象将消息处理完成后再继续,异步消息的发送者在发送完消息后不等待接收方就继续自己的处理。返回消息是指当一个对象将消息发送给另一个对象后,另一个对象返回的虚线有向边,表示原消息已处理的消息。创建消息是表示对消息传递目标对象的创建。销毁消息是表示对消息传递目标对象的删除。 ⑤对象图(object diagram)。对象图描述一组对象及它们之间的关系。对象图描述了在类图中所建立的事物实例的静态快照。和类图一样,这些图给出系统的静态设计视图或静态进程视图,但它们是从真实案例或原型案例的角度建立的。 ⑥活动图(activity diagram)。活动图将进程或其他计算结构展示为计算内部一步步的控制流和数据流。活动图专注于系统的动态视图。它对系统的功能建和业务流程建模特别重要,并强调对象间的控制流程。 ⑦状态图(state diagram)。状态图描述一个状态机,它由状态、转移、事件和活动组成。状态图给出了对象的动态视图。它对于接口、类或协作的行为建模尤为重要,而且它强调事件导致的对象行为,这非常有助于对反应式系统建模。定义对象内部行为 ⑧类图(class diagram)。类图描述一组类、接口、协作和它们之间的关系。在OO系统的建模中,最常见的图就是类图。类图给出了系统的静态设计视图,活动类的类图给出了系统的静态进程视图。 ⑨在初步的业务需求描述已经形成的前提下,基于UML的需求分析过程大致可分为以下步骤: 1) 利用用例及用例图表示需求。从业务需求描述出发获取执行者和场景;对场景进行汇总、分类、抽象,形成用例;确定执行者与用例、用例与用例图之间的关系,生成用例图。 2)利用包图和类图表示目标软件系统的总体框架结构。根据领域知识、业务需求描述和既往经验设计目标软件系统的顶层架构;从业务需求描述中提取“关键概念”,形成领域概念模型;从概念模型和用例出发,研究系统中主要的类之间的关系,生成类图。
| 类别 | 图名 | 关键字 | 作用/特点 | 典型用途 | 相关对比 |
|---|---|---|---|---|---|
| 静态结构图 | 类图 | 类、接口、关系、静态结构,表达类的内部行为 | 展示类与类之间的关系,是最常见的 UML 图 | 面向对象系统设计、数据库建模 | 和 对象图对比:类图是抽象设计,对象图是实例快照 |
| 对象图 | 对象实例、关系、快照 | 类图实例化的快照,展示运行时对象及关系 | 验证类图、展示运行时对象关系 | 和 类图对比:对象图 = 类图的运行时实例 | |
| 包图 | 包、依赖、组织结构 | 表示软件体系结构的模块化组织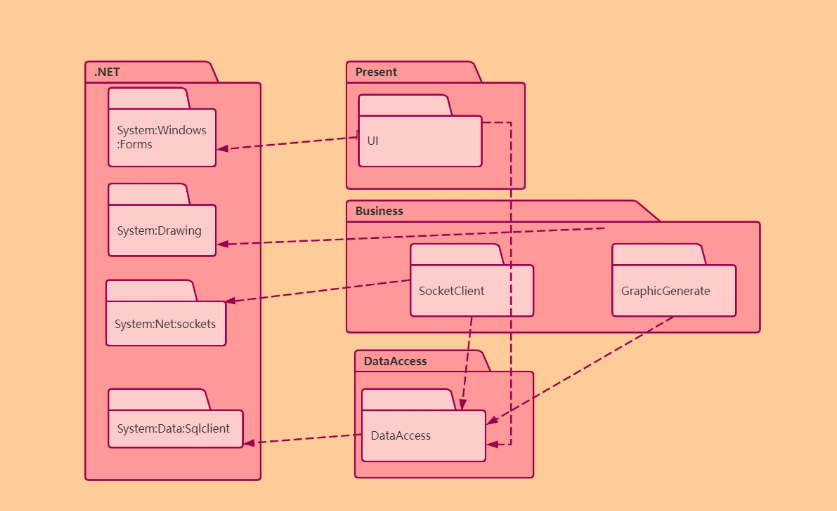 | 软件分层、模块依赖分析 | 和 构件图对比:包图偏逻辑组织,构件图偏物理实现 | |
| 构件图 | 构件、接口、依赖 | 表示系统的物理组件及依赖关系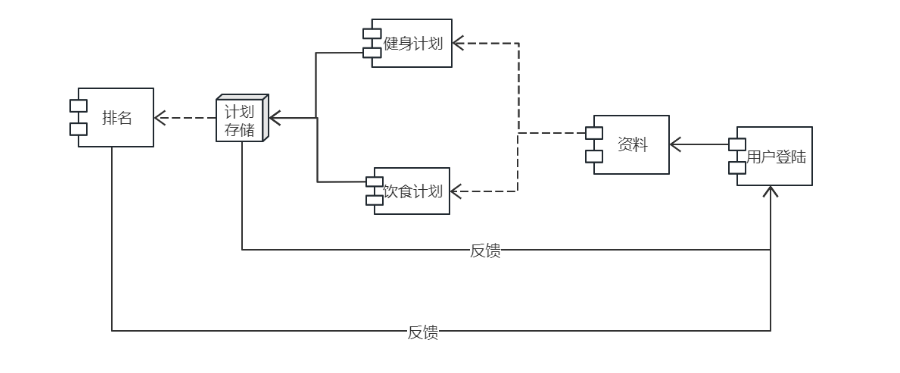 | 系统实现阶段、物理组件设计 | 和 部署图对比:构件图关注软件组件,部署图关注硬件节点 | |
| 部署图 | 节点、硬件、连接 | 展示系统运行时硬件拓扑及软件部署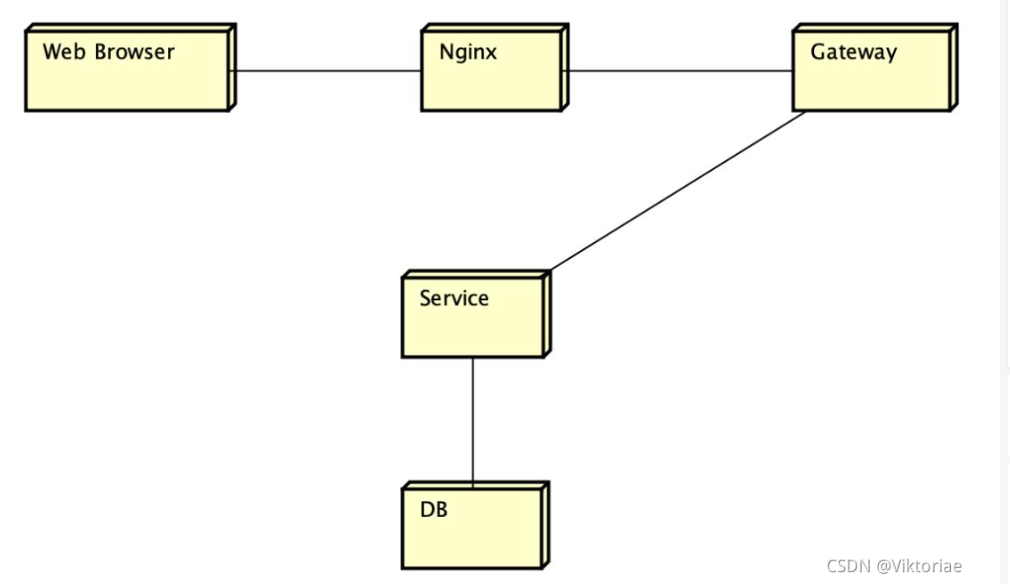 | 分布式系统部署、运维设计 | 和 构件图对比:部署图更偏运行环境,构件图更偏逻辑实现 | |
| 制品图 | 制品、输出、工件 | 表示开发过程中产生的物理制品,如文档、库 | 项目交付物管理、版本控制 | 和 构件图对比:制品图是产出物,构件图是实现单元 | |
| 组合结构图 | 内部结构、协作、部件 | 展示类或构件的内部结构及协作关系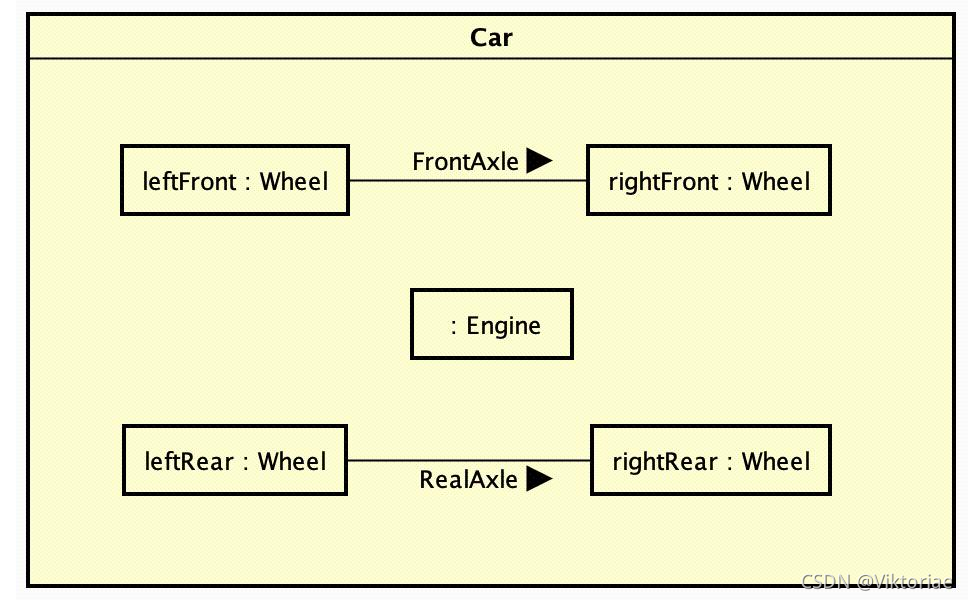 | 框架设计、组件内部协作说明 | 和 类图对比:组合结构图更关注内部协作细节 | |
| 行为图 | 用例图 | 参与者、用例、系统边界 | 从用户视角展示系统功能需求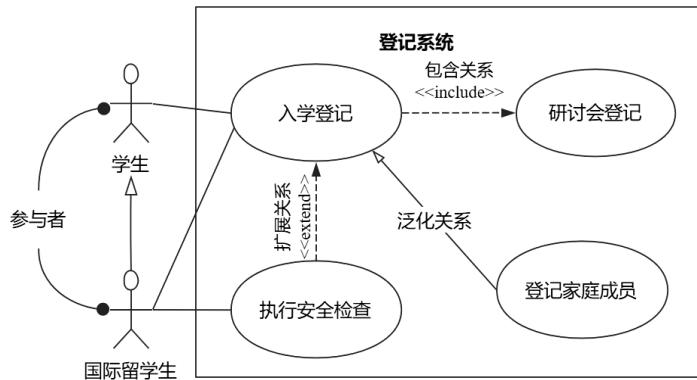 | 需求分析、功能建模 | 和 活动图对比:用例图关注“做什么”,活动图关注“怎么做” |
| 状态图 | 状态、事件、转移,定义内部行为 | 描述对象随事件发生而转移的状态机 | 反应式系统建模、协议状态机 | 和 活动图对比:状态图关注状态变化,活动图关注流程控制 | |
| 活动图 | 流程、分支、汇合、控制流 | 强调业务流程和控制流,类似流程图但更面向对象 | 业务流程建模、算法流程设计 | 和 状态图对比:活动图是流程导向,状态图是状态导向 | |
| 交互图 | 序列图 | 时间顺序、消息、同步/异步 | 强调消息的时间顺序,展示对象交互过程 | 用例实现、时序分析 | 和 通信图对比:序列图突出时间顺序,通信图突出对象关系 |
| 通信图 | 对象、连接、消息 | 强调对象之间的结构关系及消息传递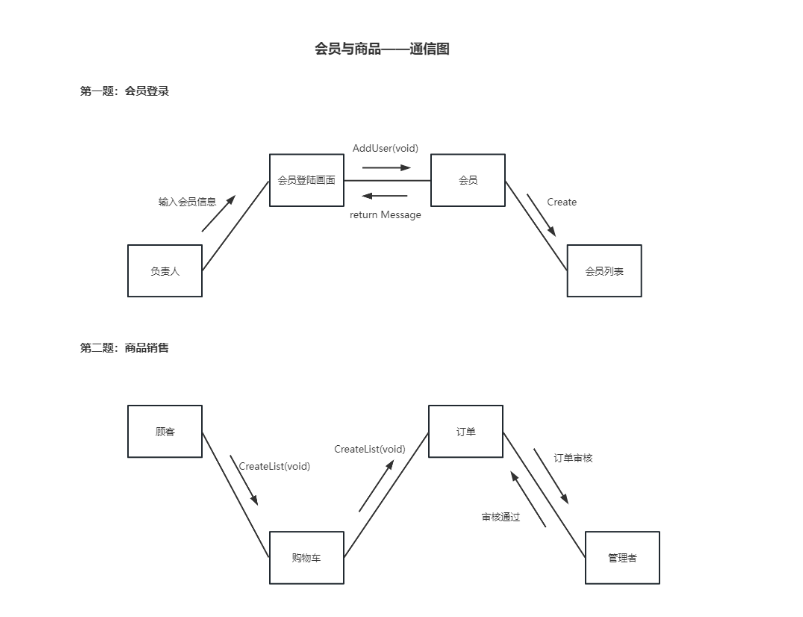 | 交互逻辑说明、系统通信建模 | 和 序列图对比:通信图侧重对象结构,序列图侧重时间 c | |
| 交互概览图 | 流程、交互组合、控制节点 | 综合展示多个交互之间的控制流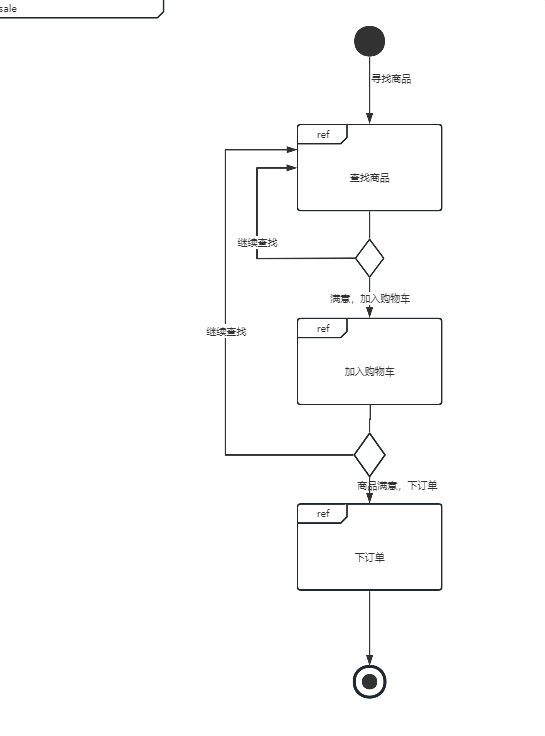 | 大型系统交互流程总览 | 和 活动图对比:交互概览图可嵌入交互图,活动图不可 | |
| 计时图 | 时间轴、状态随时间变化 | 强调对象或交互随时间推移的状态变化 | 实时系统、嵌入式系统 | 和 序列图对比:计时图突出“时间连续性”,序列图突出“消息离散性” |
①类图如图1.9所示。类图展现了一组 对象、接口、协作和它们之间的关系。
②用例图如图1.10所示。用例图(Use Case Diagram)展现了一组用例、参与者(Actor)以及它们之间的关系。用例之间有 扩展关系和包含关系,参与者和用例之间有关联关系,用例与用例、参与者与参与者之间有泛化关系(继承关系)。
- 包含关系的特点是当两个或多个用例中共用一组相同的动作时,可以将这组相同的动作抽出来作为一个独立的子用例,供多个基用例所共享;包含关系是指一个用例必须调用另一个用例才能完成,例如输入密码后必须验证
- 扩展关系则是对基用例的扩展,基用例是一个完整的用例,即使没有子用例的参与,也可以完成一个完整的功能。扩展关系是可选调用,如登录后可选择弹广告;
- 泛化关系是父用例与子用例之间的继承关系,如会员注册是父用例,电话或邮件注册是其具体形式,二者选其一执行。
| 关系 | 关键词 | 简要说明 | 示例 |
|---|---|---|---|
| 包含关系(Include) | 必须、共享、复用 | 基用例必须调用子用例;抽取共用动作供多个用例复用。 | 输入密码 → 验证密码(登录必须包含验证)A-> B |
| 扩展关系(Extend) | 可选、扩展、增强 | 基用例本身完整;子用例是可选扩展,在特定条件下触发。 | 登录 → 弹出广告(广告是可选扩展) A -> (B) |
| 泛化关系(Generalization) | 继承、父子、替代 | 子用例继承父用例的特性;子用例是父用例的具体实现或替代。 | 会员注册 → 电话注册 / 邮件注册 A -> BC |
图1.10 UML用例图
4)UML中有 5种视图(View):用例视图、逻辑视图、进程视图、实现视图、部署视图,其中的 用例视图居于中心地位。
$①$逻辑视图。逻辑视图也称为设计视图,它表示了设计模型中在架构方面具有重要意义的部分,即类、子系统、包和用例实现的子集。当采用面向对象的设计方法描述对象模型时,通常使用类图表达类的内部属性和行为,以及类集合之间的交互关系;采用状态图定义对象的内部行为。 $②$进程视图。进程视图是可执行线程和进程作为活动类的建模,它是逻辑视图的一次执行实例,描述了并发与同步结构。 $③$实现视图。实现视图对组成基于系统的物理代码的文件和构件进行建模。 $④$部署视图。部署视图把构件部署到一组物理节点上,表示软件到硬件的映射和分布结构。 $⑤$用例视图。用例视图是最基本的需求分析模型。
和4+1模型的区别
| 对比点 | 软件架构 4+1 模型 | UML 4+1 视图 |
|---|---|---|
| 提出者 | Kruchten(1995,Rational 方法) | UML 规范中借鉴 |
| 性质 | 方法论/思想:指导如何多角度描述架构 | 建模语言/工具:用图形表达各视图 |
| 目的 | 架构说明书,让不同干系人都能理解系统 | 建模支持,用具体 UML 图展现架构 |
| 关系 | 抽象的思想框架 | 落地的表达手段(用 UML 图实现 4+1 模型) |
(5)形式化方法和形式化语言。
形式化方法是把概念、判断、推理转化成特定的形式符号后,对形式符号表达系统进行研究的方法。形式化方法有不同的分类方法。根据描述方式分,有 模型描述和性质描述两类;根据表达能力分,有 模型方法、代数方法、进程代数方法、逻辑方法和网络模型方法5类。形式化方法的开发过程贯穿 软件工程的整个生命周期。
形式化方法是一种具有坚实数学基础的方法,从而允许对系统和开发过程做严格处理和论证,适用于那些系统安全级别要求极高的软件的开发。形式化方法的主要优越性在于它能够数学地表述和研究应用问题及软件实现。但是它要求开发人员具备良好的数学基础。用形式化语言书写的大型应用问题的软件规格说明往往过于细节化,并且难于为用户和软件设计人员所理解。由于这些缺陷,形式化方法在目前的软件开发实践中并未得到普遍应用。
Z语言是一种形式化语言,具有 状态一操作风格,借助模式来表达系统结构。建立于 集合论和数理逻辑的基础上,是一个 强类型系统,可以使用自然语言。
(6)COM(Component Object Model) 微软提出的组件对象模型,核心目标是 二进制级别的可复用。一个重要限制:COM 不支持实现继承(不像 C++/Java 那样继承父类实现)。COM 的两种对象组装方式: 1)包含(Containment):外部对象持有一个内部对象的引用。当客户调用外部对象的方法时,外部对象转发调用给内部对象。就像外部对象是一个“代理人”,客户看不到内部对象,感觉只是在和外部对象交互。 2)聚集(Aggregation):外部对象直接把内部对象的接口暴露给客户,而不是再转发请求。客户调用时,其实就是直接在用内部对象的方法,只是看起来像是在用外部对象。这样避免了转发带来的性能损耗。
COM和UML的区别:
| 特性 | COM(组件对象模型) | UML(统一建模语言) |
|---|---|---|
| 本质 | 组件二进制 标准 | 建模语言/规范 |
| 关注点 | 组件交互、接口、复用、部署 | 系统建模、结构与行为表达 |
| 层次 | 实现层(运行时交互) | 设计层(图形化建模) |
| 作用 | 确保组件可复用、可交互、跨语言兼容 | 描述和设计系统结构、行为、依赖关系 |
| 联系 | 可以用 UML 来建模 COM 系统及接口关系 | UML 模型最终可以落实到 COM 实现上 |
1.5 多媒体技术
1.媒体与多媒体
媒体是承载信息的载体,即信息的表现形式(或者传播形式),如 文字、声音、图像、动画和视频等。多媒体有 4个重要的特征:
(1)多维化,即媒体的多样化。 (2)集成性,多媒体与设备集成,也与信息和表现集成。 (3)交互性,可向用户提供更有效的控制和使用信息的手段。 (4)实时性,音频和视频等信息具有很强的时间特性。
多媒体系统通常由 硬件和软件组成,其中多媒体硬件主要包括 计算机主要配置和外部设备以及与各种外部设备的控制接口;多媒体软件主要包括 多媒体驱动软件、多媒体操作系统、多媒体数据处理软件、多媒体创作工具软件和多媒体应用软件等。
2.多媒体系统的关键技术
(1)视、音频技术,视频技术包括 视频数字化和视频编码技术两个方面;音频技术包括 音频数字化、语音处理、语音合成及语音识别4个方面。 (2)通信技术,是多媒体系统中的一项关键技术,通常包括 数据传输信道技术和数据传输技术。 (3)数据压缩技术,包括 即时压缩和非即时压缩、数据压缩和文件压缩、无损压缩与有损压缩等。 (4)虚拟现实(Virtual Reality,VR)/增强现实(Augmented Reality,AR)技术,虚拟现实又称人工现实、临境等,是一种可以创建和体验虚拟世界的计算机仿真系统,采用计算机技术生成一个逼真的 视觉、听觉、触觉、味觉及嗅觉的感知系统与用户交互;增强现实技术是指把原本在现实世界的一定时间和空间范围内很难体验到的实体信息(视觉信息、声音、味道和触觉等),通过模拟仿真后,再叠加到现实世界中被人类感官所感知,从而达到超越现实的感官体验。VR/AR技术主要分为 桌面式、分布式、沉浸式和增强式4种。
1.6 练习题
- 目前处理器市场中存在CPU和DSP两种类型的处理器,分别用于不同的场景,这两种处理器具有不同的体系结构,DSP采用()。
A.冯·诺依曼结构 B.哈佛结构 C.FPGA结构 D.与GPU相同的结构
解析:编程 DSP芯片是一种具有特殊结构的微处理器,为了达到快速进行数字信号处理的目的,DSP芯片一般都采用特殊的软硬件结构:哈佛结构。
哈佛结构将存储器空间划分成两个,分别存储 程序和数据。它们有两组总线连接到处理器核,允许 同时对它们进行访问,每个存储器 独立编址,独立访问。这种安排将处理器的 数据吞吐率加倍,更重要的是同时为处理器核提供数据与指令。在这种布局下,DSP得以实现 单周期的MAC指令。
在哈佛结构中,由于程序和数据存储器在两个分开的空间中,因此 取指和执行能完全重叠运行。
答案:B
- ()是专用于实时的数字信号处理的处理器。
A.DSP B.CUP C.GPU D.FPGA
解析:DSP专用于 实时的数字信号处理,常采用 哈佛体系结构。
答案:A
- 在线学习系统中,课程学习和课程考试都需要先检查学员的权限,“课程学习”与“检查权限”两个用例之间属于(1)课程学习过程中,如果所缴纳学费不够,就需要补缴学费,“课程学习”与“缴纳学费”两个用例之间属于(2):课程学习前需要课程注册,可以采用电话注册或网络注册,“课程注册”与“网络注册”两个用例之间属于(3)。
(1)A.包含关系 B.扩展关系 C.泛化关系 D.关联关系(2)A.包含关系 B.扩展关系 C.泛化关系 D.关联关系(3)A.包含关系 B.扩展关系 C.泛化关系 D.关联关系
解析:用例之间的关系主要有 包含、扩展和泛化3类。
1)包含关系:当可以从两个或两个以上的用例中 提取公共行为时,应该使用包含关系来表示它们。课程学习与检查权限是 包含关系。
2)扩展关系:如果一个用例明显地混合了两种或两种以上的不同场景,即根据情况可能发生多种分支,则可以将这个用例分为一个基本用例和一个或多个扩展用例,这样使描述可能更加清晰。课程学习与缴纳学费是 扩展关系。
3)泛化关系:当多个用例共同拥有一种类似的结构和行为的时候,可以将它们的 共性抽象成为父用例,其他的用例作为泛化关系中的子用例。课程注册与网络注册是 泛化关系。
答案:ABC
第2小时 嵌入式基础知识
2.0 章节考点分析
第2小时主要学习 嵌入式系统的组成及特点、嵌入式系统的分类、嵌入式软件的组成及特点、嵌入式系统硬件体系结构、安全攸关软件的安全性设计等内容。根据考试大纲,本小时知识点会涉及 单项选择题和案例分析题,本小时只关注选择第2小时嵌入式基础知识题部分。按以往全国计算机技术与软件专业技术资格(水平)考试的出题规律约占 5分。本小时内容属于 基础知识范畴,除了书本上的知识以外,也涉及一些专业知识。本小时知识架构如图2.1所示。
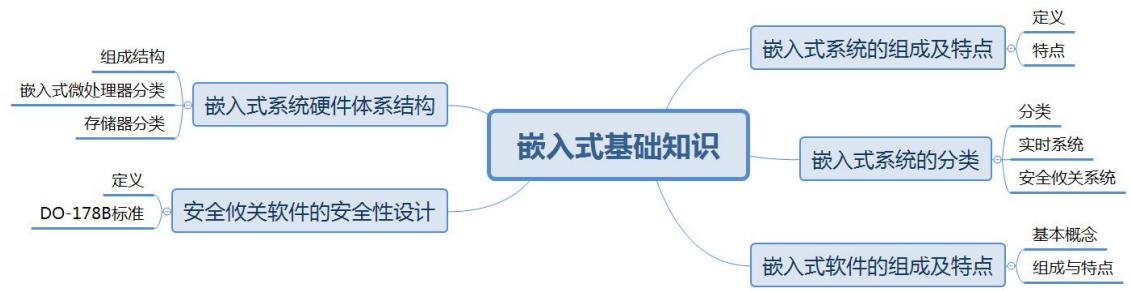
图2.1本小时知识架构
【导读小贴士】
随着计算机技术、微电子技术、通信技术以及集成电路技术的发展,嵌入式技术逐渐发展和成熟起来。嵌入式系统的应用日益广泛,有很多技术特性与通用计算机系统不同,并在数量上远远超越了通用计算机系统,成为计算机技术和计算机应用领域的一个重要组成部分。嵌入式知识点属于比较偏的考点,属于拔高内容,案例部分属于选答题,不强制要求掌握。
2.1 嵌入式系统的组成及特点
【基础知识点】
- 定义
嵌入式系统(Embedded System) 是以 特定应用为中心、以计算机技术为基础,并将 可配置与可裁剪的软、硬件集成于一体的专用计算机系统。嵌入式系统的组成结构是:
(1)嵌入式处理器,除满足 低功耗、体积小等需求外,工艺可分为 民用、工业和军用等三个档次,民用级器件的工作温度范围是 $0\sim 70^{\circ}C$、工业级的是 $-40\sim 85^{\circ}C$、军用级的是 $-55\sim 150^{\circ}C$。其应用环境常常非常恶劣,比如有 高温、寒冷、电磁、震动、烟尘等环境因素。 (2)相关支撑硬件,指除处理器以外的其他硬件,如 存储器、定时器、总线等。 (3)嵌入式操作系统,与通用操作系统不同,嵌入式操作系统应具备 实时性、可裁剪性和安全性等特征。 (4)支撑软件,其中的公共服务通常运行在操作系统之上,以库的方式被应用软件所引用。 (5)应用软件,是指为完成嵌入式系统的某一专用目标所开发的软件。
- 嵌入式系统的特点
(1)专用性强,常常面向特定应用需求,配备多种传感器。 (2)技术融合,将先进的计算机技术、通信技术、半导体技术和电子技术与各个行业的具体应用紧密结合难以拆分。 (3)软硬一体软件为主,在通用的嵌入式系统版本基础上裁剪冗余,高效设计。 (4)资源受限,由于低功耗、体积小和集成度高等要求,系统的资源非常少。 (5)程序代码固化在ROM中,以提高执行速度和系统可靠性。 (6)需专门开发工具和环境,见2.3节。 (7)体积小、价格低、工艺先进、性能价格比高、系统配置要求低、实时性强。 (8)对 安全性和可靠性的要求高。
HarmonyOs系统 HarmonyOS系统功能按照“系统->子系统->功能/模块”逐步逐级展开,在多设备部署场景下,支持根据实际需求裁剪或增加子系统或功能/模块。 内核层:鸿蒙系统分为内核子系统和驱动子系统。在内核子系统中鸿蒙系统采用多内核设计,支持针对不同资源受限设备选用合适的OS内核;鸿蒙系统驱动框架是鸿蒙系统硬件生态开放的基础,它提供统一外设访问能力和驱动开发、管理框架。 系统服务层:系统服务层是鸿蒙系统的核心能力集合,通过框架层对应用程序提供服务。包含了系统基本能力子系统集、基础软件服务子系统集、增强软件服务子系统集、硬件服务子系统四个部分。框架层:框架层为鸿蒙系统应用程序提供Java/C/C++/S等多语言用户程序框架和Abity框架,及各种软硬件服务对外开放的多语言框架API,也为搭载鸿蒙系统的电子设备提供C/C++/S等多语言框架API。应用层:应用层包括系统应用和第三方非系统应用,鸿蒙系统应用由一个或多个FA或PA组成。系统安全:在搭载鸿蒙系统的分布式终端上保证“正确的人通过正确的电子设备,正确地使用数据”。通过“分布式多段协同身份认证“保证“正确的人”,通过“在分布式终端构筑可信运行环境"保证“正确的电子设备”,通过“分布式数据在跨终端流动的过程中,对数据进行分类分级管理”来保证“正确地使用数据”。综上,B选项说法错误。
微内核 采用微内核结构的操作系统与传统的操作系统相比,其优点是提高了系统的灵活性、可扩充性,增强了系统的可靠性,提供了对分布式系统的支持。其原因如下: ① 灵活性和可扩展性:由于微内核OS的许多功能是由相对独立的服务器软件来实现的,当开发了新的硬件和软件时,微内核OS只须在相应的服务器中增加新的功能,或再增加一个专门的服务器。与此同时,也必然改善系统的灵活性,不仅可在操作系统中增加新的功能,还可修改原有功能,以及删除已过时的功能,以形成一个更为精干有效的操作系统。 ② 增强了系统的可靠性和可移植性:由于微内核是出于精心设计和严格测试的,容易保证其正确性;另一方面是它提供了规范而精简的应用程序接口(API),为微内核外部的程序编制高质量的代码创造了条件。此外,由于所有服务器都是运行在用户态,服务器与服务器之间采用的是消息传递通信机制,因此,当某个服务器出现错误时,不会影响内核,也不会影响其他服务器。另外,由于在微内核结构的操作系统中,所有与特定CPU和I/O设备硬件有关的代码,均放在内核和内核下面的硬件隐藏层中,而操作系统其他绝大部分(即各种服务器)均与硬件平台无关,因而,把操作系统移植到另一个计算机硬件平台上所需作的修改是比较小的。 ③ 提供了对分布式系统的支持:由于在微内核OS中,客户和服务器之间以及服务器和服务器之间的通信,是采用消息传递通信机制进行的,致使微内核OS能很好地支持分布式系统和网络系统,事实上,只要在分布式系统中喊予所有进程和服务器唯一的标识符,在微内核中再配置一张系统映射表(即进程和服务器的标识符与它们所驻留的机器之间的对应表),在进行客户与服务器通信时,只需在所发送的消息中标上发送进程和接收进程的标识符,微内核便可利用系统映射表,将消息发往目标,而无论目标是驻留在哪台机器上。
2.2 嵌入式系统的分类
【基础知识点】
- 分类
根据不同用途可将嵌入式系统划分为 嵌入式实时系统和嵌入式非实时系统两种。而实时系统又可分为 强实时(Hard Real- Time)系统和弱实时(Weak Real- Time)系统。从安全性要求看,嵌入式系统还可分为 安全攸关(Safety- Critical或Life- Critical)系统和非安全攸关系统。
- 实时系统
实时系统(Real-Time System,RTS) 是指能够在 规定的时间内完成系统功能和做出响应的系统。
- 安全攸关系统
安全攸关系统(Safety-Critical System) 是指其不正确的功能或者失效会导致 人员伤亡、财产损失等严重后果的计算机系统。
2.3 嵌入式软件的组成及特点
【基础知识点】
- 基本概念
大多数嵌入式系统都具备 实时特征,这种嵌入式系统的典型架构可概括为两种模式,即 层次化模式架构和递归模式架构。嵌入式系统的最大特点就是 系统的运行和开发是在不同环境中进行的,通常将运行环境称为 目标机环境,称开发环境为 宿主机环境,宿主机与目标机之间通过 串口、网络或JTAG接口连接。由于宿主机和目标机的指令往往是不同的,嵌入式系统的开发通常需要 交叉平台开发环境支持,基本开发工具是 交叉编译器、交叉链接器和源代码调试器。还需要注意 实时性、安全性和可靠性。代码规模、软/硬件协同工作的效率和稳定性、特定领域的需求等。
- 嵌入式系统的组成与特点
从细节上看,嵌入式系统可以分为:
(1)硬件层,包括处理器、存储器、总线、I/O接口及电源、时钟等。 (2)抽象层,包括硬件抽象层(HAL),为上层应用(操作系统)提供虚拟的硬件资源;板级支持包(BSP),是一种硬件驱动软件,为上层操作系统提供对硬件进行管理的支持。 (3)操作系统层,由嵌入式操作系统、文件系统、图形用户接口、网络系统和通用组件等可配置模块组成。 (4)中间件层,是连接两个独立应用的桥梁,常用的有嵌入式数据库、OpenGL、消息中间件、Java中间件、虚拟机(VM)、DDS/CORBA和Hadoop等 (5)应用层,包括不同的应用软件。
嵌入式软件的主要特点有:
(1)可剪裁性:设计方法包括静态编译、动态库和控制函数流程实现功能控制等。 (2)可配置性:设计方法包括数据驱动、静态编译和配置表等。 (3)强实时性:设计方法包括表驱动、配置、静/动态结合、汇编语言等。 (4)安全性(Safety):设计方法包括编码标准、安全保障机制、FMECA(故障模式、影响及危害性分析)。 (5)可靠性:设计方法包括容错技术、余度技术和鲁棒性设计等。 (6)高确定性:设计方法包括静态分配资源、越界检查、状态机、静态任务调度等。综上所述,嵌入式软件的开发也与传统的软件开发方法差异较大。在嵌入式系统设计时,要进行低功耗设计。主要技术有编译优化技术、软硬件协同设计、算法优化。
2.4 嵌入式系统硬件体系结构
【基础知识点】
- 组成结构
组成结构传统的嵌入式系统主要由嵌入式微处理器、存储器、总线逻辑、定时/计数器、看门狗电路、I/O接口和外部设备等部件组成。
- 嵌入式微处理器分类
| 类别 | 英文全称 | 主要特点 | 代表型号 / 系列 |
|---|---|---|---|
| 微处理器(MPU) | Microprocessor Unit | 专门设计的电路板,集成度低、可靠性高,主要用于通用计算 | Am186/88、386EX、SC-400、PowerPC、68000、MIPS、ARM系列 |
| 微控制器(MCU) | Microcontroller Unit | 又称单片机,核心存储器与部分外设封装在片内,体积小、功耗低、成本低、可靠性高 | 8501、P5IXA、MCS-251、MCS-96/196/296、C166/167、MC68HC05/11/12/16、68300、ARM系列 |
| 数字信号处理器(DSP) | Digital Signal Processor | 采用哈佛结构,对结构和指令做特殊设计,适合执行大量数据处理任务 | TMS320系列(C2000/C5000/C6000/C8000)、DSP56000系列、实时DSP处理器等 |
| 图形处理器(GPU) | Graphics Processing Unit | 相比CPU,增强浮点与并行计算能力,广泛应用于AI深度学习与图像运算 | NVIDIA、AMD Radeon、Apple GPU 等 |
| 片上系统(SoC) | System on Chip | 在单一芯片上集成完整系统(含处理器、IP核、存储器、嵌入式软件),是一个系统级产品而非单一芯片 | 各类 ARM SoC(如高通骁龙、苹果A系列、华为麒麟) 等 |
(1)微处理器(MicroprocessorUnit,MPU):微处理器 $^+$ 专门设计的电路板,集成度低、可靠性高,主要有:Am186/88、386EX、SC-400、PowerPC、68000、MIPS、ARM系列等。 (2)微控制器(MicrocontrollerUnit,MCU):又称单片机,把核心存储器和部分外设封装在片内。优点是单片化、体积小、功耗和成本下降,可靠性提高。包括8501,P5IXA,MCS-251,MCS-96/196/296,C166/167,MC68HC05/11/12/16,68300和数目众多的ARM系列。 (3)数字信号处理器(DigitalSignalProcessing,DSP):采用哈佛结构,对系统结构和指令进行了特殊设计,适合执行大量数据处理。包括TMS320系列(含C2000、C5000、C6000、C8000系列)、DSP56000系列、实时DSP处理器等。 (4)图形处理器(GraphicsProcessingUnit,GPU):与CPU相比大幅加强子浮点运算能力和多核并行计算能力,因此常用于AI技术的深度学习的数据运算。 (5)片上系统(SystemonChip,SoC):由多个具有特定功能的集成电路组合在一个芯片上形成的系统或产品,其中包含完整的硬件系统,如处理器、IP(IntellectualProperty)核、存储器等及其承载的嵌入式软件,如操作系统和定制的用户软件。
SoC称为片上系统,它是一个产品,是一个有专用目标的集成电路,其中包含完整系统并有嵌入软件的全部内容。所以B的说法是错误的,SoC不是一块处理器芯片。同时它又是一种技术,用以实现从确定系统功能开始,到软/硬件划分,并完成设计的整个过程。(A是正确的)从狭义角度讲,它是信息系统核心的芯片集成,是将系统关键部件集成在一块芯片上;(C是正确的)从广义角度讲,SoC是一个微小型系统,如果说中央处理器(CPU)是大脑,那么SoC就是包括大脑、心脏、眼睛和手的系统。国内外学术界一般倾向将SoC定义为将微处理器、模拟IP核、数字IP核和存储器(或片外存储控制接口)集成在单一芯片上,它通常是客户定制的,或是面向特定用途的标准产品。(D是正确的)。
嵌入式微处理器主要用于处理相关任务。由于嵌入式系统通常都在室外使用,可能处于不同环境,因此选择处理器芯片时,也要根据不同使用环境选择不同级别的芯片。其主要因素是芯片可适应的工作环境温度。通常,我们把芯片分为民用级、工业级和军用级。
1)民用级的工作温度范围:070°C
2)工业级的工作温度范围:-4085°C
3)军用级的工作温度范围:-55~150C
嵌入式实时操作系统兼具嵌入式操作系统的特点和实时操作系统的特点。嵌入式操作系统主要有以下特点:** 1)微型化 2)代码质量高 3)专业化 4)实时性强 5)可裁减、可配置。 实时操作系统的最核心特点是实时性强。
实时系统存在多种调度算法。 1)优先级调度算法:系统为每个任务分配一个相对固定的优先顺序,然后调度程序根据优先级的高低排序,按时间顺序进行高优先级任务优先调度。 2)抢占式优先级调度算法:是在优先级调度算法基础上,允许高优先级任务抢占低优先级任务而运行。 3)最晚截止期调度算法:指调度程序按每个任务最接近其截止期末端的时间进行调度,本题描述的就是最晚截止期调度算法。 4)最早截止期调度算法:指调度程序按每个任务的截止期时间,选择最早到截止期的头端时间的任务进行调 度。
实时系统的正确性依赖于运行结果的逻辑正确性和运行结果产生的时间正确性,即实时系统必须在规定的时间范围内正确地响应外部物理过程的变化。 实时多任务操作系统是根据操作系统的工作特性而言的。实时是指物理进程的真实时间。实时操作系统是指具有实时性,能文持实时控制系统工作的操作系统。首要任务是调度一切可利用的资源来完成实时控制任务,其次才着眼于提高计算机系统的使用效率,重要特点是要满足对时间的限制和要求。一个实时操作系统可以在不破坏规定的时间限制的情况下完成所有任务的执行。任务执行的时间可以根据系统的软硬件的信息而进行确定性的预测。也就是说,如果硬件可以做这件工作,那么实时操作系统的软件将可以确定性地做这件工作。 实时操作系统可根据实际应用环境的要求对内核进行裁剪和重新配置,根据不同的应用,其组成有所不同。
一个嵌入式实时操作系统(RTOS)的评价要从很多角度进行,如体系结构、API的丰富程度、网络支持、可靠性等。其中,实时性是RTOS评价的最重要的指标之一。实时性的优劣是用户选择操作系统的一个重要参考。严格地说,影响嵌入式操作系统实时性的因素有很多,如常用系统调用平均运行时间、任务切换时间、线程切换时间、信号量混洗时间(指从一个任务释放信号量到另一个等待该信号量的任务被激活的时间延迟)、中断响应时间和任务执行时间不是反映RTOS实时性的评价指标。
混成系统:一般由离散分离组件和连续组件并行或串行组成,组件之间的行为由计算模型进行控制。
微内核相比于传统内核,效率较差。D选项的叙述是错误的。 采用微内核结构的操作系统与传统的操作系统相比,其优点是提高了系统的灵活性、可扩充性,增强了系统的可靠性,提供了对分布式系统的支持。其原因如下: ① 灵活性和可扩展性:由于微内核OS的许多功能是由相对独立的服务器软件来实现的,当开发了新的硬件和软件时,微内核OS只须在相应的服务器中增加新的功能,或再增加一个专门的服务器。与此同时,也必然改善系统的灵活性,不仅可在操作系统中增加新的功能,还可修改原有功能,以及删除已过时的功能,以形成一个更为精干有效的操作系统。 ② 增强了系统的可靠性和可移植性:由于微内核是出于精心设计和严格测试的,容易保证其正确性;另一方面是它提供了规范而精简的应用程序接口(API),为微内核外部的程序编制高质量的代码创造了条件。此外,由于所有服务器都是运行在用户态,服务器与服务器之间采用的是消息传递通信机制,因此,当某个服务器出现错误时,不会影响内核,也不会影响其他服务器。另外,由于在微内核结构的操作系统中,所有与特定CPU和I/O设备硬件有关的代码,均放在内核和内核下面的硬件隐藏层中,而操作系统其他绝大部分(即各种服务器)均与硬件平台无关,因而,把操作系统移植到另一个计算机硬件平台上所需作的修改是比较小的。 ③ 提供了对分布式系统的支持:由于在微内核OS中,客户和服务器之间以及服务器和服务器之间的通信,是采用消息传递通信机制进行的,致使微内核OS能很好地支持分布式系统和网络系统。事实上,只要在分布式系统中赋予所有进程和服务器唯一的标识符,在微内核中再配置一张系统映射表(即进程和服务器的标识符与它们所驻留的机器之间的对应表),在进行客户与服务器通信时,只需在所发送的消息中标上发送进程和接收进程的标识符,微内核便可利用系统映射表,将消息发往目标,而无论目标是驻留在哪台机器上。
软件设计层面的功耗控制主要可以从以下方面展开 1)软硬件协同设计,即软件的设计要与硬件匹配,考虑硬件因素。 2)编译优化,采用低功耗优化的编译技术。 3)减少系统的持续运行时间,可从算法角度进行优化。 4)用“中断"代替“查询” 5)进行电源的有效管理,
板级支持包(BSP,也称为硬件抽象层HAL)一般包含相关底层硬件的初始化、数据的输入输出操作和硬件设备的配置等功能,它主要具有以下两个特点。 ①硬件相关性,因为嵌入式实时系统的硬件环境具有应用相关性,而作为上层软件与硬件平台之间的接口,BSP需为操作系统提供操作和控制具体硬件的方法。 ②操作系统相关性,不同的操作系统具有各白的软件层次结构,因此不同操作系统具有特定的硬件接口形式。
- 存储器分类
(1)随机存取存储器(RandomAccessMemory,RAM)。工作需要持续电力提供,可随机读写。 1)动态随机存取存储器(DynamicRAM,DRAM),采用电容存储信息,优点是集成度高、容量大、成本低,缺点是访问速度较慢、需要定期刷新。常作主存。 2)静态随机存取存储器(StaticRAM,SRAM),采用多个晶体管自锁的方式保存状态,优点是访问速度快、不需要刷新,缺点是集成度低、容量小、成本高。常用作高速缓存。
(2)只读存储器(ReadOnlyMemory,ROM),存储的数据不会因掉电而丢失,读取的速度比RAM快,常见的有以下几种:
1)掩膜型只读存储器(MaskProgrammedROM,MROM),优点是通过掩膜大批量制造、成本低,缺点是同批数据全部一致且不可修改,只适合大批量生产。 2)可编程只读存储器(ProgrammableROM,PROM),可以用专用编程设备一次性烧录数据,适合少量制造。 3)可擦可编程只读存储器(ErasableProgrammableROM,EPROM),优点是写入的数据可以通过紫外线擦除重写。 4)电可擦可编程只读存储器(Electrically Erasable Programmable ROM,EEPROM),优点是写入的数据可以通过电压来清除,但是清除的速度很慢。 5)快闪存储器(Flash Memory),优点是可以联机擦写数据且擦写的次数多、速度快,缺点是读取的速度慢(相对其他 ROM 的速度而言)。
(3)内(外)总线逻辑。
1)根据传输的信息种类分类,可分为以下几种。 ① 数据总线,用于传送需要处理或者需要存储的数据。 ② 地址总线,用于指定在RAM之中存储的数据的地址。 ③ 控制总线,将微处理器控制单元的信号传送到周边设备。
2)根据连接部件分类,可分为以下几种。 ① 片内总线,连接芯片内部各元件。 ② 系统总线或板级总线,连接计算机系统的核心组件。 ③ 局部总线,连接局部少数组件。 ④ 通信总线,主机连接外设的总线。各类总线在嵌入式系统的位置如图2.2所示。
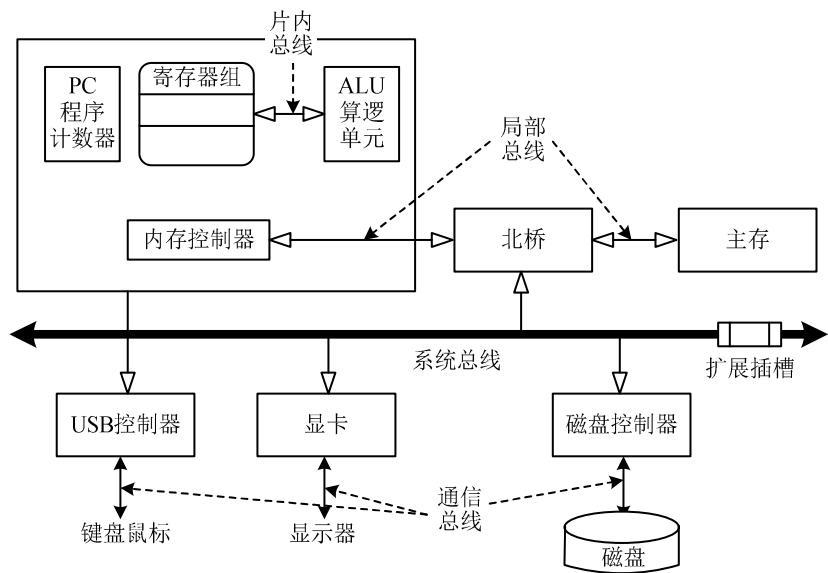
图2.2 各类总线在嵌入式系统的位置
3)按照数据传输的方向,总线可以分为单工总线和双工总线。单工总线只能从一端向另一端传输而不能反向;双工总线能在两个方向传输。双工总线又分为半双工总线和全双工总线。半双工总线只能轮流向两个方向传输;全双工总线可以同时在两个方向传输。
4)按照总线使用的信号类型,总线可以分为并行总线和串行总线。并行总线包含多位传输线,在同一时刻可以传输多位数据,但一致性要求高,传输距离较近;而串行总线只使用一位传输线,同一时刻只传输一位数据,但距离可以较远。
(4)看门狗电路,是嵌入式系统必须具备的一种系统恢复能力,可防止程序出错或者死锁。主要由输入端、寄存器、计数器和狗叫模块构成。通过寄存器对看门狗进行基本设置,计数器计算狗叫时间,狗叫模块决定看门狗超时后发出的中断或复位方式。程序正常运行时MCU会在输入端定期喂狗,超时不喂狗就会触发狗叫模块,一般是重启MCU。
(5)嵌入式数据库
基于网络的数据库系统(Netware Database System,NDB)是基于4G/5G的移动通信之上,主要由客户端、通信协议和远程服务器等三部分组成。 1)NDB的客户端主要负责提供接口给嵌入式程序,在逻辑上可以把嵌入式设备看作远程服务器的一个客户端; 2)通信协议负责规范客户端与远程服务器之间的通信; 3)远程服务器负责维护服务器上的数据库数据。
嵌入式系统的数据库系统称为嵌入式数据库系统或嵌入式实时数据库系统,就是在嵌入式设备上使用的DBMS。由于用到EDBMS的嵌入式系统多是移动信息设备,例如,掌上电脑、PDA、车载设备等移动通信设备,位置固定的嵌入式设备很少用到,因此,嵌入式数据库也称为移动数据库或嵌入式移动数据库。EDBMS的作用主要是解决移动计算环境下数据的管理问题,移动数据库是移动计算环境中的分布式数据库。嵌入式数据库管理系统一般只提供本机服务接口且只为前端应用提供基本的数据支持。
2.5 安全攸关软件的安全性设计
【基础知识点】
- 定义
IEEE定义安全攸关软件是用于一个系统中,可能导致不可接受的风险的软件。
安全攸关系统:是指系统失效会对生命或者健康构成威胁的系统,存在于航空、航天、汽车、轨道交通等领域,对安全性要求很高。通常在需求分析阶段就必须考虑安全性需求了安全性需求:是指通过约束软件的行为,使其不会出现不可接受的违反系统安全的行为需求。所以第一空选择C选项。选项A中,不会出现系统安全的行为,这种说法本身就是错误的:B选项是对可靠性的说明:D选项事故是系统不安全的后果。需求本身就是根据已知的系统信息来进行获取的,所以第二空选择A选项,系统信息。
- DO-178B标准
该标准的目的是为制造机载系统和设备的机载软件提供指导,使其能够提供在满足符合适航要求的安全性水平下完成预期功能。DO-178B标准将软件生命周期分为软件计划过程、软件开发过程和软件综合过程,其中软件开发过程细分为软件需求过程、软件设计过程、软件编码过程和集成过程4个子过程;软件综合过程细分为软件验证过程、软件配置管理过程、软件质量保证过程、审定联络过程4个子过程。DO-178B根据软件在系统中的重要程度将软件的安全等级分为 $\mathrm{A}\sim \mathrm{E}$ 五级,分别对应灾难级(A)、危害级(B)、严重级(C)、不严重级(D)和没有影响级(E)。
2.6 练习题
- 在嵌入式系统的存储部件中,存取速度最快的是()
A.内存 B.寄存器组C. Flash D. Cache
解析:存储速度从快到慢分别是:寄存器组、Cache、内存、Flash。
答案:B
- 以下关于嵌入式系统硬件抽象层的叙述,错误的是()
A.硬件抽象层与硬件密切相关,可对操作系统隐藏硬件的多样性 B.硬件抽象层将操作系统与硬件平台隔开 C.硬件抽象层使软硬件的设计与调试可以并行 D.硬件抽象层应包括设备驱动程序和任务调度
解析:硬件抽象层是位于操作系统内核与硬件电路之间的接口层,其目的在于将硬件抽象化。它隐藏了特定平台的硬件接口细节,为操作系统提供虚拟硬件平台,使其具有硬件无关性,可在多种平台上进行移植。在基于硬件抽象层的开发中,软硬件的设计和调试具有无关性,并可完全地并行进行。硬件的错误不会影响到系统软件的调试,同样,软件设计的错误也不会影响硬件。
答案:D
- 以下描述中,()不是嵌入式操作系统的特点。
A. 面向应用,可以进行裁剪和移植
B. 用于特定领域,不需要支持多任务
C. 可靠性高,无须人工干预独立运行,并处理各类事件和故障
D. 要求编码体积小,能够在嵌入式系统的有效存储空间内运行
解析:嵌入式操作系统是应用于嵌入式系统,实现软硬件资源的分配,任务调度,控制、协调并发活动等的操作系统软件。它除了具有一般操作系统最基本的功能如多任务调度、同步机制等之外,通常还会具备以下适用于嵌入式系统的特性:面向应用,可以进行检查和移植,以支持开放性和可伸缩性的体系结构;强实时性,以适应各种控制设备及系统;硬件适用性,对于不同硬件平台提供有效的支持并实现统一的设备驱动接口;高可靠性,运行时无须用户过多干预,并处理各类事件和故障;编码体积小,通常会固化在嵌入式系统有限的存储单元中。
答案:B
- 嵌入式系统设计一般要考虑低功耗,软件设计也要考虑低功耗设计,软件低功耗设计一般采用()。
A. 结构优化、编译优化和代码优化
B. 软硬件协同设计、开发过程优化和环境设计优化
C. 轻量级操作系统、算法优化和仿真实验
D. 编译优化技术、软硬件协同设计和算法优化
解析:软件设计层面的功耗控制可以从以下几个方面展开:
(1)软硬件协同设计,即软件的设计要与硬件的匹配,考虑硬件因素。(2)编译优化,采用低功耗优化的编译技术。(3)减少系统的持续运行时间,可从算法角度进行优化。(4)用中断代替查询。(5)进行电源的有效管理。
答案:D
- 以下关于嵌入式系统开发的叙述,正确的是()。
A. 宿主机与目标机之间只需要建立逻辑连接
B. 宿主机与目标机之间只能采用串口通信方式
C. 在宿主机上必须采用交叉编译器来生成目标机的可执行代码
D. 调试器与被调试程序必须安装在同一台机器上
解析:在嵌入式系统开发中,由于嵌入式设备不具备足够的处理器能力和存储空间,程序开发一般用PC(宿主机)来完成,然后将可执行文件下载到嵌入式系统(目标机)中运行。
当宿主机与目标机的机器指令不同时,就需要交叉工具链(指编译、汇编、链接等一整套工具)。
答案:C
第3小时 计算机网络基础知识
3.0 章节考点分析
第3小时主要学习计算机网络的基本概念、通信技术、网络技术、组网技术和网络工程等内容。根据考试大纲,本小时知识点会涉及单项选择题,按出题规律约占5分。本小时内容属于基础知识范畴,除了书本上的知识以外,也有一些扩展知识。本小时知识架构如图3.1所示。
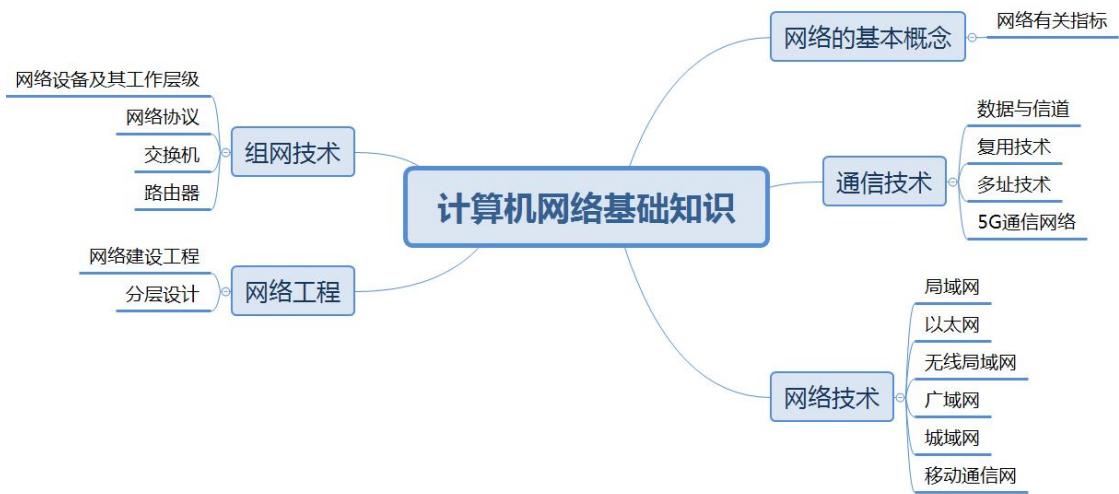
图3.1 本小时知识架构
【导读小贴士】
尽管计算机网络是计算机系统信息共享和信息传输必不可少的重要组成部分,大量的高级架构知识如分布式、高并发、面向服务、微服务、云原生等均与网络密不可分,但是这一小时的内容不作为考试学习研究的重点。计算机网络有独立的考试科目,就系统架构设计师考试来说范围过于广泛,重点很难把握,因此本章只对必要考点进行梳理,希望广大考生能有的放矢地复习。
3.1 网络的基本概念
【基础知识点】
跟网络有关的指标分为:
(1)性能指标:从速率、带宽、吞吐量和时延等不同方面来度量计算机网络的性能。 (2)非性能指标:从费用、质量、标准化、可靠性、可扩展性、可升级性、易管理性和可维护性等来度量。
3.2 通信技术
【基础知识点】
(1)数据与信道:在通信中的数据包括模拟信号和数字信号,通过信道来传输,信息传输就是信源和信宿通过信道收发信息的过程。信道可分为逻辑信道和物理信道。逻辑信道是指在数据发送端和接收端之间存在的一条虚拟线路,可以是有连接的或无连接的,以物理信道为载体。信号在信源端和信宿端都需要经过信号变换,中间经过编码、交织、调制和解码等过程。 (2)复用技术:是指在一条信道上同时传输多路数据的技术,如TDM时分复用、FDM频分复用和CDM码分复用等。即一条路上行驶多辆货车。 (3)多址技术:是指在一条线上同时传输多个用户数据的技术,在接收端把多个用户的数据分离,如TDMA时分多址、FDMA频分多址和CDMA码分多址等。即一辆车上的货物属于不同用户。 (4)5G通信网络。作为新一代的移动通信技术,网络结构、网络能力和应用场景等都与过去有很大不同,具有高速率、低时延、接入用户数高等优点。5G网络的切片技术是将5G网络分割成多张虚拟网络,从而支持更多的应用。就是将一个物理网络切割成多个虚拟的端到端的网络,每个虚拟网络之间,包括网络内的设备、接入、传输和核心网,是逻辑独立的,任何一个虚拟网络发生故障都不会影响到其他虚拟网络。在一个网络切片中,至少可分为无线网子切片、承载网子切片和核心网子切片三部分。
3.3 网络技术
【基础知识点】
| 类型 | 英文名称 / 标准 | 定义与特点 | 拓扑结构 / 层次结构 | 主要技术或子标准 | 典型速率 / 特性 |
|---|---|---|---|---|---|
| 局域网(LAN) | Local Area Network | 在有限地理范围内将计算机互联的封闭型网络 | 总线型、星型、树型、环型、网状型 | — | 适用于办公室、校园、企业等局部环境 |
| 以太网(Ethernet) | IEEE 802.3 | 一种最常用的局域网组网技术 | — | 以太网帧长:最小 64 字节,最大 1518 字节 | 最小帧长设定用于避免冲突 |
| 无线局域网(WLAN) | IEEE 802.11(a/b/g/n/ac) | 利用无线技术在空中传输数据、语音、视频 | 点对点型、Hub型、完全分布型 | 802.11n、802.11ac 等 | 802.11n:200 Mb/s;802.11ac:1 Gb/s |
| 广域网(WAN) | Wide Area Network | 连接分布于广域范围的计算机设备 | — | 通信子网、资源子网 | 相关技术:SONET、SDH、DDN、FR、ATM |
| 城域网(MAN) | IEEE 802.6 | 建立在单个城市范围内的计算机通信网 | 核心层、汇聚层、接入层 | — | 连接多个局域网,服务于城市范围 |
| 移动通信网 | 1G–5G | 实现移动终端通信的蜂窝网络 | — | 服务化架构(SBA)、网络切片技术 | 1G–5G演进:1G模拟 → 2G数字 → 3G扩频 → 4G高速 → 5G多技术融合 5G支持FlexE硬切片与网络功能定制 |
(1)局域网(LAN)。是指在有限地理范围内将若干计算机通过传输介质互联成的封闭型的计算机网络。局域网有总线型、星型、树型、环型、网状五种拓扑结构,如图3.2所示。

图3.2 根据网络拓扑结构分类
(2)以太网(Ethernet)。是一种计算机局域网组网技术,由IEEE802.3定义。以太网数据帧的最小长度必须不小于64字节,最大长度一般是1518字节。设置最小帧长是为了避免冲突,最小帧长是根据网络中检测冲突的最长时间来定的。 (3)无线局域网(Wireless Local Area Networks,WLAN)。利用无线技术在空中传输数据、话音和视频信号。WLAN采用IEEE802.11标准,有a、b、g、n、ac等子标准,802.11n传输速率可达 $200\mathrm{Mb / s}$ ,802.11ac则可达1Gb/s。WLAN拓扑结构有点对点型、Hub型和完全分布型。点对点型用于网络互联和延长;Hub型用于终端接入;完全分布型则处于理论探讨阶段无具体应用。 (4)广域网(WAN)。是一种将分布于更广区域的计算机设备联接起来的网络,需要使用路由器和网关设备。广域网由通信子网与资源子网组成。广域网可以分为公共传输网络、专用传输网络和无线传输网络3类。广域网相关技术有同步光网络(SONET)、同步数字体系(SDH)、数字数据网(DDN)、帧中继(FR)和异步传输技术(ATM)。 (5)城域网(Metropolitan Area Network,MAN)。是在单个城市范围内所建立的计算机通信网,采用IEEE802.6标准。通常分为3个层次:核心层、汇聚层和接入层。 (6)移动通信网。其发展经历了1G模拟信号传输、2G数字通信技术、3G扩展频谱、4G快速发展繁荣、5G多业务、多技术融合等5代。5G网络的主要特征为服务化架构和网络切片。
1)服务化架构(Service-Based Architecture,SBA) 可以实现网络功能的灵活定制和按需组合,以及软件快速迭代和升级。 2)网络切片技术可以在单个物理网络中切分出多个分离的逻辑网络用于不同业务。5G还引入了基于灵活以太网(Flexible Ethernet,FlexE)的硬切片技术。
将计算机中的数字数据在网络中用模拟信号表示时,需要进行调制,也就是要进行波形变换,或者是频谱变换,将数字信号的频谱变换成适合于在模拟信道中传输的频谱。最基本的调制方法有调幅、调频和调相3种。 (1)调幅 调幅 (Amplitude Modulator,AM) 即载波的振幅随着基带数字信号而变化,例如数字信号1用有载波输出表示数字信号0用无载波输出表示。这种调幅的方法又称为幅移键控(Ampliude Shift Keying,ASK),其特点是信号 容易实现,技术简单,但抗干扰能力差。 (2)调频 调频(Frequency Modulator,FM) 即载波的频率随着基带数字信号而变化,例如数字信号1用频率f,表示,数字信号0用频率f,表示。这种调频的方法又叫频移键控(Frequency Shift Keying,FSK),其特点是信号容易实现,技术简单,抗干扰能力较强。 (3)调相 调相(Phase Modulator,PM) 即载波的初始相位随着基带数字信号而变化,例如数字信号1对应于相位180°,数字信号0对应于相位0°。这种调相的方法又叫相移键控(Phase Shit Keying,PSK) ,其特点是抗干扰能力较强但信号实现的技术比较复杂。
3.4 组网技术(网络协议、路由器、OSI/RM)
【基础知识点】
- 网络设备及其工作层级
(1)集线器(Hub)和中继器(Repeater)工作在物理层。 (2)网桥(Bridge)和交换机(Switcher)工作在数据链路层。 (3)路由器(Router)和防火墙(Firewall)主要工作在网络层。防火墙是网络中一种重要的安全设备,作为网络对外的门户。
- 网络协议
OSI/RM七层模型见表3.1。
表3.1 OSI/RM七层模型的主要功能和详细说明
| 层级 | 名称 | 主要功能 | 典型设备 / 协议 / 数据单元 | 举例说明 |
|---|---|---|---|---|
| 第7层 | 应用层 | 为应用程序提供网络服务接口 | HTTP、FTP、SMTP、DNS、Telnet | 浏览网页、发送邮件 |
| 第6层 | 表示层 | 数据格式转换、加密解密、压缩 | SSL/TLS、JPEG、MPEG、ASCII | 数据加密传输、视频播放 |
| 第5层 | 会话层 | 建立、管理、终止会话连接 | RPC、NetBIOS、SQL 会话 | 登录远程主机、视频会议会话控制 |
| 第4层 | 传输层 | 提供端到端通信、可靠传输 | TCP、UDP、SPX | 分段重组、端口通信(80、443等) |
| 第3层 | 网络层 | 路由选择、逻辑寻址(IP) | IP、ICMP、ARP、OSPF、RIP | 路由器IP 地址分配、数据包转发 |
| 第2层 | 数据链路层 | 成帧、差错检测、物理地址识别 | MAC、PPP、以太网、VLAN | 交换机转发帧、MAC 地址识别 |
| 第1层 | 物理层 | 比特传输、电气与机械特性定义 | 光纤、双绞线、中继器、集线器 | 电信号传输、硬件接口标准 |
防止阻塞的方法有: 1)在传输层可采用:重传策略、乱序缓存策略、确认策略、流控制策略和确定超时策略。 2)在网络层可采用:子网内部的虚电路与数据报策略、分组排队和服务策略、分组丢弃策略、路由算法和分组生存管理。 3)在数据链路层可采用:重传策略、乱序缓存策略、确认策略和流控制策略,
Internet协议的主要协议及其层次关系见表3.2。
表3.2 Internet协议的主要协议及其层次关系
| ISO/OSI 模型 | TCP/IP 协议 | 协议说明 | TCP/IP 模型 |
|---|---|---|---|
| 应用层 | FTP(文件传输协议) | 运行在 TCP 之上,用于两台计算机之间传送文件;建立两条 TCP 连接:控制端口 21,数据端口 20。 | 应用层 |
| TFTP(简单文件传输协议) | 基于 UDP(端口 69);无认证、无连接;使用超时重传确保数据到达。 | ||
| HTTP(超文本传输协议) | 用于浏览器与 WWW 服务器间传输网页内容;基于 TCP,端口 80。 | ||
| HTTPS(安全超文本传输协议) | HTTP + SSL/TLS 加密;确保传输安全;端口 443。 | ||
| SMTP(简单邮件传输协议) | 用于发送邮件,工作在 TCP 之上,端口 25。 | ||
| POP3(邮局协议第3版) | 用于接收邮件,客户端从服务器下载邮件;基于 TCP,端口 110。 | ||
| IMAP(互联网邮件访问协议) | 允许客户端在服务器上读取、同步、管理邮件,支持多设备访问;端口 143。 | ||
| DHCP(动态主机配置协议) | 自动分配 IP、网关、DNS 等信息;基于 UDP(客户端 68,服务器 67);客户端响应第一个 OFFER。 | ||
| DNS(域名系统) | 将域名解析为 IP 地址;PTR 记录用于反向解析(IP→域名);使用 UDP/TCP 端口 53。 | ||
| 表示层 | 合并入应用层 | TCP/IP 模型中不单独划分表示层 | ↑ 同上 |
| 会话层 | 合并入应用层 | TCP/IP 模型中不单独划分会话层 | ↑ 同上 |
| 传输层 | TCP(传输控制协议) / UDP(用户数据报协议) | TCP:面向连接、可靠传输;UDP:无连接、不可靠但开销小。 | 传输层 |
| 网络层 | IP / ICMP | IP:负责寻址与路由;ICMP:传递控制信息(如 ping)。 | 网际层 |
| 数据链路层 | Ethernet IEEE 802.3 / FDDI / Token-Ring | 负责帧封装与物理寻址(MAC 层功能)。 | 网络接口层 |
| 物理层 | 硬件层 | 负责比特流的物理传输(电信号、接口标准等)。 | ↑ 同上 |
这里根据考试大纲,列举一些常见的协议供广大考生学习。
(1)应用层协议。
1)文件传输协议(File Transport Protocol,FTP):是网络上两台计算机传送文件的协议,运行在TCP之上,是通过Internet将文件从一台计算机传输到另一台计算机的一种途径。FTP在客户机和服务器之间需建立两条 TCP 连接,一条用于传送控制信息(使用 21 号端口),另一条用于传送文件内容(使用 20 号端口)。 2)简单文件传输协议(Trivial File Transfer Protocol,TFTP):是用来在客户机与服务器之间进行简单文件传输的协议,提供不复杂、开销不大的文件传输服务。TFTP 建立在 UDP 之上,69 号端口;提供不可靠的数据流传输服务,不提供存取授权与认证机制,使用超时重传方式来保证数据的到达。 3)超文本传输协议(Hypertext Transfer Protocol,HTTP):是用于从 WWW 服务器传输超文本到本地浏览器的传送协议。HTTP 建立在 TCP 之上,使用 80 号端口。 4)安全超文本传输协议(Hypertext Transfer Protocol Secure,HTTPS):是以安全为目标的 HTTP 通道,在 HTTP 的基础上通过传输加密和身份认证保证了传输过程的安全性。HTTPS 在 HTTP 的基础下加入安全套接层(Secure Socket Layer,SSL)或 TLS,HTTPS 使用的 443 号端口。 5)动态主机配置协议(Dynamic Host Configuration Protocol,DHCP):通常被应用在大型的局域网络环境中,主要作用是集中地管理、分配 IP 地址,使网络环境中的主机动态地获得 IP 地址、网关地址、DNS 服务器地址等信息,并能够提升地址的使用率。在网络范围内可能存在多个 DHCP 服务器,各自负责不同的网段,也可能由同一个 DHCP 服务器,负责多个不同网段的地址分配。如果网络中有多个 DHCP 服务器发送 OFFER 报文,客户端只根据第一个收到的 OFFER 报文,返回 REQUEST 报文。 6)域名系统(Domain Name System,DNS):DNS 把主机域名解析为 IP 地址的系统,而 PTR(Pointer Record)负责将 IP 地址映射到域名的解析。
DNS 查询过程有两种方法,见表 3.3。
表3.3 DNS查询过程的两种方法
| 迭代查询 | 递归查询 |
| 查询得到的是其他服务器的引用,本地服务器就要访问被引用的服务器,做进一步的查询 | 查询方式要求服务器彻底地进行名字解析,并返回最后的结果 |
(2)传输层协议。
1)传输控制协议(Transmission Control Protocol,TCP)。TCP 是可靠的、面向连接的网络协议。具有差错校验和重传、流量控制、拥塞控制等功能。适用于数据量比较少,且对可靠性要求高的场合。 2)用户数据报协议(User Datagram Protocol,UDP)。UDP 是不可靠的、无连接的网络协议。UDP 适合数据量大,对可靠性要求不是很高,但要求速度快的场合。
TCP采用可变大小的滑动窗口协议进行流量控制。在前向纠错系统中,当接收端检测到错误后就根据纠错编码的规律自行纠错;在后向纠错系统中,接收端会请求发送端重发出错分组。IP协议不预先建立虚电路,而是对每个数据报独立地选择路由并一站一站地进行转发,直到送达目标地。
Web页面访问过程为: 1)我向浏览器中输入网址后,浏览器会校验网址的合法性,如果网址不合法,会传给默认的搜索引擎。如果网址合法并通过验证,浏览器会解析,得到协议(http或https)、域名、资源页面(比如首页等) 2)DNS查询 浏览器会先检查域名信息是否在缓存中,再检查域名是否在本地的Hosts文件中。如果还不在,那么浏览器会向DNS服务器发送一个查询请求,获得目标服务器的IP地址。 3)TCP封包及传输。 4)建立TCP连接后发起HTTP请求: 5)服务器接收请求并响应。
区分服务是为解决服务质量问题在网络上将用户发送的数据流按照它对服务质量的要求划分等级的一种协议。区分服务将具有相同特性的若干业务流汇聚起来,为整个汇聚流提供服务,而不是面向单个业务流来提供服务。每个IP分组都要根据其Q0S需求打上一个标记,这种标记称为DS码点,可以利用IPV4协议头中的服务类型字段,或者IPV6协议头中的通信类别字段来实现,这样就维持了现有的IP分组格式不变。
(3)网络层协议。
IPv6 被称为下一代互联网协议,IP 数据报的目的地址有单播、多播/组播、任播。IPv4 to IPv6 过渡技术主要有:双协议栈技术、隧道技术、NAT-PT 技术。
IPv6地址的格式前缀(FP)用于表示地址类型或子网地址,用类似于IPV4的CIDR表示方法表示。链路本地地址:前缀为1111 1110 10,用于同一链路的相邻节点间的通信。相当于IPv4的自动专用IP地址。为实现IP地址的自动配置,IPV6主机将MAC地址附加在地址前缀1111 1110 10之后,产生一个链路本地地址。
通常一台IPV6主机有多个IPv6地址,即使该主机只有一个单接口。一台IPV6主机可以同时拥有以下几种单点传送地址: 1)每个接口的链路本地地址: 2)每个接口的单播地址(可以是一个站点本地地址和一个或多个可聚集全球地址); 3)回环(loopback)接口的回环地址(::1); 此外,每台主机还需要时刻保持收听以下多点传送地址上的信息; 1)节点本地范围内所有节点组播地址(FF01::1); 2)链路本地范围内所有节点组播地址(FF02::1): 3)请求节点(solicited-node)组播地址(如果主机的某个接口加入请求节点组); 4)组播组组播地址(如果主机的某个接口加入任何组播组)。
在域名解析过程中,一般有两种查询方式:递归查询和迭代查询。 1)递归查询:服务器必须回答目标IP与域名的映射关系。 2)迭代查询:服务器收到一次迭代査询回复一次结果,这个结果不一定是目标IP与域名的映射关系,也可以是其他DNS服务器的地址。 递归查询会向下探索,最终返回答案,选代查询不会向下探索,会立即返回消息,可以只返回线索 在本题中,本地域名服务器向根域名服务器发出査询请求后,根域名服务器会一层一层的进行査询,,将最终结果告诉本地域名服务器,这种方式属于递归查询,这种方式增加了根域名服务器的负担,影响了性能。
- 交换机
交换机功能包括集线功能、中继功能、桥接功能、隔离冲突域功能。交换机协议有:
(1)生成树协议(STP),可以很好地解决链路环路问题。 (2)链路聚合协议,可以提升与邻接交换设备之间的端口带宽和提高链路可靠性。
1)交换机的初始MAC地址表为空 2)因为交换机接收到数据帧后,如果没有相应的表项,交换机会采用ARP泛洪操作,即广播方式进行转发。 3)因为交换机通过读取输入帧中的源地址来添加相应的MAC地址表项。 4)交换机的MAC地址表项是动态增长的。
- 路由器
路由功能由路由器(Router)来提供,包括异种网络互连、子网协议转换、数据路由、速率适配、隔离网络、报文分片和重组、备份和流量控制。路由器协议主要有:
(1)内部网关协议(Interior Gateway Protocol,IGP):指在一个自治系统(Autonomous System,AS)内运行的路由协议。 (2)外部网关协议(Exterior Gateway Protocol,EGP):指在AS之间的路由协议。EGP是为简单的树型拓扑结构设计的。 (3)边界网关协议(Border Gateway Protocol,BGP):Internet的网络规模庞大,网络情况复杂,EGP已不适用,在EGP的经验之上制定了新的网关协议即BGP,也是Internet上唯一的网关协议。
对等网络,即对等计算机网络,是一种在对等者(Peer)之间分配任务和工作负载的分布式应用架构,是对等计算模型在应用层形成的一种组网或网络形式。在对等网络中,由于采用总线式的连接,因此网络中的终端数量越多,终端所能够分配到的转发时隙就越小,所带来的延迟也就越大,A选项错误。 路由器一般采取存储转发方式,而交换机采取的是直接转发方式,相比存储转发方式,直接转发方式转发时延更小。因为存储转发方式需要对待转发的数据包进行重新拆包,分析其源地址和目的地址,再根据路由表对其进行路由和转发,而直接转发方式不对数据包的三层地址进行分析,因此路由器转发所带来的延迟要大于交换机。B选项错误。 数据在lnternet中传输时,由于互联网中的转发数据量大月所需经过的节点多,势必会带来更大的延迟。C选项错误。网络延迟= 处理延迟+排队延迟+发送延迟+传播延迟。如果不考虑网络环境,服务器的延迟的主要因素是队列延迟和磁盘IO延迟。D选项正确。
层次化路由的含义是指对网络拓扑结构和配置的了解是局部的,一台路由器不需要知道所有的路由信息,只需要了解其管辖的路由信息,层次化路由选择需要配合层次化的地址编码。而子网或超网就属于层次化地址编码行为。
管理距离是指一种路由协议的路由可信度。每一种路由协议按可靠性从高到低,依次分配一个信任等级,这个信任等级就叫管理距离。 为什么要出现管理距离这个技术呢? 在自治系统内部,如RIP协议是根据路径传递的跳数来决定路径长短也就是传输距离,而像EIGRP协议是根据路径传输中的带宽和延迟来决定路径开销从而体现传输距离的。这是两种不同单位的度量值,我们没法进行比较。为了方便比较,我们定义了管理距离。这样我们就可以统一单位从而衡量不同协议的路径开销从而选出最优路径。正常情况下,管理距离越小,它的优先级就越高,也就是可信度越高。对于两种不同的路由协议到一个目的地的路由信息,路由器首先根据管理距离决定相信哪一个协议。AD值越低,则它的优先级越高。 一个管理距离是一个从0-255的整数值,0是最可信赖的,而255则意味着不会有业务量通过这个路由。 由此可见,管理距离是与信任相关的,只有选项C是相符的。
3.5 网络工程(分层)
【基础知识点】
- 网络建设工程
可分为网络规划、网络设计和网络实施3个环节。
(1)网络规划以需求为导向,兼顾技术和工程可行性。
(2)网络设计包括逻辑设计和物理设计, 1)逻辑设计指网络结构设计、网络技术选型、IP地址和路由设计、网络冗余设计以及网络安全设计等; 2)物理设计指布线设计、机房设计、设备选型等。
网络的生命周期至少包括网络系统的构思计划、分析设计、实时运行和维护的过程。对于大多数网络系统来说,由于应用的不断发展,这些网络系统需要不断重复设计、实施、维护的过程。网络系统生命周期可以划分为5个阶段,实施这5个阶段的合理顺序是需求规范、通信规范、逻辑网络设计、物理网络设计、实施阶段。
1)需求分析阶段有助于设计者更好地理解网络应该具有什么功能和性能,最终设计出符合用户需求的网络,它为网络设计提供依据。网络需求分析包括网络总体需求分析、综合布线需求分析、网络可用性与可靠性分析、网络安全性需求分析,此外还需要进行工程造价估算 2)网络逻辑结构设计是体现网络设计核心思想的关键阶段,在这一阶段根据需求规范和通信规范,选择一种比较适宜的网络逻辑结构,并基于该逻辑结构实施后续的资源分配规划、安全规划等内容。逻辑网络设计利用需求分析和现有网络体系分析的结果来设计逻辑网络结构,最后得到一份逻辑网络设计文档,输出内容包括以下几点:
- 逻辑网络设计图
- IP地址方案
- 安全方案
- 招聘和培训网络员工的具体说明
- 对软硬件、服务、员工和培训的费用初步估计。
3)物理网络设计是对逻辑网络设计的物理实现,通过对设备的具体物理分布、运行环境等的确定,确保网络的物理连接符合逻辑连接的要求。在这一阶段,网络设计者需要确定具体的软硬件、连接设备、布线和服务。现有网络体系分析的工作目的是描述资源分布,以便于在升级时尽量保护已有投资,通过该工作可以使网络设计者掌握网络现在所处的状态和情况。物理网络设计是对逻辑网络设计的物理实现,通过对设备的具体物理分布、运行环境等确定,确保网络的物理连接符合逻辑连接的要求。输出如下内容:
- 网络物理结构图和布线方案
- 设备和部件的详细列表清单
- 软硬件和安装费用的估算
- 安装日程表,详细说明服务的时间以及期限
- 安装后的测试计划
- 用户的培训计划
网络冗余设计的目的就是避免网络组件单点失效造成应用失效; 负载分担是网络冗余设计中的一种设计方式,其通过并行链路提供流量分担来提高性能;网络中存在备用链路时,可以考虑加入负载分担设计来减轻主路径负担。 备用路径是在主路径失效时启用,其和主路径承担不同的网络负载;
RAID5用N块盘时,实际可用容量=单盘容量x(N-1)。3块80G盘时,容量=80x(3-1)=160G2.不同容量盘做RAID 5时,以最小盘为准。2块80G和1块40G,相当于3块40G盘,容量=40x(3-1)=80G。
综合布线分六大子系统。
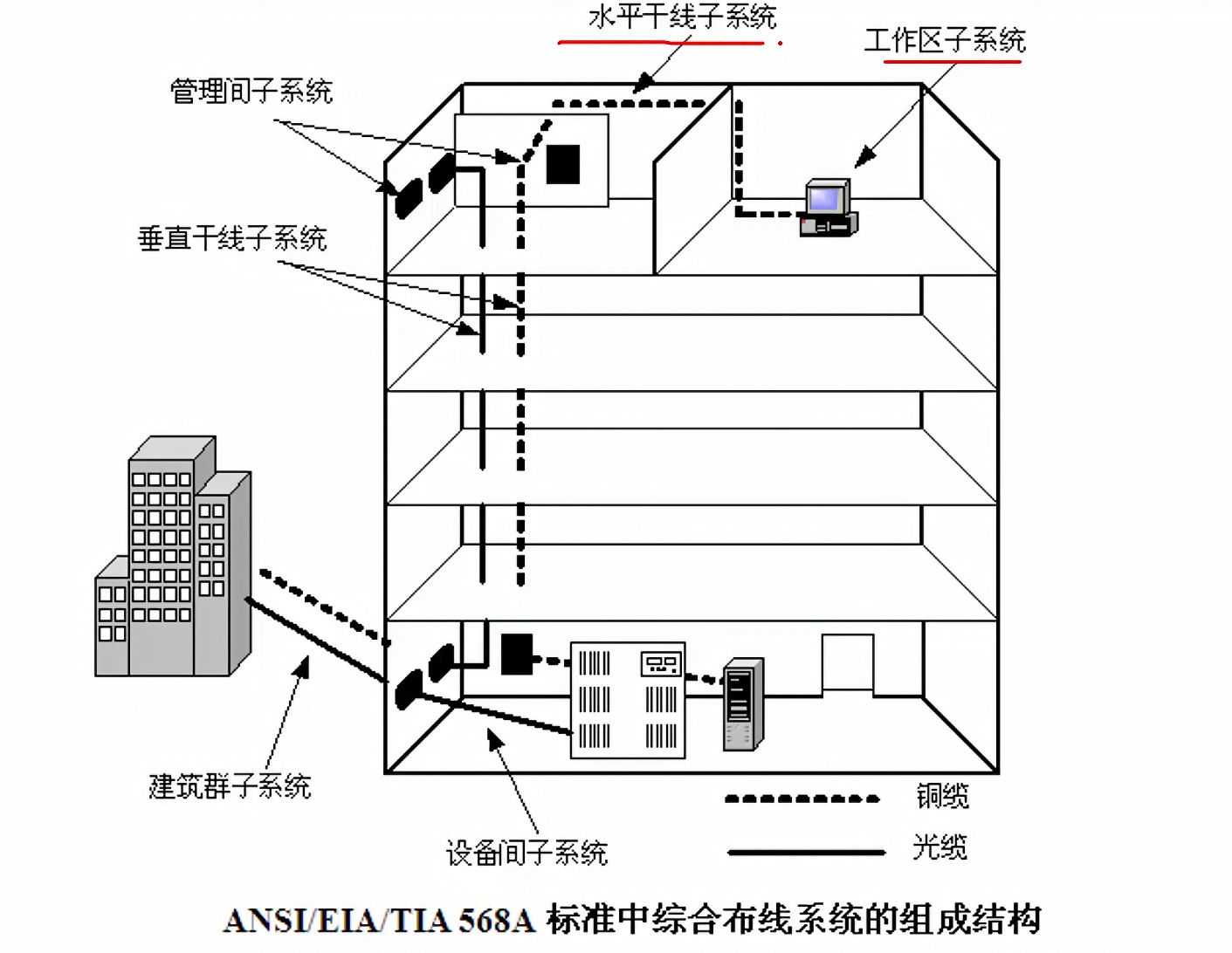
1)工作区子系统(Worklocation):目的是实现工作区终端设备与水平子系统之间的连接,由终端设备连接到信息插座的连接线缆所组成。工作区常用设备是计算机、网络集线器(Hub或Mau)、电话、报警探头、摄像机、监视器、音响等。 2)水平子系统(Horizontal):目的是实现信息插座和管理子系统(跳线架)间的连接,将用户工作区引至管理子系统,并为用户提供一个符合国际标准,满足语音及高速数据传输要求的信息点出口。该子系统由一个工作区的信息插座开始,经水平布置到管理区的内侧配线架的线缆所组成。水平子系统是指从楼层管理间到信息插口这一段,它连接了垂直干线子系统与工作区子系统。 3)管理子系统(Administration):本子系统由交连、互连配线架组成。管理间为连接其他子系统提供连接手段,。交连和互连允许将通讯线路定位或重新定位到建筑物的不同部分,以便能更容易地管理通信线路,使在移动终端设备时能方便地进行插拔。互连配线架根据不同的连接硬件分楼层配线架(箱)IDF和总配线架(箱)MDF,IDF可安装在各楼层的干线接线间,MDF一般安装在设备机房。 4)垂直干线子系统(Backbone):目的是实现计算机设备、程控交换机(PBX)、控制中心与各管理子系统间的连接,是建筑物干线电缆的路由。该子系统通常是两个单元之间,特别是在位于中央点的公共系统设备处提供多个线路设施。系统由建筑物内所有的垂直干线多对数电缆及相关支撑硬件组成,以提供设备间总配线架与干线接线间楼层配线架之间的干线路由。常用介质是大对数双绞线电缆和光缆。 5)设备室子系统(Equipment):本子系统主要是由设备间中的电缆、连接器和有关的支撑硬件组成,作用是将计算机、PBX、摄像头、监视器等弱电设备互连起来并连接到主配线架上。设备包括计算机系统、网络集线器(Hub)、网络交换机(Switch)、程控交换机(PBX)、音响输出设备、闭路电视控制装置和报警控制中心等 6)建筑群子系统(Campus):该子系统将一个建筑物的电缆延伸到建筑群的另外一些建筑物中的通信设备和装置上,是结构化布线系统的一部分,支持提供楼群之间通信所需的硬件。它由电缆,光然和入楼处的过流过压电气保护设备等相关硬件组成,常用介质是光缆。
网络存储
| 存储类型 | 连接方式 | 主要特点 | 优点 | 缺点 | 典型应用场景 |
|---|---|---|---|---|---|
| 直连式存储(DAS) | 存储设备通过 SCSI 接口电缆 直接连接服务器 | 服务器上外挂大容量硬盘,I/O请求直接发送到存储设备 | 结构简单、性能高、成本低 | 扩展性差、不支持容错;依赖服务器;不能跨平台共享文件;服务器故障易致数据丢失 | 中小型企业、单机系统、数据库本地磁盘存储 |
| 网络接入存储(NAS) | 存储设备 直接通过网络接口连接到局域网 | 内置 瘦操作系统(仅含访问控制、数据保护、恢复等功能),通过网络协议提供文件访问 | 易于部署;跨平台共享文件;可集中管理;采用 RAID 保护数据 | 传输效率受网络带宽限制;延迟高于 DAS | 文件共享服务器、备份中心、视频监控数据存储 |
| 存储区域网络(SAN) | 通过专用高速网络(如以太网(IP SAN)和光纤通道(FC SAN)) 连接存储设备和服务器 | 独立于数据网络的后端存储网络;专门负责数据传输与管理;提供企业级存储服务 | 高速传输;高可扩展性;集中化管理;支持容错与备份 | 成本高;部署复杂;维护要求高 | 数据中心、大型企业存储系统、云计算平台 |
1)开放系统的直连式存储(Direct-Attached Storage,DAS) 在服务器上外挂了一组大容量硬盘,存储设备与服务器主机之间采用SCSI通道连接,带宽为10MB/S、20MB/S、40MB/s和80MB/s等。直连式存储直接将存储设备连接到服务器上,这种方法难以扩展存储容量,而且不支持数据容错功能,当服务器出现异常时会造成数据丢失。DAS(DirectAtached Storage,直接附加存储) 即直连方式存储。在这种方式中,存储设备是通过电缆(通常是SCSI接口电缆)直接连接服务器。1/0(输入/输出)请求直接发送到存储设备。DAS也可称为SAS(Server-Attached Storage,服务器附加存储)。它依赖于服务器,其本身是硬件的堆,不带有任何存储操作系统,DAS不能提供跨平台文件共享功能,各系统平台下文件需分别存储。 2)网络接入存储(Network Atached Storage,NAS) 是将存储设备连接到现有的网络上,提供数据存储和文件访问服务的设备。NAS服务器是在专用主机上安装简化了的瘦操作系统(只具有访问权限控制、数据保护和恢复等功能)的文件服务器。NAS服务器内置了与网络连接所需要的协议,可以直接联网,具有权限的用户都可以通过网络访问NAS服务器中的文件。在NAS存储结构中,存储系统不再通过I/0总线附属于某个特定的服务器或客户机,而是直接通过网络接口与网络直接相连,由用户通过网络来访问。NAS设备有自己的OS,其实际上是一个带有瘦服务器的存储设备,其作用类似于一个专用的文件服务器,不过把显示器、键盘、鼠标等设备省去,NAS用于存储服务,可以大大降低存储设备的成本,另外NAS中的存储信息都是采用RAID方式进行管理的,从而有效的保护了数据。 3)存储区域网络(Storage Area NetworK,SAN) 是一种连接存储设备和存储管埋子系统的专用网络,专门提供数据存储和管理功能。SAN可以被看作是负责数据传输的后端网络,而前端网络(或称为数据网络)则负责正常的TCP/IP传输。也可以把SAN看作是通过特定的互连方式连接的若干台存储服务器组成的单独的数据网络,提供企业级的数据存储服务。 未来的信息存储将以SAN存储方式为主。SAN 主要采取数据块的方式进行数据和信息的存储,目前主要使用于以太网(IP SAN)和光纤通道(FC SAN)两类环境中
(3)网络实施包括工程实施计划、网络设备验收、设备安装和调试、系统试运行和切换、用户培训等。
- 分层设计
网络设计一般采用分层的方式,分为接入层、汇聚层、核心层
(1)接入层:直接面向用户连接或访问网络的部分,主要解决相邻用户之间的互访需求,并且为这些访问提供足够的带宽,接入层还应当适当负责一些用户管理功能(如地址认证、用户认证、计费管理等),以及用户信息收集工作(如用户的IP地址、MAC地址、访问日志等)。 (2)汇聚层:是核心层和接入层的分界面,完成网络访问策略控制、数据包处理、过滤、寻址,以及其他数据处理的任务。汇聚层的存在与否要视网络规模大小而定。 (3)核心层:网络主干部分称为核心层,核心层的主要目的在于通过高速转发通信,提供优化、可靠的骨干传输结构,因此,核心层交换机应拥有更高的可靠性、性能和吞吐量。核心层的设备采用双机冗余热备份是非常必要的,也可以使用负载均衡功能来改善网络性能。
进行网络层次化设计时,一般分为核心层、汇聚层、接入层三个层次。为了保证网络的层次性,不能在设计中随意加入额外连接、除去接入层,其他层次应尽量采用模块化方式,块间的边界应非常清晰。应是先从接入层开始设计,然后逐级往核心层走。原因是接入层其实代表了需求,是因为进行层次化网络设计时,有大量终端设备要接入,并有速度上的要求,才有了汇聚层要达到什么要求,核心层得怎么设计。选项B的说法本末倒置了,
3.6 练习题
- 在以太网标准中规定的最小帧长是(1)字节。最小帧长是根据(2)来定的。
(1)A.20 B.64 C.128 D.1518
(2)A.网络中传送的最小信息单位 B.物理层可以区分的信息长度 C.网络中发生冲突的最短时间 D.网络中检测冲突的最长时间
解析:以太网规定最小帧长为64字节,最大帧长为1518字节。设置最小帧长是为了避免冲突,最小帧长是根据网络中检测冲突的最长时间来定的。
答案:B D
- TCP和UDP协议均提供了( )能力。
A.连接管理 B.差错校验和重传 C.流量控制 D.端口寻址
解析:TCP与UDP均有端口号的概念。
TCP采用连接管理、差错校验和重传、流量控制等方式来确保数据按序、无差错、无重复、没有部分丢失地传输。
UDP是一种无连接的协议,适用于传输数据量大,对可靠性要求不高,传输速度快的场合。
答案:D
- 下列无线网络技术中,覆盖范围最小的是(
A.802.15.1蓝牙 B.802.11n无线局域网 C.802.15.4ZigBee D.802.16m无线城域网
解析:蓝牙的覆盖范围大约在10米以内,802.11n无线局域网的覆盖范围在100米以内,ZigBee的覆盖范围在 $10\sim 100$ 米之间, $802.16\mathrm{m}$ 无线城域网的覆盖范围在 $2\sim 10\mathrm{km}$ 。4个选项中,蓝牙覆盖范围最小。
答案:A
- 以下关于网络冗余设计的叙述中,错误的是(
A.网络冗余设计避免网络组件单点失效造成应用失效 B.备用路径与主路径同时投入使用,分担主路径流量 C.负载分担是通过并行链路提供流量分担来提高性能的 D.网络中存在备用链路时,可以考虑加入负载分担设计
解析:网络冗余设计的目的就是避免网络组件单点失效造成应用失效;备用路径是在主路径失效时启用,其和主路径承担不同的网络负载;负载分担是网络冗余设计中的一种设计方式,其通过并行链路提供流量分担来提高性能;网络中存在备用链路时,可以考虑加入负载分担设计来减轻主路径负担。
答案:B
第2篇 架构设计专业知识
第4小时 信息系统基础知识
4.0 章节考点分析
第4小时主要学习信息系统概述、信息化的典型应用、典型信息系统架构模型等内容。
本小时内容属于基础知识范畴,根据考试大纲及以往全国计算机技术与软件专业技术资格(水平)考试的出题规律,本小时知识点会涉及单项选择题,约占2~6分,本小时知识架构如图4.1所示。
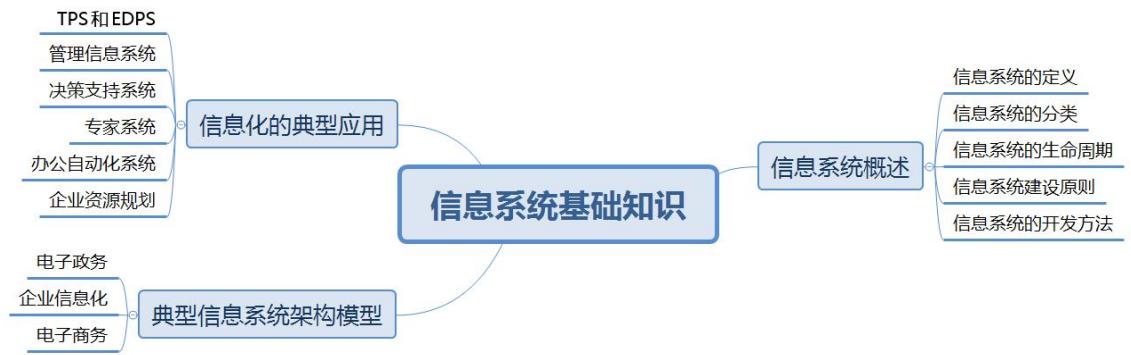
图4.1 本小时知识架构
【导读小贴士】
在系统架构设计师考试中,信息化和信息系统的基础知识也是必不可少的。本小时的知识通用性强,掌握了这些知识,对学习其他软考科目也是有益处的,难度不大,充分理解记忆即可。
4.1 信息系统概述
【基础知识点】
- 信息系统的定义
信息系统是由计算机软硬件、网络和通信设备、信息资源、用户和规章制度组成的以处理信息流为目的的人机一体化系统。信息系统的功能有:输入、存储、处理、输出和控制。理查德·诺兰(Richard L. Nolan)将信息系统的发展道路划分为初始、传播、控制、集成、数据管理和成熟6个阶段。
一般说来,信息化需求包含3个层次,即:战略需求、运作需求和技术需求。 1)战略需求。组织信息化的战略需求的目标是提升组织的竞争能力、为组织的可持续发展提供一个支持环境。从某种意义上来说,信息化对组织不仅仅是服务的手段和实现现有战略的辅助工具;信息化可以把组织战略提升到一个新的水平,为组织带来新的发展契机。特别是对于企业,信息化战略是企业竞争的基础。 2)运作需求。组织信息化的运作需求是组织信息化需求非常重要且关键的一环,它包含三方面的内容:一是实现信息化战略目标的需要:二是运营策略的需要;三是人才培养的需要。 3)技术需求。由于系统开发时间过长等问题在信息技术层面上对系统的完善、升级、集成和整合提出了需求。也有的组织,原来基本上没有大型的信息系统项目,有的也只是一些单机应用,这样的组织的信息化需求,一般是从头开发新的系统。
企业信息化一定要建立在企业战略规划基础之上,以企业战略规划为基础建立的企业管理模式是建立企业战略数据模型的依据。企业信息化就是技术和业务的融合。这个"合“并不是简单地利用信息系统对手工的作业流程进行自动化,而是需要从企业战略的层面、业务运作层面、管理运作层面这3个层面来实现。 企业信息化建设与其说是一场技术变革,还不如说是对企业的经营管理和业务流程的一次革命,它是借助于先进的信息技术和网络技术的价值链进行重构。同时,企业信息化是一个不断发展、变化的过程,它没有终点,至少目前还看不到终点。 企业信息化方法并不同于信息系统建设方法,这是因为信息系统建设方法是一个具体的信息项目建设的方法,而企业信息化方法是整个企业实现信息化的方法,因此,企业信息化方法要比信息系统建设方法层次更高、涉及面更广。
企业战略数据模型分为数据库模型和数据仓库模型, 1)数据库模型用来描述日常事务处理中的数据及其关系; 2)数据仓库模型则描述企业高层管理决策者所需信息及其关系。 在企业信息化过程中,数据库模型是基础,一个好的数据库模型应该客观地反映企业生产经营的内在联系。数据库是办公自动化、计算机辅助管理系统、开发与设计自动化、生产过程自动化、Intranet的基础和环境。
国家信息化体系包括信息技术应用、信息资源、信息网络、信息技术和产业、信息化人才、信息化法规政策和标准规范6个要素。 1)信息技术应用。 信息技术应用是指把信息技术广泛应用于经济和社会各个领域。信息技术应用是信息化体系六要素中的龙头,是国家信息化建设的主阵地。 2)信息资源。 信息资源、材料资源和能源共同构成了国民经济和社会发展的三大战略资源。信息资源的开发利用是国家信息化的核心任务,是国家信息化建设取得实效的关键,也是我国信息化的薄弱环节。 3)信息网络。 信息网络是信息资源开发利用和信息技术应用的基础,是信息传输、交换和共享的必要手段。目前,人们通常将信息网络分为电信网、广播电视网和计算机网。三种网络的发展方向是:互相融通、取长补短、逐步实现三网融合。 4)信息技术和产业。 信息技术和产业是我国进行信息化建设的基础。 5)信息化人才。 信息化人才是国家信息化成功之本,对其他各要素的发展速度和质量有着决定性的影响,是信息化建设的关键。 6)信息化政策法规和标准规范。 信息化政策法规和标准规范用于规范和协调信息化体系各要素之间关系,是国家信息化快速、持续、有序、健康发展的根本保障。
- 信息系统的分类
信息系统分为业务(数据)处理系统、管理信息系统、决策支持系统、专家系统、办公自动化系统、综合性信息系统等6类。
- 信息系统的生命周期
信息系统的生命周期分为产生、开发、运行和消亡4个阶段。
- 信息系统建设原则
信息系统建设原则可以分为高层管理人员介入原则、用户参与开发原则、自顶向下规划原则、工程化原则等。
- 信息系统的开发方法
| 方法分类 | 核心思想 / 特点 | 优点 | 缺点 | 适用场景 / 理解要点 |
|---|---|---|---|---|
| 自顶向下开发法 | 从最高层定义问题 → 分层细化 → 下层逐步实现。体现“整体先行、逐层求精”。 | ① 有助于整体规划与协调 ② 支持战略层决策 ③ 培养全局视角 | ① 对分析/设计人员要求高 ② 周期长、成本高 ③ 下层约束力弱 | 适用于大型系统的顶层设计与总体规划。如:ERP总体架构。 |
| 自底向上开发法 | 从已有模块、逻辑部件或相似系统出发 → 连接、扩展 → 构建完整系统。 | 快速、灵活、可复用 | 整体一致性弱 | 适用于小型系统或已有模块复用项目。类似“先造零件,再组系统”。 |
| ├─ 形式化方法 | 自底向上中的严格数学化开发方法。 用数学模型描述系统结构、逻辑与验证。 | 精确、可靠,可进行逻辑证明与验证 | 成本高、实施难度大 | 适用于高安全/高可靠性系统(如航天、核电、军工等)。 |
| └─ 非形式化方法 | 自底向上中的经验型、工程化方法。不追求数学严谨性。分为: ① 整体性方法(贯穿全生命周期) ② 局部性方法(针对某一阶段) | 灵活、易实践 | 缺乏精确验证 | 适用于一般性信息系统开发。 |
| 结构化方法(生命周期法) | 含结构化分析、结构化设计、结构化程序设计。核心:自顶向下、逐步求精、模块化设计。 | 目标清晰、阶段分明、文档规范 | 周期长、难应对需求变化、忽视数据结构 | 传统经典方法,适合数据处理型项目。 |
| 原型法(快速原型法) | 快速构建系统原型与用户交互,迭代改进需求。 | 沟通效率高、能早期验证需求 | 管理复杂易反复 | 适用于需求不确定或变化快的系统。 类型: ① 水平原型(界面展示) ② 垂直原型(功能实现) ③ 抛弃式(探索需求) ④ 演化式(逐步完善成最终系统)。 |
| 构件化开发方法(Component-Based Development) | 以可复用构件(组件) 为核心构建系统。构件来源:复用、提取、购买或重新开发。 | 提高复用率、缩短周期、降低成本 | 构件标准化与兼容性问题 | 适用于大型复杂系统或分布式系统。理解:像“拼积木造软件”。 |
软件开发方法是指软件开发过程所遭循的办法和步骤,从不同的角度可以对软件开发方法进行不同的分类。 从开发风范上看,可分为自顶向下的开发方法和自底向上的开发方法。(在实际软件开发中,大都是两种方法结合,只不过是应用于开发的不同阶段以何者为主而已) 1)自顶向下的开发:先对最高层次中的问题进行定义、设计、编程和测试,而将其中未解决的问题作为一个子任务放到下一层次中去解决。 自顶向下开发方法的优点是: ①可为企业或机构的重要决策和任务实现提供信息。 ②支持企业信息系统的整体性规划,并对系统的各子系统的协调和通信提供保证。 ③方法的实践有利于提高企业人员整体观察问题的能力,从而有利于寻找到改进企业组织的途径。 自顶向下开发方法的缺点是: ①对系统分析和设计人员的要求较高。 ②开发周期长,系统复杂,一般属于一种高成本、大投资的工程。 ③对于大系统而言自上而下的规划对于下层系统的实施往往缺乏约束力。 ④从经济角度来看,很难说自顶向下的做法在经济上是合算的。
2)自底向上的开发:根据系统功能要求,从具体的器件、逻辑部件或者相似系统开始,通过对其进行相互连接、修改和扩大,构成所要求的系统。 从性质上看,可分为形式化方法和非形式化方法。 1)形式化方法是一种具有坚实数学基础的方法,从而允许对系统和开发过程做严格处理和论证,适用于那些系统安全级别要求极高的软件的开发。 2)非形式化方法则不把严格性作为其主要着眼点,通常以各种开发型的形式得以体现。从适应范围来看,可分为整体性方法与局部性方法。适用于软件开发全过程的方法称为整体性方法;适用于开发过程某个具体阶段的软件方法称为局部性方法。
信息系统的开发方法主要有:结构化方法、原型法、面向对象方法、面向服务的方法、敏捷方法、构件化开发方法等。结构化方法、面向对象方法详见第7小时,这里介绍其他几种开发方法。
(1)结构化方法也称为生命周期法,是一种传统的信息系统开发方法,由结构化分析、 结构化设计和结构化程序设计三部分组成,其精髓是自顶向下、逐步求精和模块化设计。 结构化方法的主要特点是:开发目标清晰化、开发工作阶段化、开发文档规范化和设计方法结构化。结构化方法特别适合于数据处理领域的问题,但是不适应于规模较大、比较复杂的系统开发。结构化方法的缺点是开发周期长、难以适应需求的变化、很少考虑数据结构。
(2)原型法。原型法也称快速原型法,可以根据用户的初步需求利用系统工具快速建立一个系统模型,与用户交流。原型法按照实现功能划分可以分为: 1)水平原型:行为原型,用于界面。细化需求但并未实现功能。 2)垂直原型:结构化原型,用于复杂算法的实现,实现了部分功能。
原型法按照最终结果划分可以分为: 1)抛弃式:探索式原型,解决需求不确定性、二义性、不完整性、含糊性等。 2)演化式:逐步演化为最终系统,用于易于升级和优化的场合,适用于Web项目。
(3)构件化开发方法。基于构件/组件(Component)的软件开发是解决复杂环境下软件规模与复杂性的一种手段。构件并非一定包含类,一个类元素只能属于一个构件。构件的获取方式有:
1)从现有构件中获得符合要求的构件,直接使用或作适应性修改,得到可复用的构件。 2)通过遗留工程(Legacy Engineering),将具有潜在复用价值的构件提取出来,得到可复用的构件。 3)从市场上购买现成的商业构件。 4)开发新的符合要求的构件。
获取到的构件可以存放到构件库中,根据需求裁剪使用。构件的分类方式见表4.1。
表4.1 构件的分类方式
| 分类 | 具体描述 | 帮助理解 |
|---|---|---|
| 关键字分类法 | 通过分析找出使得企业成功的关键因素,然后再围绕这些关键因素来确定系统的需求并进行规划。通过对关键成功因素的识别,找出实现目标所需的关键信息集合,从而确定系统开发的优先次序。关键成功因素来自于组织的目标,通过组织的目标分解和关键成功因素识别、性能指标识别,一直到产生数据字典。 | 像词典目录一样,先有大类(如“通信”),再细分成“网络通信”“无线通信”等。层次分明、逻辑清晰。 |
| 刻面分类法 | 定义若干用于刻画构件特征的“刻面”(即维度),每个刻面包含若干概念,描述构件在该维度的特征。刻面可描述功能、数据、语境或其他特征。 | 像电商商品的多维筛选:按颜色、价格、品牌筛选构件,多维组合检索,灵活方便。 |
| 超文本方法 | 所有构件配有详尽功能/行为说明文档,并以网状链接方式连接相关概念或构件。检索者可按联想思维任意跳转,系统通过全文检索匹配关键字实现浏览式检索。 | 类似维基百科或网页超链接系统,可以自由点击跳转、联想式浏览,更符合人脑思维。 |
构件检索的方式也可以分为:基于关键字的检索、刻面检索法、超文本检索法。
(4)面向服务的方法。面向服务的方法是在面向对象方法的基础上发展起来的,对于跨构件的功能调用,则采用接口的形式暴露出来。进一步将接口的定义与实现进行解耦,则催生了服务和面向服务(Service-Oriented,SO) 的开发方法。以粗粒度、松散耦合和基于标准的服务为基础,增强了系统的灵活性、可复用性和可演化性。对于系统架构设计师考试我们重点关注的是面向服务的架构(SOA),这部分内容将在第18小时中介绍。
(5)面向对象方法是目前比较主流的开发方法。面向对象方法是系统的描述及信息模型的表示与客观实体相对应,符合人们的思维习惯,有利于系统开发过程中用户与开发人员的交流和沟通,缩短开发周期,提高系统开发的正确性和效率。可以把结构化方法和面向对象方法结合起来进行系统开发。首先使用结构化方法进行自顶向下的整体划分;然后再自底向上地采用面向对象方法开发系统。
(6)敏捷方法。敏捷方法是一种以人为核心、迭代、循序渐进的开发方法。敏捷方法主要有两个特点,这也是其区别于其他方法,尤其是重型方法的最主要的特征。 最小化软件工程工作产品以及整体精简开发。与传统方法相比,敏捷开发方法比较适合需求变化较大或者开发前期需求不是很清晰的项目,以它的灵活性来适应需求的变化。
1)敏捷方法是适应型而非预设型。重型方法试图对一个软件开发项目在很长的时间跨度内做出详细的计划,然后依计划进行开发。这类方法在计划制定完成后拒绝变化。而敏捷方法则欢迎变化。 2)敏捷方法是面向人的而非面向过程的。它们试图使软件开发工作能够利用人的特点,充分发挥人的创造能力,强调软件开发应当是一项愉快的活动。
敏捷方法的核心思想主要有以下3点: 1)敏捷方法是适应型,而非可预测型。2)敏捷方法以人为本,而非以过程为本。3)属于迭代增量式的开发过程。
- 信息系统战略规划
| 方法名称 | 英文全称 | 核心思想 / 要点 | 优点 | 缺点 | 记忆关键词 |
|---|---|---|---|---|---|
| 关键成功因素法 (CSF) | Critical Success Factors | 从组织目标出发,识别影响目标实现的关键成功因素,提炼关键信息需求 | 抓住主要矛盾,突出重点;经理熟悉,易于接受 | 随环境和时期变化需不断重新识别,稳定性不足 | 抓重点 |
| 战略目标集转化法 (SST) | Strategy Set Transformation | 将组织使命、目标、战略转化为信息系统目标的结构化方法 | 目标全面,考虑多方需求,疏漏较少 | 突出重点的能力不如 CSF,可能导致冗余 | 全覆盖 |
| 企业系统规划法 (BSP) | Business System Planning | 自上而下识别目标/过程/数据,再自下而上设计系统;通过过程与数据分析推导系统目标 | 保证企业目标与系统目标一致;信息一致性好;适应组织变化 | 过程复杂,目标导向不明显,对人员要求高 | 自上而下+自下而上 |
| 企业信息分析与集成技术 (BIAIT) | Business Information Analysis & Integration Technology | 通过分析企业信息资源,强调集成与整体规划 | 系统性强,适合大型复杂企业 | 技术要求高,实施难度大 | 信息集成 |
| 产出/方法分析 (E/MA) | Ends/Means Analysis | 通过分析“产出”和“方法”的关系来确定系统目标和过程 | 思路清晰,目标与方法对应关系直观 | 对复杂组织可能不够细致,容易遗漏 | 产出-方法 |
| 投资分析法 (Investment/Chargout) | — | 从投资回报和成本角度分析信息系统建设的可行性和优先级 | 强调经济效益,便于资金决策 | 可能忽视非经济性目标(如战略价值) | 算钱 |
| 零基预算卡法 | Zero-based Budgeting Card | 以零为基点重新规划和分配预算,确保资源分配合理性 | 有助于控制成本,避免资源浪费 | 工作量大,执行成本高 | 从零开始 |
| 阶石法 | Step Stone Method | 将规划过程划分为逐步推进的阶段,每一步都是后续的基础 | 实施渐进,风险可控 | 周期长,整体效率较低 | 一步一步 |
4.2 信息化的典型应用(ERP、TPS、DSS)
【基础知识点】
- TPS和EDPS
业务处理系统(Transaction Processing System,TPS)或电子数据处理系统(Electronic Data Processing System,EDPS)是信息化的典型应用。业务处理系统可以实现计算机自动化、减轻处理数据的负担、提高处理效率。它既是信息系统发展的最初级形式,也是基础和桥梁。因其简单和成熟常用结构化生命周期法开发。对事务所发生的数据进行输入、处理和输出(即IPO)。业务系统数据处理周期分为数据输入、数据处理、数据库的维护、文件报表的生成和查询处理5个阶段(对功能的进一步阐述)。数据处理方式包括批处理(Batch Processing)方式和联机事务处理(OnLine Transaction Processing,OLTP)方式。
- 管理信息系统
管理信息系统(Manage Information System,MIS)是在TPS基础上发展的高度集成化的人机信息系统,用于企业整体的某些管理和业务层面的管理决策。MIS系统的上层是子系统和功能,底层是各个过程,功能由过程组合实现。一个MIS系统可以用一个功能/层次矩阵表示。共有销售市场子系统、生产子系统、后勤子系统、人事子系统、财务和会计子系统、信息处理子系统和高层管理子系统7个子系统。
- 决策支持系统
决策支持系统(Decision Support System,DSS)是管理信息系统应用概念的深化,是在管理信息的基础上发展起来的系统。DSS是能帮助决策者利用数据和模型去解决半结构化决策问题和非结构化决策问题的交互式系统。服务于高层决策的管理信息系统,按功能可分为专用DSS、DSS工具和DSS生成器。专用DSS是为解决某一领域问题的DSS。DSS工具是指某种语言、某种操作系统、某种数据库系统。DSS生成器是通用决策支持系统,一般DSS包括数据库、模型库、方法库、知识库和会话部件。
决策支持系统(Decision Support System,DSS)有两种定义:
(1)定义一:DSS是一个由语言系统、知识系统和问题处理系统3个互相关联的部分组成的,基于计算机的系统。特征如下:
1)数据和模型是DSS的主要资源。 2)用来支援用户作决策。 3)主要用于解决半结构化及非结构化问题。 4)作用在于提高决策的有效性而不是提高决策的效率。
(2)定义二:DSS是一个交互式的、灵活的、适应性强的基于计算机的信息系统。特征如下:
1)针对上层管理人员。 2)界面友好。 3)将模型、分析技术与传统的数据存取与检索技术结合起来。 4)对环境及决策方法改变的灵活性与适应性。 5)支持但不是代替决策。 6)利用先进信息技术快速传递和处理信息。
DSS系统的管理者处于核心地位,结合DSS的支持进行决策。DSS有两种级别结构形式:两库结构和基于知识的结构。
DSS支撑九项基本功能: $(1)$ 多层决策,为决策整理和提供数据; $(2)$ 收集、存储和提供外部信息; $(3)$ 收集和提供活动的反馈信息; $(4)$ 具有模型的存储和管理能力; $(5)$ 对常用的各种方法的存储和管理; $(6)$ 对各种数据、模型、方法进行管理; $(7)$ 数据加工; $(8)$ 具有人一机接口和图形加工; $(9)$ 支持分布使用方式。特点是面向决策者、支持半结构化问题、辅助支持、过程动态、交互。组建过程是:数据重组、建立数据仓库、建立数据字典、数据挖掘、建立模型。
- 专家系统
基于知识的专家系统(Expert System,ES)是一种智能的计算机程序,该程序使用知识与推理过程,求解那些需要资深专家的专门知识才能解决的高难度问题。ES属于人工智能,用于求解半结构化或非结构化问题。专家系统包括:机器人技术、视觉系统、自然语言处理、学习系统和神经网络等分支。专家系统与一般计算机系统的比较见表4.2。
表4.2 专家系统与一般计算机系统的比较
| 比较项 | 专家系统 | 一般计算机系统 |
| 功能 | 解决问题、解释结果、进行判断与决策 | 解决问题 |
| 处理能力 | 处理数字与符号 | 处理数字 |
| 处理问题种类 | 多属准结构性或非结构性,可处理不确定的知识,使用于特定的领域 | 多属结构性,处理确定的知识 |
具体来说ES具有超越时间限制、操作成本低廉、易于传递与复制、处理手段一致、善于克服难题、适用特定领域等特点。ES由知识库、综合数据库、推理机、知识获取、解释程序、人一机接口组成。其中,推理机和知识库一起构成专家系统的核心。一般的专家系统通过推理机与知识库和综合数据库的交互作用来求解领域问题。
- 办公自动化系统
办公自动化系统(Office Automatic System,OAS)可以解决包括数据、文字、声音、图像等信息的一体化处理问题,是一个集文字、数据、语言、图像为一体的综合性、跨学科的人机信息处理系统,可以进行事务处理、信息管理和辅助决策。OAS由计算机设备、办公设备、数据通信及网络设备、软件系统构成。
- 企业资源规划(Enterprise Resource Planning,ERP)
企业资源规划(Enterprise Resource Planning,ERP)中的企业的所有资源包括三大流:物流、资金流和信息流。ERP是在信息技术基础上集成了企业的所有资源信息,为企业提供决策、计划、控制与经营业绩评估的全方位和系统化的管理平台。ERP的管理范围涉及企业的所有供需过程,是对供应链的全面管理,还与人事系统和CRM等关联。ERP包括生产预测、销售管理、经营计划、主生产计划、物料需求计划、能力需求计划、车间作业计划、采购与库存管理、质量与设备管理和财务管理共11个基本模块。ERP的功能有:支持决策、不同行业的针对性IT解决方案、提供全行业和跨行业的供应链。
1)需求信息流(需方到供方):如客户订单、生产计划、采购合同等 2)供应信息流(供方到需方):如入库单、完工报告单、库存记录、可供销售量、提货发运单等
ERP五个层次的计划: 1)生产预测计划是对市场需求进行比较准确的预测,是经营计划、生产计划大纲和主生产计划编制的基础; 2)销售管理计划是针对企业的销售部门的相关业务进行管理,属于最高层计划的范畴,是企业最重要的决策层计划之一; 3)生产计划大纲根据经营计划的生产目标制定,是对企业经营计划的细化; 4)主生产计划说明了在一定时期内生产什么,生产多少和什么时候交货,它的编制是ERP的主要工作内容; 5)物料需求计划是对主生产计划的各个项所需的全部制造件和全部采购件的网络支持计划和时间进度计划; 6)能力需求计划是对物料需求计划所需能力进行核算的一种计划管理方法,能够帮助企业尽早发现企业生产能力的瓶颈,为实现企业的生产任务提供能力帮面的保障。
管理科学的核心就是应用科学的方法实施管理,按照市场发展的要求,对企业现有的管理流程重新整合,从作为管理核心的财务、资金管理,向技术、物资、人力资源的管理,并延伸到企业技术创新、工艺设计、产品设计、生产制造过程的管理,进而扩展到客户关系管理、供应链的管理乃至发展到电子商务,形成企业内部向外部扩散的全方位管理。企业信息化注重企业经营管理方面的信息分析和研究,信息系统所蕴含的管理思想也可帮助企业建立更为科学规范的管理运作体系,提供准确及时的管理决策信息。
- 客户关系管理(Customer Relationship Management,CRM)
是一套先进的管理思想及技术手段,它通过将人力资源、业务流程与专业技术进行有效的整合,最终为企业涉及到客户或者消费者的各个领域提供了完美的集成,使得企业可以更低成本、更高效率地满足客户的需求,并与客户建立起基于学习性关系基础上的一对一营销模式,从而让企业可以最大程度提高客户满意度和忠诚度。CRM系统的主要模块包括销售自动化、营销自动化、客户服务与支持、商业智能。
客户关系管理(CRM)系统将市场营销的科学管理理念通过信息技术的手段集成在软件上,能够帮助企业构建良好的客户关系。在客户管理系统中,销售自动化是其中最为基本的模块,营销自动化作为销售自动化的补充,包括营销计划的编制和执行、计划结果分析等功能。客户服务与支持是CRM系统的重要功能。目前,客户服务与支持的主要手段有两种,分别是呼叫中心和互联网。CRM系统能够与ERP系统在财务、制造、库存等环节进行连接两者之间虽然关系比较独立,但由于两者之间具有一定的关系,因此会形成一定的闭环反馈结构。
客户关系管理系统的【核心是客户价值管理】,而不是客户信息管理。CRM的价值包括:提高工作效率,节省开支、提高客户满意度、提高客户的忠诚度。
所谓供应链就有供应商、制造商、分销商、零售商等等所供成的物流的网络,那么同一个企业就可能处在这个网络当中的一个节点,所以SCM他是一种集成的管理思想和方法,从单一的企业角度来看,SCM他是通过改善上下游的关系,整合和优化供应链当中的物流、信息流、资金流,来获得企业的竞争的优势,所以整个供应链的内容大概就包括了计划、采购、制造、配送和退货这五个方面的基本内容,所以整个供应链应该理解为从源头的供应商开始,到最终的消费者的集成的业务整个流程,不仅对消费者带来有价值的消费和服务,而且还能为顾客带来一些有用的信息,在整个SCM当中,他的关键问题,就是配送网络的重构问题以及配送的战略问题,另外一个就是供应链集成与战略伙伴的关系。SCM包括计划、采购、制造、配送、退货五大基本内容。 (1)计划:这是SCM的策略性部分。企业需要有一个策略来管理所有的资源,以满足客户对产品的需求。好的计划是建立一系列的方法监控供应链,使它能够有效、低成本地为顾客递送高质量和高价值的产品或服务。 (2)采购:选择能为企业提供产品和服务的供应商,与供应商建立一套定价、配送和付款流程,并监控和改善管理。 (3)制造:安排生产、测试、打包和准备送货所需的活动,是供应链中测量内容最多的部分,包括质量水平、产品产量和工人的生产效率等的测量。 (4)配送:也称为物流,是调整用户的订单收据、建立仓库网络、派递送人员提货并送货到顾客手中、建立产品计价系统、接收付款。 (5)退货:这是供应链中的问题处理部分。建立网络接收客户退回的次品和多余产品,并在客户应用产品出问题时提供支持。
4.3 典型信息系统架构模型(EI,企业信息化、电子商务)
【基础知识点】
(1)电子政务(Electronic Government,EG)。电子政务是利用信息技术和其他相关技术,实现公务、政务、商务、事务的一体化管理与运行的政府形态改造的系统工程。行为主体是:政府(Government)、企(事)业单位(Business)及居民(Citizen)。具体分类见表4.3。
表4.3 电子政务分类
| 名称 | 解释 |
|---|---|
| 政府对政府(G2G) | 政府内部的政务活动,包括国家和地方基础信息的采集、处理和利用,如人口信息;政府之间各种业务流所需要采集和处理的信息,如计划管理;政府之间的通信系统,如网络系统;政府内部的各种管理信息系统,如财务管理;以及各级政府的决策支持系统和执行信息系统等 |
| 政府对企业(G2B) | 政府面向企业的活动主要包括政府向企(事)业单位发布的各种方针、政策、法规、行政规定,即企(事)业单位从事合法业务活动的环境,政府向企(事)业单位颁发的各种营业执照、许可证、合格证和质量认证等 |
| 政府对居民(G2C) | 政府面向居民所提供的服务,以及各种关于社区GA和水、火、天灾等与公共安全有关的信息。户口、各种证件和牌照的管理等,还包括各公共部门,如学校、医院、图书馆和公园等 |
| 企业对政府(B2G) | 企业面向政府的活动包括企业应向政府缴纳的各种税款,按政府要求应该填报的各种统计信息和报表,参加政府各项工程的竞、投标,向政府供应各种商品和服务,以及申请的援助 |
| 居民对政府(C2G) | 包括个人应向政府缴纳的各种税款和费用,按政府要求应该填报的各种信息和表格,以及缴纳各种罚款等。此外,报警服务(盗贼、医疗、急救、火警等)即在紧急情况下居民需要向政府报告并要求政府提供的服务,也属于这个范围 |
| 政府对员工(G2E) | 政府面向公务员和事业单位工作人员的管理与服务,如人事管理、薪酬福利、在线培训、考核评估等,用于提升内部管理效率和员工满意度 |
(2)企业信息化(Enterprise Informatization,EI)。企业信息化是企业利用现代信息技术,实现经营活动的自动化、便捷化、网络化和智能化,以加强企业核心竞争力的过程。企业信息化是技术和业务的融合,从企业战略、业务运作和管理运作3个层面去实现。
企业信息化的方法有:业务流程重构方法、核心业务应用方法、信息系统建设方法、主题数据库方法、资源管理方法、人力资本投资方法。 1)业务流程重构方法:“彻底的、根本性的”重新设计流程。 2)核心业务应用方法:围绕核心业务推动信息化 3)信息系统建设方法:建设信息系统作为企业信息化的重点和关键 4)主题数据库方法:建立面向企业的核心业务的数据库,消除“信息孤岛” 5)资源管理方法:切入点是为企业资源管理提供强大的能力。如:ERP、SCM。 6)人力资本投资方法:人力资本理论【注意不是人力资源管理】把一部分企业的优秀员工看作是一种资本,能够取得投资收益。
企业信息化是指企业以业务流程的优化和重构为基础,在一定的深度和广度上利用计算机技术、网络技术和数据库技术,控制和集成化管理企业生产经营活动中的各种信息,实现企业内外部信息的共享和有效利用,以提卨企业的经济效益和市场竞争力,这将涉及到企业的管理理念的创新,管理流程的优化,管理团队的重组和管理手段的革新。企业信息化一定要建立在企业战略规划的基础之上,以企业战略规划为基础建立的企业管理模式是建立企业战略数据模型的依据。
企业信息化涉及对企业管理理念的创新,管理流程的优化,管理团队的重组和管理手段的革新。管理创新是按照市场发展的要求,对企业现有的管理流程重新整合,从作为管理核心的财务、物料管理,转向技术、物资、人力资源的管理,并延伸到企业技术创新、工艺设计、产品设计、生产制造过程的管理,进而还要扩展到客户关系管理、供应链管理乃至发展到电子商务。
企业信息化程度是国家信息化建设的基础和关键,企业信息化就是企业利用现代信息技术,通过信息资源的深入开发和广泛利用,实现企业生产过程的自动化、管理方式的网络化、决策支持的智能化和商务运营的电子化,不断提高生产、经营、管理、决策的效率和水平,进而提高企业经济效益和企业竞争力的过程。企业信息化方法主要包括业务流程重构、核心业务应用、信息系统建设、主题数据库、资源管理和人力资本投资方法。企业战略规划是指依据企业外部环境和自身条件的状况及其变化来制定和实施战略,并根据对实施过程与结果的评价和反馈来调整,制定新战略的过程。
决策支持系统 1)非结构化决策是指决策过程复杂,不可能用确定的模型和语言来描述其决策过程,更无所谓最优解的决策。由于目标不明确或不同的目标相互冲突,其决策过程和决策方法没有固定的规律可以遵循,没有固定的决策规则和通用模型可依,决策者的主观行为(学识、经验、直觉、判断力、洞察力、个人偏好和决策风格等)对各阶段的决策效果有相当影响。它是决策者根据掌握的情况和数据并依据经验临时做出的决定。 2)半结构化决策是指可以建立适当的算法产生决策方案,使决策方案得到较优的解。其决策过程和方法有一定规律可以遵循,但又不能完全确定,即有所了解但不全面,有所分析但不确切,有所估计但不确定。这样的决策一般可适当建立模型,但难以确定最优方案。在组织的决策中,管理决策问题基本上属于半结构化决策和结构化决策问题。
DSS基本组成部分 1)数据库子系统存储、管理、提供与维护用于决策支持的数据,是支持模型库子系统和方法库子系统的基础; 2)模型库子系统是构建和管理模型的子系统,它是DSS中最复杂和最难实现的部分。DSS用户是依靠模型库中的模型进行决策的,因此,DSS是由模型驱动的; 3)推理部分由知识库(方法库)、知识库管理系统和推理机组成,知识库内存储的方法程序一般有排序算法、分类算法、最小生成树算法、最短路径算法、计划评审技术、线性规划、整数规划、动态规划、各种统计算法和组合算法等; 4)用户接口子系统是DSS的人机交互界面,用以接收和检验用户请求,调用系统内部功能为决策服务,使模型运行、数据调用和知识推理达到有机的统一,有效地解决决策问题。
企业数字化转型分为5个发展阶段:初始级发展阶段、单元级发展阶段、流程级发展阶段、网络级发展阶段和生态级发展阶段。 1)初始级发展阶段:处于该发展阶段的组织,在单一职能范围内初步开展了信息(数字)技术应用,但尚未有效发挥信息(数字)技术对主营业务的支持作用。 2)单元级发展阶段:处于该阶段的组织,在主要或若干主营业务单一职能范围内开展了(新一代)信息技术应用提升相关单项业务的运行规范性和效率。 3)流程级发展阶段:处于该阶段的组织,在业务线范围内,通过流程级数字化和传感网级网络化,以流程为驱动实现主营业务关键业务流程及关键业务与设备设施、软硬件、行为活动等要素间的集成优化。 4)网络级发展阶段:处于该阶段的组织,在全组织(企业)范围内,通过组织(企业)级数字化和产业互联网级网络化,推动组织(企业)内全要素、全过程互联互通和动态优化,实现以数据为驱动的业务式创新。 5)生态级发展阶段:处于该阶段的组织,在生态组织范围内,通过生态级数字化和泛在物联网级网络化,推动与生态合作伙伴间资源、业务、能力等要素的开放共享和协同合作,共同培育智能驱动型的数字新业务。
供应链信息流 是指整个供应链上信息的流动。它是一种虚拟形态,包括了供应链上的供需信息和管理信息,它伴随着物流的运作而不断产生。因此有效的供应链管理作为信息流管理的主要作用在于及时在供应链中传递需求和供给信息,提供准确的管理信息,从而使供应链成员都能得到实时信息,以形成统一的计划与执行,从而为最终顾客更好地服务。供应链信息流的特点: 1)覆盖范围广 供应链中的信息流瘦盖了从供应商、制造商到分销商,再到零售商等供应链中的所有环节。其信息流分为需求信息流和供应信息流,这是两个不同流向的信息流。当需求信息(如客户订单、生产计划、采购合同等) 从需方向供方流动时,便引发物流。同时供应信息(如入库单、完工报告单、库存记录、可供销售量、提货发运单等) 又同物料一起沿着供应链从供方向需方流动。单个企业下的信息流则主要限定在企业内部的进销存记录。 2)获取途径多 由于供应链中的企业是一种协作关系和利益共同体,因而供应链中的信息获取渠道众多,对于需求信息来说既有来自顾客也有来自分销商和零售商的:供应信息则来自于各供应商,这些信息通过供应链信息系统而在所有的企业里流动与分享。对于单个企业情况来说,由于没有与上下游企业形成利益共同体,上下游企业也就没有为它提供信息的责任和动力,因此单个企业的信息获取完全倚赖于自己的收集。 3)信息质量高 由于存在专业分工,供应链中的信息质量要强于单个企业下的信息质量,例如分销商和零售商可以专门负青收集需求信息,供应商则收集供应信息,生产厂商收集产品信息等。
企业信息集成 是一个十分复杂的问题,按照组织范围来分,分为企业内部的信息集成和外部的信息集成两个方面。 1)企业内部的信息集成 按集成内容,企业内部的信息集成一般可分为以下四个方面: ①技术平台的集成系统底层的体系结构、软件、硬件以及异构网络的特殊需求首先必须得到集成。这个集成包括信息技术硬件所组成的新型操作平台,如各类大型机、小型机、工作站、微机、通信网络等信息技术设备,还包括置入信息技术或者说经过信息技术改造的机床、车床、自动化工具、流水线设备等新型设施和设备。 ②数据的集成为了完成应用集成和业务流程集成,需要解决数据和数据库的集成问题。数据集成的目的是实现不同系统的数据交流与共享,是进行其他更进一步集成的基础。数据集成的特点是简单、低成本,易于实施,但需要对系统内部业务的深入了解。数据集成是对数据进行标识并编成目录,确定元数据模型。只有在建立统一的模型后,数据才能在数据库系统中分布和共享。数据集成采用的主要数据处理技术有数据复制、数据聚合和接口集成等。 ③应用系统的集成应用系统集成是实现不同系统之间的互操作,使得不同应用系统之间能够实现数据和方法的共享。它为进一步的过程集成打下了基础。 ④业务过程的集成对业务过程进行集成的时候,企业必须在各种业务系统中定义、授权和管理各种业务信息的交换,以便改进操作、减少成本、提高响应速度。业务流程的集成使得在不同应用系统中的流程能够无缝连接,实现流程的协调运作和流程信息的充分共享。
2)企业外部的信息集成 企业外部的信息集成主要包括以下两个部分: ①通过门户网站和互联网实现公众、社会团体、社会和客户的互动,实现企业内外部信息资源的有效交流和集成; ②通过与合作伙伴信息系统的对接,建立动态的企业联盟,发展基于竞争合作机制的虚拟企业,重塑企业的战略模式和竞争优势。Internet的发展增加了企业之间的合作与交流,虚拟企业、扩展的供应链管理和协同商务等都是企业之间集成的典型。通过合作,几个企业和公司组成一个相对稳定的合作网络,这种合作网络可以提供单个公司所不能提供的产品和服务,获得单个公司无法完成的定单。为了增加合作的效率,必须实现网络中有合作关系的公司之间活动和过程的集成。另外,企业间的集成并不是使企业内所有的系统都实现集成,而只是集成一些与企业之间的业务过程有关的系统,因此,企业间的集成是一种有选择的集成。企业间集成的一个关键问题是使企业间不同系统实现数据格式的匹配。
IETF集成服务(IntServ)工作组根据服务质量的不同,把Intermet服务分成了三种类型。 1)保证质量的服务(Guaranteed Services):对带宽、时延、抖动和丢包率提供定量的保证。 2)负载受控的服务(Controlled-load Services):提供一种类似于网络欠载情况下的服务,这是一种定性的指标。 3)尽力而为的服务(Best-Effort):这是Intemet提供的一般服务,基本上无任何质量保证。
为了加强对企业信息资源的管理,企业应按照信息化和现代化企业管理要求设置信息管理机构,建立信息中心,确定信息主管,统一管理和协调企业信息资源的开发、收集和使用。信息中心是企业的独立机构,直接由最高层领导并为企业最高管理者提供服务。其主要职能是处理信息,确定信息处理的方法,用先进的信息技术提高业务管理水平,建立业务部门期望的信息系统和网络并预测未来的信息系统和网络,培养信息资源的管理人员等。
集成管理是企业信息资源管理的主要内容之一。实行企业信息资源集成的前提是对企业历史上形成的企业信息功能的集成,其核心是对企业内部和外部信息流的集成,其实施的基础是各种信息手段的集成。通过集成管理实现企业信息系统各要素的优化组合,使信息系统各要素之间形成强大的协同作用,从而最大限度地放大企业信息的功能,实现企业可持续发展的目的。
集成平台 是支持企业集成的支撑环境,包括硬件、软件、软件工具和系统,通过集成各种企业应用软件形成企业集成系统。由于硬件环境和应用软件的多样性,企业信息系统的功能和环境都非常复杂,因此,为了能够较好地满足企业的应用需求,作为企业集成系统支持环境的集成平台,其基本功能主要有: (1)通信服务它提供分布环境下透明的同步/异步通信服务功能,使用户和应用程序无需关心具体的操作系统和应用程序所处的网络物理位置,而以透明的函数调用或对象服务方式完成它们所需的通信服务要求。 (2)信息集成服务它为应用提供透明的信息访问服务,通过实现异种数据库系统之间数据的交换、互操作、分布数据管理和共享信息模型定义(或共享信息数据库的建立),使集成平台上运行的应用、服务或用户端能够以一致的语义和接口实现对数据(数据库、数据文件、应用交互信息)的访问与控制。 (3)应用集成服务它通过高层应用编程接口来实现对相应应用程序的访问,这些高层应用编程接口包含在不同的适配器或代理中,它们被用来连接不同的应用程序。这些接口以函数或对象服务的方式向平台的组件模型提供信息,使用户在无需对原有系统进行修改(不会影响原有系统的功能)的情况下,只要在原有系统的基础上加上相应的访问接口就可以将现有的、用不同的技术实现的系统互联起来,通过为应用提供数据交换和访问操作使各种不同的系统能够相互协作。 (4)二次开发工具二次开发工具是集成平台提供的一组帮助用户开发特定应用程序(如实现数据转换的适配器或应用封装服务等)的支持工具,其目的是简化用户在企业集成平台实施过程中(特定应用程序接口)的开发工作。 (5)平台运行管理工具它是企业集成平台的运行管理和控制模块,负青企业集成平台系统的静态和动态配置、集成平台应用运行管理和维护、事件管理和出错管理等。通过命名服务、目录服务、平台的动态静态配置,以及其中的关键数据的定期备份等功能来维护整个服务平台的系统配置及稳定运行。
数据集成方式
| 概念 | 作用与原理 | 理解辅助 | 是否需要数据映射 |
|---|---|---|---|
| 包装器(Wrapper) | 由于参与集成的数据源存在数据库管理系统(DBMS)或操作系统(OS)的差异,需要对各数据源进行格式包装与转换。包装器向外提供统一的调用接口,将不同数据源的访问差异屏蔽,对应的查询也通过包装器执行并返回统一格式的结果。 | 类似“适配器模式”,把各种异构数据源“包装”成统一接口供系统使用。 | ✅ 需要(用于格式与接口转换) |
| 数据网关(Data Gateway) | 负责不同通信系统之间的数据互通。通过物理连接与协议接口的软件连接,实现数据接收、提取、发送与转发。 | 相当于系统间的“桥梁”,让不同系统“能说同一种语言”。 | ⚙️ 需要(依赖通信协议匹配) |
| 数据映射(Data Mapping) | 在两个数据模型之间建立数据元素的一一对应关系,实现数据从一个模型到另一个模型的语义转换。 | 类似“翻译对照表”,规定 A 系统的字段怎么对应到 B 系统。 | 🔑 是核心环节 |
| 主动记录(Active Record) | 可理解为在业务系统中记录数据的同时,将数据实时同步到集成系统的方式,无需额外映射即可实现同步。 | 像“实时抄送机制”,业务数据生成时立即同步给集成系统。 | ❌ 不需要(直接同步单表数据) |
企业应用集成(Enterprise Application Integration,EAI)。 EAI构建统一标准的基础平台,将进程、软件、标准和硬件联合起来,连接具有不同功能和目的而又独自运行的企业内部的应用系统,以达到信息和流程的共享,使企业相关应用整合在一起。EAI就是在各个应用系统的接口之间共享数据和功能。EAI的基本原则就是集成多个系统并保证系统互不干扰,也就是独立性。EAI的终极目标就是将多个企业和企业内部的多个应用集成到一个虚拟的、统一的应用系统中。因此实施EAI必须遵循如下原则:应用程序的独立性;面向商业流程;独立于技术;平台无关。EAI提供4个层次的服务,从下至上依次为通信服务、信息传递与转化服务、应用连接服务、流程控制服务。
企业进行系统集成时,“业务系统的运行平台和开发语言差异较大,而且系统所使用的通信协议和数据格式各不相同”。在这种情况下,需要采用总线技术对传输协议和数据格式进行转换与适配。当需要集成并灵活定义系统功能之间的协作关系时,应该采用基于工作流的功能关系定义方式。
系统集成方式分为面向信息、面向过程、面向服务三类,是宏观分类。
| 集成模式 | 核心思想 | 特点/作用 | 关键词 |
|---|---|---|---|
| 面向信息的集成 (Data-oriented) | 以数据交换与共享为核心,将不同系统的数据格式、存储方式统一 | 解决数据孤岛,实现跨系统数据访问与共享 | 数据共享 |
| 面向过程的集成 (Process-oriented) | 强调业务流程的交互逻辑,与核心业务逻辑分离 | 不同系统通过流程协作完成业务,支持跨系统流程自动化 | 流程协作 |
| 面向服务的集成 (Service-oriented) | 以服务接口与调用为核心,将系统功能封装成服务 | 松耦合、可重用,通过服务编排实现灵活的系统组合与扩展(典型如SOA/微服务) | 服务封装 |
| 集成点 | 核心对象 | 效果 | 解决关键点 | 关键词 |
|---|---|---|---|---|
| 界面集成 | 界面 | 统一入口,产生“整体”感觉 | “整体”感觉,最小代价实现一体化操作 | 门面 |
| 数据集成 | 数据 | 不同来源的数据逻辑或物理上“集中” | 其他集成方法的基础 | 数据池 |
| 控制集成 | 应用逻辑 | 调用其他系统已有方法,达到集成效果 | —— | API调用 |
| 业务流程集成(过程集成) | 应用逻辑 | 跨企业,或优化流程而非直接调用 | 企业之间的信息共享能力 | 流程 |
| 门户集成 | —— | 将内部系统对接到互联网上 | 发布到互联网上 | 门户 |
集成实现手段
| 集成方式 | 特点 | 关键词 |
|---|---|---|
| 消息集成 | 数据量小、交互频繁、即时性强、异步 | 异步消息 |
| 共享数据库 | 交互频繁、即时性强、同步 | 同步共享 |
| 文件传输 | 数据量大、交互频度小、即时性要求低(常见于月末、年末的批量数据传输) | 批量文件 |
| 远程过程调用(RPC) | 跨系统调用功能模块,交互紧密、实时性强、对耦合度要求较高 | RPC调用 |
企业门户
| 门户类型 | 英文缩写 | 含义说明 | 特点/作用 | 关键词 |
|---|---|---|---|---|
| 企业信息门户 | EIP | 员工、合作伙伴、客户、供应商都能访问企业内网和因特网存储的各种信息 | 统一访问入口 | 信息入口 |
| 企业知识门户 | EKP | 在企业网站的基础上增加知识性内容 | 企业知识库 | 知识库 |
| 企业应用门户 | EAP | 以业务流程和企业应用为核心,把不同应用模块通过门户技术集成 | 企业信息系统的网上集成界面 | 应用集成 |
| 垂直门户 | —— | 针对某个特定行业或兴趣领域,传送的内容只面向相关群体 | 行业/兴趣领域专属 | 行业门户 |
企业集成技术的架构层次:网络集成(语法互联)、数据集成(语义互通)、应用集成(语用互操作)、会聚集成(集成化运行)。 其中数据集成主要有以下三种模式:数据联邦、数据复制和基于接口的数据集成。 (1)数据联邦 数据联邦是指不同的应用共同访问一个全局虚拟数据库,通过全局虚拟数据库管理系统为不同的应用提供全局信息服务,实现不同的应用和数据源之间的信息共享和数据交换,其具体实现由客户端应用、全局信息服务和若干个后部数据源三部分组成。 (2)数据复制模式 在数据复制模式中,通过底层应用数据源之间的一致性复制来实现(访问不同数据库的)不同应用之间的信息共享和互操作,其实现的关键是必须能够提供在两个或多个数据库系统之间实现数据转换和传输的基础结构(以屏蔽不同数据库间数据模型的差异)。 (3)基于接口的数据集成模式 在基于接口的数据集成模式中,不同的应用系统之间利用适配器(或接口代理)提供的应用编程接口来实现相互调用。应用适配器或接口代理通过其开放或私有接口将业务信息从其所封装的具体应用系统中提取出来,进而实现不同的应用系统之间业务数据的共享与互交换,接口调用的方式可以采用同步调用方法,也可以采用基于消息中间件的异步方法来实现, 答案选择D选项。
(3)电子商务(Electronic Commerce,EC)。电子商务指利用Web提供的通信手段在网上买卖产品或提供服务,及其衍生行为。主要模式有:B2B、B2C、C2C、O2O(线上购买线下的服务)。
电子商务分五个方面,即电子商情广告、电子选购与交易、电子交易凭证的交换、电子支付与结算,以及网上售后服务等。 参与电子商务的实体有4类:客户(个人消费者或集团购买)、商户(包括销售商、制造商和储运商)、银行(包括发行和收单行)及认证中心。
电子数据交换(EDI)是电子商务活动中采用的一种重要的技术手段。 1)EDI的实施需要一个公认的标准和协议,将商务活动中涉及的文件标准化和格式化; 2)EDI通过计算机网络,在贸易伙伴之间进行数据交换和自动处理; 3)EDI主要应用于企业与企业、企业与批发商之间的批发业务; 4)EDI的实施在技术上比较成熟,但是实施EDI需要统一数据格式,成本与代价较大。
1)生产计划大纲(Production Planning,PP) 是根据经营计划的生产目标制定的,是对企业经营计划的细化,用以描述企业在可用资源的条件下,在一定时期中的产量计划。生产计划大纲在企业决策层的三个计划中有承上启下的作用,一方面它是企业经营计划和战略规划的细化,另一方面它又用于指导企业编制主生产计划,指导企业有计划地进行生产。 2)主生产计划(Master Production Schedule,MPS) 是对企业生产计划大纲的细化,说明在一定时期内的如下计划:生产什么,生产多少和什么时候交货。主生产计划的编制以生产大纲为准,其汇总结果应当等同于生产计划大纲,同时,主生产计划又是其下一层计划–物料需求计划的编制依据。主生产计划的编制是ERP的主要工作内容。主生产计划的质量将大大影响企业的生产组织工作和资源的利用, 3)物料需求计划 (Matena Reouirement Plannina,MRP) 是对主生产计划的各个项目所害的全部制造件和全部采购件的网络支持计划和时间进度计划,它根据主生产计划对最终产品的需求数量和交货期,推导出构成产品的零部件及材料的需求数量和需求时期,再导出自制零部件的制作订单下达日期和采购件的采购订单发送日期,并进行需求资源和可用能力之间的进一步平衡。物料需求计划是生产管理的核心,它将主生产计划安排生产的产品分解成各自制零部件的生产计划和采购件的采购计划。物料需求计划属于ERP管理层计划。 4)能力需求计划(Capacity Requirements Planning,CRP) 是对物料需求计划所需能力进行核算的一种计划管理方法。旨在通过分析比较MRP的需求和企业现有生产能力,及早发现能力的瓶颈所在,为实现企业的生产任务而提供能力方面的保障。 5)车间作业计划(Production Activity Control,PAC) 是在MRP所产生的加工制造订单(即自制零部件生产计划)的基础上,按照交货期的前后和生产优先级选择原则以及车间的生产资源情况(如设备、人员、物料的可用性、加工能力的大小等),将零部件的生产计划以订单的形式下达给适当的车间。车间作业计划属于ERP执行层计划。当前主流的车间作业计划模式是JIT(JustIn Time)模式,
4.4 练习题
- ERP中的企业资源包括()
A.物流、资金流和信息流 B.物流、工作流和信息流 C.物流、资金流和工作流 D.资金流、工作流和信息流
解析:企业的所有资源包括三大流:物流、资金流和信息流。ERP是对这3种资源进行全面集成管理的管理信息系统。
答案:A
- ERP(Enterprise Resource Planning)是建立在信息技术的基础上,利用现代企业的先进管理思想,对企业的物流、资金流和(1)流进行全面集成管理的管理信息系统,为企业提供决策、计划、控制与经营业绩评估的全方位和系统化的管理平台。在ERP系统中,(2)管理模块主要是对企业物料的进、出、存进行管理。
(1)A. 产品 B. 人力资源 C. 信息 D. 加工
(2)A. 库存 B. 物料 C. 采购 D. 销售
解析:ERP 是建立在信息技术的基础上,利用现代企业的先进管理思想,对企业的物流、资金流和信息流进行全面集成管理的管理信息系统,为企业提供决策、计划、控制与经营业绩评估的全方位和系统化的管理平台。
ERP 系统主要包括:生产预测、销售管理、经营计划、主生产计划、物料需求计划、能力需求计划、车间作业计划、采购与库存管理、质量与设备管理、财务管理、有关扩展应用模块等内容。显然对企业物料的进、出、存进行管理的模块是库存管理模块。
答案:CA
- 电子政务是对现有的政府形态的一种改造,利用信息技术和其他相关技术,将其管理和服务职能进行集成,在网络上实现政府组织结构和工作流程优化重组。与电子政务相关的行为主体有三个,即政府、(1)及居民。国家和地方人口信息的采集、处理和利用,属于(2)的电子政务活动。
(1)A. 部门 B. 企(事)业单位 C. 管理机构 D. 行政机关
(2)A. 政府对政府 B. 政府对居民 C. 居民对居民 D. 居民对政府
解析:电子政务是对现有的政府形态的一种改造,利用信息技术和其他相关技术,将其管理和服务职能进行集成,在网络上实现政府组织结构和工作流程优化重组。与电子政务相关的行为主体有三个,即政府、企(事)业单位及居民。国家和地方人口信息的采集、处理和利用,属于政府对政府的电子政务活动。
答案:BA
第5小时 信息安全技术基础知识
5.0 章节考点分析
第5小时主要学习信息安全基础知识、信息安全系统的组成框架、信息加解密技术、密钥管理技术、访问控制及数字签名技术、信息安全的抗攻击技术、信息安全的保障体系与评估方法等内容。
根据考试大纲,本小时知识点会涉及单项选择题,约占5分。本小时内容侧重于概念知识,根据以往全国计算机技术与软件专业技术资格(水平)考试的出题规律,考查的知识点多来源于教材,扩展内容较少。本小时知识架构如图5.1所示。
图5.1 本小时知识架构
【导读小贴士】
信息安全事关国家安全和社会稳定,在新版教材中,信息安全的内容大幅增加了,知识点也得到了更新,与信息安全工程师的某些内容同步。所以掌握本小时知识点非常重要,不仅可以在考试中拿到分数,也会给日常生活带来帮助。
5.1 信息安全基础知识
【基础知识点】
(1)信息安全(Information Security)。信息安全是指为数据处理系统而采取的技术的和管理的安全保护,保护计算机硬件、软件、数据不因偶然的或恶意的原因而遭到破坏、更改和泄露。 信息安全的基本要素有机密性、完整性、可用性、可控性与可审查性。 信息安全的范围包括设备安全、数据安全、内容安全和行为安全。其中数据安全即采取措施确保数据免受未授权的泄露、篡改和毁坏,包括秘密性、完整性和可用性3个方面。 信息存储安全的范围:信息使用的安全、系统安全监控、计算机病毒防治、数据的加密和防止非法的攻击等。
1)设备安全 信息系统设备的安全是信息系统安全的首要问题,是信息系统安全的物质基础,它包括3个方面 ①设备的稳定性:指设备在一定时间内不出故障的概率。 ②设备的可靠性:指设备在一定时间内正常执行任务的概率。 ③设备的可用性:指设备可以正常使用的概率, 2)数据安全 数据信息可能泄露,可能被篡改,数据安全即采取措施确保数据免受未授权的泄露、篡改和毁坏,包括以下3个方面: ①数据的秘密性:指数据不受未授权者知晓的属性。 ②数据的完整性:指数据是正确的、真实的、未被篡改的、完整无缺的属性。 ③数据的可用性:指数据可以随时正常使用的属性。 3)内容安全 内容安全是信息安全在政治、法律、道德层次上的要求,包括以下3个方面 ①信息内容在政治上是健康的。 ②信息内容符合国家的法律法规, ③信息内容符合中华民族优良的道德规范 4)行为安全 信息系统的服务功能是指最终通过行为提供给用户,确保信息系统的行为安全,才能最终确保系统的信息安全。行为安全的特性如下: ①行为的秘密性:指行为的过程和结果不能危害数据的秘密性, ②行为的完整性:指行为的过程和结果不能危害数据的完整性,行为的过程和结果是预期的。 ③行为的可控性:指当行为的过程偏离预期时,能够发现、控制和纠正。
安全性(security)是指系统在向合法用户提供服务的同时能够阻止非授权用户使用的企图或拒绝服务的能力。安全性又可划分为 1)机密性(信息不泄露给未授权的用户、实体或过程)、 2)完整性(保证信息的完整和准确,防止信息被篡改)、 3)不可否认性(不可抵赖,即由于某种机制的存在,发送者不能否认自己发送信息的行为和信息的内容。)及 4)可控性(对信息的传播及内容具有控制的能力,防止为非法者所用)等特性。
(2)网络安全。网络安全漏洞和隐患表现在物理安全性、软件安全漏洞、不兼容使用安全漏洞等方面。网络安全威胁表现在非授权访问、信息泄露或丢失、破坏数据完整性、拒绝服务攻击、利用网络传播病毒等方面。安全措施的目标包括访问控制、认证、完整性、审计和保密等5个方面。
网络攻击
在被动攻击(passive atack)中,攻击者的目的只是获取信息,这就意味着攻击者不会篡改信息或危害系统。系统可以不中断其正常运行。常见的被动攻击包括:窃听和流量分析。 主动攻击(active attack)可能改变信息或危害系统。威胁信息完整性和有效性的攻击就是主动攻击。主动攻击通常易于探测但却难于防范,因为攻击者可以通过多种方法发起攻击。常见的主动攻击包括:篡改、伪装、重放、拒绝服务攻击。 物理攻击是指攻击者可以直接接触到信息与网络系统的硬件、软件和周边环境设备。通过对硬件设备、网络线路电源、空调等的破坏,使系统无法正常工作,甚至导致程序和数据无法恢复。 分发攻击是指在软件与硬件开发出来之后到安装之前的这段时间,或当它从一个地方传输到另一个地方时,攻击者恶意修改软/硬件,这种攻击可能给一个产品引入后门程序等恶意代码,以便日后在未获授权的情况下访问信息或系统。
数据被非授权地进行修改是破坏了数据的完整性,而拒绝服务攻击会破坏服务的可用性,使正常合法用户无法访问,利用统计分析方法对诸如通信频度、通信的信息流向、通信总量的变化等参数进行研究,从而发现有价值的信息和规律是业务流分析。 1)非法使用(非授权访问):某一资源被某个非授权的人,或以非授权的方式使用。 2)破坏信息的完整性:数据被非授权地进行增删、修改或破坏而受到损失。 3)授权侵犯(内部攻击):被授权以某一目的使用某一系统或资源的某个人,却将此权限用于其他非授权的目的,。 4)计算机病毒:一种在计算机系统运行过程中能够实现传染和侵害功能的程序。 5)拒绝服务:对信息或其他资源的合法访问被无条件地阻止。 6)陷阱门:在某个系统或某个部件中设置的“机关”,使得在特定的数据输入时,允许违反安全策略。 7)旁路控制:攻击者利用系统的安全缺陷或安全性上的脆弱之处获得非授权的权利或特权。 8)业务欺骗:某一系统或系统部件欺骗合法的用户或系统自愿地放弃敏感信息等。 9)特洛伊木马:软件中含有一个觉察不出的有害的程序段,当它被执行时,会破坏用户的安全,这种应用程序称为特 洛伊木马。物理侵入:侵入者绕过物理控制而获得对系统的访问业务流分析:通过对系统进行长期监听,利用统计分析方法对诸如通信频度、通信的信息流向、通信总量的变化等参数进行研究,从中发现有价值的信息和规律。
HTTP协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协议传输隐私信息非常不安全,为了保证这些隐私数据能加密传输,SSL协议用于对HTTP协议传输的数据进行加密,从而就诞生了HTTPS。简单来说,HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全HTTPS和HTTP的区别主要如下: 1)https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。 2)http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。 3)http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。 4)http的连接很简单,是无状态的:HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协 议,比http协议安全
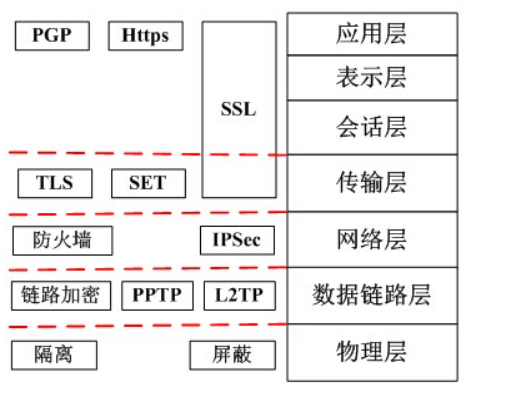
MIME (Multipurpose Interet Mail Extensions)中文名为:多用途互联网邮件扩展类型 。Intemnet电子邮件由一个邮件头部和一个可选的邮件主体组成,其中邮件头部含有邮件的发送方和接收方的有关信息。MIME是针对邮件主体的一种扩展描述机制。它设定某种扩展名的文件用一种应用程序来打开的方式类型,当该扩展名文件被访问的时候,浏览器会自动使用指定应用程序来打开。多用于指定一些客户端自定义的文件名,以及一些媒体文件打开方式。所以这是与邮件内容直接相关的一个协议。 而S/MIME (Secure Multipurpose Interet Mai Extensions)是对MIME在安全方面的扩展。它可以把MIME实体(比如数字签名和加密信息等)封装成安全对象。增强安全服务,例如具有接收方确认签收的功能,这样就可以确保接收者不能否认已经收到过的邮件。还可以用于提供数据保密、完整性保护、认证和鉴定服务等功能。 S/MIME只保护邮件的主体,对头部信息则不进行加密,以便让邮件成功地在发送者和接收者的网关之间传递。
IDS:即入侵检测系统,这个系统会根据操作行为的特征或是异常行径来判断是不是一次入侵行为。像杀毒软件就用到了入侵检测系统的原理,通过特征识别病毒。 防火墙:作用是内外网之间的隔离。外网的请求要到内网,必须通过防火墙,所以防火墙能使用一些判断规则来把些恶意行为拒之门外。但如果攻击本身来自内网,防火墙就无能为力了。 网闸:一个物理隔离装置,与IDS和防火墙不同,网闸连接的两个网络是不相通的。网闸与内网相联时,会断开与外网的连接,与外网相联时,会断开与内网的连接。 UTM安全设备的定义是指一体化安全设备,它具备的基本功能包括网络防火墙、网络入侵检测/防御和网关防病毒功能,但这几项功能并不一定要同时得到使用,不过它们应该是UTM设备自身固有的功能。
5.2 信息安全系统的组成框架
【基础知识点】
信息安全系统框架通常由技术体系、组织机构体系和管理体系共同构建。
(1)技术体系。从技术体系看,信息安全系统涉及基础安全设备、计算机网络安全、操作系统安全、数据库安全、终端设备安全等多方面技术。 (2)组织机构体系。信息系统安全的组织机构分为决策层、管理层和执行层3个层次。 (3)管理体系。信息系统安全的管理体系由法律管理、制度管理和培训管理3个部分组成。
一个完整的信息安全系统至少包含三类措施:技术方面的安全措施,管理方面的安全措施和相应的政策法律。 信息安全技术涉及信息传输的安全、信息存储的安全以及对网络传输信息内容的审计三方面,当然也包括对用户的鉴别和授权。 1)信息安全的技术措施主要有:信息加密、数字签名、身份鉴别、访问控制、网络控制技术、反病毒技术、数据备份和灾难恢复。 2)实现安全管理,应有专门的安全管理机构;有专门的安全管理人员;有逐步完善的管理制度;有逐步提供的安全技术设施。信息安全管理主要涉及以下几个方面:人事管理;设备管理,场地管理存储媒体管理:软件管理:网络管理:密码和密钥管理。 3)国内的相关法规:中华人民共和国计算机安全保护条例、中华人民共和国商用密码条例 中华人民共和国计算机信息网络国际联网管理暂行办法、关于对与国际联网的计算机信息系统进行备案工作的通知、计算机信息网络国际联网安全保护管理办法等。 综上,答案选择B、C选项。
5.3 信息加解密技术
【基础知识点】
- 数据加密
数据加密是防止未经授权的用户访问敏感信息的手段,保障系统的机密性要素。数据加密有对称加密算法、非对称加密算法两种。
常用的对称加密算法:DES、3DES、AES、DESX、Blowfish、、RC4、RC5、RC6。 常用的非对称加密算法:RSA、DSA、ECC、Diffie-Hellman、El Gamal。
- 对称密钥加密算法 (效率高)
对称密钥算法的加密密钥和解密密钥相同,又称为共享密钥算法。对称加密算法主要有:
(1)数据加密标准(Data Encryption Standard,DES),明文切分为64位的块(即分组),由56位的密钥控制变换成64位的密文。 (2)三重DES(Triple-DES)是DES的改进算法,使用两把56位的密钥对明文做三次DES加解密,密钥长度为112位。 (3)国际数据加密算法(International Data Encryption Algorithm,IDEA),分组长度64位,密钥长度128位,已经成为全球通用的加密标准。 (4)高级加密标准(Advanced Encryption Standard,AES),分组长度128位,支持128位、192位和256位3种密钥长度,用于替换脆弱的DES算法,且可以通过软件或硬件实现高速加解密。 (5)SM4国密算法,分组长度和密钥长度都是128位。 (6)RC-5
- 非对称密钥加密算法
非对称密钥加密算法的加密密钥和解密密钥不相同,又称为不共享密钥算法或公钥加密算法。在非对称加密算法中用公钥加密,私钥解密,可实现保密通信;用私钥加密,公钥解密,可实现数字签名。非对称加密算法可以分为:
(1)RSA(Rivest,Shamir and Adleman)是一种国际通用的公钥加密算法,安全性基于大素数分解的困难性,密钥的长度可以选择,但目前安全的密钥长度已经高达2048位。RSA的计算速度比同样安全级别的对称加密算法慢1000倍左右。 (2)SM2国密算法,基于椭圆曲线离散对数问题,在相同安全程度的要求下,密钥长度和计算规模都比RSA小得多。 对称SM1、非对称SM2、摘要SM3、无线SM4、标识SM9
| 算法名称 | 算法特性描述 | 备注 |
|---|---|---|
| SM1 | 对称加密,分组长度和密钥长度均为128比特 | 广泛应用于电子政务、电子商务及国民经济的各个应用领域 |
| SM2 | 非对称加密,用于公钥加密算法、密钥交换协议、数字签名算法 | 国家标准推荐使用素数域256位椭圆曲线 |
| SM3 | 杂凑算法,杂凑值长度为256比特 | 适用于商用密码应用中的数字签名和验证 |
| SM4 | 对称加密,分组长度和密钥长度均为128比特 | 适用于无线局域网产品 |
| SM9 | 标识密码算法 | 不需要申请数字证书,适用于互联网应用的各种新兴应用的安全保障 |
商用密码签名 (3)ECC
开放式认证方式:完全不认证也不加密。 WEP:最基本的加密技术,全称为有线等效保密,是一种教据加密算法,它的安全技术源自于名为RC4的RSA数据加密技术,是无线局域网WLAN的必要的安全防护层。运用了该技术的无线网络,所有客户端与无线接入点的数据都会以一个共亨的密钥进行加密,常见的密钥长度有64 bits和128 bits两种。 WPA:WiFi Protected Access,全称为WiFi网络安全存取。WPA协议是在前一代有线等效加密(WEP)的基础上产生的,解决了前任WEP的缺陷问颖,它使用TKIP(临时密钥完整性)协议,是IEEE802.11i标准中的过渡方案。在安全的防护上比WEP更为周密,主要体现在身份认证、加密机制和数据包检查等方面,而且它还提升了无线网络的管理能力。WPA2:是WPA加密的升级版。它是WiFi联盟验证过的IEEE 802.11i标准的认证形式,WPA2实现了802.11i的强制性元素,特别是Michael算法被公认彻底安全的CCMP(计数器模式密码块链消息完整码协议)讯息认证码所取代、而RC4加密算法也被AES(高级加密)所取代。 WPA-PSKNPA2-PSK:是WPA与WPA2两种加密算法的混合体,是目前安全性最好的WiFi加密模式。WPA-PSK也叫作WPA-Personal(WPA个人)。WPA-PSK使用TKIP加密方法把无线设备和接入点联系起来。WPA2-PSK使用AES加密方法把无线设备和接入点联系起来。使用AES加密算法不仅安全性能更高,而且由于其采用的是最新技术,因此,在无线网络传输速率上面也要比TKIP更快。
5.4 密钥管理技术
【基础知识点】
(1)密钥的使用控制。控制密钥的安全性主要有密钥标签和控制矢量两种技术。密钥的分配发送有物理方式、加密方式和第三方加密方式。该第三方即密钥分配中心(Key Distribution Center,KDC)。 (2)公钥加密体制的密钥管理。有直接公开发布(如PGP)、公用目录表、公钥管理机构和公钥证书4种方式。公钥证书可以由个人下载后保存和传递,证书管理机构为CA(Certificate Authority)。
消息摘要是对原文信息提取特征值,做这个操作,当原始信息被篡改时,我们能及时感知到,所以能防止篡改。而对消息摘要“加密”,虽然做的是加密操作,但并无加密的作用。因为私钥加密时,公钥解密。公钥谁都能获取到,所以谁都能解,故无法防止窃听,但可以防止抵赖。所以对摘要进行加密的目的是防止抵赖。
目前最常用的第三方认证服务包括:PKI/CA和Kerberos。PKI/CA是基于非对称密钥体系的,Kerberos是基于对称密钥体系的。
1)PKl( Public Key nfrastructure )指的是公钥基础设施。CA(Certificate Authority )指的是认证中心。 PKI 从技术上解决了网络通信安全的种种障碍。 CA从运营、管理、规范、法律、人员等多个角度来解决网络信任问题。由此,人们统称为“PKI/CA”。从总体构架来看,PKICA 主要由最终用户、认证中心和注册机构来组成。
在PKI系统体系中,证书机构CA负责生成和签署数字证书,注册机构RA负责验证申请数字证书用户的身份。
 2)Kerberos 是一种网络认证协议,其设计目标是通过密钥系统为客户机/服务器应用程序提供强大的认证服务。该认证过程的实现不依赖于主机操作系统的认证,无需基于主机地址的信任,不要求网络上所有主机的物理安全,并假定网络上传送的数据包,可以被任意地读取、修改和插入数据。在以上情况下,Kerberos 作为一种可信任的第三方认证服务,是通过传统的密码技术(如:共享密钥)执行认证服务的。认证过程具体如下:
客户机向认证服务器(AS)发送请求,要求得到某服务器的证书,然后 AS 的响应包含这些用客户端密钥加密的证书。证书的构成为: 1)服务器“ticket”: 2) 一个临时加密密钥(又称为会话密钥“session key”)。客户机将 ticket(包括用服务器密钥加密的客户机身份和一份会话密钥的拷贝)传送到服务器上。会话密钥可以(现已经由客户机和服务器共享)用来认证客户机或认证服务器,也可用来为通信双方以后的通讯提供加密服务,或通过交换独立子会话密钥为通信双方提供进一步的通信加密服务。KDC(密码学中的密钥分发中心)是密钥体系的一部分,旨在减少密钥体制所固有的交换密钥时所面临的风险,KDC在kerberos中通常提供两种服务:AuthenticationService(AS)认证服务和Ticket-Granting Service(TGS):授予票据服务。
2)Kerberos 是一种网络认证协议,其设计目标是通过密钥系统为客户机/服务器应用程序提供强大的认证服务。该认证过程的实现不依赖于主机操作系统的认证,无需基于主机地址的信任,不要求网络上所有主机的物理安全,并假定网络上传送的数据包,可以被任意地读取、修改和插入数据。在以上情况下,Kerberos 作为一种可信任的第三方认证服务,是通过传统的密码技术(如:共享密钥)执行认证服务的。认证过程具体如下:
客户机向认证服务器(AS)发送请求,要求得到某服务器的证书,然后 AS 的响应包含这些用客户端密钥加密的证书。证书的构成为: 1)服务器“ticket”: 2) 一个临时加密密钥(又称为会话密钥“session key”)。客户机将 ticket(包括用服务器密钥加密的客户机身份和一份会话密钥的拷贝)传送到服务器上。会话密钥可以(现已经由客户机和服务器共享)用来认证客户机或认证服务器,也可用来为通信双方以后的通讯提供加密服务,或通过交换独立子会话密钥为通信双方提供进一步的通信加密服务。KDC(密码学中的密钥分发中心)是密钥体系的一部分,旨在减少密钥体制所固有的交换密钥时所面临的风险,KDC在kerberos中通常提供两种服务:AuthenticationService(AS)认证服务和Ticket-Granting Service(TGS):授予票据服务。
5.5 访问控制及数字签名技术
【基础知识点】
- 基本模型
访问控制技术包括3个要素,即主体、客体和控制策略。访问控制包括认证、控制策略实现和审计3方面的内容。审计的目的是防止滥用权力。
访问控制的实现技术
(1)访问控制矩阵(Access Control Matrix,ACM),以主体为行索引,以客体为列索引的矩阵,该技术是后面三个技术的基础,当主客体元素很多的时候实现困难。 (2)访问控制表(Access Control Lists,ACL),按列(即客体)保存访问矩阵,是目前最流行、使用最多的访问控制实现技术。 (3)能力表(Capabilities),按行(即主体)保存访问矩阵。 (4)授权关系表(Authorization Relations),抽取访问矩阵中的非空元素保存,当矩阵是稀疏矩阵的时候很有效,常用于安全数据库系统。
访问控制类型
| 控制类型 | 说明 |
|---|---|
| OBAC基于对象的访问控制 | OBAC 访问控制系统是从信息系统的数据差异变化和用户需求出发,
有效地解决了信息数据量大、数据种类繁多、数据更新变化频繁的大型管理信息系统的安全管理问题。 控制策略和控制规则是 OBAC 系统的核心所在。 |
| RBAC基于角色的访问控制 | RBAC 是指根据完成某些职责或任务所需要的访问权限来进行授权和管理。 RBAC 由 用户(U)、角色(R)、会话(S) 和 权限(P) 四个基本要素组成。 |
| TBAC基于任务的访问控制 | TBAC 从应用和企业层面出发,以任务(活动)为单位建立安全模型并实现安全机制,
在任务处理过程中提供动态实时的安全管理。 模型由工作流、授权结构体、受托人集和许可集四部分组成,通常用五元组 (S, O, P, L, AS) 表示:S 表示主体,O 表示客体,P 表示许可,L 表示生命周期,AS 表示授权步骤。 |
| ABAC基于属性的访问控制 | ABAC 根据主体属性、客体属性、环境条件以及访问策略对主体的请求操作进行授权或拒绝。 适用于细粒度策略控制与动态环境(例如强制上下文感知访问控制)的场景。 |
- 数字签名
数字签名是公钥加密技术与数字摘要技术的应用。数字签名的条件是:可信、不可伪造、不可重用、不可改变和不可抵赖。基于对称密钥的签名只能在两方间实现,而且需要双方共同信赖的仲裁人。利用公钥加密算法的数字签名则可以在任意多方间实现,不需要仲裁且可重复多次验证。实际应用时先对文件做摘要,再对摘要签名,这样可以大大提升数字签名的速度。同时摘要的泄露不影响文件保密。
每个数字证书上都会有其颁发机构的签名,我们可以通过验证CA对数字证书的签名来核实数字证书的有效性。如果证书有效,说明此网站经过CA中心的认证,是可信的网站,所以这个动作是用来验证网站真伪的,而不能验证客户方的真伪。
数字签名技术是一种用于保证数字信息完整性和来源真实性的技术。它基于公钥密码学原理,使用发送者的私钥进行签名,而接收者则用相应的公钥进行验证。 在数字签名的过程中,首先需要使用哈希函数生成信息的摘要,这一步是为了确保信息的完整性。接着,发送者使用自己的私钥对信息摘要进行加密,生成数字签名。这一步的目的是为了证明信息的来源和完整性,因为私钥是唯一的,只有发送者拥有。接收者在收到信息和数字签名后,使用发送者的公钥对数字签名进行解密,以恢复出原始的信息摘要。然后,接收者再次使用哈希函数对接收到的信息生成摘要,并与解密得到的摘要进行比较。如果两者 一致,则说明信息在传输过程中未被篡改,且确实来自该发送者。
X.509数字证书内容 1)证书的版本信息; 2)证书的序列号,每个证书都有一个唯一的证书序列号; 3)证书所使用的签名算法; 4)证书的发行机构名称,命名规则一般采用X.509格式; 5)证书的有效期,现在通用的证书一般采用UTC时间格式,它的计时范围为1950-2049:证书6)所有人的名称,命名规则一般采用X.509格式; 7)证书所有人的公开密钥; 8)证书发行者对证书的签名。
5.6 信息安全的抗攻击技术(网络攻击)
【基础知识点】
| 攻击类型 | 攻击名称 | 描述 |
|---|---|---|
| 被动攻击 | 窃听(网络监听) | 用各种可能的合法或非法的手段窃取系统中的信息资源和敏感信息。例如对通信线路中传输的信号进行搭线监听,或者利用通信设备在工作过程中产生的电磁泄漏截取有用信息等。 |
| 业务流分析(截取) | 通过对系统进行长期监听,利用统计分析方法对诸如通信频度、通信的信息流向、通信总量的变化等参数进行研究从而发现有价值的信息和规律。 | |
| 非法登录 | 非法登录是指未经授权的人或者程序通过破解、盗用账号密码的方式,进入到平台的后台管理系统,进行非法操作或者窃取数据这些行为。有些资料将这种方式归为被动攻击方式。 | |
| 主动攻击 | 假冒身份 | 非法用户冒充成为合法用户,特权小的用户冒充成为特权大的用户。 |
| 抵赖 | 这是一种来自用户的攻击,例如:否认自己曾经发布过的某条消息,伪造一份对方来信等。 | |
| 旁路控制(旁路攻击) | 攻击者利用系统的安全缺陷或安全性上的脆弱之处获得未授权的权利或特权。例如,攻击者通过各种攻击手段发现原本应保密、却暴露出来的一些系统特性,并利用这些“特性”绕过防线,侵入系统内部。 | |
| 重放攻击 | 攻击者将所截获的某次合法通信数据拷贝,出于非法目的而重新发送。 加入【时间戳】能识别并应对重放攻击。 | |
| 拒绝服务(DoS) | 攻击者通过占用系统资源、网络带宽等方式,破坏服务的【可用性】,使合法访问被阻止。 | |
| WEB 服务攻击类型 | XSS 跨站脚本攻击 | 通过利用网页 【开发时留下的漏洞】,以巧妙的方式注入恶意指令代码到网页中。 |
| CSRF 跨站请求伪造攻击 | 攻击者通过一些技术手段,欺骗用户的浏览器去访问一个自己曾经认证过的网站,并执行一些操作(如转账或购买商品等)。 | |
| 缓冲区溢出攻击 | 利用 【缓冲区溢出漏洞】 进行的攻击。这类漏洞在各种操作系统和应用软件中都很常见。 | |
| SQL 注入攻击 | 攻击者将 SQL 命令插入到 Web 表单中,欺骗服务器执行恶意 SQL 命令。 SQL 注入攻击的方式包括:【恶意拼接查询】、【利用注释执行非法命令】、【传入非法参数】、【添加额外条件】。 |
- 密钥的选择
密钥在概念上被分成数据加密密钥(DK)和密钥加密密钥(KK)两大类。后者用于保护密钥。加密的算法通常是公开的,加密的安全性在于密钥。为对抗攻击,密钥生成需要考虑增大密钥空间、选择强钥和密钥的随机性3个方面的因素。
- 拒绝服务(Denial of Service,DoS)攻击
| 攻击类型 | 子类 | 抗攻击技术 / 防御措施 |
|---|---|---|
| 拒绝服务 | 传统拒绝服务 | - 加强对数据包的特征识别 - 设置防火墙监视本地主机端口的使用情况 |
| 分布式拒绝服务(DDoS) | - 对通信数据量进行统计分析以获得有关攻击系统的位置和数量信息 - 尽可能修补已发现的问题和系统漏洞 |
DoS是使系统不可访问并因此拒绝合法的用户服务要求的行为,侵犯系统的可用性要素。传统拒绝服务攻击的分类有消耗资源、破坏或更改配置信息、物理破坏或改变网络部件、利用服务程序中的处理错误使服务失效等4种模式。
目前常见的DoS攻击模式为分布式拒绝服务攻击(Distributed Denial of Service,DDoS)。现有的DDoS工具一般采用Client(客户端)、Handler(主控端)、Agent(代理端)三级结构。
DDoS 的防御包括特征识别、防火墙、通信数据量的统计、修正问题和漏洞4种方法。
- 欺骗攻击与防御
欺骗攻击与防御具体分为:
| 攻击类型 | 具体攻击 | 抗攻击技术 / 防御措施 |
|---|---|---|
| 欺骗攻击 | ARP 欺骗 | - 固化 ARP 表,阻止 ARP 欺骗 - 使用 ARP 服务器 - 采用双向绑定方法解决并防止 ARP 欺骗 - 使用 ARP 防护软件(例如 ARP Guard) |
| DNS 欺骗 | - 被动监听检测 - 虚假保温(保活)检测(疑为“虚假缓存检测”) - 交叉检查查询 | |
| IP 欺骗 | - 预防此类攻击可以删除 UNIX 中的 /etc/hosts.equiv、$HOME/.rhosts 文件,修改 /etc/inetd.conf 文件使 RPC 机制无法滥用- 通过防火墙过滤来自外部而信源地址却是内部 IP 的报文 |
(1)ARP欺骗:ARP协议解析IP地址为MAC网卡物理地址,欺骗该机制即可阻断正常的网络访问。常用防范办法为固化ARP表、使用ARP服务器、双向绑定和安装防护软件。 ARP攻击是针对以太网地址解析协议ARP的一种攻击技术,此种攻击可让攻击者取得局域网上的数据封包甚至可篡改封包,且可让网络上特定计算机或所有计算机无法正常连接。ARP攻击造成网络无法跨网段通信的原因是伪造网关ARP报文使得数据包无法发送到网关。 (2)DNS欺骗:DNS协议解析域名为IP地址,欺骗该机制可以使用户访问错误的服务器地址。其检测有被动监听检测、虚假报文探测和交叉检查查询3种方法。 (3)IP欺骗:攻击者修改IP数据报的报头,把自身的IP地址修改为另一个IP,以获取信任。常用防火墙等防范IP欺骗。
- 端口扫描(Port Scanning)
端口扫描是入侵者搜集信息的几种常用手法之一。端口扫描尝试与目标主机的某些端口建立连接,如果目标主机该端口有回复,则说明该端口开放,甚至可以获取一些信息。端口扫描有全TCP连接、半打开式扫描(SYN扫描)、FIN扫描、第三方扫描等分类。
- 针对TCP/IP堆栈的攻击方式
(1)同步包风暴(SYN Flooding):是应用最广泛的一种DoS攻击方式,攻击TCP协议建立连接的三次握手,让目标主机等待连接完成而耗尽资源。可以减少等待超时时间来防范。 (2)ICMP攻击:例如Ping of Death攻击操作系统的网络层缓冲区,旧版操作系统会崩溃死机。防范方法是打补丁,升级到新版操作系统。Ping of Death攻击在因特网上,ping of death是一种拒绝服务攻击,方法是由攻击者故意发送大于65535字节的ip数据包给对方。TCP/IP的特征之一是碎裂:它允许单一IP包被分为几个更小的数据包。在1996年,攻击者开始利用那一个功能,当他们发现一个进入使用碎片包可以将整个!P包的大小增加到IP协议允许的65536比特以上的时候。当许多操作系统收到一个特大号的IP包的时候,它们不知道该做什么,因此,服务器会被冻结、宕机或重新启动。 (3)SNMP攻击:SNMP协议常用于管理网络设备,早期的SNMP V1协议缺少认证,可能被攻击者入侵。防范方法是升级 (4)land 攻击是一种使用相同的源和目的主机和端口发送数据包到某台机器的攻击。结果通常使存在漏洞的机器崩溃。在Land攻击中,一个特别打造的SYN包中的源地址和目标地址都被设置成某一个服务器地址,这时将导致接受服务器向它自己的地址发送SYN-ACK消息,结果这个地址又发回ACK消息并创建一个空连接,每一个这样的连接都将保留直到超时掉。各种系统对Land攻击反应不同,许多UNIX系统将崩溃,而 Windows NT 会变的极其缓慢(大约持续五分钟)。 (5)Teardrop攻击Teardrop攻击是一种拒绝服务攻击。是基于UDP的病态分片数据包的攻击方法,其工作原理是向被攻击者发送多个分片的IP包(IP分片数据包中包括该分片数据包属于哪个数据包以及在数据包中的位置等信息),某些操作系统收到含有重善偏移的伪造分片数据包时将会出现系统崩溃、重启等现象。
- 系统漏洞扫描
系统漏洞扫描指对重要计算机信息系统进行检查,发现其中可能被黑客利用的漏洞。漏洞扫描既是攻击者的准备工作,也是防御者安全方案的重要组成部分。系统漏洞扫描分为:
(1)基于网络的漏洞扫描,通过网络来扫描目标主机的漏洞,常常被主机边界的防护所封堵,因而获取到的信息比较有限。 (2)基于主机的漏洞扫描,通常在目标系统上安装了一个代理(Agent)或者是服务(Services),因而能扫描到更多的漏洞。有扫描的漏洞数量多、集中化管理、网络流量负载小等优点。
5.7 信息安全的保障体系与评估方法
【基础知识点】
- 等级保护
《计算机信息系统安全保护等级划分准则》(GB17859—1999)规定了计算机系统安全保护能力的5个等级。
(1)第1级:用户自主保护级(对应TCSEC的C1级)。 (2)第2级;系统审计保护级(对应TCSEC的C2级)。 (3)第3级;安全标记保护级(对应TCSEC的B1级)。 (4)第4级:结构化保护级(对应TCSEC的B2级)。 (5)第5级:访问验证保护级(对应TCSEC的B3级)。
- 安全保密技术
安全保密技术主要有:
(1)数据泄密(泄露)防护(Data Leakage Prevention,DLP)。DLP是通过一定的技术手段,防止企业的指定数据或信息资产以违反安全策略规定的形式流出企业的一种策略。 (2)数字水印(Digital Watermark)。数字水印是指通过数字信号处理方法,在数字化的媒体文件中嵌入特定的标记。水印分为可感知的和不易感知的两种。
- 安全协议
常用的安全协议有:
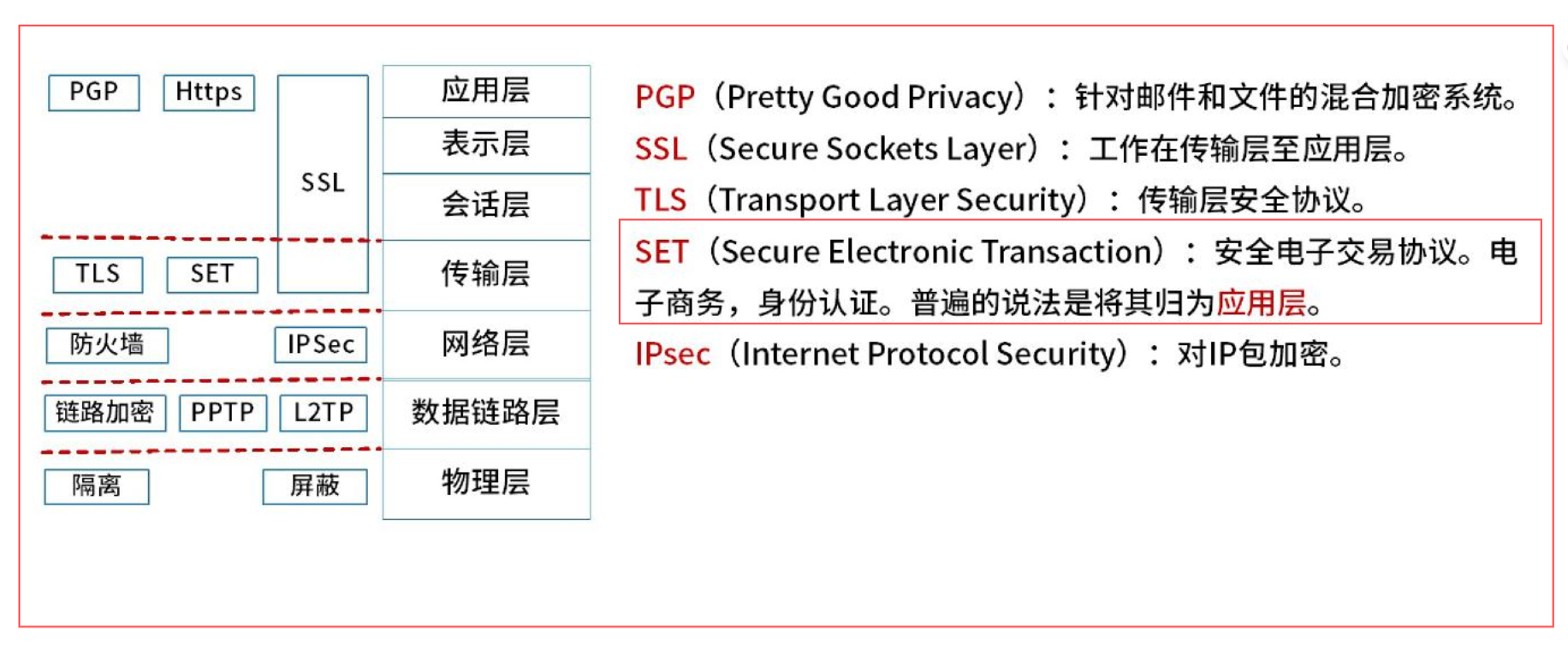
(1)SSL协议。SSL协议是介于应用层和TCP层之间的安全通信协议,提供保密性通信、点对点身份认证、可靠性通信3种安全通信服务。 (2)PGP(Pretty Good Privacy)。PGP是一种加密软件,应用了多种密码技术,包括RSA、IDEA、完整性检测和数字签名算法,实现了一个比较完善的密码系统。广泛地用于电子邮件安全。PGP(Pretty Good Privacy),是一个基于RSA公钥加密体系的邮件加密软件。可以用它对邮件保密以防止非授权者阅读,它还能对邮件加上数字签名从而使收信人可以确认邮件的发送者,并能确信邮件没有被篡改。它可以提供一种安全的通讯方式,而事先并不需要任何保密的渠道用来传递密匙。它采用了一种RSA和传统加密的杂合算法,用于数字签名的邮件文摘算法,加密前压缩等,还有一个良好的人机工程设计。它的功能强大,有很快的速度 (3)互联网安全协议(Internet Protocol Security,IPSec)。IPSec是工作在网络层的安全协议,主要优点是它的透明性,提供安全服务不需要更改应用程序。 (4)SET协议。主要用于解决用户、商家和银行之间通过信用卡支付的交易问题,保证支付信息的机密、支付过程的完整、商户和持卡人身份合法性及可操作性。 (5)HTTPS协议。详见第3小时,这里不再赘述。
SNMPV3把对网络协议的安全威胁分为主要的和次要的两类。标准规定安全模块必须提供防护的两种主要威胁是: 1)修改信息:就是某些未经授权的实体改变了进来的SNMP报文,企图实施未经授权的管理操作,或者提供虚假的管理对象。 2)假冒:即未经授权的用户冒充授权用户的标识,企图实施管理操作。 必须提供防护的两种次要威胁是: 1)修改报文流:由于SNMP协议通常是基于无连接的传输服务,重新排序报文流、延迟或重放报文的威胁都可能出现。这种威胁的危害性在于通过报文流的修改可能实施非法的管理操作。 2)消息泄露:SNMP引擎之间交换的信息可能被偷听,对于这种威胁的防护应采取局部的策略, 不必提供防护的威胁包括: 1)拒绝服务:因为在很多情况下拒绝服务和网络失效无法区别,所以可以由网络管理协议来处理,安全子系统 不必采取措施。 2)通信分析:即由第三者分析管理实体之间的通信规律,从而获取需要的信息。由于通常都是由少数管理站来管理整个网络的,所以管理系统的通信模式是可预见的,防护通信分析就没有多大作用了。根据以上分析可以得知,本题应选B。
- 信息系统的安全风险与评估
信息系统的安全风险是指由于系统存在的脆弱性所导致的安全事件发生的概率和可能造成的影响。
风险评估是对信息系统及由其处理、传输和存储的信息的保密性、完整性和可用性等安全属性进行科学评价的过程,是信息安全保障体系建立过程中重要的评价方法和决策机制。风险评估的基本要素为脆弱性、资产、威胁、风险和安全措施。其中,威胁是一种对机构及其资产构成潜在破坏的可能性因素或者事件。脆弱性评估是安全风险评估中的重要内容,脆弱性不仅包括各种资产本身存在的脆弱性,没有正确实施的安全保护措施本身也可能是一个安全薄弱环节。风险计算模型包含信息资产、弱点/脆弱性、威胁等关键要素。
- 安全防范体系
安全防范体系的层次划分: (1)物理环境的安全性。包括通信线路、物理设备和机房的安全等。 (2)操作系统的安全性。主要表现在三个方面,一是操作系统本身的缺陷带来的不安全因素.主要包括身份认证、访问控制和系统漏洞等;二是对操作系统的安全配置问题,三是病毒对操作系统的威胁。 (3)网络的安全性。网络层的安全问题主要体现在计算机网络方面的安全性,包括网络层身份认证、网络资源的访问控制、数据传输的保密与完整性、远程接入的安全、域名系统的安全、路由系统的安全、入侵检测的手段和网络设施防病毒等 (4)应用的安全性。由提供服务所采用的应用软件和数据的安全性产生,包括Web服务、电子邮件系统和DNS等。此外,还包括病毒对系统的威胁。 (5)管理的安全性。包括安全技术和设备的管理、安全管理制度、部门与人员的组织规则等。
- 安全审计
安全审计四要素: 控制目标、安全漏洞、控制措施、控制测试 安全审计功能(6个部分): 安全审计自动响应、安全审计自动生成、安全审计分析、安全审计浏览、安全审计事件选择、安全审计事件存储
5.8 系统安全分析与设计
基于任务的访问控制模型(TBAC Model,Task-based Access Control Model) 是从应用和企业层角度来解决安全问题,以面向任务的观点,从任务(活动)的角度来建立安全模型和实现安全机制,在任务处理的过程中提供动态实时的安全管理。在TBAC中,对象的访问权限控制并不是静止不变的,而是随着执行任务的上下文环境发生变化。TBAC首要考虑的是在工作流的环境中对信息的保护问题:在工作流环境中,数据的处理与上一次的处理相关联,相应的访问控制也如此,因而TBAC是一种上下文相关的访问控制模型。其次,TBAC不仅能对不同工作流实行不同的访问控制策略,而且还能对同一工作流的不同任务实例实行不同的访问控制策略。从这个意义上说,TBAC是基于任务的,这也表明,TBAC是一种基于实例(instance-based)的访问控制模型。TBAC模型由工作流、授权结构体、受托人集、许可集四部分组成。 OBAC访问控制系统是从信息系统的数据差异变化和用户需求出发,有效地解决了信息数据量大、数据种类繁多、数据更新变化频繁的大型管理信息系统的安全管理。并从受控对象的角度出发,将访问主体的访问权限直接与受控对象相关联,一方面定义对象的访问控制列表,增、删、修改访问控制项易于操作,另一方面,当受控对象的属性发生改变,或者受控对象发生继承和派生行为时,无须更新访问主体的权限,只需要修改受控对象的相应访问控制项即可,从而减少了访问主体的权限管理,降低了授权数据管理的复杂性。
Bell-LaPadula模型的安全规则如下: (1)简单安全规则(Simple Security Rule):安全级别低的主体不能读安全级别高的客体(No Read Up); (2)星属性安全规则(Star Security Property):安全级别高的主体不能往低级别的客体写(No Write Down); (3)强星属性安全规则(Strong Star Security Property):不允许对另一级别进行读写; (4)自主安全规则(Discretionary Security Property):使用访问控制矩阵来定义说明自由存取控制。其存取控制体现在内容相关和上下文相关。
5.9 练习题
- 在信息安全领域,基本的安全性原则包括机密性(Confidentiality)、完整性(Integrity)和可用性(Availability)。机密性指保护信息在使用、传输和存储时(1)。信息加密是保证系统机密性的常用手段。使用哈希校验是保证数据完整性的常用方法。可用性指保证合法用户对资源的正常访问,不会被不正当地拒绝。(2)就是破坏系统的可用性。
(1)A.不被泄露给已注册的用户 B.不被泄露给未授权的用户C.不被泄露给未注册的用户 D.不被泄露给已授权的用户 (2)A.跨站脚本攻击(XSS) B.拒绝服务攻击(DoS)C.跨站请求伪造攻击(CSRF) D.缓冲区溢出攻击
解析:机密性指保护信息在使用、传输和存储时不被泄露给未授权的用户。
跨站脚本攻击(XSS)是指恶意攻击者往Web页面里插入恶意html代码,当用户浏览该页时,嵌入Web中的html代码会被执行,从而实现劫持浏览器会话、强制弹出广告页面、网络钓鱼、删除网站内容、窃取用户Cookies资料、繁殖XSS蠕虫、实施DDoS攻击等目的。 拒绝服务(DoS)攻击利用大量合法的请求占用大量网络资源,以达到瘫痪网络的目的。受到DoS攻击的系统,可用性大大降低。 跨站请求伪造(CSRF)是一种挟制、欺骗用户在当前已登录的Web应用程序上执行非本意的操作的攻击。 缓冲区溢出攻击是指利用缓冲区溢出漏洞,从而控制主机,进行攻击。
答案:BB
- DES加密算法的密钥长度为56位,三重DES的密钥长度为()位。
A.168 B.120 C.112 D.56
解析:三重DES采用两组56位的密钥K1和K2,通过“K1加密一K2解密一K1加密”的过程,两组密钥加起来的长度是112位。
答案:C
- 非对称加密算法中,加密和解密使用不同的密钥,下面的加密算法中(1)属于非对称加密算法。若甲、乙采用非对称密钥体系进行保密通信,甲用乙的公钥加密数据文件,乙使用(2)来对数据文件进行解密。
(1)A.AES B.RSA C.IDEA D.DES
(2)A.甲的公钥 B.甲的私钥 C.乙的公钥 D.乙的私钥
解析:加密密钥和解密密钥不相同的算法,称为非对称加密算法,这种方式又称为公钥密码体制。常见的非对称加密算法有RSA等。若甲、乙采用非对称密钥体系进行保密通信,甲用乙的公钥加密数据文件,乙使用乙的私钥来对数据文件进行解密。
加密密钥和解密密钥相同的算法,称为对称加密算法。常见的对称加密算法有DES、3DES、IDEA、AES等。
答案:B D
第6小时 系统工程基础知识
6.0 章节考点分析
第6小时主要学习系统工程和系统性能等内容。
根据考试大纲,本小时知识点会涉及单项选择题,约占2—5分。本小时内容侧重于概念知识,也会有计算题。根据以往全国计算机技术与软件专业技术资格(水平)考试的出题规律,考查的知识点多来源于教材,扩展内容较少。本小时知识架构如图6.1所示。
图6.1 本小时知识架构
【导读小贴士】
系统工程是一种方法论,从宏观上对如何创建和管理一个信息化工程提出了理论框架。而系统
性能评估和设计是架构师的重要工作之一,所以掌握本小时知识点很重要。本小时的内容比较基础,难度并不大。
6.1 系统工程(三维结构)
【基础知识点】
- 定义与特点
系统工程是运用系统方法,对系统进行规划、研究、设计、制造、试验和使用的组织管理技术,利用电现代子计算机,对系统的结构、要素、信息和反馈等进行分析,以达到最优规划、最优设计、最优管理和最优控制等目的。是人们用科学方法解决复杂问题的一门技术。系统工程方法的特点是整体性、综合性、协调性、科学性和实践性。系统工程方法可以分为:
(1)霍尔的三维结构。霍尔的三维结构是美国系统工程专家霍尔(A.D.Hall)等人于1969年提出的一种系统工程方法论,形成了由时间维、逻辑维和知识维组成的三维空间结构。时间维分为规划、拟订方案、研制、生产、安装、运行、更新7个时间阶段;逻辑维包括明确问题、确定目标、系统综合、系统分析、优化、决策、实施7个逻辑步骤;知识维包括工程、医学、建筑、商业、法律、管理、社会科学、艺术等知识和技能。 ①逻辑维运用系统工程方法解决某一大型工程项目时,一般可分为七个步骤:1.明确问题;2.建立价值体系或评价体系;3.系统分析;4.系统综合;5.系统方案的优化选择;6.决策"决策就是管理”,“决策就是决定”,人类的决策管理活动面临着被决策系统的日益庞大和日益复杂;7.制定计划有了决策就要付诸实施,实施就要依靠严格的有效的计划。 ②时间维(工作进程),对于一个具体的工作项目,从制定规划起一直到更新为止,全部过程可分为七个阶段:1.规划阶段。即调研、程序设计阶段,目的在于谋求活动的规划与战略;2.拟定方案。提出具体的计划方案;3.研制阶段。作出研制方案及生产计划;4.生产阶段。生产出系统的零部件及整个系统,并提出安装计划;5.安装阶段。将系统安装完毕,并完成系统的运行计划;6.运行阶段。系统按照预期的用途开展服务;7.更新阶段。即为了提高系统功能,取消旧系统而代之以新系统,或改进原有系统,使之更加有效地工作。 ③知识维(专业科学知识),系统工程除了要求为完成上述各步骤、各阶段所需的某些共性知识外,还需要其他学科的知识和各种专业技术,霍尔把这些知识分为工程、医药、建筑、商业、法律、管理、社会科学和艺术等。各类系统工程,如军事系统工程、经济系统工程、信息系统工程等。都需要使用其它相应的专业基础知识。
(2)切克兰德方法。切克兰德方法的核心不是最优化而是比较与探寻。将工作过程分为认识问题、根底定义、建立概念模型、比较及探寻、选择、设计与实施、评估与反馈7个步骤。
(3)并行工程。并行工程(Concurrent Engineering)方法是对产品及其相关过程(包括制造过程和支持过程)进行并行、集成化处理的系统方法和综合技术,目标是提高质量、降低成本、缩短产品开发周期和产品上市时间。
(4)综合集成法。钱学森等提出从系统的本质出发可以把系统分为简单系统和巨系统两大类。开放的复杂巨系统的一般基本原则:整体论、相互联系、有序性、动态,主要性质是开放性、复杂性、进化与涌现性、层次性和巨量性。
(5)WSR系统方法。WSR系统方法是物理一事理一人理方法论的简称。具有中国传统哲学的思辨思想,是多种方法的综合统一,属于定性与定量分析综合集成的东方系统思想。一般工作过程可理解为理解意图、制定目标、调查分析、构造策略、选择方案、协调关系和实现构想7步。
- 系统工程的生命周期
对系统工程生命周期进行定义的目的是以有序而且高效的方式建立一个满足利益攸关者需求的框架。系统工程的生命周期阶段包括探索研究、概念阶段、开发阶段、生产阶段、使用阶段、保障阶段和退役阶段。生命周期方法有:
1)计划驱动方法:需求->设计->构建->测试->部署 2)渐进迭代式开发:提供连续交付以达到期望的系统 3)精益开发:起源于丰田,是一个动态的、知识驱动的,以客户为中心的过程 4)敏捷开发:更好的灵活性
- 基于模型的系统工程(Model-Based Systems Engineering,MBSE)
MBSE是建模方法的形式化应用,以使建模方法支持系统需求、分析、设计、验证和确认等活动,持续贯穿到所有生命周期阶段。产物包括:在需求分析阶段,产生需求图、用例图及包图;在功能分析与分配阶段,产生顺序图、活动图及状态机(State Machine)图;在设计综合阶段,产生模块定义图、内部块图及参数图等。系统工程的三大支柱:建模语言、建模工具和建模思路。
6.2 系统性能
【基础知识点】
- 系统性能评价
系统性能评价指标是软件、硬件的性能指标的集成。其中:
(1)评价计算机的主要性能指标有时钟频率(主频)、运算速度、运算精度、数据处理速率(Processing Data Rate,PDR)、吞吐率等。
(2)评价路由器的主要性能指标有设备吞吐量、端口吞吐量、全双工线速转发能力、路由表能力、背板能力、丢包率、时延、时延抖动、协议支持等。评价交换机所依据的性能指标有端口速率、背板吞吐量、缓冲区大小、MAC地址表大小等。
(3)评价网络的性能指标有设备级性能指标、网络级性能指标、应用级性能指标、用户级性能指标和吞吐量。
(4)评价操作系统的性能指标有系统上下文切换、系统响应时间、系统的吞吐率(量)、系统资源利用率、可靠性和可移植性。
(5)衡量数据库管理系统的主要性能指标有最大并发事务处理能力、负载均衡能力、最大连接数等。
(6)评价Web服务器的主要性能指标有最大并发连接数、响应延迟和吞吐量。
- 性能指标计算
主要方法有定义法、公式法、程序检测法和仪器检测法。计算公式主要有:
(1)每秒百万次指令数(Millions of Instructions Per Second,MIPS)
$$ \text{MIPS} = \frac{\text{指令条数}}{\text{执行时间} \times 10^6} $$
(2)峰值计算,是指计算机每秒钟能完成的浮点计算最大次数。包括理论浮点峰值和实测浮点峰值。
理论浮点峰值 $= \mathrm{CPU}$ 主频 $\times \mathrm{CPU}$ 每个时钟周期执行浮点运算的次数 $\times$ 系统中CPU数
(3)等效指令速度法或吉普森(Gibson)法,早期用加法指令的运算速度来衡量计算机的速度,后来发展为各个指令的运算时间乘以占比。通常加、减法指令占 $50%$ ,乘法指令占 $15%$ ,除法指令占 $5%$ ,程序控制指令占 $15%$ ,其他指令占 $15%$ 。
$$ 等效指令时间 T = \sum_{i=1}^{n} W_i \times T_i $$
式中:Wi为第 $i$ 种指令的使用占比;Ti为第 $i$ 种指令的运算时间。
- 性能调整
性能调整由查找和消除瓶颈组成。对于数据库系统,性能调整主要包括CPU/内存使用状况、优化数据库设计、优化数据库管理以及进程/线程状态、硬盘I/O及剩余空间、日志文件大小等。对于应用系统,性能调整主要包括应用系统的可用性、响应时间、并发用户数以及特定应用的系统资源占用等。
- 阿姆达尔(Amdalal)解决方案
阿姆达尔定律:计算机系统中对某一部件采用某种更快的执行方式所获得的系统性能改变程度,取决于这种方式所占总执行时间的比例。加速比的定义:
$$ \text{加速比} = \frac{\text{使用增强部件时完成整个任务的时间}}{\text{不使用增强部件时完成整个任务的时间}} $$
$$ \text{新的执行时间} = \text{原来的执行时间} \times \Big[(1 - \text{增强比例}) + \frac{\text{增强比例}}{\text{增强加速比}}\Big] $$
$$ \text{总加速比} = \frac{\text{原来的执行时间}}{\text{新的执行时间}} = \frac{1}{(1 - \text{增强比例}) + \frac{\text{增强比例}}{\text{增强加速比}}} $$
Amdahl 定律表明
[\text{系统加速比} = \frac{1}{(1 - f_e) + \frac{f_e}{r_e}}] 其中:
- ( f_e ):计算机执行某个任务的总时间中可被改进部分的时间所占百分比;
- ( r_e ):改进部分采用改进措施后比没有采用改进措施前性能提高的倍数。
利用这个公式,若 ( f_e = 0.9 )、( 系统加速比 = 5 ),
则re为:
[\text{系统加速比}=5 = \frac{1}{(1 - 0.9) + \frac{0.9}{re}} ]
re=9
即该功能的处理速度约提高 3.6 倍。
加速比主要取决于两个因素:在原有的计算机上,能被改进并增强的部分在总执行时间中所占的比例,这个值称为增强比例,它永远小于等于1;通过增强的执行方式所取得的改进,即如果整个程序使用了增强的执行方式,那么这个任务的执行速度会有多少提高,这个值是在原来条件下程序的执行时间与使用增强功能后程序的执行时间之比。
- 性能评估
性能评估主要包括:
(1)基准测试程序(Benchmark)定义:应用程序中用得最多、最频繁的那部分核心程序。
基准测试程序中,评测的准确程度依次递减:真实的程序、核心程序、小型基准程序和合成基准程序。基准测试程序有整数测试程序Dhrystone、浮点测试程序Linpack、Whetstone基准测试程序、SPEC基准测试程序和TPC基准程序。
(2)Web服务器的性能评测方法有基准性能测试、压力测试和可靠性测试。
(3)系统监视的方法通常有系统内置命令、查阅系统日志、可视化技术3种方式。
6.3 练习题
- 霍尔等人于1969年提出了系统方法的三维结构体系,通常称为霍尔三维结构,这是系统工程方法论的基础。霍尔三维结构以时间维、(1)维、知识维组成的立体结构概括性地表示出系统工程的各阶段、各步骤以及所涉及的知识范围。其中时间维是系统的工作进程,对于一个具体的工程项目,可以分为7个阶段,在(2)阶段会做出研制方案及生产计划。
(1)A.空间 B.结构 C.组织 D.逻辑
(2)A.规划 B.拟定 C.研制 D.生产
解析:霍尔的三维结构,是美国系统工程专家霍尔等人于1969年提出的一种系统工程方法论,形成了由时间维、逻辑维和知识维组成的三维空间结构。
时间维分为规划、拟订方案、研制、生产、安装、运行、更新7个时间阶段,各阶段工作如下:
$(1)$ 规划阶段。即调研、程序设计阶段,目的在于谋求活动的规划与战略。
$(2)$ 拟订方案。提出具体的计划方案。
$(3)$ 研制阶段。作出研制方案及生产计划。
$(4)$ 生产阶段。生产出系统的零部件及整个系统,并提出安装计划。
$(5)$ 安装阶段。将系统安装完毕,并完成系统的运行计划。
$(6)$ 运行阶段。系统按照预期的用途开展服务。
$(7)$ 更新阶段。即为了提高系统功能,取消旧系统而代之以新系统,或改进原有系统,使之更加有效地工作。
答案:D C
- 对计算机评价的主要性能指标有时钟频率、(1)、运算精度和内存容量等。对数据库管理系统评价的主要性能指标有(2)、数据库所允许的索引数量和最大并发事务处理能力等。
(1)A.丢包率 B.端口吞吐量 C.可移植性 D.数据处理速率
(2)A.MIPS B.支持协议和标准 C.最大连接数 D.时延抖动
解析:性能指标,是软、硬件的性能指标的集成。在硬件中,包括计算机、各种通信交换设备、各类网络设备等;在软件中,包括:操作系统、协议以及应用程序等。
评价计算机的主要性能指标有时钟频率(主频)、运算速度、运算精度、数据处理速率(ProcessingDataRate,PDR)、吞吐率等。
衡量数据库管理系统的主要性能指标有最大并发事务处理能力、负载均衡能力、最大连接数等。
答案:D C
- 峰值MIPS(每秒百万次指令数)用来描述计算机的定点运算速度,通过对计算机指令集中基本指令的执行速度计算得到。假设某计算机中基本指令的执行需要5个机器周期,每个机器周期为 $3\mu \mathrm{s}$ ,则该计算机的定点运算速度为()MIPS。
A.8 B.15 C.0.125 D.0.067
解析:峰值MIPS是衡量CPU速度的一个指标。根据题干描述,假设某计算机中基本指令的执行需要5个机器周期,每个机器周期为 $3\mu \mathrm{s}$ ,则该计算机每完成一个基本指令需要 $5\times 3 = 15\mu \mathrm{s}$ 根据峰值MIPS的定义,其定点运算速度为 $1 / 15 = 0.067\mathrm{MIPS}$ ,特别需要注意单位 $\mu \mathrm{s}$ 和百万指令数,在计算过程中恰好抵消。详细计算公式如下:
MIPS = 指令条数/(执行时间 $\times 10^{6}) = 1 / (5\times 3\times 10^{- 6}\times 10^{6}) = 1 / 15 = 0.067$
答案:D
第7小时 软件工程基础知识
7.0 章节考点分析
第7小时主要学习软件工程、需求工程、系统分析与设计、净室软件工程、基于构件的软件工程、软件项目管理等内容。
根据考试大纲,本小时知识点会涉及单项选择题和下午案例分析题,约占$8\sim 15$分,论文也会有涉及。本小时内容较基础,侧重于概念知识和管理知识。根据以往全国计算机技术与软件专业技术资格(水平)考试的出题规律,考查的知识点多来源于教材,扩展内容较少。本小时知识架构如图7.1所示。
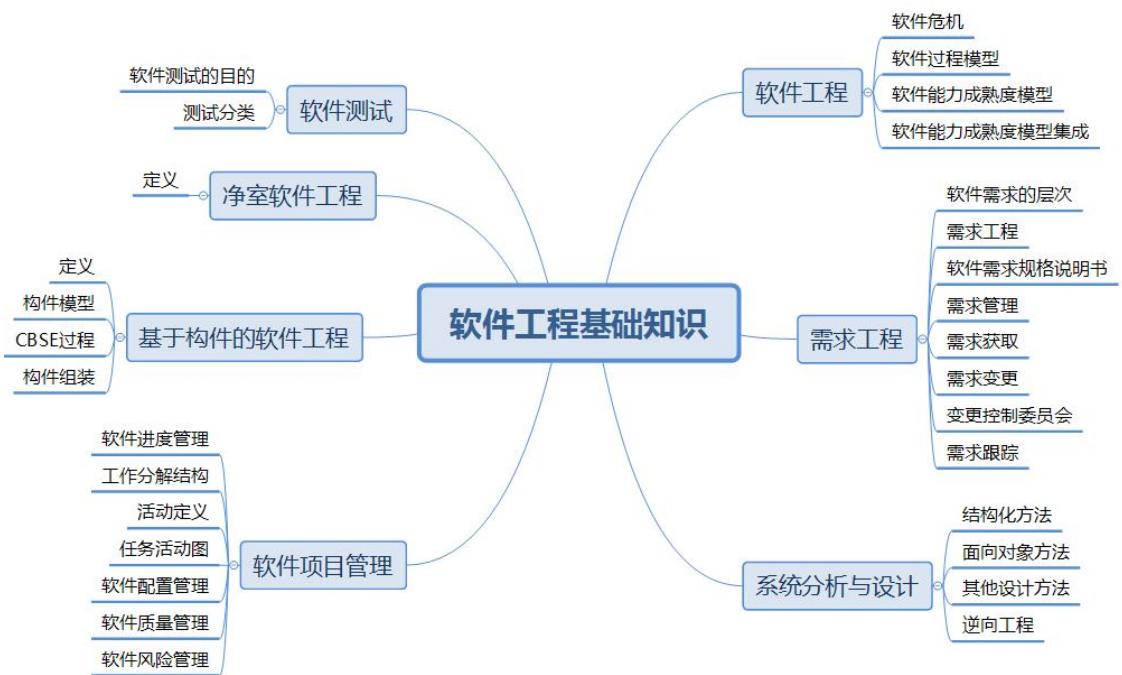
图7.1 本小时知识架构
【导读小贴士】
软件工程是以工程的管理方法去管理软件项目,涉及的知识点很多,也很重要。像结构化和面向对象在三门考试中都会出题,日常开发中也常常需要面对,所以掌握本小时知识点很重要。本小时的内容比较基础,难度并不大。
7.1 软件工程(瀑布模型、4+1视图、RUP、CMMI)
【基础知识点】
(1)软件危机(Software Crisis)。具体表现为:软件开发进度难以预测、软件开发成本难以控制、软件功能难以满足用户期望、软件质量无法保证、软件难以维护和软件缺少适当的文档资料。
(2)软件生命周期模型又称软件开发模型(software develop model)或软件过程模型(sofware process model),软件要经历从需求分析、软件设计、软件开发、运行维护,直至被淘汰这样的全过程,这个全过程就是软件的生命周期。它是从某一个特定角度提出的软件过程的简化描述。软件生存周期的提出是为了更好地管理、维护和升级软件,其中更大的意义在于管理软件开发的步骤和方法。软件过程模型是软件开发实际过程的抽象与概括,它应该包括构成软件过程的各种活动,也就是对软件开发过程各阶段之间关系的一个描述和表示。软件活动主要有如下一些: 1)软件描述。必须定义软件功能以及使用的限制。 2)软件开发。也就是软件的设计和实现,软件工程人员制作出能满足描述的软件。 3)软件有效性验证。软件必须经过严格的验证,以保证能够满足客户的需求。 4)软件进化(演化)。软件随着客户需求的变化不断改进。
按照传统的软件生命周期方法学,可以把软件生命周期划分为软件定义、软件开发、软件运行与维护3个阶段。其主要活动阶段包括:可行性分析与计划制订、需求分析、软件设计(概要设计和详细设计)、软件实现(编码)、测试、维护等活动,其中软件开发阶段包括软件设计、实现与测试。
软件过程构架结构由四个层次组成:方针、过程、规程和第四层的标准、规范、指南、模板、Checklist等组成。 1)方针为第一层文件,它是组织标准软件的高层次的抽象描述,它反映在公司的过程改进总体方针、政策中,由公司主管副总裁批准执行。 2)过程为第二层文件,主要规定在项目开发中执行该过程时应当执行的各项活动及适用标准。过程定义文件及其相关文件制定必须符合方针的要求。 3)规程为第三层文件,是对过程某些复杂活动的具体描述。 4)标准、规范、指南、模板、Checklist、范例库等是对上级过程或规程提供细致的步骤、活动及说明的支持性文档,第四层的文件从属于上级过程。
软件生命周期描述了软件从生到死的全过程。为了使软件生命周期中的各项任务能够有序地按照规程进行,需要一定的工作模型对各项任务给予规程约束,这样的工作模型被称为软件过程模型,有时也称为软件生命周期模型。常见的软件过程模型主要包括:
| 模型 | 核心思想 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 瀑布模型 | 阶段性顺序开发(需求→设计→实现→测试→维护) | 结构清晰、易于管理 | 缺乏灵活性,需求变更代价高 | 需求稳定、项目规模较小 |
| 原型模型 | 先构建原型验证需求,再迭代完善 | 用户早期参与,减少需求偏差 | 可能过度依赖原型,浪费资源 | 用户需求不清晰,需验证可行性 |
| 螺旋模型 | 融合瀑布和原型,强调风险分析,每轮螺旋迭代分为目标设定、风险分析、开发和有效性验证、评审4个阶段 | 风险管理好,灵活 | 成本高,复杂度高 | 大型、复杂、高风险项目 |
| 敏捷模型 | 适应型,而非可预测型;以人为本,而非以过程为本;迭代增量式的开发过程 | 灵活,快速响应变化,价值交付早 | 文档不足,依赖团队素质 | 小团队,快速变化的环境,互联网、创新产品 |
| 软件统一过程模型 (RUP) | 用例驱动、迭代开发、分阶段(初始、细化、构建、移交) | 系统化,适应变更,重视架构 | 过程复杂,学习成本高 | 大中型项目,需求变化频繁 |
| RAD模型 | 快速应用开发,强调原型+工具支持 | 快速交付,用户参与度高 | 适用性受限,需强大工具支持 | 小型到中型、快速交付项目 |
| 增量模型 | 分阶段构建,每次交付部分可运行系统 | 降低变更成本,用户早期反馈,价值快速实现 | 架构需提前设计好,整体规划要求高 | 中大型项目,需求可能演进,需快速交付 |
| 演化模型 | 逐步完善,系统随着用户反馈逐渐演化 | 灵活,适应变更 | 过程难以控制,可能无止境 | 需求不明确,需要渐进式明确的系统 |
| 喷泉模型 | 面向对象,开发过程迭代、并行(不严格顺序) | 支持迭代和复用 | 管理复杂,不易掌控进度 | 面向对象开发项目 |
| V模型 | 瀑布的扩展,验证与确认对应,强调测试 | 测试贯穿始终,质量保证 | 需求变更代价大 | 安全性、可靠性要求高的系统 |
| 基于可重用构件的模型 | 通过已有软件构件组装新系统 | 开发效率高,降低成本 | 依赖构件库,灵活性受限 | 构件库丰富的环境、大型企业项目 |
| 形式化方法模型 | 使用数学方法描述与验证系统,确保逻辑正确性 | 严谨、精确、可证明正确 | 开发成本高,难以推广 | 对安全性、可靠性、精确性要求极高的系统(如航空、核电、金融系统) |
| 净室软件工程(Cleanroom) | 使用盒结构规约进行分析和建模,并且将正确性验证作为发现和排除错误的主要机制,使用统计测试来获取认证软件可靠性所需要的信息。强调在规约和设计上的严格性,还强调统计质量控制技术,包括基于客户对软件的预期使用测试。 | 提高软件可靠性,缺陷率极低 | 开发成本高,对人员要求高 | 对质量、可靠性、无错误运行要求极高的系统(如军工、航空、航天) |
1)瀑布模型(Waterfall Model),如图7.2所示,是结构化开发方法使用的软件过程模型。可以说是最早使用的软件生存周期模型之一。由于这个模型描述了软件生存的一些基本过程活动,所以它被称为软件生存周期模型。这些活动从一个阶段到另一个阶段逐次下降,形式上很像瀑布。瀑布模型的特点是因果关系紧密相连,前一个阶段工作的输出结果,是后一个阶段工作的输入。或者说,每一个阶段都是建立在前一个阶段的正确结果之上,前一个阶段的错误和疏漏会隐蔽地带入后一个阶段。这种错误有时甚至可能是灾难性的,因此每一个阶段工作完成后,都要进行审查和确认。每一个阶段工作完成后都伴随着一个里程碑。缺点是需求难以一次确定、变更的代价高、结果难以预见、各阶段工作不能并行。
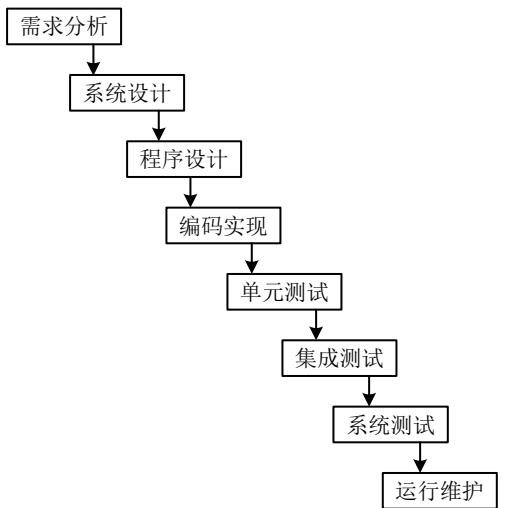
图7.2 瀑布模型
2)原型模型(Prototype Model),如图 7.3 所示,又称快速原型,是原型方法使用的生命周期模型。原型模型解决了瀑布模型需求难以一次确定、结果难以预见的缺点。原型模型有原型开发和目标软件开发两个阶段: ①原型开发阶段。软件开发人员根据用户提出的软件系统的定义,快速地开发一个原型。该原型应该包含目标系统的关键问题和反映目标系统的大致面貌,展示目标系统的全部或部分功能、性能等。 ②目标软件开发阶段。在征求用户对原型的意见后对原型进行修改完善,确认软件系统的需求并达到一致的理解,进一步开发实际系统。
抛弃型原型将原型作为需求确认的手段,在需求确认结束后就被抛弃不用,继续用瀑布模型。演化性原型在需求确认结束后,不断补充和完善原型,直至形成一个完整的产品。
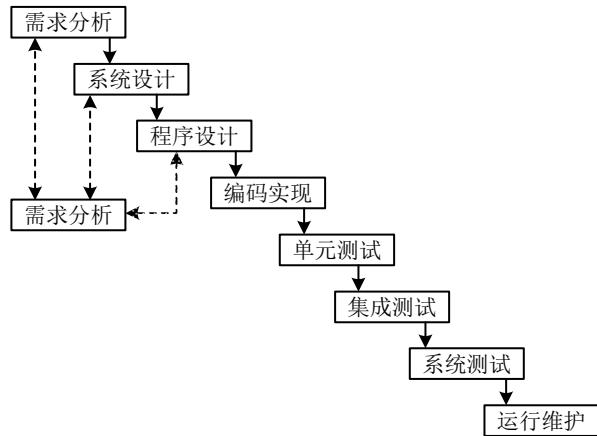
图7.3 原型模型
3)螺旋模型(Spiral Model),如图 7.4 所示,是在快速原型的基础上结合瀑布模型件开发流程分成多个阶段,每一个阶段都由目标设定、风险分析、开发和有效性验证、评审4部分组成。支持大型软件开发,适用于面向规格说明、面向过程和面向对象的软件开发方法,强调其他模型忽视的风险分析。
①目标设定。为该项目进行需求分析,定义和确定这一个阶段的专门目标,指定对过程和产品的约束,并且制定详细的管理计划。 ②风险分析。对可选方案进行风险识别和详细分析,制定解决办法,采取有效的措施避免这些风险。 ③开发和有效性验证。风险评估后,可以为系统选择开发模型,并且进行原型开发,即开发软件产品。 ④评审。对项目进行评审,以确定是否需要进入螺旋线的下一次回路,如果决定继续,就要制定下一阶段计划。
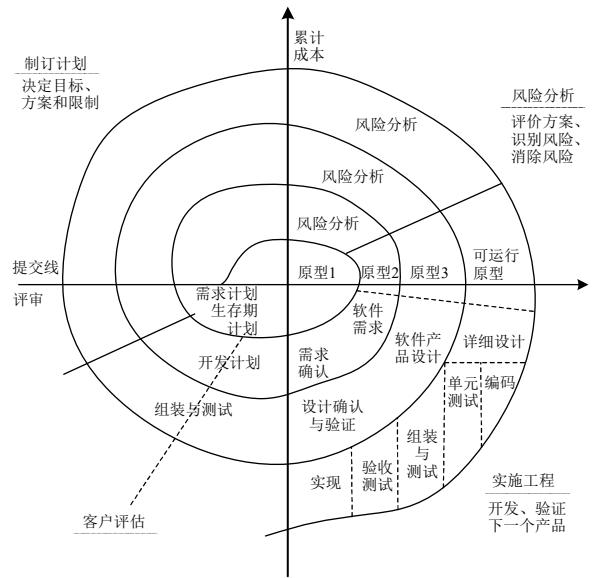
图7.4 螺旋模型
4)敏捷模型(Agile),属于敏捷方法使用的模型。敏捷方法遵循迭代增量式开发过程,以原型开发思想为基础,是适应型、非可预测型,以人为本而非以过程为本。敏捷模型主要有极限编程(Extreme Programming,XP)、水晶系列方法、并列争球法(Scrum)、特征驱动开发方法(Feature Driven Development,FDD) 等具体的敏捷方法,这些方法的显著特征如下:
极限编程(XP):,成本低、高效、低风险、测试先行(先写测试代码,再编写程序)。
水晶系列方法:它与XP方法一样,都有以人为中心的理念,但在实践上有所不同。Alistair考虑到人们一般很难严格遵循一个纪律约束很强的过程,因此,与XP的高度纪律性不同,Alistair探索了用最少纪律约束而仍能成功的方法,从而在产出效率与易于运作上达到一种平衡。也就是说,虽然水晶系列不如XP那样的产出效率,但会有更多的人能够接受并遵循它。
并列争球法(Scrum):该方法侧重于项目管理。Scrum包括一系列实践和预定义角色的过程骨架(是一种流程、计划、模式,用于有效率地开发软件)。在Scrum中,使用产品Backlog来管理产品的需求,产品Backlog是一个按照商业价值排序的需求列表。根据Backlog的内容,将整个开发过程分为若干个短的迭代周期(Sprint),在Sprint中,Scrum团队从产品Backlog中挑选最高优先级的需求组成Sprint Backlog。在每个迭代结束时,Scrum团队将递交潜在可交付的产品增量。当所有Sprint结束时,团队提交最终的软件产品。该方法强调这样一个事实,即明确定义了的可重复的方法过程只限于在明确定义了的可重复的环境中,为明确定义了的可重复的人员所用,去解决明确定义了的可重复的问题。
功用驱动开发方法(FDD-feature Driven Development) 像其他方法一样,它致力于短时的选代阶段和可见可用的功能。在FDD中,一个选代周期一般是两周。在FDD中,编程开发人员分成两类:首席程序员和“类"程序员(class owner)。首席程序员是最富有经验的开发人员,他们是项目的协调者、设计者和指导者,而“类”程序员则主要做源码编写。
ASD(Adaptive Sofware Development)方法由Jim Highsmith提出,其核心是三个非线性的、重叠的开发阶段:猜测、合作与学习。
| 方法 | 特点/理念 | 关键做法或角色 | 关键词 |
|---|---|---|---|
| 极限编程(XP) | 成本低、高效、低风险,测试先行(先写测试代码,再写程序) | 强调结对编程、持续集成、重构、用户故事驱动 | 测试先行、结对编程 |
| 水晶系列方法(Crystal) | 最少纪律约束而仍能成功的方法;在生产率与易于运行之间达到一种平衡 | 团队灵活调整流程,更易被人员接受 | 灵活、低纪律 |
| 并列争球法(Scrum) | 项目管理框架,强调迭代开发(Sprint),使用Backlog管理需求 | 产品Backlog → Sprint Backlog,迭代增量交付 | Sprint、Backlog |
| 功用驱动开发方法(FDD) | 短的迭代阶段,交付可见和可用的功能;每次迭代一般两周 | 首席程序员、类程序员;面向特征的设计与编码 | 特征、类、迭代 |
| 自适应软件开发(ASD) | 三个非线性阶段:猜测、合作、学习 | 强调灵活适应、持续改进 | 猜测、合作、学习 |
5)软件统一过程模型(Rational Unified Process,RUP)。
①RUP的三个核心特点是:以架构为中心,用例驱动,增量与选代。 增量与迭代的好处是:
- 降低了在一个增量上的开支风险。如果开发人员重复某个选代,那么损失只是这一个开发有误的选代的花费。
- 降低了产品无法按照既定进度进入市场的风险。通过在开发早期就确定风险,可以尽早来解决而不至于在开发后期匆匆忙忙。
- 加快了整个开发工作的进度。因为开发人员清楚问题的焦点所在,他们的工作会更有效率。
- 由于用户的需求并不能在一开始就作出完全的界定,它们通常是在后续阶段中不断细化的。
②4个阶段 RUP生命周期是一个二维的软件开发模型,划分为多个循环(Cycle),每个循环生成产品的一个新的版本,每个循环依次由初始化、细化、构造和移交4个连续的阶段(Phase)组成,每个阶段完成确定的任务。RUP在每次迭代中,只考虑系统的一部分需求,进行分析、设计、实现、测试和部署等过程。
初始阶段:定义最终产品视图和业务模型,并确定系统范围。 细化阶段:设计及确定系统的体系结构,制定工作计划及资源要求。 构造阶段:构造产品并继续演进需求、体系结构、计划直至产品提交。 移交阶段:把产品提交给用户使用。
③9个核心工作流,这9个核心工作流分别是:【6个核心过程工作流】业务建模、需求、分析与设计、实现、测试、部署、【3个核心支持工作流】配置与变更管理、项目管理、环境。RUP的特点是【用例驱动的、以架构为中心的、迭代和增量的软件开发过程】。
1)商业(业务)建模(Business Modeling):商业建模工作流描述了如何为新的目标组织实现一个构想,并基于这个构想在商业用例模型和商业对象模型中定义组织的过程、角色和责任。 2)需求(Requirements):需求工作流的目标是描述系统应该做什么,并使开发人员和用户就这一描述达成共识。为了达到该目标,要对需要的功能和约束进行提取、组织、文档化;最重要的是理解系统所解决问题的定义和范围。 3)分析和设计(Analysis & Design):分析和设计工作流将需求转化成未来系统的设计,为系统开发一个健壮的结构并调整设计使其与实现环境相匹配,优化其性能。 4)实现(lmplementation):实现工作流的目的包括以层次化的子系统形式定义代码的组织结构;以组件的形式(源文件、二进制文件、可执行文件)实现类和对象;将开发出的组件作为单元进行测试以及集成由单个开发者(或小组)所产生的结果,使其成为可执行的系统。 5)测试(Test):测试工作流要验证对象间的交互作用,验证软件中所有组件的正确集成,检验所有的需求已被正确的实现,识别并确认缺陷在软件部署之前被提出并处理。 6)部署(Deployment):部署工作流的目的是成功的生成版本并将软件分发给最终用户。 7)配置和变更管理(Configuration& Change Management):配置和变更管理工作流描绘了如何在多个成员组成的项目中控制大量的产物。 8)项目管理(Proiect Management):软件项目管理平衡各种可能产生冲突的目标、管理风险,克服各种约束并成功交付使用户满意的产品。其目标包括:为项目的管理提供框架,为计划、人员配备、执行和监控项目提供实用的准则,为管理风险提供框架等。 9)环境(Environment):环境工作流的目的是向软件开发组织提供软件开发环境,包括过程和工具。
④4+1视图模型来描述架构,如图7.5所示,后被UML吸收采纳。
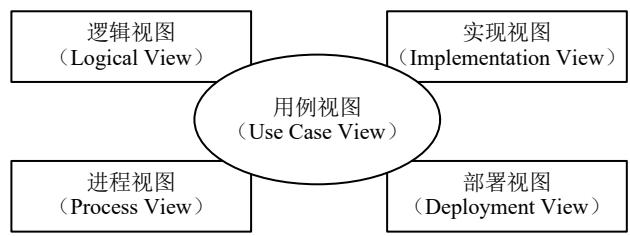
图7.5 4+1视图模型
| 视图名称 | 别名 | 主要对应角色 | 核心关注点 | 描述内容 | 常用建模图 |
|---|---|---|---|---|---|
| 逻辑视图(Logical View) | 设计视图 | 最终用户 | 功能性需求、系统组成与交互方式 | 表示系统在架构上具有重要意义的部分(类、子系统、包、用例实现等),用于建模系统的结构与协作关系 | 类图、对象图、状态图、协作图 |
| 实现视图(Implementation View) | 开发视图 | 程序员 | 模块组织结构、开发环境下的软件静态组织 | 描述系统各部分如何被组织成模块和组件,体现开发环境中的组织方式 | 包图、组件图 |
| 进程视图(Process View) | 过程视图 | 系统集成人员 | 系统运行特性、并发性与同步结构 | 描述系统的可执行线程与进程,关注非功能性需求,如性能、可用性、容错性 | 活动图 |
| 部署视图(Deployment View) | 物理视图 | 系统工程师 | 软件与硬件映射、系统拓扑结构 | 展示如何将软件映射到硬件上,考虑性能、可靠性、通信与安装问题 | 部署图 |
| 用例视图(Use Case View) | 场景视图 | 分析人员、测试人员 | 系统功能需求的外部表现 | 作为其他四个视图的指导和整合核心,通过场景描述系统的使用方式 | 用例图 |
- 逻辑视图:又叫设计视图,对应最终用户,主要支持功能性需求,它表示了设计模型中在架构方面具有重要意义的部分,即类、子系统、包和用例实现的子集。用于建模系统的组成部分以及各组成部分之间的交互方式。通常包括类图,对象图,状态图和协作图。
- 实现视图:又叫开发视图,对应程序员,关注软件开发环境下实际模块的组织,描述系统的各部分如何被组织为模块和组件即开发环境中软件的静态组织结构。该视图通常包含包图和组件图。
- 进程视图:又叫过程视图,对应系统集成人员,进程视图侧重于系统的运行特性,是可执行线程和进程作为活动类的建模,它是逻辑视图的一次执行实例,描述了并发与同步结构。描述了系统中的进程,当可视化系统中一定会发生的事情时,此视图特别有用。考虑一些非功能性的需求,如性能和可用性,它可以解决并发性、分布性、系统完整性、容错性的问题。进程视图常用活动图表示。
- 部署视图:又叫物理视图,对应系统工程师。描述如何将前三个视图中所述的系统设计实现为一组现实世界的实体。展示了如何把软件映射到硬件上,它通常要考虑到系统性能、规模、可靠性等。解决系统拓扑结构、系统安装、通信等问题。部署视图常用部署图表示。
- 用例视图:又称场景视图,对应分析、测试人员,所有其他视图都依靠用例视图(场景)来指导它们,这就是将模型称为4+1的原因。
6) 快速应用开发(Rapid Application Development,RAD)是一种比传统生存周期法快得多的开发方法,它强调极短的开发周期。RAD模型是瀑布模型的一个高速变种,通过使用基于构件的开发方法获得快速开发。如果需求理解得很好,且约束了项目范围,利用这种模型可以很快地开发出功能完善的信息系统。但是RAD也具有以下局限性:
①并非所有应用都适合RAD。RAD对模块化要求比较高,如果有哪一项功能不能被模块化,那么RAD所需要的构建就会有问题;如果高性能是一个指标,且该指标必须通过调整接口使其适应系统构件才能获得,则RAD也有可能不能奏效。 ②开发者和客户必须在很短的时间完成一系列的需求分析,任何一方配合不当,都会导致RAD项目失败。 ③RAD只能用于管理信息系统的开发,不适合技术风险很高的情况。例如,当一个新系统要采用很多新技术,或当新系统与现有系统有较高的互操作性时,就不适合使用RAD。
7)V模型是一种典型的测试模型。在V模型中测试过程被加在开发过程的后半部分,分别包括单元测试、集成测试、系统测试和验收测试。
8)增量式模型(Incremental Model)。 增量式开发相比于瀑布模型的一些重要优点: ①降低了适应用户需求变更的成本。重新分析和修改文档的工作量较之瀑布模型要少很多。 ②在开发过程中更容易得到用户对于已做的开发工作的反馈意见。 ③用户可以评价软件的现实版本,并可以看到已经实现了多少。这比让用户从软件设计文档中判断工程进度要好很多。 ④使更快地交付和部署有用的软件到客户方变成了可能,虽然不是所有的功能都已经包含在内。 ⑤相比于瀑布模型,用户可以更早地使用软件并创造商业价值。
增量模型的缺点:过程不可见。管理人员需要常规的交付物来掌握进度。如果系统是快速开发的,那么要产生每个版本的文档就很不划算。伴随新的增量的加入,系统结构会退化。敏捷方法建议定期对软件重构。面对大型、复杂以及长生命周期的系统,增量模型的以上缺点更为突出。大型系统不同部分由不同团队开发,需要稳定的框架或体系结构,这种体系结构需要事先进行计划而不是增量地开发。
9)演化模型 演化模型主要针对事先不能完整定义需求的软件开发,是在快速开发一个原型的基础上,根据用户在试用原型的过程中提出的反馈意见和建议,对原型进行改进,获得原型的新版本,重复这一过程,直到演化成最终的软件产品。 优点:任何功能一经开发就能进入测试,以便验证是否符合产品需求,可以帮助引导出高质量的产品要求。 缺点:如果不加控制地让用户接触开发中尚未测试稳定的功能,可能对开发人员及用户都会产生负面的影响。
(3)软件能力成熟度模型(Capability Maturity Model for Software,CMM)。CMM是一个概念模型,被广泛用来指导软件过程改进。模型框架和表示是刚性的,不能随意改变,但模型的解释和实现有一定弹性。该模型描述了软件过程能力的5个成熟度级别,每一级都包含若干关键过程域(Key Process Areas,KPA)。CMM的第二级为可重复级,它包括了6个关键过程域,分别是:需求管理、软件项目计划、软件项目跟踪和监督、软件分包合同管理、软件质量保证和软件配置管理。
| 等级 | 名称 | 核心特点 |
|---|---|---|
| 1 | 初始级(Initial) | 过程无序、不稳定,依赖个人能力,成功主要依赖英雄式努力,缺乏标准化管理 |
| 2 | 可重复级(Repeatable) | 建立基本项目管理流程,可重复成功的项目实践;包括6个关键过程域:需求管理、软件项目计划、软件项目跟踪和监督、软件分包合同管理、软件质量保证、软件配置管理 |
| 3 | 已定义级(Defined) | 组织级标准化过程,将项目管理和软件工程过程文档化,并在整个组织推广 |
| 4 | 量化管理级(Quantitatively Managed) | 通过量化指标管理过程,使用统计和度量方法控制项目过程和产品质量 |
| 5 | 优化级(Optimizing) | 持续过程改进,识别弱点和改进机会,推动创新和最佳实践在组织内应用 |
| 对比维度 | CMM(软件能力成熟度模型) | 软件开发模型(瀑布、敏捷、螺旋等) |
|---|---|---|
| 定义定位 | 一种过程改进模型,用于评估与提升组织的软件开发能力成熟度 | 一种开发过程模型,用于指导项目的软件开发活动与生命周期 |
| 关注层面 | 组织级(宏观) —— 关注整个企业或团队的软件工程管理水平 | 项目级(微观) —— 关注单个项目的开发实施方式 |
| 目标目的 | 提升组织过程能力,实现可预测、高质量的软件交付 | 规范项目开发流程,确保项目顺利完成与交付 |
| 核心内容 | 由5个成熟度等级组成:初始级 → 可管理级 → 已定义级 → 量化管理级 → 优化级 | 各模型有不同开发阶段:如瀑布模型(线性)、螺旋模型(风险驱动)、敏捷模型(迭代增量) |
| 输出成果 | 过程改进、标准化体系、度量指标 | 可运行的软件产品 |
| 实施主体 | 组织管理层与过程改进团队(SEPG) | 项目团队(开发、测试、设计等) |
| 时间跨度 | 长期、持续改进(提升组织整体能力) | 短期、项目周期内实施(完成单个产品开发) |
| 典型应用 | 政府、军工、大型软件企业的过程改进与质量认证(如CMMI认证) | 软件项目的开发与交付(如Web系统、移动应用等) |
| 关系 | CMM是组织改进框架,指导如何规范开发过程;软件开发模型是具体实施方法。 | 开发模型可作为CMM实践落地的具体手段。 |
| 比喻理解 | 像是企业的“管理体系建设” | 像是项目的“施工图纸和操作流程” |
(4)软件能力成熟度模型集成(Capability Maturity Model Integration for Software,CMMI)。CMMI是在CMM的基础上发展而来的。CMMI提供了一个软件能力成熟度的框架,它将软件过程改进的步骤组织成5个成熟度等级:初始级、已管理级、已定义级、量化管理级、优化级。量化管理级与已定义级的区别是对过程性能的可预测。 ①初始级(Initial):软件过程是无序的,有时甚至是混乱的,对过程几乎没有定义,成功取决于个人努力。管理是反应式的。 ②管理级(Managed):建立了基本的项目管理过程来跟踪费用、进度和功能特性。制定了必要的过程纪律,能重复早先类似应用项目取得的成功经验。 ③定义级(Defined):已将软件管理和工程两方面的过程文档化、标准化,并综合成该组织的标准软件过程。所有项目均使用经批准、剪裁的标准软件过程来开发和维护软件,软件产品的生产在整个软件过程是可见的。 ④定量管理级(Q- Managed):分析对软件过程和产品质量的详细度量数据,对软件过程和产品都有定量的理解与控制。管理有一个作出结论的客观依据,管理能够在定量的范围内预测性能。 ⑤优化级(Optimizing):过程的量化反馈和先进的新思想、新技术促使过程持续不断改进。在CMMI的已定义级中,开发过程,包括技术工作和管理工作,均已实现标准化、文档化。建立了完善的培训制度和专家评审制度,全部技术活动和管理活动均可控制,对项目进行中的过程、岗位和职责均有共同的理解。
| 级别 | 英文名 | 核心特征 | 关键点 | 理解比喻 |
|---|---|---|---|---|
| 1️⃣ 初始级(Initial) | Chaos 模式 | 无标准、无规范、全靠个人 | 成功靠“英雄”式努力 | 像是创业早期的小团队,没流程、没标准,老板今天灵感来了就改方向。 |
| 2️⃣ 已管理级(Managed) | 有计划、有控制 | 建立基本的项目管理制度:进度、成本、质量可控 | “项目可重复” | 像是公司开始懂得用 Excel 管项目、开会记录、制定计划,不再全靠感觉。 |
| 3️⃣ 已定义级(Defined) | 有标准、有制度 | 整个组织统一流程、文档化、标准化 | “流程可复制” | 像是公司内部形成 SOP(标准作业流程),每个部门都按标准做。 |
| 4️⃣ 定量管理级(Quantitatively Managed) | 有数据、有测量 | 对过程和产品都进行量化分析与控制 | “结果可预测” | 像是公司开始统计缺陷率、开发周期、测试效率,用数据预测项目风险。 |
| 5️⃣ 优化级(Optimizing) | 有反馈、有创新 | 基于量化反馈,持续优化过程,引入新技术 | “持续改进” | 像是公司形成 PDCA 循环,不断优化流程,主动改进、追求卓越。 |
7.2 需求工程
【基础知识点】
- 软件需求的层次
软件需求包括3个不同的层次:
(1)业务需求(Business Requirement),反映了组织机构或客户对系统、产品高层次的目标要求。 (2)用户需求(User Requirement),描述了用户使用产品必须要完成的任务,是用户对该软件产品的期望。业务需求和用户需求构成了用户原始需求文档的内容。 (3)功能需求(functional requirement),从系统操作的角度定义了开发人员必须实现的软件功能,来满足业务需求和用户需求。 (4)非功能需求包括产品必须遵从的标准、规范和合约以及性能要求等,它对于软件产品的整体质量和用户体验至关重要。
- 需求工程(Requirement Engineering,RE)
需求工程包括需求开发和需求管理两大类活动。 1)需求开发包括:需求获取,需求分析,需求定义,需求验证这些主要活动; 2)需求管理包括:变更控制、版本控制、需求跟踪和需求状态跟踪这些活动。
需求抽取和分析的过程主要分为以下四个步骤:1.需求发现和理解;2.需求分类和组织;3.需求优先级排序和协商;4.需求文档化。 需求抽取有两个基本的方法:1.访谈,开发者和其他人谈论他们做的事情。2.观察或人种学调查,观察人们做自己的工作来了解他们使用哪些制品、他们如何使用这些制品等。
- 软件需求规格说明书(Software Requirement Specification,SRS)
SRS具体包括功能需求、非功能需求和约束。约束包括设计约束和过程约束。批准的SRS是需求开发和需求管理之间的桥梁。
需求开发的结果应该有项目视图和范围文档、用例文档和SRS,以及相关的分析模型。经评审批准,这些文档就定义了开发工作的需求基线。这个基线在客户和开发人员之间就构成了软件需求的一个约定,它是需求开发和需求管理之间的桥梁。
- 需求管理
需求管理是一个对系统需求变更、了解和控制的过程,包括变更控制、版本控制、需求跟踪、需求状态跟踪等活动。 需求管理的目标是为软件需求建立一个基线,提供给软件工程和管理使用:软件计划、产品和活动与软件需求保持一致。
需求跟踪包括编制每个需求与系统元素之间的联系文档,这些元素包括其它需求、体系结构、设计部件、源代码模块、测试、帮助文件和文档等。需求跟踪一般采用需求跟踪矩阵做跟进工作,跟踪矩阵将从需求源头一直跟进到最终的软件产品。
在初步的业务需求描述已经形成的前提下,基于UML的需求分析过程大致可分为以下步骤: ①利用用例及用例图表示需求。从业务需求描述出发获取执行者和场景;对场景进行汇总、分类、抽象,形成用例;确定执行者与用例、用例与用例图之间的关系,生成用例图。 ②)利用包图和类图表示目标软件系统的总体框架结构。根据领域知识、业务需求描述和既往经验设计目标软件系统的顶层架构;从业务需求描述中提取“关键概念”,形成领域概念模型;从概念模型和用例出发,研究系统中主要的类之间的关系,生成类图。
- 需求获取
需求获取是获得系统必要的特征,或者是获得用户能接受的、系统必须满足的约束。需求获取的基本步骤:
(1)开发高层的业务模型。(2)定义项目范围和高层需求。(3)识别用户角色和用户代表。(4)获取具体的需求。(5)确定目标系统的业务工作流。(6)需求整理与总结。
需求获取的方法包括用户面谈、需求专题讨论会、问卷调查、现场观察、原型化方法和头脑风暴法等。
- 需求变更
需求的变更遵循以下流程: (1)问题分析和变更描述。这是识别和分析需求问题或者一份明确的变更提议,以检查它的有效性,从而产生一个更明确的需求变更提议。 (2)变更分析和成本计算。使用可追溯性信息和系统需求的一般知识,对需求变更提议进行影响分析和评估。变更成本计算应该包括对需求文档的修改、系统修改的设计和实现的成本。一旦分析完成并且被确认,应该进行是否执行这一变更的决策。 (3)变更实现。这要求需求文档和系统设计以及实现都要同时修改。如果先对系统的程序做变更,然后再修改需求文档,这几乎不可避免地会出现需求文档和程序的不一致。
图7.6 需求变更管理过程
- 变更控制委员会(Change Control Board,CCB)
CCB由项目所涉及的多方成员共同组成,通常包括用户和实施方的决策人员。CCB是决策机构,不是作业机构,通常CCB的工作是通过评审手段来决定项目是否能变更,但不提出变更方案。过程及操作步骤为制定决策、交流情况、重新协商约定。
- 需求跟踪
需求跟踪提供了由需求到产品实现整个过程范围的明确查阅的能力。需求跟踪的目的是建立与维护需求一设计一编程一测试之间的一致性,确保所有的工作成果符合用户需求。需求跟踪有正向跟踪和逆向跟踪两种方式,合称为双向跟踪。不论采用何种跟踪方式,都要建立与维护需求跟踪矩阵。
需求跟踪有两种方式: (1)正向跟踪。检查《产品需求规格说明书》中的每个需求是否都能在后继工作成果中找到对应点。 (2)逆向跟踪,检查设计文档、代码、测试用例等工作成果是否都能在《产品需求规格说明书》中找到出处。
需求跟踪包括编制每个需求与系统元素之间的联系文档,这些元素包括别的需求、体系结构、其他设计部件、源代码模块、测试、帮助文件和文档等。跟踪能力信息使变更影响分析十分便利,有利于确认和评估实现某个建议的需求变更所必须的工作。
利用需求跟踪能力链(traceabilitylink)可以跟踪一个需求使用的全过程,也就是从初始需求到实现的前后生存期。跟踪能力是优秀需求规格说明书的一个特征,为了实现跟踪能力,必须统一地标识出每一个需求,以便能明确地进行查阅。
 1)客户需求向前追溯到软件需求。这样就能区分出开发过程中或者开发结束后,由于客户需求变更受到影响的软件需求,这也就可以确保软件需求规格说明包括了所有客户需求。
2)从软件需求回溯响应的客户需求。这也就是确认每个软件需求的源头。如果使用实例的形式来描述客户需求,那么客户需求与软件需求之间的跟踪情况就是使用实例和功能性需求。
3)从软件需求向前追溯到下一级工作产品。由于开发过程中系统需求转变为软件需求、设计、编码等,所以通过定义单个需求和特定的产品元素之间的(联系)链,可以从需求向前追溯到下一级工作产品。这种联系链告诉我们每个需求对应的产品部件,从而确保产品部件满足每个需求。
4)从产品部件回溯到软件需求。说明了每个部件存在的原因。如果不能把设计元素、代码段或测试回溯到一个需求,可能存在“画蛇添足”的程序。然而,如果这些孤立的元素表明了一个正当的功能,则说明需求规格说明书漏掉了一项需求。
1)客户需求向前追溯到软件需求。这样就能区分出开发过程中或者开发结束后,由于客户需求变更受到影响的软件需求,这也就可以确保软件需求规格说明包括了所有客户需求。
2)从软件需求回溯响应的客户需求。这也就是确认每个软件需求的源头。如果使用实例的形式来描述客户需求,那么客户需求与软件需求之间的跟踪情况就是使用实例和功能性需求。
3)从软件需求向前追溯到下一级工作产品。由于开发过程中系统需求转变为软件需求、设计、编码等,所以通过定义单个需求和特定的产品元素之间的(联系)链,可以从需求向前追溯到下一级工作产品。这种联系链告诉我们每个需求对应的产品部件,从而确保产品部件满足每个需求。
4)从产品部件回溯到软件需求。说明了每个部件存在的原因。如果不能把设计元素、代码段或测试回溯到一个需求,可能存在“画蛇添足”的程序。然而,如果这些孤立的元素表明了一个正当的功能,则说明需求规格说明书漏掉了一项需求。
- 联合需求计划(Joint Requirement Planning,JRP)
JRP是一个通过高度组织的群体会议来分析企业内的问题并获取需求的过程,它是联合应用开发(JAD)的一部分。JRP的主要意图是收集需求,而不是对需求进行分析和验证。实施JRP时应把握以下主要原则:在JRP实施之前,应制定详细的议程,并严格遵照议程进行;按照既定的时间安排进行;尽量完整地记录会议期间的内容;在讨论期间尽量避免使用专业术语;充分运用解决冲突的技能;会议期间应设置充分的间歇时间;鼓励团队取得一致意见;保证参加JRP的所有人员能够遵守实现约定的规则。
- 系统建议方案
根据项目规模的大小,系统方案既可以单独形成文档(系统建议方案报告、系统方案说明书),也可以合并到可行性研究报告中。如果单独形成文档,其内容和格式与可行性研究报告也是类似的。作为一个正式文档,系统建议方案报告至少应该包含以下内容: (1)前置部分。包括标题、目录和摘要。摘要部分以1~2页的篇幅总结整个系统建议方案报告,提供系统方案中的重要时间、地点、人物、原因,以及系统方案是如何实现的等信息。因为多数高层管理人员没有时间读完整个报 告,他们可能只阅读摘要。因此,摘要部分显得特别重要。 (2)系统概述。包括系统建议方案报告的目的、对问题的陈述、项目范围和报告内容的叙述性解释。 (3)系统研究方法。简要地解释系统建议方案报告中包含的信息是如何得到的,研究工作是如何进行的。例如通过各种调查技术获取用户初步需求,通过座谈和观察获取现有系统的资料等。 (4)候选系统方案及其可行性分析。系统阐述每个候选系统方案,并采用合适的方法进行可行性评价。 (5)建议方案。在对各个候选系统方案进行可行性评价之后,通常会推荐一个解决方案,并且要给出推荐该解决方案的理由。 (6)结论。简要地描述摘要的内容,再次指出系统开发的目标和所建议的系统方案。同时,需要再次强调项目的必要性和可行性,以及系统建议方案报告的价值。 (7)附录。系统分析师认为阅读者可能会感兴趣的所有信息,但这些信息对于理解系统建议方案报告的内容来说不是必要的。
7.3 系统分析与设计(SASD、SD、面向对象、设计模式、逆向、高内聚低耦合)
【基础知识点】 (1)结构化建模方法。结构化建模方法是以过程为中心的技术,可用于分析一个现有的系统以及定义新系统的业务需求。结构化建模方法的基本工具是数据流图(DFD)。 (3)面向对象建模方法。面向对象建模方法将”数据”和“过程“集成到被称为“对象”的结构中,消除了数据和过程的人为分离现象。面向对象建模方法所创建的模型被称为对象模型。随着面向对象技术的不断发展和应用,形成了面向对象的建模标准,即UML(统一建模语言)。UML定义了这些模型图以对象的形式共建一个信息系统或应用系统。 (3)信息建模方法。信息建模方法是从数据的角度对现实世界建立模型,模型是现实系统的一个抽象,它强调在分析和研究过程需求之前,首先研究和分析数据需求。信息建模方法的基本工具是实体联系图(ERD)。
| 建模方法 | 核心思想 / 特点 | 建模侧重点 | 主要工具 / 表示方式 | 典型应用 / 说明 |
|---|---|---|---|---|
| 结构化建模方法(Structured Modeling) | 以过程为中心,关注数据流与处理过程,适合描述系统功能与数据流转关系,自顶向下 | 过程导向(Process-Oriented) | 数据流图(DFD) | 用于分析现有系统或定义新系统的业务需求 |
| 面向对象建模方法(Object-Oriented Modeling) | 将“数据”与“过程”集成为对象,消除两者分离,体现封装、继承与交互思想,自底向上 | 对象导向(Object-Oriented) | UML 图(统一建模语言):包括类图、用例图、时序图等 | 用于对象模型创建与信息系统整体建模 |
| 信息建模方法(Information Modeling) | 从数据角度出发,对现实世界进行抽象建模,先分析数据需求再分析过程需求 | 数据导向(Data-Oriented) | 实体联系图(ERD) | 用于描述数据结构与关系,强调信息逻辑建模 |
| 面向服务建模方法(Service-Oriented Modeling) | 基于服务(Service)为核心,通过服务组合与编排实现系统功能,强调粗粒度、松耦合、可重用与可组合性 | 服务导向(Service-Oriented) | 服务建模语言(SoaML)、BPMN(业务流程建模) | 用于SOA架构设计、微服务系统分析与集成建模 |
软件设计包括四个既独立又相互联系的活动,即数据设计、软件结构设计、人机界面设计和过程设计,这四个活动完成以后就得到了全面的软件设计模型。 1)数据设计:将模型转换成数据结构的定义。好的数据设计将改善程序结构和模块划分,降低过程复杂性。 2)软件结构设计:定义软件系统各主要部件之间的关系。 3)人机界面设计:软件内部,软件和操作系统间以及软件和人之间如何通信。 4)过程设计:系统结构部件转换成软件的过程描述。
- 结构化方法(Structured Analysis and Structured Design,SASD)
结构化方法又称为面向功能的软件开发方法或面向数据流的软件开发方法。针对软件生存周期各个不同的阶段,有结构化分析、结构化设计和结构化编程等方法。
| 阶段 | 全称 | 核心思想 / 特点 | 主要任务 | 关键工具 / 方法 | 关键概念与原则 |
|---|---|---|---|---|---|
| 结构化分析(SA) | Structured Analysis | 以数据流为中心,自顶向下逐层分解;利用图形表达用户功能需求;建立逻辑模型 | 明确目标 → 确定系统范围 → 建立顶层DFD → 分层分解DFD → 检查确认 | 数据流图(DFD)、数据字典(DD、核心)、结构化语言、判定表、判定树 | - 功能建模(DFD)、 - 行为建模(状态图)、 - 数据建模(ER图); - DFD四要素:数据流、处理、数据存储、外部项; - DFD规则:父子图一致、输入输出完整 |
| 结构化设计(SD) | Structured Design | 面向数据流的设计方法,以 SA 产出文档为基础,自顶向下、逐步求精、模块化设计 | 架构设计、接口设计、数据设计、过程设计;分为概要设计与详细设计 | - 概要设计:模块结构图、层次图、HIPO图(层次结构图、IPO(输入输出)); - 详细设计:PAD图(自顶向下、顺序选择循环) 、 盒图、程序流程图(PFD) | 高内聚、低耦合;模块独立性:功能、逻辑、状态三属性;模块外部特性(接口) vs 内部特性(数据与代码) |
| 结构化编程(SP) | Structured Programming | 以控制结构为核心的编程方法;通过顺序、分支、循环三种控制结构构造程序;强调可读性与规范性 | 将设计模型转化为程序实现;使用结构化控制语句;保证程序清晰可维护 | 控制结构:顺序结构、分支结构、循环结构;程序流程图 | 自顶向下、逐步细化;清晰第一,效率第二;规范书写;缩进清晰;算法与数据结构分离;公式:程序 = 算法 + 数据结构 |
(1)结构化分析(Structured Analysis,SA)。SA利用图形表达用户需求中的功能需求,是一种面向数据流的需求分析方法,其基本思想是自顶向下逐层分解。结构化分析具体的建模过程及步骤为明确目标、确定系统范围、建立顶层DFD图、构建第一层 DFD 分解图、开发 DFD 层次结构图、检查确认 DFD 图。DFD 图需要满足规则:父图数据流必须在子图中出现;一个处理至少有一个输入流和一个输出流;一个存储必定有流入和流出;一个数据流至少有一端是处理端;模型表达的信息是全面的、完整的、正确的和一致的。
在结构化分析中,主要进行三个方面的建模:功能建模、行为建模和数据建模。功能建模一般采用DFD,行为建模一般采用状态转换图,数据建模一般采用ER图。使用的手段主要有数据流图(Data Flow Diagram,DFD)、数据字典、结构化语言、判定表以及判定树等。 ①数据流图是进行结构化分析时所使用的模型,是表达系统内数据的流动并通过数据流描述系统功能的一种方法。由4种基本元素组成:数据流、处理/加工、数据存储和外部项。 ②数据字典(Data Dictionary) 是一种标记用户可以访问的数据项和元数据的目录,是对系统中使用的所有数据元素定义的集合,包括数据项、数据结构、数据流、数据存储和处理过程。是在DFD的基础上,对DFD中出现的所有命名元素都加以定义,使得每个图形元素的名字都有一个确切的解释。
1)功能建模是使用功能点的概念来描述系统的功能,并将其分解为各个子功能,以明确系统的功能需求,常用的方法有数据流图(DFD)。DFD描绘信息流和数据输入输出的移动过程。 2)行为建模是描述系统的行为和交互方式,常用的方法有状态转换图(STD)。STD通过描述系统的状态及引起系统状态转换的事件,表示系统的行为。 3)数据建模是通过建立数据模型来描述系统所涉及的数据以及数据之间的关系,通常使用实体关系图(E-R图) 来表示实体之间的关系和属性。E-R图提供了表示实体类型、属性和联系的方法。
(2)结构化设计(Structured Design,SD)。SD 是一种面向数据流的设计方法,以 SRS 和 SA 阶段所产生的数据流图和数据字典等文档为基础,包括架构设计、接口设计、数据设计和过程设计等任务,是一个自顶向下、逐步求精和模块化的过程。 ①架构设计:定义软件系统备主要部件之间的关系。 ①数据设计:将模型转换成数据结构的定义。好的数据设计将改善程序结构和模块划分,降低过程复杂性。 ③接口设计 (人机界面设计) :软件内部,软件和操作系统之间以及软件和人之间如何通信。 ④过程设计:系统结构部件转换成软件的过程描述。确定软件各个组成部分内的算法及内部数据结构,并选定某种过程的表达形式来描述各种算法。
SD 分为概要设计和详细设计两个阶段。 ①概要设计(外部设计) 的主要任务是将软件需求转化为数据结构和软件系统结构。确定软件系统的结构,对系统进行模块划分,确定每个模块的功能、接口和模块之间的调用关系,又称为模块结构图,反映了系统的总体结构。图形有模块结构图、层次图和HIPO图 1)HIPO图(HierarchyplusInput- Process- Output,HIPO)是IBM公司于20世纪70年代中期在层次结构图的基础上推出的一种描述系统结构和模块内部处理功能的工具。HIPO图由层次结构图和IPO图两部分构成, ①层次结构图描述整个系统的设计结构以及各类模块之间的关系 ②IPO图是指结构化设计中变换型结构的输入(Input)、加工(Processing)、输出(Output)。IPO图是对每个模块进行详细设计的工具,它是输入加工输出(INPUT PROCESS OUTPUT)图的简称。主体是处理过程说明,可以采用流程图、判定树/表等来进行描述。
②详细设计(内部设计)的主要任务是为每个模块设计实现的细节。详细设计的表示工具有图形工具、表格工具和语言工具。图形有业务流图、程序流程图(PFD)、问题分析图(Problem Analysis Diagram,PAD)、NS流程图等。 1)N-S图,也被称为盒图或NS图(Nassi- Shneiderman图)。一种在流程图中完全去掉流程线,全部算法写在一个矩形阵内,容易表示嵌套关系和层次关系,并具有强烈的结构化特征。NS图几乎是流程图的同构,任何的NS图都可以转换为流程图,而大部分的流程图也可以转换为NS图 2)PAD 图(Problem Analysis Diagram,问题分析图),也叫问题分析图,用二维树形结构的图表示程序的控制流。PAD图的特点:①自顶向下、逐步分解,适合和结构化程序设计相结合。②用嵌套矩形块来表示控制结构,而不是像流程图那样大量用箭头。③强调顺序、选择、循环三大基本控制结构。 3)程序流程图(Program Flow Diagram)是一种 用图形化符号 描述程序逻辑流程的工具。通过 框图(矩形、菱形、箭头等) 表示程序的步骤、判断、循环等控制结构。直观展示了程序从开始到结束的 执行顺序 和 分支路径。
在SD中,模块是实现功能的基本单位,一般具有功能、逻辑和状态3 个基本属性。模块是指执行某一特定任务的数据结构和程序代码。通常将模块的结构和功能定义为其外部特性,将模块的局部数据和实现该模块的程序代码称为内部特性。模块独立是指每个模块完成相对独立的特定子功能,与其他模块之间的关系最简单。通常用内聚和耦合两个标准来衡量模块的独立性,其设计原则是“高内聚、低耦合”。
内聚表示模块内部各代码成分之间联系的紧密程度,内聚度从高到低的排序见表 7.2。
表7.2 模块的内聚类型 恭顺通过拾罗藕
| 内聚类型 | 描述 |
| 功能内聚 | 各个部分协同完成一个单一功能,缺一不可 |
| 顺序内聚 | 处理元素相关,而且必须顺序执行,通常前一任务的输出是后一任务的输入 |
| 通信内聚 | 所有处理元素集中在一个数据结构的区域上 |
| 过程内聚 | 处理元素相关,而且必须按特定的次序执行 |
| 时间内聚 | 所包含的任务必须在同一时间间隔内执行 |
| 逻辑内聚 | 完成逻辑上相关的一组任务,互相存在调用关系 |
| 偶然内聚 | 完成一组没有关系或松散关系的任务,或者仅仅代码相似 |
耦合表示模块之间联系的程度,耦合度从低到高依次如表 7.1 所示。
表7.1 模块的耦合类型 飞速飙控通宫内
| 耦合类型 | 描述 |
| 非直接耦合 | 两个模块之间没有直接关系,互相不依赖对方 |
| 数据耦合 | 一组模块借助参数表传递简单数据 |
| 标记耦合 | 一组模块通过参数表传递记录等复杂信息(数据结构) |
| 控制耦合 | 模块之间传递的信息中包含用于直接控制模块内部逻辑的信息 |
| 通信耦合 | 一组模块共享了输入或输出 |
| 公共耦合 | 多个模块都访问同一个公共数据环境,公共的数据环境可以是全局数据结构、共享的通信区、内存的公共覆盖区等 |
| 内容耦合 | 一个模块直接访问另一个模块的内部数据、一个模块不通过正常入口跳转到另一个模块的内部、两个模块有一部分程序代码重叠、一个模块有多个入口等 |
(3)结构化编程(Structured Programming,SP)。SP通过顺序、分支和循环三种基本的控制结构可以构造出任何单入口单出口的程序。SP强调:自顶向下,逐步细化;清晰第一,效率第二;书写规范,缩进格式;基本结构,组合而成。P原则:程序 $\coloneqq$ (算法) $^+$ (数据结构)。两者分开设计,以算法(函数或过程)为主。
(4)数据库设计(概念结构设计部分)。概念结构设计建立抽象的概念数据模型,通常采用实体-联系图(Entity Relationship Diagram,E-R图) 来表示。
- 面向对象(Object-Oriented,OO)方法
| 方法 | 核心概念与层次 | 主要原则 / 特征 | 模型或图示 | 典型要素 / 类型 |
|---|---|---|---|---|
| 面向对象分析(OOA) | 模型由 5 个层次(主题层、对象类层、结构层、属性层、服务层)和 5 个活动(标识对象类、标识结构、定义主题、定义属性、定义服务)组成 | 抽象、封装、继承、分类、聚合、关联、消息通信、粒度控制、行为分析 | - 顶层架构图、 - 用例图、 - 领域概念模型 | 分析阶段关注 问题域(What),不涉及实现 |
| 面向对象设计(OOD) | 数据结构与算法被封装到对象中 | 强调 模块化、可复用性、封装性 | - 以包图表示的软件体系结构图、 - 以交互图表示的用例实现图、 - 完整精确的类图、 - 针对复杂对象的状态图、 - 用以描述流程化处理过程的活动图 | 类的三种类型:①实体类(如学生、教师)②控制类(如登录验证)③边界类(如界面、通信协议) |
| 面向对象程序设计(OOP) | 以对象为核心,将系统看作 对象的集合 | 三大特征:①封装 ②继承(取代、包含、受限、特化)③多态 | - 数据流图表示功能模型; - 状态图表示行为模型; - ER图表示数据模型;吧 | 关注 实现阶段(How),通过代码实现类与对象的行为 |
(1)面向对象的分析方法(Object-Oriented Analysis,OOA)。 1)OOA模型由5个层次(主题层、对象类层、结构层、属性层和服务层)和5个活动(标识对象类、标识结构、定义主题、定义属性和定义服务)组成。 2)OOA的基本原则有抽象、封装、继承、分类、聚合、关联、消息通信、粒度控制和行为分析。 3)OOA的5个基本步骤:确定对象和类、确定结构、确定主题、确定属性、确定方法。 4)OOA主要由顶层架构图、用例与用例图、领域概念模型构成。
OOA大致上遵循如下5个基本步骤: (1)确定对象和类。这里所说的对象是对数据及其处理方式的抽象,它反映了系统保存和处理现实世界中某些事物的信息的能力。类是多个对象的共同属性和方法集合的描述,它包括如何在一个类中建立一个新对象的描述, (2)确定结构。结构是指问题域的复杂性和连接关系。类成员结构反映了泛化-特化关系,整体-部分结构反映整 本和局部之间的关系。 (3)确定主题。主题是指事物的总体概貌和总体分析模型。 (4)确定属性。属性就是数据元素,可用来描述对象或分类结构的实例,可在图中给出,并在对象的存储中指定 (5)确定方法。方法是在收到消息后必须进行的一些处理方法:方法要在图中定义,并在对象的存储中指定。对于每个对象和结构来说,那些用来增加、修改、删除和选择的方法本身都是隐含的(虽然它们是要在对象的存储中定义的,但并不在图上给出),而有些则是显示的。答案选择B选项。
根据继承内容,继承可分为 1)取代继承(子对象在继承父对象特性后取代其位置)、 2)包含继承(子对象在完全继承父对象特性后,再继承其他对象的特性,使其能力不少于父对象)、 3)受限继承(子类继承父类功能进行限制,而不是扩展功能)和 4)特化继承(特化继承是指子类是父类的一个特殊版本,子类在父类的基础上进行更具体的定义和细化,但一般不会通过继承多个父类来扩展功能超出原单一父类范围)。
(2)面向对象设计方法(Object-Oriented Design,OOD)。在OOD中,数据结构和在数据结构上定义的操作算法封装在一个对象之中。 1)类封装了信息和行为,是具有相同属性、方法和关系的对象集合的总称。类可以分为3种类型: ①实体类:一般来说是一个名词,通常都是永久性需要存储的,例如教师、学生。 ②控制类:是用于控制用例工作的类,控制对象(控制类的实例)通常控制其他对象或协调其他对象的行为,例如登录验证。 ③边界类:用于封装在用例内、外流动的信息或数据流,例如窗口、通信协议、接口等。 2)设计模型则包含以包图表示的软件体系结构图、以交互图表示的用例实现图、完整精确的类图、针对复杂对象的状态图和用以描述流程化处理过程的活动图等。
(3)面向对象程序设计(Object-Oriented Programming,OOP)。OOP以对象为核心,该方法认为程序由一系列对象组成。 1)OOP的基本特点有封装、继承和多态。 ①封装是指将一个计算机系统中的数据以及与这个数据相关的一切操作组装到一起。 ②继承是指一个对象针对于另一个对象的某些独有的特点、能力进行复制或者延续。继承可以分为4类,分别为取代继承、包含继承、受限继承和特化继承。 ③多态指同一操作作用于不同的对象,可以产生不同的结果。 2)OOP的数据流图表示功能模型;状态图表示行为模型;ER图表示数据模型;
3)设计模式的分类 根据目的分类 ①创建型:单抽原件厂,用来创建对象 ②结构型:想代外祖试乔装,处理类或对象的组合 ③行为型:观摩解放、责备命中、厕撞蝶,描述类与对象之间怎样交互、怎样分配职责 根据作用范围分类:可分为类模式和对象模式 ①类模式用于处理类和子类的关系,这种关系通过继承建立,在编译时就确定了,是一种静态关系。 ②对象模式处理对象间的关系,具有动态关系。
| 分类 | 模式名称 | 描述 | 关键词 |
|---|---|---|---|
| 创建型 | 单例模式(Singleton) | 确保一个类只有一个实例,并提供全局访问点。 | 唯一,全局 |
| 工厂方法模式(Factory Method) | 定义创建对象的接口,让子类决定实例化哪一个类。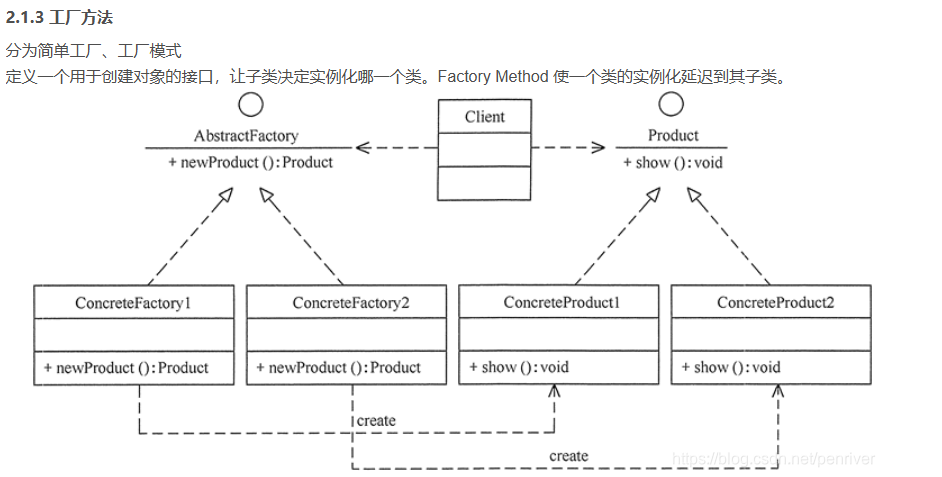 | 接口,子类决定 | |
| 抽象工厂模式(Abstract Factory) | 提供一个接口,用于创建相关或依赖对象的家族,而无需指定其具体类。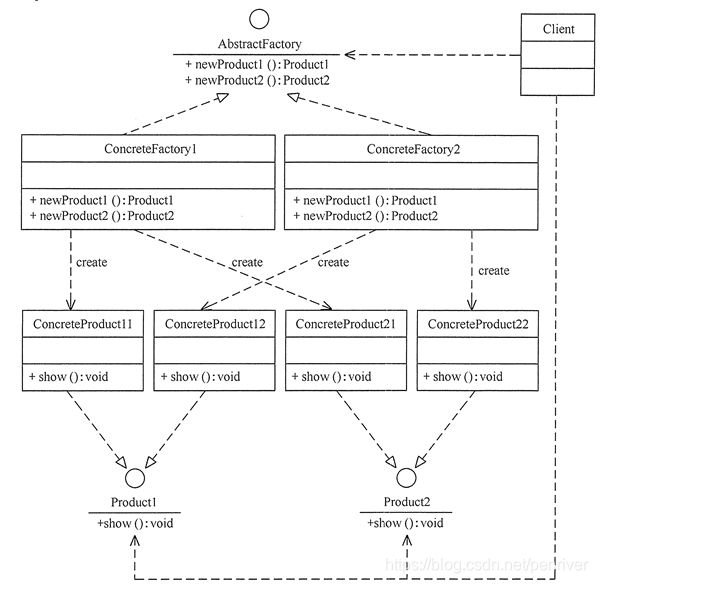 | 产品族,系列对象 | |
| 建造者模式(Builder) | 将一个复杂对象的构建与它的表示分离,使同样的构建过程可以创建不同的表示。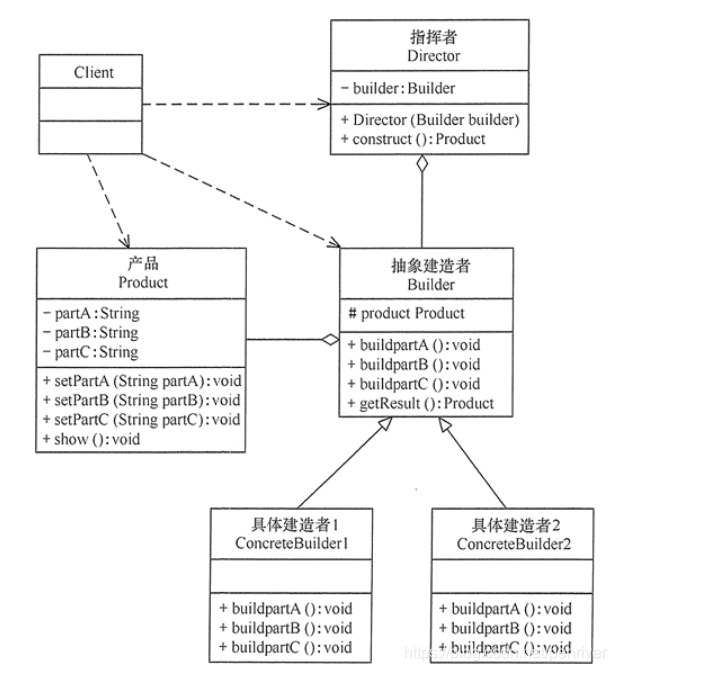 | 复杂对象 | |
| 原型模式(Prototype) | 通过复制已有对象来创建新对象,避免重复初始化。 允许对象在不了解创建对象的确切类以及如何创建细节的情况下创建自定义对象。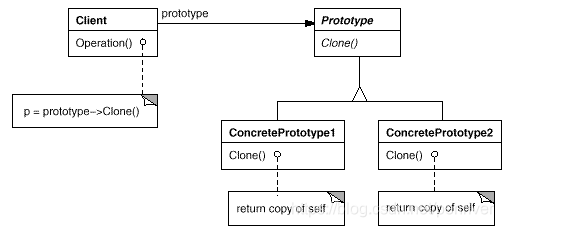 | 克隆,复制 | |
| 结构型 | 适配器模式(Adapter) | 将一个类的接口转换成客户期望的另一个接口,实现接口【不兼容】的类可以协同工作。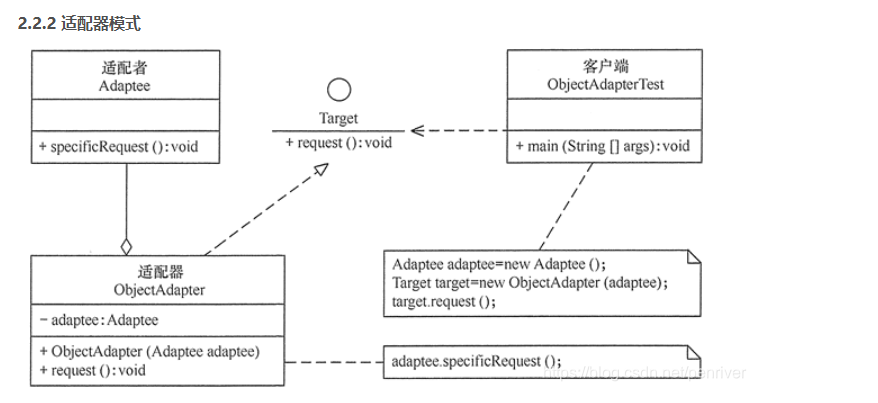 | 转换,兼容 |
| 桥接模式(Bridge) | 将抽象部分与实现部分分离,使它们可以独立变化。Abstraction 持有 Implementor 的引用;RefinedAbstraction 继承 Abstraction;ConcreteImplementorA / ConcreteImplementorB 实现 Implementor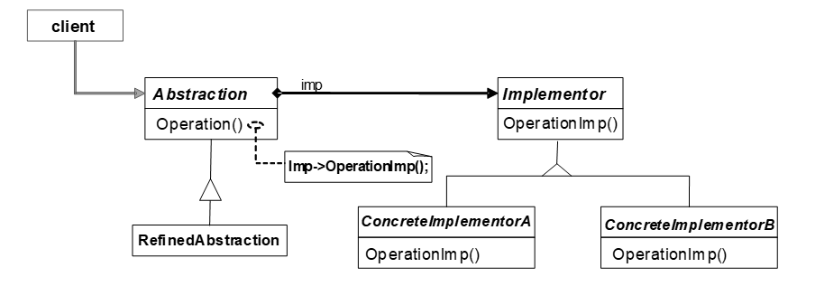 | 分离,解耦 | |
| 装饰器模式(Decorator) | 动态地给对象增加【额外功能】,而不改变其结构。比静态继承具有更大的灵活性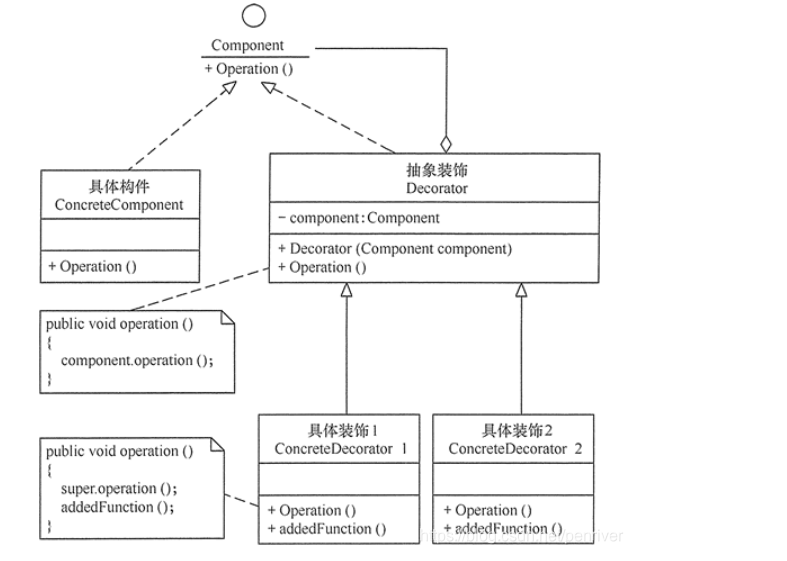 | 包装,增强 | |
| 组合模式(Composite) | 将对象组合成树形结构,使用户对单个对象和组合对象的使用具有一致性。Component(抽象组件) 定义对象的统一接口; Leaf(叶子节点) 表示树形结构中的叶子对象(最小单元),没有子节点,实现抽象组件定义的操作。;Composite(组合节点) 表示树中的非叶子节点,可以包含子节点(Leaf 或 Composite),实现抽象组件接口,并负责对子节点的管理。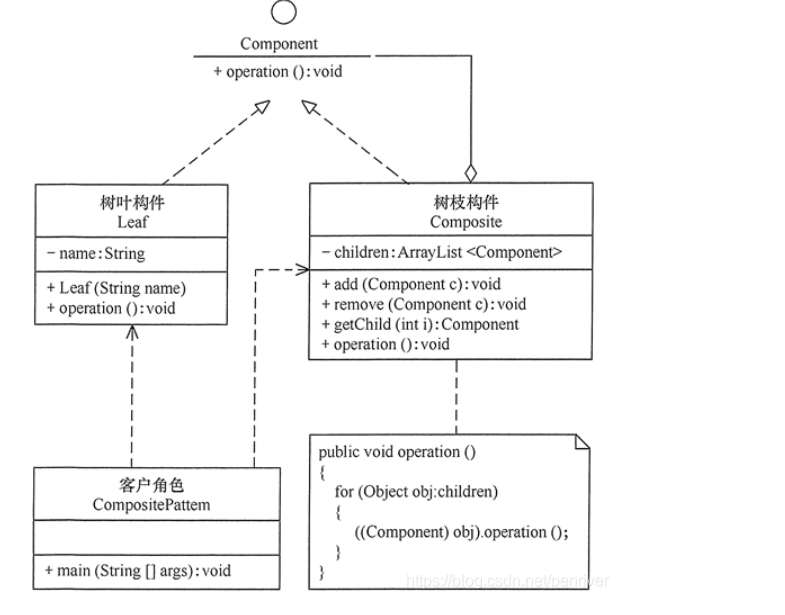 | 树形,整体-部分 | |
| 外观模式(Wrapper Facade) | 为子系统中的一组接口提供一个一致的入口,简化系统使用。Client(客户端) 使用 Component 接口来操作对象(无须区分是叶子还是组合对象)。服务端程序应该在包装器外观的实例上调用需要的方法,然后将请求和请求的参数发送给操作系统API函数,调用成功后将结果返回,使用该模式提高了底层代码访问的一致性,但降低了服务端程序的调用性能。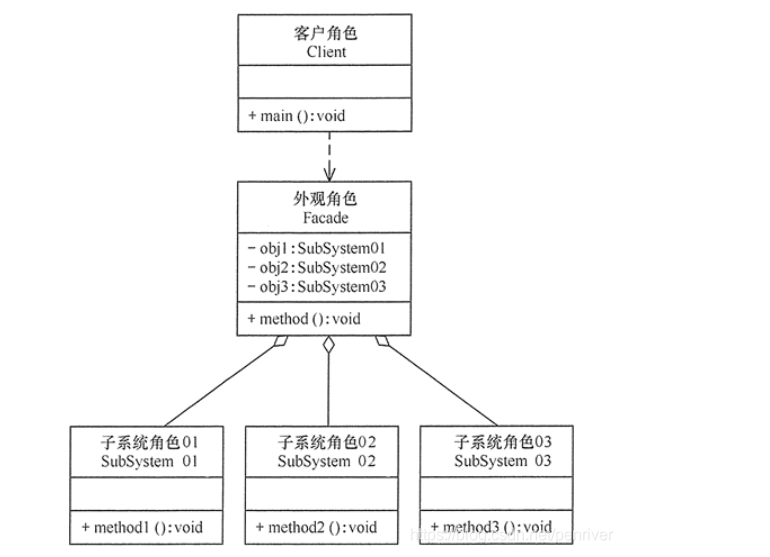 | 门面,简化 | |
| 享元模式(Flyweight) | 通过共享技术有效地支持大量细粒度对象,减少内存消耗。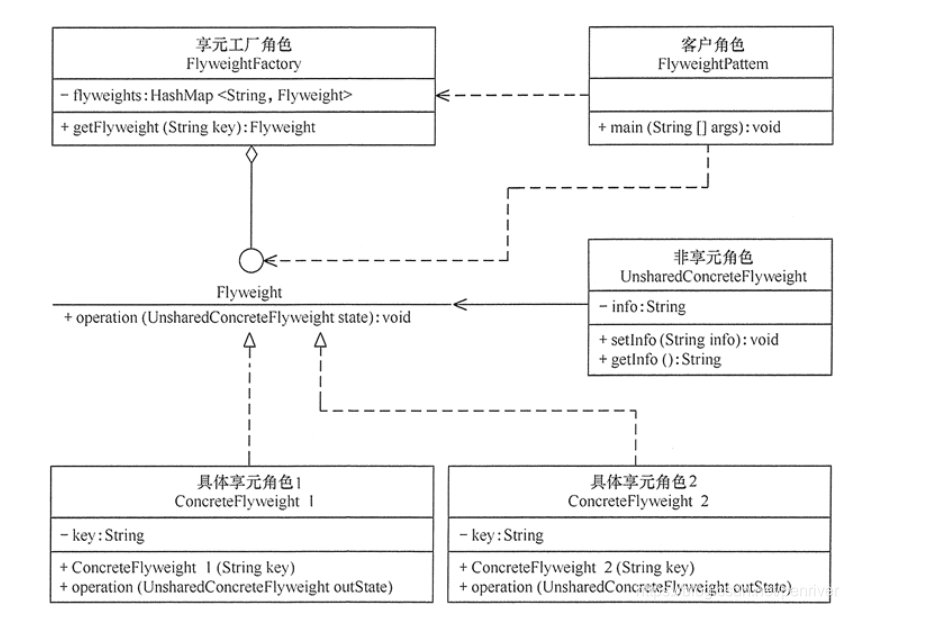 | 共享,节省内存 | |
| 代理模式(Proxy) | 为其他对象提供一种代理以控制对该对象的访问。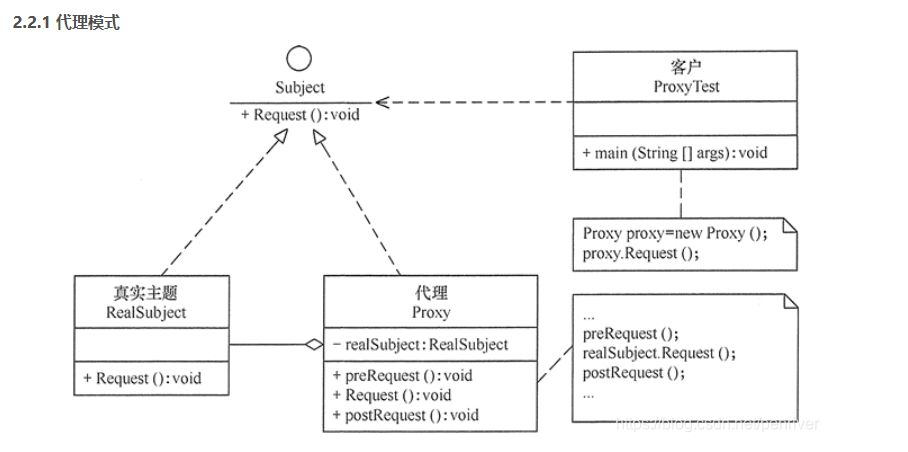 | 代理,中介 | |
| 行为型 | 模板方法模式(Template Method) | 定义算法的骨架,将某些步骤延迟到子类实现。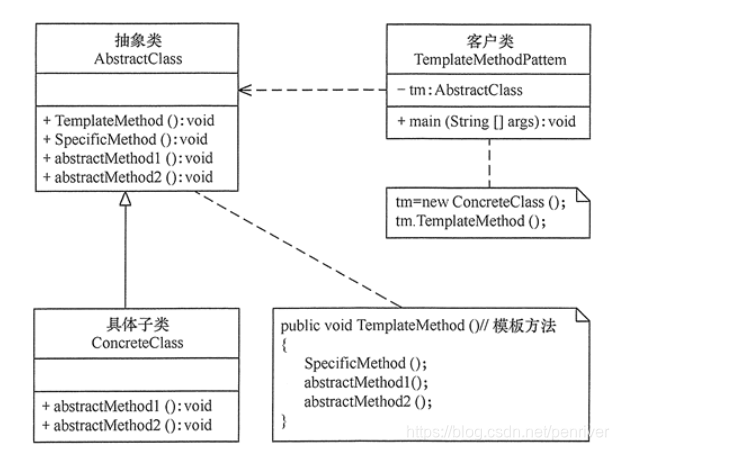 | 框架,步骤固定 |
| 策略模式(Strategy) | 定义一系列算法,将它们封装起来并使它们可以相互替换。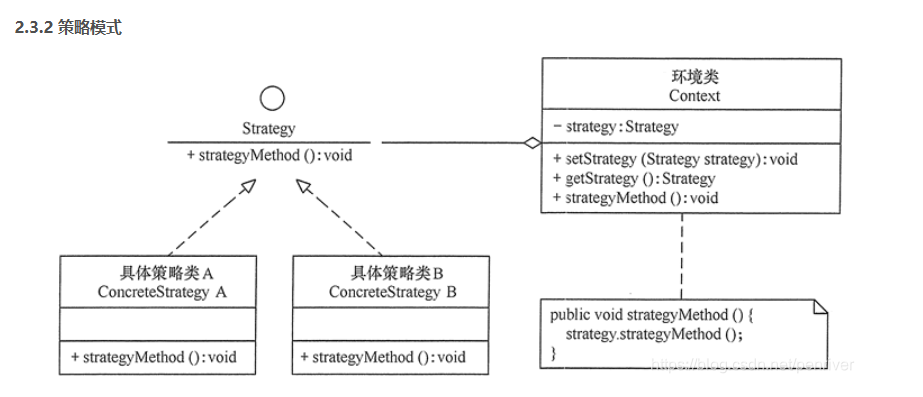 | 算法族,替换 | |
| 命令模式(Command) | 将请求【封装】为对象,从而可用不同请求对客户进行参数化。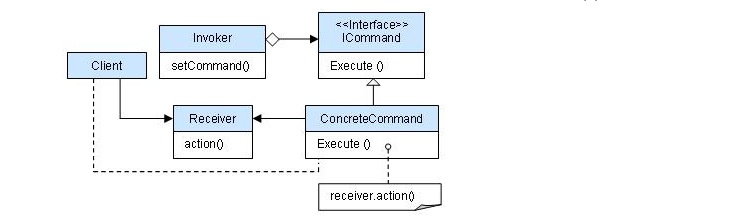 | 请求封装,解耦 | |
| 责任链模式(Chain of Responsibility) | 很多对象由每一个对象对其下家的引用而连接起来形成一条链,将请求沿着处理链传递,直到有对象处理它为止。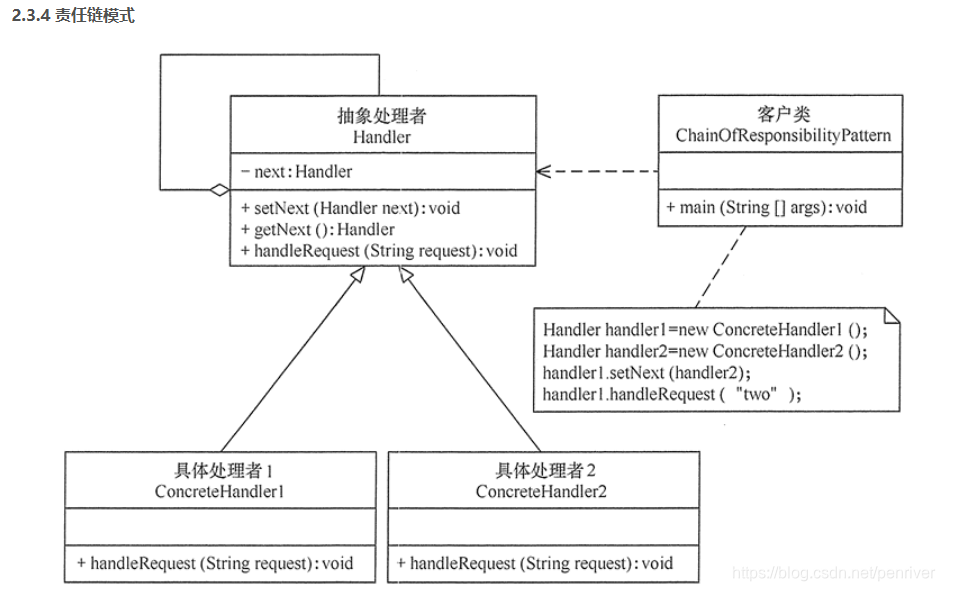 | 传递,链式处理 | |
| 状态模式(State) | 将每一个条件分支放入一个独立的类中,适用复杂逻辑关系 if 类1 else 类2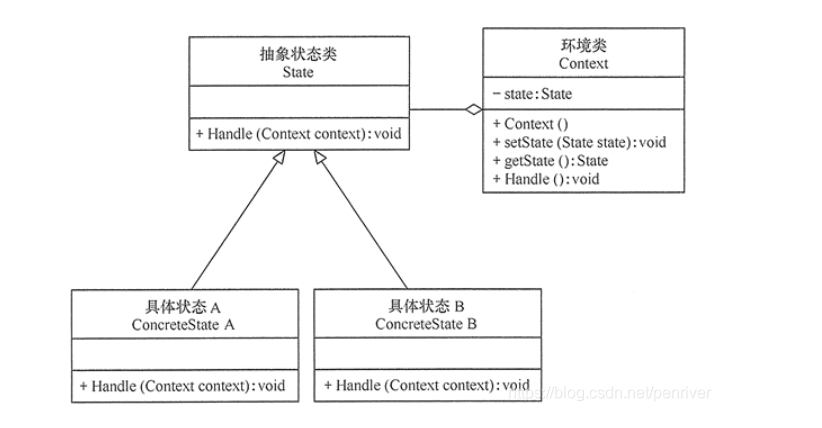 | 状态切换,行为变化 | |
| 观察者模式(Observer) | 定义对象间一对多依赖,当一个对象状态发生改变时,通知所有依赖它的对象。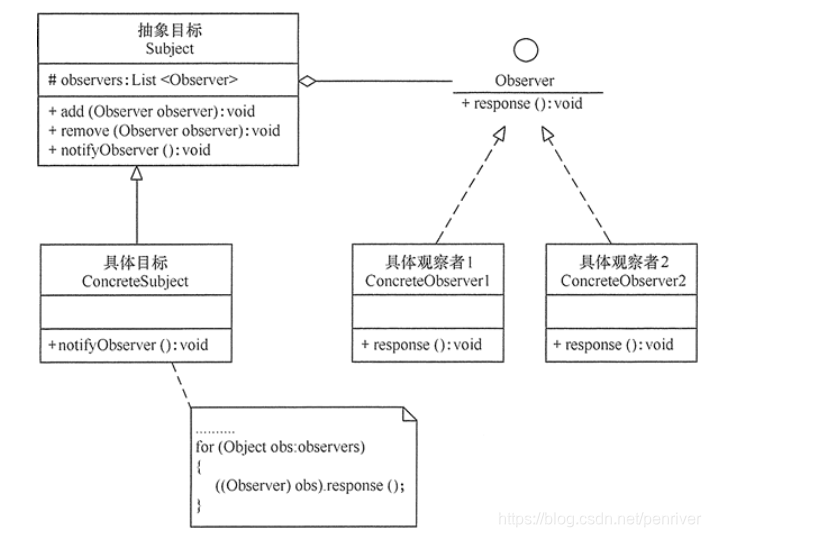 | 发布-订阅,通知 | |
| 中介者模式(Mediator) | 用一个中介对象封装一组对象的交互,减少对象间的依赖关系。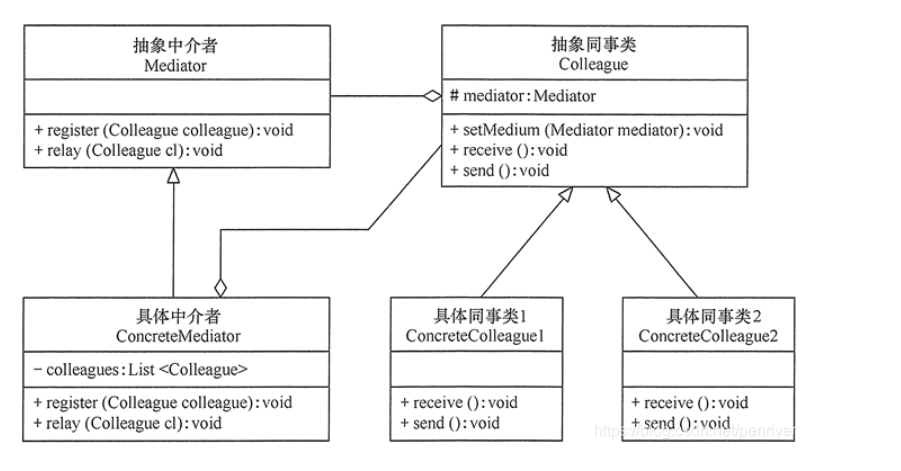 | 中心,调度 | |
| 迭代器模式(Iterator) | 提供一种顺序访问聚合对象元素的方法,而不暴露其内部表示。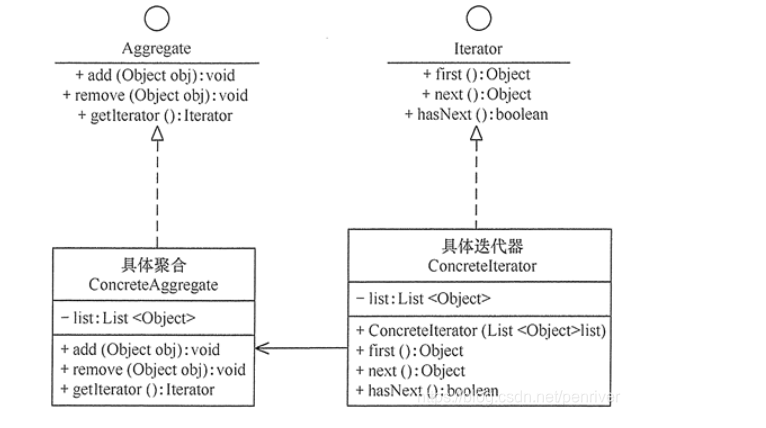 | 遍历,顺序访问 | |
| 访问者模式(Visitor) | 封装作用于某对象结构中的各元素的操作,使你可以在不改变类的前提下定义新操作。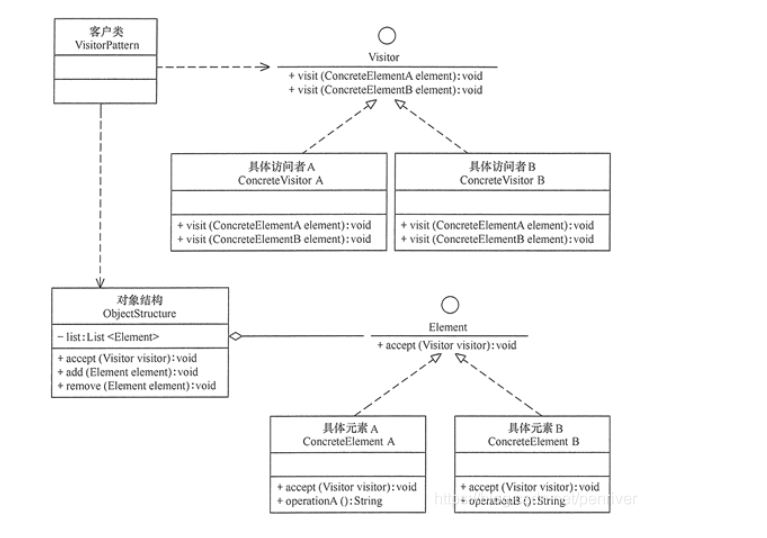 | 新操作,分离访问 | |
| 备忘录模式(Memento) | 在不破坏封装性的前提下,捕获对象的内部状态,以便以后恢复。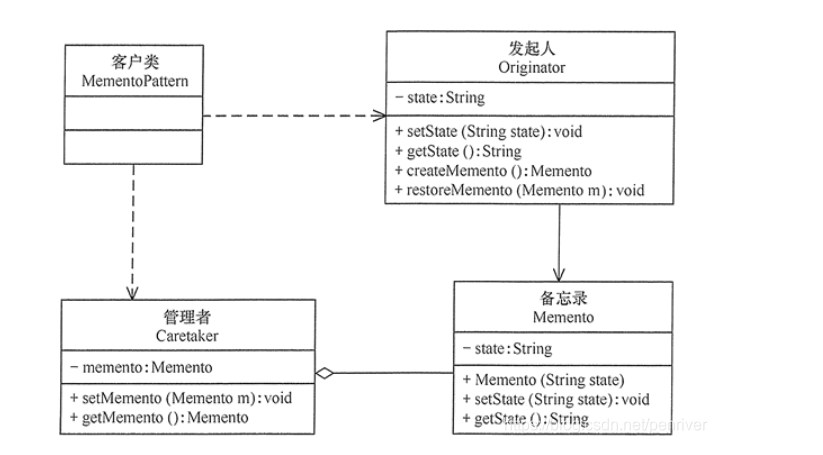 | 备份,恢复 | |
| 解释器模式(Interpreter) | 为某种语言定义文法,并提供解释器来解释该语言中的句子。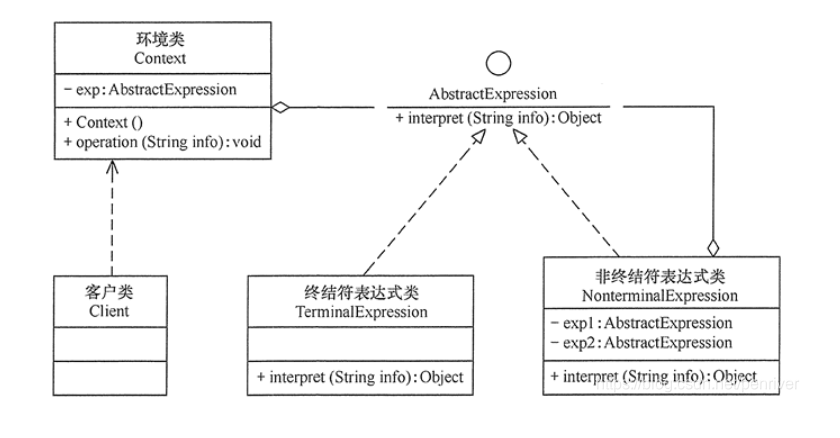 | 语法,解释执行 |
4)设计原则: ①单一职责原则:设计目的单一的类,只完成一个职能,关系简单,使系统达到高内聚低耦合 ②开闭原则:对扩展开放,对修改封闭,防止破坏原有代码的功能 ③李氏(Liskov)替换原则:子类可以替换父类,泛化关系,子类不能重写父类的方法 ④依赖倒置原则:要依赖于抽象,而不是具体实现,针对接口编程,不要针对实现编程,防止过度耦合,灵活性、可扩展性都会更好 ⑤接口隔离原则:使用多个专门的接口比使用单一的总接口要好 ⑥组合重用原则:要尽量使用组合,而不是继承关系达到重用目的,防止继承的紧耦合 ⑦迪米特(Demeter)原则(最少知识原则):一个对象1.应当对其他对象有尽可能少的了解,信息隐蔽原则。信息隐蔽是开发整体程序结构时使用的法则,即将每个程序的成分隐蔽或封装在一个单一的设计模块中,定义每一个模块时尽可能少地显露其内部的处理。在设计时首先列出一些可能发生变化的因素,在划分模块时将一个可能发生变化的因素隐蔽在某个模块的内部,使其他模块与这个因素无关。在这个因素发生变化时,只需修改含有这个因素的模块,而与其他模块无关。信息隐蔽原则对提高软件的可修改性、可测试性和可移植性都有重要的作用。
(4)数据持久化与数据库。永久保存对象的状态,需要进行对象的持久化(Persistence),把内存中的对象保存到数据库或可永久保存的存储设备中。在多层软件设计和开发中采用持久层(Persistence Layer)专注于实现数据持久化,将对象持久化到关系数据库中,需要进行对象/关系的映射(Object/Relation Mapping,ORM)。目前主流的持久化技术框架包括 Hibernate、iBatis/Mybatis和JDO等。
1)Hibernate:是一个开源的全自动的ORM框架,对JDBC进行了非常轻量级的对象封装,提供抽象的HQL可以自动生成不同数据库的SQL语句,优点是具有跨数据库平台的特性。 2)iBatis/Mybatis:提供手动的ORM实现,需要程序员手写SQL,优点是可以结合特定的数据库特性深度优化。 3)Java数据对象(JavaDataObject,JDO):是Java标准中的持久化API,提供了透明的对象存储,并且不仅仅支持关系数据库,还支持普通文件、XML文件和对象数据库等。
- 软件重用
其他设计方法如构件与软件重用。软件重用是使用已有软件产品来开发新的软件系统的过程,分为水平式重用和垂直式重用两种类型,见表7.3。
表7.3 软件重用类型
| 名称 | 对象 | 举例 |
| 水平式重用 | 不同应用领域中的软件元素 | 标准函数库 |
| 垂直式重用 | 共性应用领域间的软部件 | 区块链 |
- 逆向工程(Reverse Engineering)
逆向工程是通过分析已有的程序,寻求比源代码更高级的抽象表现形式(比如文档)的活动,是在不同抽象层级中进行的溯源行为。一般认为,凡是在软件生命周期内将软件某种形式的描述转换成更为抽象形式的活动都可称为逆向工程。与之相关的概念是: 1)重构(restructuring),指在同一抽象级别上转换系统描述形式; 2)设计恢复(designrecovery),指借助工具从已有程序中抽象出有关数据设计、总体结构设计和过程设计的信息(不一定是原设计): 3)再工程(re-engineering),也称修复和改造工程,它是在逆向工程所获信息的基础上修改或重构已有的系统,产生系统的一个新版本。
表7.4 逆向工程信息恢复的级别
| 级别 | 内容 | 抽象级别 | 逆向工程恢复难度 | 工具支持可能性 | 人工参与程度 |
|---|---|---|---|---|---|
| 实现级 | 能够导出过程的设计模型,如语法树、符号表 | ⬆️递增 | ⬆️递增 | ⬇️递减 | ⬆️递增 |
| 结构级 | 程序和数据结构信息,如调用图,包括反映程序各部分之间相关依赖关系的信息 | ↑ | ↑ | ↓ | ↑ |
| 功能级 | 功能和程序段之间的关系,如对象模型、数据和控制流模型 | ↑ | ↑ | ↓ | ↑ |
| 领域级 | 实体与应用域之间的关系,如 UML 状态图和部署图 | ↑ | ↑ | ↓ | ↑ |
- 形式化方法
形式化方法是一种具有坚实数学基础的方法,从而允许对系统和开发过程做严格处理和论证,适用于那些系统安全级别要求极高的软件的开发。形式化方法的主要优越性在于它能够数学地表述和研究应用问题及软件实现。但是它要求开发人员具备良好的数学基础。用形式化语言书写的大型应用问题的软件规格说明往往过于细节化,并且难以为用户和软件设计人员所理解。由于这些缺陷,形式化方法在目前的软件开发实践中并未得到普遍应用。净率软件工程(Cleanroom Software Enaineering,CSE)是软件开发的一种形式化方法,可以开发较高质量的软件。它使用盒结构规约进行分析和建模,并且将正确性验证作为发现和排除错误的主要机制,使用统计测试来获取认证软件可靠性所需要的信息。CSE强调在规约和设计上的严格性,还强调统计质量控制技术,包括基于客户对软件的预期使用测试。
7.4 软件测试(黑盒白盒、确认测试)
【基础知识点】
- 软件测试的目的
测试是确保软件的质量,确认软件以正确的方式做了用户所期望的事情。软件测试通常在规定的时间和成本内完成,以尽量多地发现漏洞,但不能保证发现所有的漏洞。软件测试过程主要有:分析需求文档、测试用例设计、测试执行过程、测试结果分析、形成测试报告。而软件测试周期并行与软件生命周期,存在于软件生命周期的各个阶段。
- 测试分类
1)以测试过程中程序执行状态为依据可分为静态测试和动态测试,静态测试和动态测试是按是否运行程序划分的 2)以具体实现算法细节和系统内部结构的相关情况为根据可分黑盒测试、白盒测试和灰盒测试3类; 3)从程序执行的方式来分类,可分为人工测试和自动化测试。 4)而功能测试、性能测试、验收测试、压力测试等属于按测试目标或质量特性划分的类别。
(1)根据程序执行状态可分为静态测试(Static Testing,ST)和动态测试(Dynamic Testing,DT)。
静态测试工具是对代码进行语法扫描,找到不符合编码规范的地方,根据某种质量模型评价代码的质量,生成系统的调用关系图等。它直接对代码进行分析,不需要运行代码,也不需要对代码编译链接和生成可执行文件,静态测试工具可用于对软件需求、结构设计、详细设计和代码进行评审、走审和审查,也可用于对软件的复杂度分析、数据流分析、控制流分析和接口分析提供支持。 包括桌前检查(桌面检查)、代码走查、代码审查等方式。
静态分析通过解析程序文本从而识别出程序语句的各个部分,审查可能的缺陷和异常之处,静态分析包括五个阶段: 1)控制流分析阶段找出并突出显示那些带有多重出口或入口的循环以及不可达到的代码段;使用控制流图系统地检査程序的控制结构。按照结构化程序规则和程序结构的基本要求进行程序结构检査。控制流图描述了程序元素和它们的执行顺序之间的联系。一个程序元素通常是一个条件、一个简单的语句,或者一块语句(多个连续语句)。 2)数据流分析阶段突出程序中变量的使用情况;用数据流图来分析数据处理的异常现象(数据异常),这些异常包括初始化、赋值、或引用数据等的序列的异常。 3)接口分析阶段检查子程序和过程声明及它们使用的一致性;程序的接口分析涉及子程序以及函数之间的接口一致性,包括检査形参与实参类型、个数、维数、顺序的一致性。当子程序之间的数据或控制传递使用公共变量块或全局变量时,也应检査它们的一致性。 4)表达式分析括号不匹配,数组引用越界,除数为零。 5)信息流分析阶段找出输入变量和输出变量之间的依赖关系; 6)路径分析阶段找出程序中所有可能的路径并画出在此路径中执行的语句。
动态测试工具与静态测试工具不同,它需要运行被测试系统,并设置探针,向代码生成的可执行文件中插入检测代码,可用于软件的覆盖分析和性能分析,也可用于软件的模拟、建模、仿真测试和变异测试等。包括黑盒测试、白盒测试。
(2)根据是否关注具体实现和内部结构可分为黑盒测试、白盒测试和灰盒测试。
①黑盒测试也称为功能测试,主要用于集成测试,确认测试和系统测试阶段。黑盒测试根据软件需求规格说明所规定的功能来设计试用例,一般包括功能分解、等价类划分、边界值分析、判定表、因果图、状态图、随机测试、错误推测和正交试验法等。 1)等价类划分是用得最多的一种黑盒测试方法。所谓等价类就是某个输入域的集合,对每一个输入条件确定若干个有效等价类和若干个无效等价类,分别设计覆盖有效等价类和无效等价类的测试用例。无效等价类是用来测试非正常的输入 数据的,所以要为每个无效等价类设计一个测试用例。 2)边界值分析通过选择等价类边界作为测试用例,不仅重视输入条件边界,而且也必须考虑输出域边界。在实际测试工作中,将等价类划分法和边界值分析结合使用,能更有效地发现软件中的错误。 3)因果图方法是从用自然语言书写的程序规格说明的描述中找出因(输入条件)和果 (输出或程序状态的改变),可以通过因果图转换为判定表。 4)正交试验设计法,就是使用已经造好了的正交表格来安排试验并进行数据分析的一种方法,目的是用最少的测试用例达到最高的测试覆盖率。 5)判定表:最适合描述在多个逻辑条件取值的组合所构成的复杂情况下,分别要执行哪些不同的动作。
②白盒测试也称为结构测试,主要用于软件单元测试阶段,测试人员按照程序内部逻辑结构设计测试用例,检测程序中的主要执行通路是否都能按预定要求正确工作。白盒测试方法主要有控制流测试、数据流测试和程序变异测试等。 控制流测试根据程序的内部逻辑结构设计测试用例,常用的技术是逻辑覆盖。主要的覆盖标准有语句覆盖、判定覆盖、条件覆盖、条件/判定覆盖、条件组合覆盖、修正的条件/判定覆盖和路径覆盖等。 1)语句覆盖是指选择足够多的测试用例,使得运行这些测试用例时,被测程序的每个语句至少执行一次。 2)判定覆盖也称为分支覆盖,它是指不仅每个语句至少执行一次,而且每个判定的每种可能的结果(分支)都至少执行一次。 3)条件覆盖是指不仅每个语句至少执行一次,而且使判定表达式中的每个条件都取得各种可能的结果。 4)条件/判定覆盖同时满足判定覆盖和条件覆盖。它的含义是选取足够的测试用例,使得判定表达式中每个条件的所有可能结果至少出现一次,而且每个判定本身的所有可能结果也至少出现一次。 5)条件组合覆盖是指选取足够的测试用例,使得每个判定表达式中条件结果的所有可能组合至少出现一次。 6)修正的条件/判定覆盖。需要足够的测试用例来确定各个条件能够影响到包含的判定结果。 7)路径覆盖是指选取足够的测试用例,使得程序的每条可能执行到的路栏都至少经过一次(如果程序中有环路,则要求每条环路路径至少经过一次)。测试时既会参考 外部功能需求,也会结合 部分代码实现、架构设计、接口定义 等信息来设计用例。
③灰盒测试是一种结合黑盒与白盒特点的测试方法。测试人员部分了解系统的内部结构或逻辑(不像黑盒完全不知,也不像白盒完全透明)。测试时既会参考外部功能需求,也会结合部分代码实现、架构设计、接口定义 等信息来设计用例。灰盒测试的特点: 1)信息获取:测试人员可能知道数据结构、数据库设计、接口文档、关键算法的大致逻辑。但不需要掌握所有源代码。 2)测试角度:外部:验证功能是否符合需求(类似黑盒)。内部:通过已知部分逻辑,提高用例覆盖率,发现更隐蔽的缺陷(类似白盒)。 3)应用场景:接口测试(知道 API 协议和参数,但不完全清楚内部实现)。集成测试(理解模块间数据流)。安全测试(利用对内部逻辑的部分了解,进行漏洞挖掘)。
三者区别
| 测试方法 | 内部逻辑了解程度 | 关注点 | 常见应用场景 |
|---|---|---|---|
| 黑盒测试 | ❌ 不知道 | 功能、需求、输入输出 | 功能测试、验收测试 |
| 白盒测试 | ✅ 完全知道 | 代码逻辑、路径覆盖 | 单元测试、代码级测试 |
| 灰盒测试 | ⚪ 部分知道 | 功能 + 部分逻辑 | 接口测试、集成测试、安全性 |
(3)根据程序执行的方式来分类可分为人工测试(Manual Testing,MT)和自动化测试(Automatic Testing,AT)。
脚本技术 自动化测试工具主要使用脚本技术来生成测试用例,测试脚本不仅可以在功能测试上模拟用户的操作,比较分析而且可以用在性能测试、负载测试上。虚拟用户可以同时进行相同的、不同的操作,给被测软件施加足够的数据和操作,检查系统的响应速度和数据吞吐能力。 1)线性脚本,是录制手工执行的测试用例得到的脚本,这种脚本包含所有的击键、移动、输入数据等,所有录制的测试用例都可以得到完整的回放。 2)结构化脚本,类似于结构化程序设计,具有各种逻辑结构、函数调用功能。也允许其他脚本调用。 3)共享脚本可以在不同主机、不同共享脚本,共享脚本是指可以被多个测试用例使用的脚本系统之间共享,也可以在同一主机、同一系统之间共享。 4)数据驱动脚本,将测试输入存储在独立的(数据)文件中,而不是存储在脚本中。可以针对不同数据输入实现多个测试用例。 5)关键字驱动脚本,关键字驱动脚本是数据驱动脚本的逻辑扩展。它将数据文件变成测试用例的描述,采用一些关键字指走要执行的任务。
(4)从阶段上划分,软件测试可以分为单元测试、集成测试、系统测试和验收测试。 1)单元测试单元测试也称为模块测试,测试的对象是可独立编译或汇编的程序模块、软件构件或OO软件中的类(统称为模块),其目的是检查每个模块能否正确地实现设计说明中的功能、性能、接口和其他设计约束等条件,发现模块内可能存在的各种差错。单元测试的技术依据是软件详细设计说明书。常采用白盒的静态测试如静态分析、代码审查等,也可以采用自动化的动态测试。 2)集成测试对通过单元测试的模块进行组装测试,以验证组装的正确性,一般采用白盒测试和黑盒测试结合的方法。从组装策略来看,集成测试可以分为一次性组装和增量式组装,增量式组装测试效果更好。集成测试计划一般在概要设计阶段完成。 3)系统测试检查组装完成的系统是否符合SRS的要求。主要测试内容包括功能测试、性能测试、健壮性测试、安全性测试等,结束标志是测试工作已满足测试目标所规定的需求覆盖率,并且测试所发现的缺陷都已全部归零。系统测试的依据是软件需求规格说明书。系统测试采用黑盒测试,以此来检查该系统是否符合软件需求。 ①恢复测试:恢复测试监测系统的容错能力。 ②安全性测试:系统的安全性测试是检测系统的安全机制、保密措施是否完善,主要是为了检验系统的防范能力。 ③强度测试:是对系统在异常情况下的承受能力的测试,是检查系统在极限状态下运行时,性能下降的幅度是否在允许的范围内。 ④性能测试:检査系统是否满足系统设计方案说明书对性能的要求。 ⑤安装测试:在安装软件系统时,会有多种选择。安装测试就是为了检测在安装过程中是否有误、是否容易操作等。 ⑥可靠性测试:通常使用以下两个指标来衡量系统的可靠性:平均失效间隔时间MTBF (mean time between failures)是否超过了规定的时限,因故障而停机时间MTTR (mean time to repairs)在一年中不应超过多少时间。 4)验收测试是确认系统满足用户需求或者协议的要求,确保系统能支撑业务运行。
(5)根据测试目的不同,性能测试主要包括压力测试、负载测试、并发测试和可靠性测试等 ①强度测试:是在系统资源特别低的情况下考查软件系统极限运行情况。 ②负载测试:用于测试超负荷环境中程序是否能够承担,确定在各种工作负载下系统的性能,测试当负载逐渐增加时,系统各项性能指标的变化情况。 ③压力测试:通过确定系统的瓶颈或不能接收的性能点,来获得系统能够提供的最大服务级别的测试。负载测试和压力测试可以结合进行,统称为负载压力测试。 ③容量测试:并发测试也称为容量测试,主要用于测试系统可同时处理的在线最大用户数量。
(6)确认测试主要用于验证软件的功能、性能和其他特性是否与用户需求一致。根据用户的参与程度,通常包括以下4种类型: 1)内部确认测试。内部确认测试主要由软件开发组织内部按照软件需求规格说明书进行测试。 2)α测试和β测试。对于通用产品型的软件开发而言,α测试是指由用户在开发环境下进行测试,通过α测试以后的产品通常称为α版;β测试是指由用户在实际使用环境下进行测试,通过β测试的产品通常称为β版。一般在通过β测试后,才能把产品发布或交付给用户。 3)验收测试。验收测试是指针对软件需求规格说明书,在交付前以用户为主进行的测试。其测试对象为完整的、集成的计算机系统。验收测试的目的是,在真实的用户工作环境下,检验软件系统是否满足开发技术合同或软件需求规格说明书。验收测试的结论是用户确定是否接收该软件的主要依据。 4)系统测试的目的是在真实系统工作环境下,验证完整的软件配置项能否和系统正确连接,并满足系统/子系统设计文档和软件开发合同规定的要求。系统测试的主要内容包括功能测试、健壮性测试、性能测试、用户界面测试、安全性测试、安装与反安装测试等。其中性能测试包括负载测试、压力测试、可靠性测试和并发测试。
(7)回归测试 目的是确认新修改没有引入新的缺陷,并且原有的功能仍能正常工作。例如:修复了某个 bug,除了确认 bug 修复成功,还需要在相关模块和系统范围内执行已有用例,看是否出现连锁反应。关注点:系统整体的稳定性和一致性。
和确认测试对比:
| 测试类型 | 触发条件 | 测试范围 | 关注点 |
|---|---|---|---|
| 确认测试 | 缺陷修复后 | 缺陷对应的测试用例 | 缺陷是否被修复 |
| 回归测试 | 缺陷修复、新功能加入、代码修改后 | 与修改相关或全量用例 | 是否引入新的缺陷、原功能是否正常 |
(8)其他测试还有AB测试、Web测试、链接测试和表单测试等。
| 其它测试 | 描述 |
|---|---|
| AB测试 | 多版本同时使用,利于收集各版本的用户反馈,评估出最优版本。故也算是一种 网页优化方法。 |
| Web测试 | Web系统测试与其他系统测试 测试内容基本相同,只是 测试重点不同。 Web代码测试包括:源代码规则分析、链接测试、框架测试、表单测试、图形测试等方面。 |
| 链接测试 | 链接测试可分为3个方面: 1. 测试所有链接是否按指示的那样 确实链接到了该链接的页面。 2. 测试所链接的 页面是否存在。 3. 保证Web应用系统上没有 孤立的页面。 |
| 表单测试 | 验证服务器是否 正确保存这些数据,后台运行的程序能否正确解释和使用这些信息。测试提交操作的 完整性。 |
| 回归测试 | 测试软件变更之后,变更部分的正确性和对变更需求的符合性。 |
测试模块 1)驱动模块是用来模拟被测试模块的上一级模块,相当于被测模块的主程序。它接收数据,将相关数据传送给被测模块,启用被测模块,并打印出相应的结果。 2)桩模块(Stub)是指模拟被测试的模块所调用的模块,而不是软件产品的组成的部分。主模块作为驱动模块,与之直接相连的模块用桩模块代替。在集成测试前要为被测模块编制一些模拟其下级模块功能的"替身”模块,以代替被测模块的接口,接收或传递被测模块的数据,这些专供测试用的"假"模块称为被测模块的模块。
软件测试与调试区别
| 对比维度 | 软件测试 | 调试 |
|---|---|---|
| 目的 | 发现软件中存在的错误 | 定位并修正错误 |
| 起点条件 | 已知条件(需求、测试用例等) | 不可知的内部条件 |
| 过程特点 | 有计划、有步骤,需要测试设计 | 推理、探索过程,没有预定义步骤 |
| 执行方式 | 使用预先定义的程序,预知结果 | 没有预先定义的过程,结果不可预见 |
| 关注点 | 错误的存在(“发现”问题) | 错误的原因及修复(“解决”问题) |
| 结果 | 发现缺陷,生成测试报告 | 修复缺陷,验证修复有效性 |
| 与生命周期关系 | 并行于整个软件生命周期 | 在发现问题后触发,非全周期活动 |
7.5 净室软件工程
净室软件工程(Cleanroom Software Engineering,CSE)是一种在软件开发过程中强调在软件中建立正确性的需要的方法。CSE的理论基础主要是函数理论和抽样理论。CSE使用盒子结构规约进行分析和设计建模,并且强调将正确性验证(而不是测试) 作为发现和消除错误的主要机制,使用统计测试来获取认证软件可靠性所需要的信息。CSE强调在规约和设计上的严格性,还强调统计质量控制技术,包括基于客户对软件的预期使用测试。可以生成质量非常高的软件。CSE的缺点是太理论化、忽视测试、带有传统软件工程的弊端。
净室软件工程(Cleanroom Software Engineering,CSE)是软件开发的一种形式化方法,可以开发较高质量的软件。它使用盒结构归约进行分析和建模,并且将正确性验证作为发现和排除错误的主要机制,使用统计测试来获取认证软件可靠性所需要的信息。 CSE 强调在规约和设计上的严格性,以及使用基于数学的正确性证明来对设计模型的每个元素进行形式化验证,作为对形式化方法中的扩展,CSE还强调统计质量控制技术,包括基于客户对软件的预期使用的测试。CSE 的理论基础是函数理论和抽样理论,所采用的技术手段主要有以下四个方面: 1)统计过程控制下的增量式开发。 2)基于函数的规范、设计。CSE 按照函数理论定义了三种抽象层次,分别是行为视图、有限状态机视图和过程视图,规范从一个外部行为视图(称为黑盒)开始,然后被转化为一个状态机视图(称为状态盒),最后由一个过程视图(明盒)来实现,盒结构是基于对象的,并支持软件工程的关键原则,即信息隐藏、接口与实现分离。 3)正确性验证。正确性验证是 CSE的核心,正是由于采用了这一技术,软件质量才有了极大的提高。 4)统计测试和软件认证。CSE 在测试方面采用统计学的基本原理,即当总体太大时必须采取抽样的方法。首先,确定一个使用模型来代表系统所有可能使用的(一般是无限的)总体:然后,由使用模型产生测试用例。因为测试用例是总体的一个随机样本,所以可得到系统预期操作性能的有效的统计推导。
CSE 的主要缺点体现在以下三个方面: 1)对开发人员的要求比较高。CSE 要求采用增量式开发、盒结构和统计测试方法,开发人员必须经过强化训练才能掌握。 2)正确性验证的步骤比较困难,且比较耗时。 3)开发小组不进行传统的模块测试,这是不现实的。程序员可能对编程语言和开发环境还不熟悉,而且编译器或操作系统的缺陷也可能导致未预期的错误。
7.6 基于构件的软件工程(CBSE、构件)
- 定义
基于构件的软件工程(Component-Based Software Engineering,CBSE) 是一种基于分布对象技术、强调通过可复用构件设计与构造软件系统的软件复用途径。用于CBSE的构件应该具备以下特征:
(1)可组装型:所有外部交互必须通过公开定义的接口进行。 (2)可部署性:必须能作为一个独立实体在提供其构件模型实现的构件平台上运行。 (3)文档化:构件必须是完全文档化的。 (4)独立性:构件应该是独立的,如确实需要其他构件提供服务,则应显示声明。 (5)标准化:必须符合某种标准化的构件模型。
- 构件模型
构件模型定义了构件实现、文档化以及开发的标准。目前主流的构件模型是 Web Services 模型、Sun 公司的 EJB 模型和微软的.NET 模型。构件模型包含了一些模型要素如接口、使用信息和部署信息。构件模型提供了一组被构件使用的通用服务,包括平台服务和支持服务。容器是构件模型基础设施,是支持服务的一个实现加上一个接口定义,构件必须提供该接口定义以便和容器整合在一起。
基于构件的开发模型利用模块化方法将整个系统模块化,并在一定构件模型的支持下复用构件库中的一个或多个软件构件,通过组合手段高效率、高质量地构造应用软件系统的过程。基于构件的开发模型融合了螺旋模型的许多特征,本质上是演化形的,开发过程是迭代的。基于构件的开发模型由软件的需求分析定义、体系结构设计、构件库建立、应用软件构建以及测试和发布5个阶段组成。
在基于构件的软件开发中: 1)逻辑构件模型用功能包描述系统的抽象设计,用接口描述每个服务集合,以及功能之间如何交互以满足用户需求,它作为系统的设计蓝图以保证系统提供适当的功能。接口是一个已命名的一组操作的集合。构件的客户(通常是其他构件)通过这些访问点 来使用构件提供的服务。通常来说,构件在不同的访问点有多个不同的接口。每一个访问 点会提供不同的服务,以迎合不同的客户需求,强调构件接口规范的合约性非常重要,因为构件和它的客户是在互不知情的情况下分别独立开发的,是合约提供了保证两者成功交互的公共中间层。 2)物理构件模型用技术设施产品、硬件分布和拓扑结构,以及用于绑定的网络和通信协议描述系统的物理设计,这种架构用于了解系统的性能、吞吐率等许多非功能性属性。 3)组件接口模型定义构件间调用方式 4)系统交互模型描述构件运行时的行为协作
面向构件的编程一般会涉及以下构件交互问题: (1)异步 当前的构件互连标准大都使用某种形式的事件传播机制作为实现构件实例装配的手段。其思想是相对简单的:构件实例在被期望监听的状态发生变化时发布出特定的事件对象;事件分发机制负责接收这些事件对象,并把它们发送给对其感兴趣的其他构件实例;构件实例则需要对它们感兴趣的事件进行注册,因为它们可能需根据事件对象所标志的变化改变其自身的状态。 (2)多线程 多线程是指在同一个状态空间内支持并发地进行多个顺序活动的概念。相对于顺序编程,多线程的引入为编程带来了相当大的复杂性。特别是,需要避免对多个线程共享的变量进行并发的读写操作可能造成的冲实。这种冲实也被称作数据竞争,因为两个或多个线程去竞争对共享变量的操作。线程的同步使用某种形式的加锁机制来解决此类问题,但这又带来了一个新的问题:过于保守的加锁或者错误的加锁顺序都可能导致死锁。 (3)多语言支持 面向构件编程会涉及多语言问题,在进行不同语言环境涉及互通,最佳状态是编程语言直接支持转发类的构造,则很多问题都能解决,编程的开销也将是最小的,但目前还没有主流的编程语言支持。 (4)调用者封装 语言支持带来的另外一个好处是接口定义。当构件对外提供一个接口时,可能会涉及两种不同的意图。一方面,构件外部的代码可能会调用这个接口中的操作。另一方面,构件内部的代码可能需要调用实现这个接口的一些操作。
- CBSE过程
支持基于构件组装的软件开发过程主要包括:
(1)系统需求概览。(2)识别候选构件。(3)根据发现的构件修改需求。(4)体系结构设计。(5)构件定制与适配。(6)组装构件,创建系统。
CBSE过程与传统的软件开发过程的不同点:
(1)早期需要完整的需求,以便尽可能多地识别出可复用的构件。 (2)早期阶段根据可利用的构件来细化和修改需求以匹配CBSE。 (3)架构设计完成后,可能需要修改构件以适合功能和架构的需求。 (4)开发过程就是组装构件的过程,有时需要开发适配器。 (5)CBSE中的架构设计阶段特别重要,决定和限制了可选构件的范围。
- 构件组装
常见的构件组装有顺序组装、层次组装和叠加组装3 种组装方式。构件组装可能面临接口不兼容的问题,常见的有参数不兼容、操作不兼容和操作不完备3 种。这时需要编写适配器构件来解决不兼容的问题。
7.7 软件项目管理(SQA、WBS、配置管理)
【基础知识点】
(1)软件进度管理一般包括活动定义、活动排序、活动资源估计、活动历时估计、制定进度计划和进度控制6 个过程。 (2)工作分解结构(Work Breakdown Structure,WBS) 是把一个项目,按一定的原则分解成任务,任务再分解成一项项工作,再把一项项工作分配到每个人的活动中,直到分解不下去为止。以可交付成果为导向,对项目要素进行的分组,总是处于计划过程的中心。 WBS分解只到工作包,并不会分解到活动。进行WBS分解时,对任务分解的基本要求为: 1)WBS 的工作包是可控和可管理的,不能过于复杂。 2)任务分解也不能过细,一般原则 WBS 的树形结构不超过6层。 3)每个工作包要有一个交付成果。 4)每个任务必须有明确定义的完成标准。 5)WBS 必须有利于责任分配。 (3)活动定义是指确定完成项目的各个可交付成果所必须进行的各项具体活动,还需要明确每个活动的前驱、持续时间、必须完成日期、里程碑或可交付成果。
| 工具 | 描述 | 作用/特点 |
|---|---|---|
| 分解 | 将项目工作包分解成更小、更易管理的组成部分,即活动 | 定义活动而非可交付成果;WBS、WBS词典和活动清单是依据;让团队成员参与可提高准确性 |
| 滚动式规划 | 对近期工作进行详细规划,对远期工作只进行高层次粗略规划 | 工作分解详细程度随项目生命周期推进而渐进;早期仅规划里程碑,后期分解成具体活动 |
| 模板 | 使用标准活动清单或以往项目的部分活动清单作为参考 | 可帮助识别典型活动和进度里程碑,提供活动属性信息辅助定义活动 |
| 专家判断 | 依靠有经验的团队成员或外部专家提供专业意见 | 提供制定详细项目范围、WBS和进度计划的专业知识,提升活动定义质量 |
(4)任务活动图是项目进度管理、项目成本管理等一系列项目管理活动的基础,通常采用甘特图等方式来展示和管理项目活动。
(5)软件配置管理(Software Configuration Management,SCM) 是一种标识、组织和控制修改的技术。SCM 的目的是使错误降为最小并最有效地提高生产效率。SCM 的核心内容包括版本控制和变更控制。 版本控制(Version Control)是指对软件开发过程中各种文件变更的管理,最主要的功能就是追踪和记录文件的变更、并行开发。 变更控制(Change Control) 是指对变更进行管理,确保变更有序进行。
配置管理工具的常见功能包括版本控制、变更管理、配置状态管理,访问控制和安全控制等。配置管理工具是包含了版本控制工具的。版本控制工具用来存储、更新、恢复和管理一个软件的多个版本。答案选择D选项。
软件系统工具的种类繁多,很难有统一的分类方法。通常可以按软件过程活动将软件工具分为软件开发工具、软件维护工具、软件管理和软件支持工具。 1)软件开发工具:需求分析工具、设计工具、编码与排错工具。 2)软件维护工具:版本控制工具、文档分析工具、开发信息库工具、逆向工程工具、再工程工具。 3)软件管理和软件支持工具:项目管理工具、配置管理工具、软件评价工具、软件开发工具的评价和选择。
产品配置是指一个产品在其生命周期各个阶段所产生的各种形式(机器可读或人工可读)和各种版本的文档、计算机程序、部件及数据的集合。该集合中的每一个元素称为该产品配置的一个配置项。配置项的状态有3种:“草稿”(Draft)、“正式发布”(Released)和“正在修改”(Changing) 产品配置项是构成产品配置的主要元素,配置项主要有以下两大类: 1)属于产品组成部分的工作成果:如需求文档、设计文档、源代码和测试用例等; 2)属于项目管理和机构支撑过程域产生的文档:如工作计划、项目质量报告和项目跟踪报告等。 这些文档虽然不是产品的组成部分,但是值得保存。所以选项C的工作计划虽可充当配置项,但不属于产品组成部分工作成果的配置项。
(6)软件质量管理。软件质量就是软件与明确地和隐含地定义的需求相一致的程度。 软件质量保证(Software Quality Assurance,SQA) 的目的是使软件过程对于管理人员来说是可见的。软件质量保证是软件质量管理的重要组成部分。软件质量保证主要是从软件产品的过程规范性角度来保证软件的品质。其主要活动包括:质量审计(包括软件评审)和过程分析。SQA 的主要任务是:1)SQA 审计与评审,包括对软件工作产品、软件工具和设备的审计,评审开发组的行为符合预定的过程。2)SQA 报告。3)处理不符合问题。 软件质量认证,国内软件企业主要采用的是 ISO 9001 和 CMM。
各个过程定义的负责人根据CMMI体系文件编写规范,完成相关文件的编写。相关文件自顶向下排列为: 1)方针文件:过程文件及其他相关文件都应遵循方针文件 2)过程文件:根据过程文件模板编制各PA过程文件,并对流程进行描述。 3)指南/规范文件:结合相应模板清晰说明如何完成这项工作,并说明对应的标准和需求。 4)模板文件:模板分为两类,一类是word文档模板,一类是excel表格模板。 Word文档:尽量利用公司现有的模板来制作,对需要填写替换的部分,给出具体解释或举例说明; Excel表格:主要用于需要自动计算数据的模板,对需要填写替换的部分,给出具体解释或举例说明。所以答案选择D选项。
(7)软件风险管理。软件项目风险是指在软件开发过程中遇到的预算和进度等方面的问题以及这些问题对软件项目的影响。风险管理的主要目标是预防风险,及应对发生的风险。风险管理活动可以分为: 1)Bochm把风险管理活动分成风险估计(风险辨识、风险分析、风险排序)和风险控制(风险管理计划、风险处理、风险监督)两大阶段。 2)Charette把风险分成分析(辨识、估计、评价)和管理(计划、控制、监督)两大阶段。
(8)时间管理 时间管理的过程包括:1、活动定义2、活动排序3、活动的资源估算4、活动历时估算5、制定计划6、进度控制
3点估算法:(乐观时间天数+最可能时间天数*4+保守天数)/6
(9)范围管理 在初步项目范围说明书中已文档化的主要的可交付物、假设和约束条件的基础上准备详细的项目范围说明书,是项目成功的关键。范围定义的输入包括以下内容: ① 项目章程。如果项目章程或初始的范围说明书没有在项目执行组织中使用,同样的信息需要进一步收集和开发,以产生详细的项目范围说明书。 ② 项目范围管理计划。 ③ 组织过程资产。 ④ 批准的变更申请。、
| 对比维度 | 产品范围 | 项目范围 |
|---|---|---|
| 定义 | 描述产品或服务的特性和功能 | 定义为了交付产品或服务所需完成的所有工作 |
| 关注点 | 产品本身的功能、特性和质量要求 | 实现产品或服务所需的工作、过程和交付成果,通过创建工作分解结构WBS来实现 |
| 文档形式 | 产品范围说明书(Product Scope Statement) | 项目范围声明或项目范围说明书(Project Scope Statement) |
| 作用 | 明确产品“是什么” | 明确项目“做什么”,为制定详细项目计划提供基础 |
| 组成 | 仅涉及产品特性和功能 | 包含产品范围及为实现产品所需的全部工作,包括目标、边界、可交付成果、里程碑等 |
| 管理目标 | 控制产品质量和功能范围 | 控制项目工作范围,防止范围蔓延(Scope Creep),指导时间表、预算、资源分配和风险管理 |
范围定义的输入包括: 1)范围管理计划:范围管理计划是项目管理计划的组成部分,确定了制定、监督和控制项目范围的各种活动。 2)项目章程:项目竟程中包含对项目和产品特征的概括性描述,以及项目审批要求,如果执行组织不使用项目音程则应取得或编制类似的信息,并用作制定详细范围说明书的基础。 3)需求文件使用需求文件来选择哪些需求将包含在项目中。 4)批准的变更申请。 5)组织过程资产 可能影响定义范围过程的组织过程资产包括(但不限于): ①用于制定项目范围说明书的政策、程序和模板; ②以往项目的项目档案: ③以往阶段或项目的经验教训。
(10) 成本管理 在项目的成本管理中,成本预算是将总的成本估算分配到各项活动和工作包上的过程,以此来建立一个成本的基线。成本预算是成本管理的一个关键步骤,它涉及将项目的总体成本估算细分为各个工作包或活动的成本估算,为项目的成本控制提供了基准。
| 管理过程 | 解释 |
|---|---|
| 成本估算 | 对完成项目活动所需资金进行近似估算 |
| 成本预算 | 汇总所有单个活动或工作包的估算成本,建立一个经批准的成本基准 |
| 成本控制 | 监督项目状态以更新项目预算、管理成本基准变更 |
(11)项目管理工具 项目管理工具用来辅助软件的项目管理活动。通常项目管理活动包括项目的计划、调度、通信、成本估算、资源分配及质量控制等。一个项目管理工具通常把重点放在某一个或某几个特定的管理环节上,而不提供对管理活动包罗万象的支持。 项目管理工具具有以下特征: (1)覆盖整个软件生存周期: (2)为项目调度提供多种有效手段; (3)利用估算模型对软件费用和工作量进行估算; (4)支持多个项目和子项目的管理; (5)确定关键路径,松弛时间,超前时间和滞后时间 (6)对项目组成员和项目任务之间的通信给予辅助; (7)自动进行资源平衡; (8)跟踪资源的使用; (9)生成固定格式的报表和剪裁项目报告。 成本估算工具就是一种典型的项目管理工具。
(12)数据安全治理
目标主要有三个:满足合规要求、管理数据安全风险、促进数据开发利用。这些目标旨在确保数据安全与业务发展的双向促进,同时保障组织在数据安全方面的合规性。
7.8 文档管理
软件系统的文档可以分为用户文档和系统文档两类。用户文档主要描述系统功能和使用方法,并不关心这些功能是怎样实现的;系统文档描述系统设计、实现和测试等各方面的内容。
软件需求开发的最终文档经过评审批准后,则定义了开发工作的需求基线(baseline)。这个基线在客户和开发者之间构筑了计划产品功能需求和非功能需求的一个约定(agreement)。需求约定是需求开发和需求管理之间的桥梁。
7.9 遗留系统
在坐标的四个象限内。对处在不同象限的遗留系统采取不同的演化策略: 1)改造策略。第一象限为高水平、高价值区,即遗留系统的技术含量较高且具有较高的商业价值,本身还有极大的生命力。改造策略在遗留系统的基础上,新增功能或做改进使用。 2)集成策略。第二象限 为高水平、低价值区,即遗留系统的技术含量较高,但其业务价值较低。形成了一个个信息孤岛,对这种遗留系统的演化策略为集成。 3)淘汰策略。第三象限为低水平、低价值区,即遗留系统的技术含量较低,且具有较低的业务价值。对这种遗留系统的演化策略为淘汰,即全面重新开发新的系统以代替遗留系统。 4)继承策略。第四象限 为低水平、高价值区,即遗留系统的技术含量较低,但具有较高的商业价值,对这种遗留系统的演化策略为继承。
移植工作大体上分为计划阶段、准备阶段、转换阶段、测试阶段、验证阶段。 1、计划阶段,在计划阶段,要进行现有系统的调査整理,从移植技术、系统内容(是否进行系统提炼等)、系统运行三个方面,探讨如何转换成新系统,决定移植方法,确立移植工作体制及移植日程。 2、准备阶段,在准备阶段要进行移植方面的研究,准备转换所需的资料。该阶段的作业质量将对以后的生产效率产生很大的影响。 3、转换阶段,这一阶段是将程序设计和数据转换成新机器能根据需要工作的阶段。提高转换工作的精度,减轻下一阶段的测试免担是提高移植工作效率的基本内容。 4、测试阶段,这一阶段是进行程序单元、工作单元测试的阶段。在本阶段要核实程序能否在新系统中准确地工作。所以,当有不能准确工作的程序时,就要回到转换阶段重新工作。 5、验证阶段,这是测试完的程序使新系统工作,最后核实系统,准备正式运行的阶段。
7.10 业务流程设计
业务流程建模方法主要有: 1)流程图(fow chan),是最早用于业务流程的一种图形化描述方法,易学习、好理解,但存在无法清楚界定流程界限、不支持层次化描述业务流程等问题; 2)角色活动图(RoleActivity Diagram,RAD)和角色交互图(Role Interaction Diagram,RID),擅长描述角色与活动、角色与角色的交互关系,但不支持层次化描述业务流程; 3)IDEFO和IDEF3,IDEF0描述业务流程做什么,但没指明谁做;IDEF3回答了怎么做,但描述复杂业务流程难度大; 4)高级Petri网有很强的数学基础,可以计算/仿真分析业务流程性能,但用户的学习难度大; 5)统一建模语言(Uniform Modeling Language,UML)活动图易学习和使用,但模型的仿真和分析能力差; 6)BPMN是一种以业务流程图的形式表示业务流程的图形方法,可以用其定义的一系列业务组件,组成业务流程图。
McCache
使用McCabe方法可以计算程序流程图的环形复杂度
方法一:环形复杂度V(G)=E-N+2,其中,E是流图中边的条数,N是结点数。 判定结点:1、3、6. 本题中,E=14,N=12,所以V(G)=14-12+2=4。
方法二:环形复杂度V(G)=P+1,其中,P是流图中判定结点的数目。判定结点:1、3、6.本题中,P=3,所以V(G)=3+1=4。
7.11 其他
软件开发环境(software development environment)是支持软件产品开发的软件系统。它由软件工具集和环境集成机制构成,前者用来支持软件开发的相关过程、活动和任务年;后者为工具集成和软件开发、维护和管理提供统-的支持,它通常包括数据集成、控制集成和界面集成。 1)数据集成机制提供了存储或访问环境信息库的统一的数据接口规范: 2)界面集成机制采用统一的界面形式,提供统一的操作方式; 3)控制集成机制支持各开发活动之间的通信、切换、调度和协同工作。
较完善的软件开发环境通常具有多种功能,例如,软件开发的一致性与完整性维护,配置管理及版本控制,数据的多种表示形式及其在不同形式之间的自动转换,信息的自动检索与更新,项目控制和管理,以及对开发方法学的支持。软件开发环境具有集成性、开放性、可裁减性、数据格式一致性、风格统一的用户界面等特性,因而能大幅度提高软件生产率。 集成机制根据功能的不同,可划分为环境信息库、过程控制与消息服务器、环境用户界面三个部分。 (1)环境信息库。环境信息库是软件开发环境的核心,用以存储与系统开发有关的信息,并支持信息的交流与共字。环境信息库中主要存储两类信息,一类是开发过程中产生的有关被开发系统的信息,例如,分析文档、设计文档和测试报告等;另一类是环境提供的支持信息,例如,文档模板、系统配、过程模型和可复用构件等。 (2)过程控制与消息服务器。过程控制与消息服务器是实现过程集成和控制集成的基础。过程集成是按照具体软件开发过程的要求进行工具的选择与组合,控制集成使各工具之间进行并行通信和协同工作。 (3)环境用户界面。环境用户界面包括环境总界面和由它实行统一控制的各环境部件及工具的界面。统一的、具有一致性的用户界面是软件开发环境的重要特征,是充分发挥环境的优越性、高效地使用工具并减轻用户的学习负担的保证。
软件系统工具的种类繁多,很难有统一的分类方法。通常可以按照软件过程活动将软件工具分为软件开发工具、软件维护工具、软件管理工具和软件支持工具。
| 一级分类 | 二级分类(子类) | 主要功能 / 内容 | 常见工具 / 举例 |
|---|---|---|---|
| 软件开发工具 | 需求分析工具 | 辅助定义和验证用户需求,形成功能规范。 包括基于自然语言/图形、形式化定义语言、原型等工具。 | RationalRose、Together、QuickUML、结构化分析DFD工具 |
| 设计工具 | 从功能规范出发生成系统设计文档,辅助体系结构、模块和接口设计。 | EclipseUML、WinA&D、RationalRose | |
| 编码与排错工具 | 辅助程序员进行编码、编译、调试、排错等活动。 | 编辑器、编译器、调试器、集成开发环境(IDE) | |
| 测试工具 | 辅助软件测试,包括单元测试、集成测试、系统测试等。 | JUnit、LoadRunner、Selenium、Postman | |
| 软件维护工具 | — | 辅助维护软件代码与文档、版本管理、逆向与再工程等。 | Git、SVN、文档分析工具、逆向工程工具 |
| 软件管理工具 | — | 辅助项目计划、进度、资源与质量管理。 | Jira、MS Project、配置管理工具、软件评价工具 |
| 软件支持工具 | — | 支持软件开发环境的构建、评估与协作。 | 开发工具评估系统、协作平台、环境集成工具 |
1)软件开发工具:需求分析工具、设计工具、编码与排错工具。 2)软件维护工具:版本控制工具、文档分析工具、开发信息库工具、逆向工程工具、再工程工具。 3)软件管理工具和软件支持工具:项目管理工具、配置管理工具、软件评价工具、软件开发工具的评价和选择
对应软件开发过程的各种活动,软件开发工具有需求分析工具、设计工具、编码与排错工具、测试工具等。软件建模工具是辅助建立软件系统的抽象模型的。常见的软件建模工具包括RationalRose、Together、WinA&D、QuickUML、EclipseUML等。 (1)需求分析工具用以辅助软件需求分析活动,辅助系统分析员从需求定义出发,生成完成的、清晰的、一致的功能规范。按描述需求定义的方法可以将需求分析工具分为基于自然语言或图像描述的工具和基于形式化需求定义语言的工具。 ①基于自然语言或图形描述的工具:这类工具采用分解与抽象等基本手段,对用户问题逐步求精,并在检测机制的辅助下,发现其中可能存在的问题(如一致性),通过对问题描述的修改,逐步形成能正确反映用户需求的功能规范。比如结构化分析方法采用的数据流图。 ②基于形式化需求定义语言的工具:基于形式化需求定义语言的工具大多以基于知识的需求智能助手的形式出现,并把人工智能技术运用于软件工程。这类工具通常具有一个知识库和一个推理机制。 ③其他需求分析工具:可执行规范语言以及原型技术为需求分析工具提供了另一条实现途径,这些工具通过运行可执行规范或原型,将有关的结果显示给用户和系统分析员,以便进行需求确认。 (2)设计工具:设计工具用以辅助软件设计活动,辅助设计人员从软件功能规范出发,得到相应的设计规范。 (3)编码与排错工县:编码工县和排错工县用以辅助程序员进行编码活动。编码工具辅助程序员用某种程序语言编制源程序,并对源程序进行翻译,最终转换成可执行的代码,主要有编辑程序、汇编程序、编译程序和牛成程序等。排错工具用来辅助程序员寻找源程序中错误的性质和原因,并确定其出错的位置,主要有源代码排错程序和排错程序生成程序两类。 (4)软件维护工具:软件维护工具辅助软件维护过程中的活动,辅助维护人员对软件代码及其文档进行各种维护活动。软件维护工具主要有版本控制工具、文档分析工具、开发信息库工具、逆向工程工具和再工程工具等。 (5)软件管理和软件支持工具:软件管理过程和软件支持过程往往要涉及软件生存周期中的多个活动,软件管理和软件支持工具用来辅助管理人员和软件支持人员的管理活动和支持活动,以确保软件高质高效地完成。其中常用的工具有项目管理工具、配置管理工具、软件评价工具等。
维护类型 1)改正性维护【修BUG】:识别纠正软件错误/缺陷,测试不可能发现所有错误。 2)适应性维护【应变】:指使应用软件适应环境变化【外部环境、数据环境】而进行的修改。 3)完善性维护【新需求】:为扩充功能和改善性能而进行的修改 4)预防性维护【针对未来】:为了适应未来的软硬件环境的变化,应主动增加预防性的新的功能,以使用系统适应各类变化而不被淘汰。经典实例:【专用】改【通用】。
工作流参考模型: (1)工作流执行服务。工作流执行服务是WFMS的核心模块,它的功能包括创建和管理流程定义,创建、管理和执行流程实例。在执行上述功能的同时,应用程序可能会通过编程接口与工作流执行服务交互,一个工作流执行服务可能包含有多个分布式工作的工作流引擎。该模块还为每个用户维护一个活动列表,告诉用户当前必须处理的任务,可以通过电子邮件或者短消息的形式提醒用户任务的到达,例如,在开通课程流程中,当新的课程申请的到来时,可以提示上级主管。 (2)工作流引擎。工作流引擎是为流程实例提供运行环境,并解释执行流程实例的软件模块,即负责流程处理的软件模块。 (3)流程定义工具。流程定义工具是管理流程定义的工具,它可以通过图形方式把复杂的流程定义显示出来并加以操作,流程定义工具与工作流执行服务交互,一般该模块为设计人员提供图形化的用户界面。通过流程定义工具,设计人员可以创建新的流程或者改变现有流程,在流程定义时,可以指定各项活动的参与者的类型、活动之间的相互关系和传递规则等。 (4)客户端应用。客户端应用是通过请求的方式与工作流执行服务交互的应用,也就是说,是客户端应用调用工作流执行服务。客户端应用与工作流执行服务交互,它是面向最终用户的界面,可以将客户端应用设计为B/S架构或C/S架构。 (5)调用应用。调用应用是被工作流执行服务调用的应用,调用应用与工作流执行服务交互。为了协作完成一个流程实例的执行,不同的工作流执行服务之间进行交互,它通常是工作流所携带数据的处理程序,常用的是电子文档的处理程序,它们在工作流执行过程中被调用,并向最终用户展示数据,这些应用程序的信息包括名称、调用方式和参数等。例如,在OA系统中,可以调用相关的程序来直接查看Word文档或者Excel表格数据等。 (6)管理监控工具。管理监控工具主要指组织机构和参与者等数据的维护管理和流程执行情况的监控,管理监控工具与工作流执行服务交互。WEMS通过管理监控工具提供对流程实例的状态查询、挂起、恢复和销毁等操作,同时提供系统参数和系统运行情况统计等数据。用户可以通过图形或者图表的方式对系统数据进行汇总与统计,并可随时撤销一些不合理的流程实例。
7.12 练习题
- 螺旋模型在( )的基础上扩展而成。
A.瀑布模型 B.原型模型 C.快速模型 D.面向对象模型
解析:螺旋模型是在原型模型的基础上扩展而成的。
答案:B
- (1)适用于程序开发人员在地域上分布很广的开发团队。(2)中,编程开发人员分成首席程序员和类程序员。
(1)A.水晶系列(Crystal)开发方法 B.开放式源码(Open Source)开发方法C.Scrum开发方法 D.功用驱动开发方法(FDD)
(2)A.自适应软件开发(ASD) B.极限编程(XP)开发方法 C.开放系统一过程开发方法(OpenUP) D.功用驱动开发方法(FDD)
解析:
(1)在所有的敏捷型方法中,极限编程(Extreme Programming,XP)是最引人瞩目的。它源于 Smalltalk 圈子,特别是 Kent Beck 和 Ward Cunningham 在 20 世纪 80 年代末的密切合作。XP 在一些对费用控制严格的公司中的使用,已经被证明是非常有效的。
(2)Cockburn 的水晶系列方法。水晶系列方法是由 Alistair Cockburn 提出的,它与 XP 方法一样,都有以人为中心的理念,但在实践上有所不同。Alistair 考虑到人们一般很难严格遵循一个纪律约束很强的过程,因此,与 XP 的高度纪律性不同,Alistair 探索了用最少纪律约束而仍能成功的方法,从而在产出效率与易于运作上达到一种平衡。也就是说,虽然水晶系列不如 XP 产出效率高,但会有更多的人能够接受并遵循它。
(3)开放式源码指的是开放源码界所用的一种运作方式。开放式源码项目有一个特别之处,就是程序开发人员在地域上分布很广,这使得它和其他敏捷方法不同,因为一般的敏捷方法都强调项目组成员在同一地点工作。开放源码的一个突出特点就是查错排障(Debug)的高度并行性,任何人发现了错误都可将改正源码的补丁文件发给维护者。然后由维护者将这些补丁或是新增的代码并入源码库。
(4)Scrum。Scrum 已经出现很久了,像前面所论及的方法一样,该方法强调这样一个事实,即明确定义了的可重复的方法过程只限于在明确定义了的可重复的环境中,为明确定义了的可重复的人员所用,去解决明确定义了的可重复的问题。
(5)功用驱动开发方法(Feature Driven Development,FDD)是由 Jeff De Luca 和 Peter Coad 提出来的。像其他方法一样,它致力于短时的迭代阶段和可见可用的功能。在 FDD 中,一个迭代周期一般是两周。
在 FDD 中,编程开发人员分成两类:首席程序员和类程序员(Class Owner)。首席程序员是最富有经验的开发人员,他们是项目的协调者、设计者和指导者,而类程序员则主要做源码编写。
(6)ASD 方法。ASD(Adaptive Software Development)方法由 Jim Highsmith 提出,其核心是三个非线性的、重叠的开发阶段:猜测、合作与学习。
答案:B D
- 需求管理是一个对系统需求变更、了解和控制的过程。以下活动中,()不属于需求管理的主要活动。
A.文档管理B.需求跟踪 C.版本控制 D.变更控制
解析:需求管理的活动包括变更控制、版本控制和需求跟踪等。
答案:A
- 结构化程序设计采用自顶向下、逐步求精及模块化的程序设计方法,通过()三种基本的控制结构可以构造出任何单入口单出口的程序。
A.顺序、选择和嵌套 B.顺序、分支和循环C.分支、并发和循环 D.跳转、选择和并发
解析:结构化程序设计采用自顶向下、逐步求精及模块化的程序设计方法,通过顺序、分支和循环三种基本的控制结构可以构造出任何单入口单出口的程序。
答案:B
第8小时 数据库设计基础知识
8.0 章节考点分析
第8小时主要学习数据库基础概念、关系数据库、数据库设计、应用程序与数据库交互、NoSQL数据库等内容。本小时内容侧重于概念知识,知识点会涉及单选题(约占$2\sim 5$分)和案例题(25分),根据以往全国计算机技术与软件专业技术资格(水平)考试的出题规律,考查的知识点多源于教材,扩展内容较少。本小时知识架构如图8.1所示。
图8.1 本小时知识架构
【导读小贴士】
作为一名合格的系统架构师,必须掌握数据库设计的基本概念和方法。本小时介绍数据库技术的发展历程以及数据模型、主流的关系数据库、数据库设计的步骤与方法、新型数据库 NoSQL。系统架构设计师考试中的一些案例分析题会来自本小时的内容。建议考生在理解的基础上掌握核心知识点,学会灵活应用。
8.1 数据库基础概念
【基础知识点】
- 基础概念
(1)数据(Data):是描述事物的符号记录,它具有多种表现形式,如文字、图形、图像、声音和语言等。(2)数据库系统(DataBase System,DBS):是一个采用了数据库技术,有组织地、动态地存储大量相关联数据,从而方便多用户访问的计算机系统。(3)数据库(DataBase,DB):是统一管理的、长期储存在计算机内的,有组织的相关数据的集合。(4)数据库管理系统(DataBase Management System,DBMS):是数据库系统的核心软件,是由一组相互关联的数据集合和一组用以访问这些数据的软件组成。DBMS 通常分三类:关系数据库系统(Relation DataBase System,RDBS)、面向对象的数据库系统(Object-Oriented DataBase Systems,OODBS)、对象关系数据库系统(Objective Relational DataBase System,ORDBS)。
- 发展阶段
(1)人工管理阶段。特点:数据量较少、数据不保存、没有软件系统对数据进行处理。缺点:应用程序与数据之间依赖性太强、数据组与数据组之间存在数据冗余。 (2)文件系统阶段。特点:数据可长期保留、数据不属于某个特定应用、文件组织形式多样化。缺点:数据冗余、数据不一致性、数据孤立。 (3)数据库系统阶段。特点:采用复杂的数据模型表示数据结构、有较高的数据独立性。优点:对应用程序的高度独立性、数据的充分共享性、操作方便性。
- 数据模型
数据模型三要素:数据结构、数据操作、数据的约束条件。其中,数据的约束条件包括:
(1)实体完整性。实体完整性是指实体的主属性不能取空值。 (2)参照完整性。在关系数据库中主要是指外键参照的完整性。若A关系中的某个或者某些属性参照B关系或其他几个关系中的属性,那么在关系A中该属性要么为空,要么必须出现在B关系或者其他的关系的对应属性中。 (3)用户定义完整性。用户定义完整性反映的是某一个具体应用所对应的数据必须满足一定的约束条件。例如,软考成绩不能小于0,也不能大于75。
- 数据库管理系统
数据库管理系统的主要功能包括数据定义,数据库操作,数据库运行管理,数据组织、存储和管理,数据库的建立和维护。数据库管理系统的特点:数据结构化且统一管理、有较高的数据独立性、数据控制功能。数据控制功能包括:保证数据的安全性和完整性以及并发控制的能力。
- 数据库三级模式两级映像
数据库一般采用三级模式,其体系结构如图8.2所示,系统开发人员需要通过视图层、逻辑层和物理层三个层次上的抽象来降低用户屏蔽系统的复杂性,简化用户与系统的交互。从数据库管理系统的角度,数据库也分为外模式、概念模式和内模式。具体概念见表8.1。
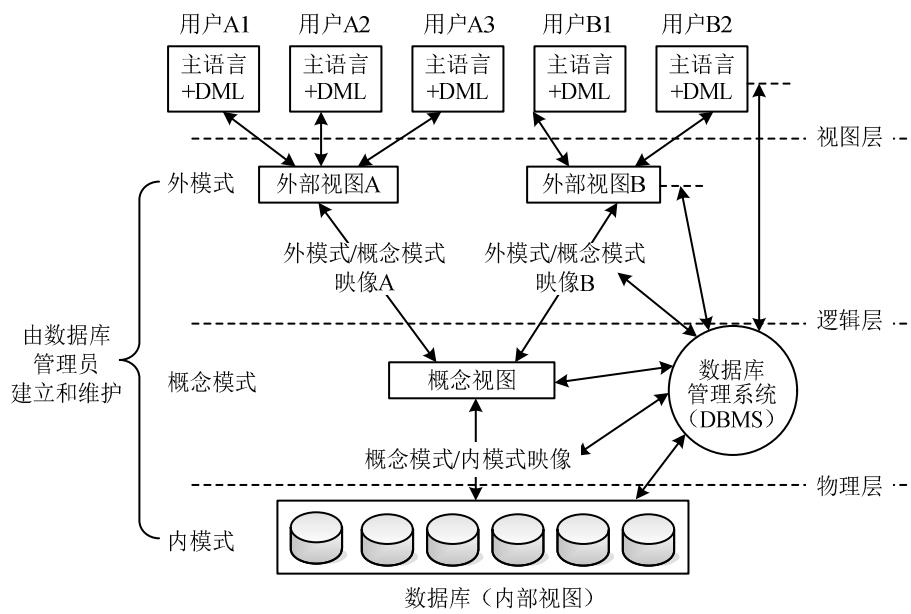
图8.2 数据库系统体系结构
数据库系统在三级模式之间提供了两级映像:概念模式/内模式映像、外模式/概念模式映像。这两级映像保证了数据库中的数据具有较高的逻辑独立性和物理独立性。具体见表8.2。
表8.1 数据库的三级模式
数据库系统结构: 三级模式: 外模式:数据的局部逻辑结构和特征的描述 模式:数据的全局逻辑结构和特征的描述 内模式:是数据物理结构和存储方式的描述,数据在数据库内部的表示方式
二级映像
外模式/模式映像: 当模式改变时,数据库管理员修改有关的外模式/模式映象,使外模式保持不变 模式/内模式映像: 当数据库的存储结构改变时,数据库管理员修改有关的模式内模式映像,使模式保持不变
| 层次 | 定义与作用 | 关键词 | 对比说明 |
|---|---|---|---|
| 概念模式(Conceptual Schema) | 描述数据库中全体数据的逻辑结构和特征,是所有用户的公共数据视图。 | 整体逻辑结构、公共视图 | 处于数据库的中间层,对上屏蔽物理细节,对下屏蔽用户差异,是连接外模式与内模式的桥梁。 |
| 外模式(External Schema) | 又称 子模式 / 用户模式,定义用户可见和可操作的数据逻辑结构。用户通过外模式编写程序或执行查询。 | 用户视图、局部逻辑结构、应用接口 | 面向具体用户或应用,可有多个;不同用户的外模式可不同,对概念模式的局部抽象。 |
| 内模式(Internal Schema) | 定义数据在数据库中的物理存储结构和访问方式,包括记录类型、索引、文件组织方式等。 | 物理存储、索引、文件结构 | 面向存储管理,只有一个;体现系统性能优化和物理实现方式。 |
表8.2 数据库的两级映像
| 类型 | 定义与作用 | 关键词 | 对比说明 |
|---|---|---|---|
| 逻辑独立性(Logical Independence) | 对应外模式与概念模式之间的映像。指应用程序与数据库逻辑结构相互独立,当逻辑结构(如表结构、字段)改变时,应用程序无需修改。 | 外–概映像、应用不变、结构可改 | 关注数据逻辑结构的变化;保持用户视图稳定,提高系统的可维护性与扩展性。 |
| 物理独立性(Physical Independence) | 对应概念模式与内模式之间的映像。指应用程序与物理存储方式相互独立,当数据的物理存储或访问方式改变时,应用程序不受影响。 | 概–内映像、存储可改、逻辑不变 | 关注物理层优化(如索引、文件组织);保证逻辑结构与应用层不受底层存储变化影响。 |
8.2 关系数据库(依赖、范式、事务)
【基础知识点】
- 基本概念
(1)属性(Attribute):在现实世界中,要描述一个事物常常取若干特征来表示。这些特征称为属性。 (2)域(Domain):每个属性的取值范围对应一个值的集合,称为该属性的域。 (3)目或度(Degree):目或度指的是一个关系中属性的个数。 (4)候选码(CandidateKey):若关系中的某一属性或属性组的值,能唯一地标识一个元组,则称该属性或属性组为候选码。判断候选码有一种比较快速的方式,就是看哪个属性只在依赖集F中“ $\twoheadrightarrow$ ”的左边出现过,那么该关系的候选码就必定包含那个属性。 (5)主码(PrimaryKey):或称主键,若一个关系有多个候选码,则选定其中一个作为主码。 (6)主属性(PrimeAttribute):包含在任何候选码中的属性称为主属性。 (7)外码(ForeignKey):如果关系模式R中的属性或属性组不是该关系的码,但它是其他关系的码,那么该属性对关系模式R而言是外码。 (8)全码(All-key):关系模型的所有属性组是这个关系模式的候选码,称为全码。
- 关系代数运算
关系代数的运算符有4类:集合运算符、专门的关系运算符、算术比较符和逻辑运算符,系统架构设计师考试重点考查集合运算符与专门的关系运算符。集合运算符、专门的关系运算符的含义及解释详见表8.3。
关系代数的运算中还有一类是属于扩展的关系代数运算,可以从基本的关系运算中导出。系统架构设计师考试关注的是外连接运算,这是连接运算的一种扩展。外连接运算包括左外连接、右外连接、完全外连接。具体见表8.4。
表8.3集合运算符和专门的关系运算符的含义及解释
| 运算符分类 | 运算符 | 含义 | 解释 |
|---|---|---|---|
| 集合运算符 | U | 并 | 关系 R 与 S 的并是由属于 R 或属于 S 的元组构成的集合 |
| - | 差 | 关系 R 与 S 的差是由属于 R 但不属于 S 的元组构成的集合 | |
| ∩ | 交 | 关系 R 与 S 的交是由属于 R 同时又属于 S 的元组构成的集合 | |
| $R \times S$ | 笛卡儿积 | - 两个关系分别为 n 列和 m 列的关系 R 和 S 的笛卡儿积是一个 (n+m) 列的元组的集合。其中的前 n 列是关系 R 的一个元组,后 m 列是关系 S 的一个元组,记作 R×S。 - 若 R 和 S 有相同的属性名,可在属性名前加关系名作为限定,以示区别。若 R 有 K1 个元组,S 有 K2 个元组,则结果有 K1×K2 个元组 | |
| 专门的关系运算符 | σ | 选择 | 取得关系 R 中符合条件的行 |
| π | 投影 | 取得关系 R 中符合条件的列 | |
| $R \bowtie_{A=B} S$ | 连接 | - 等值连接:取 R、S 的笛卡儿积中属性值相等的元组。 - 自然连接:特殊的等值连接,要求比较的属性列必须是相同的属性组,并且把结果中重复属性去掉 | |
| ÷ | 除 | 给定 R(X,Y) 和 S(Y,Z),其中 X,Y,Z 为属性组。R 中的 Y 与 S 中的 Y 可有不同属性名,但必须出自相同的域集。R ÷ S 得到 P(X),P 是 R 中满足:元组在 X 上分量值 x 的象集 Yx ⊇ S 在 Y 上投影的集合 |
表8.4外连接运算符
| 运算符 | 含义 | 名词解释 |
|---|---|---|
| $R \ ⟕\ S$ | 左外连接 | 取左侧关系中所有与右侧关系不匹配的元组,用 null 填充右侧属性,加入自然连接结果中 |
| $R \ ⟖\ S$ | 右外连接 | 取右侧关系中所有与左侧关系不匹配的元组,用 null 填充左侧属性,加入自然连接结果中 |
| $R \ ⟗\ S$ | 完全外连接 | 完成左外连接和右外连接:即同时填充左侧关系中不匹配的元组和右侧关系中不匹配的元组,用 null 填充缺失部分,加入自然连接结果中 |
- 关系数据库设计基本理论
(1)函数依赖:设R(U)是属性U上的一个关系模式,X和Y是U的子集,r是R的任一关系,如果对于r中的任意两个元组u和v,只要有 $\mathrm{u[X] = v[X]}$ ,就有 $\mathrm{u[Y] = v[Y]}$ ,则称X函数决定Y,或称Y函数依赖于X,记为 $\mathrm{X}\to \mathrm{Y}$ 。函数依赖是一种最重要、最基本的数据依赖。而关系数据库设计理论的核心就是数据间的函数依赖。 (2)非平凡的函数依赖:如果 $\mathrm{X}\to \mathrm{Y}$ , $\mathrm{Y}\not\subseteq\mathrm{X}$,即依赖的右边不是左边属性的子集 ,则称 $\mathrm{X}\to \mathrm{Y}$ 是非平凡的函数依赖。例子:学号 → 姓名 ✅(非平凡依赖,因为 姓名 不是 学号 的一部分)。 (3)平凡的函数依赖:如果 $\mathrm{X}\to \mathrm{Y}$ ,但 $\mathrm{Y}\subseteq \mathrm{X}$ ,即依赖的右边被包含在左边里面 ,则称 $\mathrm{X}\to \mathrm{Y}$ 是平凡的函数依赖。例子:(学号, 姓名) → 学号 ✅(平凡依赖,因为学号就在左边里面)。 (4)完全函数依赖:在一个关系模式里,如果Y依赖于X,但Y不依赖于X的任何真子集,则称Y完全函数依赖于X。例如,有学生关系模式(学号,系号,系主任,课程号,成绩),该关系模式的主码是学号+课程号,(学号,课程号) $\twoheadrightarrow$ 成绩是完全函数依赖。 (5)部分函数依赖:如果Y依赖于X,但其实只依赖于X的一部分属性,那么就叫 部分函数依赖。上述例子中,(学号,课程号) $\twoheadrightarrow$ 系号就属于部分函数依赖,因为对于系号来说有学号就可以推出系号。 (6)传递依赖:上述例子中,学号 $\twoheadrightarrow$ 系号,系号 $\twoheadrightarrow$ 系主任名,则称系主任名传递依赖于学号。 (7)函数依赖的公理系统(Armstrong公理系统):从已知的一些函数依赖,可以推导出另外一些函数依赖,这就需要一系列推理规则,这些规则常被称作Armstrong公理。
设关系式R(U,F),U是关系模式R的属性集,F是U上的一组函数依赖,则有以下三条推理规则:
1)A1自反律:若 $\mathrm{Y}\subseteq \mathrm{X}\subseteq \mathrm{U}$ ,则 $\mathrm{X}\to \mathrm{Y}$ 为F所蕴含。 2)A2增广律:若 $\mathrm{X}\to \mathrm{Y}$ 为F所蕴含,且 $Z\subseteq U$ ,则 $\mathrm{XZ}\to \mathrm{YZ}$ 为F所蕴含。 3)A3传递律:若 $\mathrm{X}\to \mathrm{Y}$ , $\mathrm{Y}\to \mathrm{Z}$ 为F所蕴含,则 $\mathrm{X}\to \mathrm{Z}$ 为F所蕴含。
根据上面三条推理规则,又可推出下面三条推理规则:
1)合并规则:若 $\mathrm{X}\to \mathrm{Y}$ , $\mathrm{X}\to \mathrm{Z}$ ,则 $\mathrm{X}\to \mathrm{YZ}$ 为F所蕴含。 2)伪传递规则:若 $\mathrm{X}\to \mathrm{Y}$ , $\mathrm{WY}\to \mathrm{Z}$ ,则 $\mathrm{XW}\to \mathrm{Z}$ 为F所蕴含。 3)分解规则:若 $\mathrm{X}\to \mathrm{Y}$ , $Z\subseteq Y$ ,则 $\mathrm{X}\to \mathrm{Z}$ 为F所蕴含。
无损分解。无损分解判断条件是:交集能推出差集中的属性,只要R1∩R2→(R1-R2)或R1∩R2→(R2-R1)有一个成立,就属于无损分解。好比您把公司员工表按部门和薪资拆分,只要部门ID能推出薪资信息,或薪资表能还原员工信息,两个表连接就不会丢数据。

第一空选择D选项。 对于A选项,根据Armstrong推理分解规则,A一BC,可以得到A一B,A-C,所以A选项的前半句描述是正确的 但根据A→B,B→D,D一E,此时存在传递函数依赖,所以A选项的后半句描述错误,所以A选项错误。 对于B选项,无法得到E→A,故该选项描述错误。 对于C选项,无法得到E一A,并且集合中存在传递函数依赖,所以C选项描述错误。 对于D选项,根据A选项的分析过程,A→B,B一D,D一E,根据传递律,可以得到A→D,A→E,B-E,并且存在传递函数依赖,所以D选项说法正确。 第二空选择A选项。 根据题干描述,原关系模式为:U={A,B,C,D,E),F={A→BC,B→D,D→E}。 将关系R分解为p={R1(U1,F1),R2(U2,F2)},其中:U1={A,B,C}、U2={B,D,E}。 首先根据U1,保留函数依赖A→BC,然后根据U2,保留函数依赖B一D,D一E。因此该分解保持函数依赖。 接下来可以利用公式法验证无损分解。 U∩U2=B,U1-U2={A,C},U2-U1={D,E},而R中存在函数依赖B→D,B一E,所以该分解是无损分解。(有一个就行)
- 关系数据库的规范化
关系数据库设计的方法之一就是设计满足适当范式的模式,通常可以通过判断分解后的模式达到几范式来评价模式的规范化程度。范式包括:1NF、2NF、3NF、BCNF、4NF、5NF。根据系统架构设计师考试的要求,这里重点介绍1NF、2NF、3NF、BCNF的基本概念。
(1)第一范式(1NF):若关系模式R的每一个分量是不可再分的数据项,则关系模式R属于第一范式。 (2)第二范式(2NF):若关系模式 $\mathrm{R}\in \mathrm{1NF}$ ,且消除了非主属性对主码的部分传递依赖时,则关系式R是2NF(第二范式)。 (3)第三范式(3NF):当2NF消除了非主属性对主码的传递函数依赖,则称为3NF。 (4)BC范式(BCNF):如果关系模式 $\mathrm{R}\in \mathrm{1NF}$ ,且每个属性都不传递依赖于R的候选码,那么称R是BCNF模式。
上述4种范式之间有如下联系: $\mathrm{BCNF}\subset 3\mathrm{NF}\subset 2\mathrm{NF}\subset 1\mathrm{NF}$
- 事务管理
DBMS运行的基本工作单位是事务,事务是用户定义的一个数据库操作序列,这些操作序列要么全做,要么全都不做,是一个不可分割的工作单位。事务具有的四个特性(ACID):
(1)原子性(Atomicity):事务是数据库的逻辑工作单位,事务的所有操作在数据库中要么全做,要么全都不做。 (2)一致性(Consistency):事务的执行使数据库从一个一致性状态变成另一个一致性状态。 (3)隔离性(Isolation):一个事务的执行不能被其他事务干扰。 (4)持久性(Durability):指一个事务一旦提交,它对数据库的改变必须是永久的,即便系
统出现故障时也是如此。
- 相关的SQL语句
(1)BEGIN TRANSACTION:事务开始语句。 (2)COMMIT:事务提交语句,表示事务执行成功地结束,把事务对数据库的修改写入磁盘(事务对数据库的操作首先是在缓冲区中进行的)。 (3)ROLL BACK:事务回滚语句,表示事务执行不成功地结束,即把事务对数据库的修改进行恢复。
- 并发控制
在多用户共享系统中,许多事务可能同时对同一数据进行操作,称为并发操作,此时数据库管理系统的并发控制子系统负责协调并发事务的执行,保证数据库的完整性不受破坏,同时避免用户得到不正确的数据。并发控制的主要技术是封锁,主要有两种类型的封锁,分别是X封锁和S封锁。
(1)排他型封锁(X封锁):如果事务T对数据A(可以是数据项、记录、数据集以至整个数据库)实现了X封锁,那么只允许事务T读取和修改数据A,其他事务要等事务T解除X封锁以后,才能对数据A实现任何类型的封锁。可见X封锁只允许一个事务独锁某个数据,具有排他性。 (2)共享型封锁(S封锁):如果事务T对数据A实现了S封锁,那么允许事务T读取数据A,但不能修改数据A,在所有S封锁解除之前决不允许任何事务对数据A实现X封锁。
- 数据库的备份与恢复
(1)备份(转储)与恢复:备份是指通过数据转储和监理日志文件的方法监理冗余数据,DBA定期地将整个数据库复制到磁带或另一个磁盘上保存起来的过程。这些备用的数据文本称为后备副本。数据库的恢复是指把数据库从错误状态恢复到某一个已知的正确状态的功能。当数据库遭到破坏后,就可以利用后备副本把数据库恢复,这时数据库只能恢复到备份时的状态,从那以后的所有更新事务必须重新运行才能恢复到故障时的状态。
(2)备份分类包括以下4种:
1)静态备份:指备份期间不允许(或不存在)对数据库进行任何存取、修改活动。静态备份简单,但备份必须等待用户事务结束才能进行,新的事务必须等待备份结束才能执行。这降低了数据库的可用性。 2)动态备份:指备份期间允许对数据库进行存取或修改,即备份和用户事务可以并发执行。动态备份可克服静态备份的缺点,但备份结束时后援副本上的数据并不能保证正确有效。 3)海量备份:指每次备份全部数据库。 4)增量备份:指每次只备份上次备份后更新过的数据。如果数据库很大,事务处理又十分频繁,则增量备份方式是很有效的。
(3)数据库的4类故障:事务故障、系统故障、介质故障、计算机病毒。事务故障的恢复有两个操作:撤销事务(UNDO)和重做事务(REDO)。介质故障的恢复由数据库管理员装入数据库的副本和日记文件副本,再由系统执行撤销和重做操作。
- 闭包
给出关系 R(U, F), U = {A, B, C, D, E} ,F = { A → B, D → C, BC → E, AC → B } 求属性闭包的等式成立的是 ( )。 R 的候选键为 ( )。
问题1选项: A. (A)⁺ = U B. (B)⁺ = U C. (AC)⁺ = U D. (AD)⁺ = U
问题2选项: A. AD B. AB C. AC D. BC
第一问:属性闭包
- (A)⁺
- A → B ⇒ 得到 B
- 结果 = {A, B}
- 缺少 C, D, E ⇒ 不等于 U ❌
- (B)⁺
- B 单独无推导
- 结果 = {B}
- 不等于 U ❌
- (AC)⁺
- 已有 A, C
- AC → B ⇒ 得到 B
- 有 B, C ⇒ BC → E ⇒ 得到 E
- 结果 = {A, B, C, E}
- 缺少 D ⇒ 不等于 U ❌
- (AD)⁺
- 已有 A, D
- A → B ⇒ 得到 B
- D → C ⇒ 得到 C
- 现在有 A, B, C, D
- BC → E ⇒ 得到 E
- 结果 = {A, B, C, D, E} = U ✅
👉 正确答案:D. (AD)⁺ = U
第二问:候选键
- (AD)⁺ = U,说明 AD 是超键
- A⁺ = {A, B},不等于 U
- D⁺ = {D, C},不等于 U
- 所以 AD 是最小的候选键
👉 候选键:AD
✅ 最终答案
- 问题1:D. (AD)⁺ = U
- 问题2:A. AD
8.3 数据库设计
【基础知识点】
(1)数据库设计的基本步骤。可以分为用户需求分析、概念结构设计、逻辑结构设计、物理结构设计、应用程序设计、运行维护。 ①需求分析。数据库设计人员采用一定的辅助工具对应用对象的功能、性能、限制等要求所进行的科学分析。 ②概念设计。概念结构设计是对信息分析和定义,如视图模型化、视图分析和汇总。对应用对象精确地抽象、概括而形成的独立于计算机系统的企业信息模型。描述概念模型的较理想的工具是E-R图。 ③逻辑设计。将抽象的概念模型转化为与选用的DBMS产品所支持的数据模型相符合的逻辑模型,它是物理设计的基础。包括模式初始设计、子模式设计、应用程序设计、模式评价以及模式求精。主要工作步骤:转换为数据模型→关系规范化→模式优化→设计用户模式 ④物理设计。逻辑模型在计算机中的具体实现方案。
| 阶段 | 关键词 | 主要任务 / 内容 | 核心说明与要点 |
|---|---|---|---|
| 需求分析 | 信息需求、处理需求、系统需求 | 对应用对象的功能、性能、限制进行科学分析,输出数据字典和数据流图、需求说明书 | 采用问卷、访谈等手段,明确系统边界、综合各用户需求 |
| 概念设计 | E-R模型、概念模型、抽象 | 对信息进行分析和定义,形成独立于计算机的企业信息模型,使用E-R图 | 使用 E-R 图(实体-联系图) 进行建模,解决 属性冲突、命名冲突、结构冲突 |
| 逻辑设计 | 数据模型、模式转换、完整性约束 | 将概念模型转化为逻辑模型(如关系模型);规范化与反规范化 | 包括 模式初始设计、子模式设计、模式求精;是物理设计的基础 |
| 物理设计 | 数据分布、存储结构、访问方式 | 制定逻辑模型在计算机中的具体实现方案 | 涉及 索引、文件组织、分区策略 等物理优化 |
| 应用程序设计 | 操作接口、应用逻辑 | 设计实现数据库操作的应用程序模块 | 确定 输入输出格式、事务处理流程、异常控制逻辑 |
| 运行与维护 | 优化、备份、恢复、安全 | 数据库投入运行后的监控与维护 | 包括 性能调优、备份恢复、安全管理、版本迭代 |
(2)数据需求分析。用户需求分析是综合各用户的应用需求,对现实世界要处理的对象进行详细调查,在了解先行系统的概况,确定新系统功能的过程中,协助用户明确对新系统的信息要求、处理要求和系统要求,确定新系统的边界。
(3)概念结构设计。概念数据模型又称为实体-联系模型,它按照用户的观点来对数据和信息建模,主要用于数据库设计。概念模型主要用实体-联系方法(Entity-Relationship Approach) 表示,简称E-R方法。概念结构设计工作步骤包括:选择局部应用、逐一设计分E-R图和E-R图合并。在进行E-R图合并时,需解决属性冲突、命名冲突和结构冲突。
①属性冲突:包括属性域冲突和属性取值冲突。 ①命名冲突:包括同名异义和异名同义。 ②结构冲突:包括同一对象在不同应用中具有不同的抽象,以及同一实体在不同局部E-R图中所包含的属性个数和属性排列次序不完全相同。
E-R模型简称E-R图,是描述概念世界、建立概念模型的实用工具。E-R图的三个要素有:
①实体(型):用矩形框表示,框内标注实体名称。 ①属性:用椭圆形表示,并用连线与实体连接起来。 ②实体之间的联系:用菱形框表示,框内标注联系名称,用连线将菱形框分别与有关实体相连,并在连线上注明联系类型。
(4)逻辑结构设计。逻辑结构设计阶段主要工作步骤包括确定数据模型、将E-R图转换成指定的数据模型、确定完整性约束和确定用户视图。 常见的反规范化技术包括: ①增加冗余列:增加冗余列是指在多个表中具有相同的列,它常用来在查询时避免连接操作。 ②增加派生列:增加派生列指增加的列可以通过表中其他数据计算生成。它的作用是在查询时减少计算量,从而加快查询速度。 ③重新组表:重新组表指如果许多用户需要查看两个表连接出来的结果数据,则把这两个表重新组成一个表来减少连接而提高性能 ④分割表:有时对表做分割可以提高性能。 水平分割:根据一列或多列数据的值把数据行放到两个独立的表中。水平分割通常在下面的情况下使用。 1)表很大,分割后可以降低在查询时需要读的数据和索引的页数,同时也降低了索引的层数,提高查询效率。 2)表中的数据本来就有独立性,例如表中分别记录各个地区的数据或不同时期的数据,特别是有些数据常用,而另外一些数据不常用。 3)需要把数据存放到多个介质上。 垂直分割:把主码和一些列放到一个表,然后把主码和另外的列放到另一个表中。如果一个表中某些列常用,而另外一些列不常用,则可以采用垂直分割,另外垂直分割可以使得数据行变小,一个数据页就能存放更多的数据,在查询时就会减少I/0次数。其缺点是需要管理冗余列,查询所有数据需要连接操作。
针对反规范化数据不一致问题,可采用的解决方案包括: 1)触发器数据同步。 2)应用程序数据同步。 3)批处理同步。 (5)物理设计。物理设计主要工作步骤包括确定数据分布、存储结构和访问方式。
(6)数据库实施。数据库实施是根据逻辑和物理设计的结果,在计算机上建立实际的数据库结构,数据加载(装入),进行试运行和评价。
(7)数据库运行维护。数据库运行维护主要包括对数据库性能的监测和改善、故障恢复、数据库的重组和重构。在数据库运行阶段,对数据库的维护主要由DBA完成。
(8)商业智能。商业智能(Business Intelligence,BI) 是企业对商业数据的搜集、管理和分析的系统过程,目的是使企业的各级决策者获得知识或洞察力,帮助他们作出对企业更有利的决策。一般认为数据仓库、联机分析处理(OLAP) 和数据挖掘是商业智能的三大组成部分。
商业智能系统的处理过程包括数据预处理、建立数据仓库、数据分析及数据展现4个主要阶段。 1)数据预处理是整合企业原始数据的第一步,包括数据的抽取、转换和装载三个过程。 2)建立数据仓库则是处理海量数据的基础。 3)数据分析是体现系统智能的关键,一般采用OLAP和数据挖掘技术。联机分析处理不仅进行数据汇总/聚集,同时还提供切片、切块、下钻、上卷和旋转等数据分析功能,用户可以方便地对海量数据进行多维分析。数据挖掘的目标则是挖掘数据背后隐藏的知识,通过关联分析、聚类和分类等方法建立分析模型,预测企业未来发展趋势和将要面临的问题。 4)在海量数据和分析手段增多的情况下,数据展现则主要保障系统分析结果的可视化。
(9)数据仓库(Data Warehouse) 是一个面向主题的、集成的、相对稳定且随时间变化的数据集合,用于支持管理决策。数据仓库的关键特征是:面向主题、集成的、非易失的、时变的。
传统数据库与数据仓库的比较见表8.5。
OLTP与OLAP的比较:OLTP即联机事务处理,就是我们经常说的关系数据库的基础;OLAP即联机分析处理,是数据仓库的核心部分。OLTP与OLAP的具体区别见表8.6。
表8.5传统数据库与数据仓库的比较
| 比较项目 | 传统数据库 | 数据仓库 |
| 数据内容 | 当前值 | 历史的、归档的、归纳的、计算的数据(处理过的) |
| 数据目标 | 面向业务操作程序、重复操作 | 面向主体域、分析应用 |
| 数据特性 | 动态变化、更新 | 静态、不能直接更新,只能定时添加、更新 |
| 数据结构 | 高度结构化、复杂,适合操作计算 | 简单、适合分析 |
| 使用频率 | 高 | 低 |
| 数据访问量 | 每个事务一般只访问少量记录 | 每个事务一般访问大量记录 |
| 对响应时间的要求 | 计时单位小,如秒 | 计时单位相对较大,除了秒,还有分钟、小时 |
表8.6OLTP与OLAP的区别
| 项目 | OLTP | OLAP |
| 用户 | 操作人员、低层管理人员 | 决策人员、高级管理人员 |
| 功能 | 日常操作处理 | 分析决策 |
| DB 设计 | 面向应用 | 面向主题 |
| 数据 | 当前的、最新的、细节的、二维的、分立的 | 历史的、聚集的、多维的、集成的、统一的 |
| 存取 | 读/写数千条记录 | 读上百万条记录 |
| 工作单位 | 简单的事务 | 复杂的查询 |
| 用户数 | 上千个 | 上百个 |
| DB 大小 | 100MB 至 GB 级 | 100GB 至 TB 级 |
(10)数据挖掘。数据挖掘是在没有明确假设的前提下去挖掘信息、发现知识。数据挖掘所得到的信息应具有先知、有效和实用三个特征。先前未知的信息是指该信息是预先未曾预料到的,即数据挖掘是要发现那些不能靠直觉发现的信息或知识,甚至是违背直觉的信息或知识,挖掘出的信息越是出乎意料,就可能越有价值。
8.4 应用程序与数据库的交互
【基础知识点】
常见应用程序与数据库交互方式有库函数、嵌入式SQL、通用数据接口标准和对象关系映射等。
- 库函数级别访问接口
库函数级别的数据访问接口是数据库提供的最底层的高级程序语言访问数据接口,如Oracle数据库的Oracle Call Interface(OCI)。OCI由一组应用程序开发接口(API)组成,实际是将结构化查询语言(SQL)和高级语言程序相结合。其缺点是强依赖于特定的数据库,需数据库开发人员
对数据库机制有较深的理解,学习难度较大,开发效率不是很高。
- 嵌入式SQL访问接口
嵌入式SQL(EmbeddedSQL)是一种将SQL语句直接写入某些高级程序语言源代码中的方法。
- 通用数据接口标准
通用数据接口标准:开放数据库连接(Open DataBase Connectivity,ODBC)是为解决异构数据库间的数据共享产生的。优点是不依赖于任何DBMS,能以统一的方式处理所有的关系数据库。常见数据库接口包括数据库访问对象(Data Access Object,DAO)、远程数据库对象(Remote Data Object,RDO)、ActiveX数据对象(Active Data Object,ADO)、Java数据库连接(java DataBase Connection,JDBC)。
- ORM访问接口
对象关系映射(ObjectRelationshipMapping,ORM)用于实现面向对象编程语言里不同类型系统数据之间的转换。典型的ORM框架有Hibernate、Mybatis和JPA等。
(1)Hibernate:全自动化的框架,强大、复杂、笨重、学习成本高。(2)Mybatis:半自动的框架。(3)JPA:Java自带的框架。
8.5 NoSQL数据库
【基础知识点】
分类与特点
NoSQL是一种概念,泛指非关系型的数据库,区别于关系数据库,它们不保证关系数据的ACID特性。NoSQL数据库按照所使用的数据结构的类型,可分为列式存储数据库、键值对存储数据库、文档型数据库、图数据库。
(1)列式存储数据库用来应对分布式存储的海量数据,键仍然存在,特点是指向了多个列。现有产品如Cattandra、HBate、Riak。 (2)键值对存储数据库优势是简单、易部署。但是只对部分值查询或更新时效率低下。现有产品如TokzoCabinet/Tzranu、Redis、Voldemort、OracleBDB。 (3)文档型数据库在处理网页等复杂数据时,比传统键值对数据库查询效率更高,现有产品如CouchDB、MongoDB、SequoiaDB。 · (4)图数据库适合存储通过图进行建模的数据,如社交网络数据、生物信息网络数据,交通网络数据等。常见产品有Neo4J、InfoGrid、InfiniteGraph等。
NoSQL特征:易扩展、大数据量、高性能、灵活的数据模型、高可用。
- 体系框架
NoSQL整体框架由下至上分为数据持久层(Data Persistence)、数据分布层(Data Distribution Model)、数据逻辑模型层(Data Logical Model)和接口层(Interface)。
NoSQL数据库适用情况:数据模型比较简单、需灵活性更强的IT系统,对数据库性能要求较高、不需要高度的数据一致性。
8.6 分布式数据库
【基础知识点】
- 体系结构
分布式数据库的体系结构如图8.3所示
(1)全局外模式(全局视图):全局视图是全局应用的用户视图,是全局概念模式的子集,该层直接与用户(或应用程序)交互。 (2)全局概念模式:全局概念模式定义分布式数据库中数据的整体逻辑结构,数据就如同根本没有分布一样,可用传统的集中式数据库中所采用的方法进行定义。 (3)分片模式:将一个关系模式分解成为几个数据片。原则:完整性、重构性、不相交性 (4)分布模式(分配模式):分布式数据库的本质特性就是数据分布在不同的物理位置。分配模式的主要职责是定义数据片段(即分片模式的处理结果)的存放节点。 (5)局部概念模式:局部概念模式是局部数据库的概念模式。 (6)局部内模式:局部内模式是局部数据库的内模式。
| 分布式模式层次 | 关键词 | 作用说明 | 对比说明 |
|---|---|---|---|
| 全局外模式 | 用户视图、统一访问 | 为用户提供统一的访问入口,屏蔽数据分布细节 | 类似集中式数据库的视图,用户看到的是完整表 |
| 全局概念模式 | 全局逻辑结构 | 定义全局逻辑数据模型 | 与集中式数据库的概念模式一致,不关心数据分布 |
| 分片模式 | 数据拆分规则 | 指定如何将全表划分为多个数据片段 | 相当于对表进行逻辑分割 |
| 分布模式(分配模式) | 数据放置、节点分布 | 指定每个分片(数据片)存放节点 | 体现分布式的核心特征 |
| 局部概念模式 | 节点逻辑结构 | 定义本地节点上数据的逻辑结构 | 相当于分布式下的局部逻辑表 |
| 局部内模式 | 存储结构、索引 | 描述数据在物理磁盘上的存储方式 | 对应集中式数据库的物理模式 |
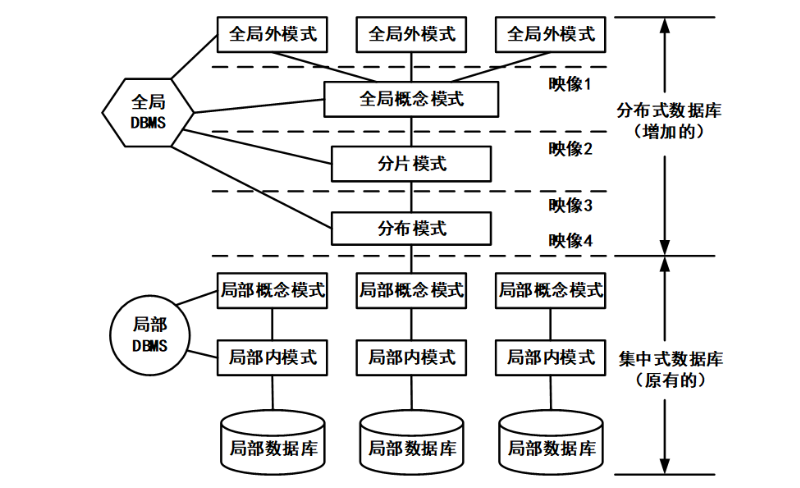 图8.3 分布式数据库体系结构
图8.3 分布式数据库体系结构
- 特点
分布式数据库具有如下特点:
(1)共享性:不同的节点的数据共享。 (2)自治性:每个节点对本地数据都能独立管理。 (3)可用性:某一场地故障时,可以使用其他场地上的副本而不至于使整个系统瘫痪。 (4)分布性:数据分布在不同场地上存储。
- 分布透明性
分布透明性是指用户不必关心数据的逻辑分片,不必关心数据存储的物理位置分配细节,也不必关心局部场地上数据库的数据模型。分布透明性包括分片透明性、位置透明性和局部数据模型透明性。
(1)分片透明性是分布透明性的最高层次。所谓分片透明性是指用户或应用程序只对全局关系进行操作而不必考虑数据的分片。 (2)位置透明性是分布透明性的下一层次。所谓位置透明性是指用户或应用程序应当了解分片情况,但不必了解片段的存储场地。 (3)局部数据模型透明性(逻辑透明)是指用户或应用程序应当了解分片及各片断存储的场地,但不必了解局部场地上使用的是何种数据模型。
- 一致性问题
分布式系统中一致性问题的主要表现形式包括: 1)数据在不同节点间同步延迟,导致读取到的不是最新数据(如购物车数据不同步) 2)跨服务事务处理中,部分操作成功而部分失败(如下单成功但支付失败)。 解决方案: 1)可以采用两阶段提交(2PC)协议来确保跨服务事务的一致性, 2)同时结合最终一致性模型(如主从复制)来减少数据同步延迟,
8.7 数据库优化技术
【基础知识点】
- 集中式数据库优化技术
集中式数据库性能优化最常见的是反规范化设计,主要包括增加冗余列、增加派生列、重新组表、水平分割表、垂直分割表。
(1)增加冗余列。增加冗余列是指在多个表中具有相同的列,它常用来在查询时避免连接操作。 (2)增加派生列。增加派生列指增加的列可以通过表中其他数据计算生成。它的作用是在查询时减少计算量,从而加快查询速度。 (3)重新组表。重新组表指如果许多用户需要查看两个表连接出来的结果数据,则把这两个表重新组成一个表来减少连接,从而提高性能。 (4)水平分割表。按记录进行分割,把数据放到多个独立的表中,主要用于表数据规模很大、表中数据相对独立或数据需要存放到多个介质上时使用。 (5)垂直分割表。对表进行分割,将主键与部分列放到一个表中,主键与其他列放到另一个表中,在查询时减少I/O次数。
反规范化设计的优点是避免进行表之间的连接操作,从而可以提高数据操作的性能;缺点是会造成数据的重复存储,浪费了磁盘空间,会产生数据的不一致性问题。若要避免数据不一致的问题,可以通过设置触发器、采用事务机制(适用于单体数据库中)、应用保证(适用于异构数据库之间)以及批处理脚本的方式,这些方式的优缺点这里不再赘述。
- 分布式数据库优化技术
分布式数据库的性能优化可以采用主从复制、读写分离、分表、分库等技术。
(1)主从复制。主从复制是建立一个和主数据库完全一样的数据库环境,称为从数据库。这样做的好处是:
1)做数据的热备。作为后备数据库,主数据库服务器故障后,可切换到从数据库继续工作,避免数据丢失。 2)架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能。 3)读写分离。使数据库能支持更大的并发。
在MySQL数据库中,主从数据库同步的模式有全同步、半同步、异步三种方式。主从数据库之间通过binlog(二进制日志)进行数据的同步。具体过程如图8.4所示。
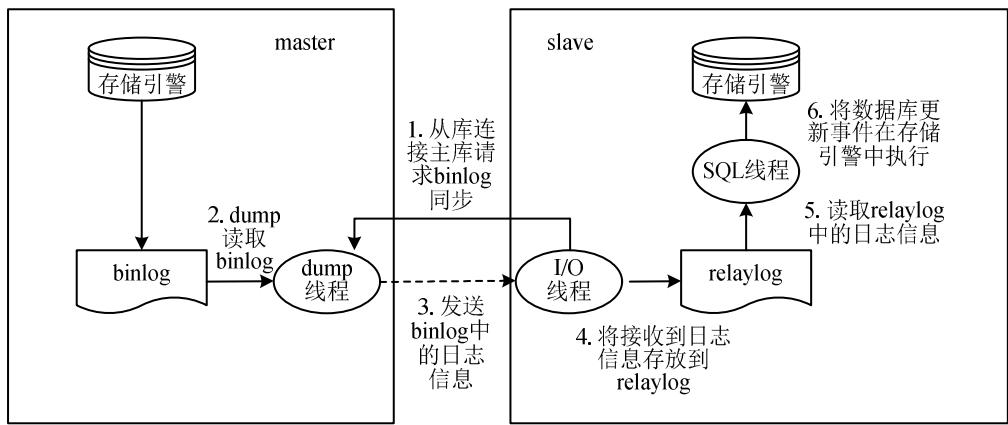
图8.4MySQL主从复制过程
这里的binlog日志有3种模式:
1)基于SQL语句的复制:每一条更新的语句(insert、update、delete)都会记录在binlog中,进而同步到从库的relaylog中,被从库的SQL线程取出来,回放执行。该模式的优点是binlog的日志量可能会比较少,比如一个涉及行数为1000行的update语句,同步这一个语句,就同步了1000行的数据。缺点是同步的SQL语句里如果含有绑定本地变量的函数、关键字,可能造成主从不一致的情况。比如SQL语句中有time函数,如果主从数据库的服务器时间不是精确相等,就会造成结果不一致。
2)基于行的复制:不记录SQL语句,只记录哪个记录更新前和更新后的数据,可以保证主从之间的数据绝对相同。缺点是:1条SQL更新1000行的数据无法再偷懒,必须原原本本同步1000行的数据量。 3)混合复制:以上两种模式的混合,选取两者的优点。对于有绑定本地特性、评估可能造成主从不一致的SQL语句,则自动选用基于行的复制,其他的选择基于SQL语句的复制。 (2)读写分离。设置不同的主、从数据库分别负责不同的操作。让主数据库负责数据的写操作,从数据库负责数据的读操作。通过角色分担的策略,分别提升读写性能,有效减少数据并发操作的延迟。 (3)分表。分表也叫分片,可以提升数据库并发以及I/O的性能。分表重在单个实例内部,将一张大表分成若干小表,业务同时访问多个表。分表的方式有两种,见表8.7。
表8.7 分表的方式
| 垂直切分 | 水平切分 |
| 把一个大表切分为多个表。例如交易ID、状态、用户、金额、商品等,作为一个热表;另外的交易备注、物流信息等众多其他属性可作为另一个表 | 把一个大表分为多个表,每个表都包含相同列,例如交易ID、状态、用户、金额、商品等,但都包含不同的行。例如一个表包含的是交易ID从1到999999的交易数据,另一个表包含的是交易ID从1000000到9999999的交易数据 |
(4)分库。分库是将原本存放在一个实例上众多分类的数据(表),分开存放到不同的实例上。有利于差异化管理。例如,一个简单的电商网站,包括用户、商品、订单三个业务模块,可以将用户数据、商品数据、订单数据分开放到三台不同的数据库服务器上,而不是将所有数据都放在一台数据库服务器上。
8.8 分布式缓存技术Redis
【基础知识点】
- 基本概念
Redis是一种分布式缓存技术,在本书8.5节中也是一种键值对数据库类型。Redis用作缓存组件时,其基于内存的读写特性,比基于磁盘读写的数据库性能要高很多,适合缓存高频热点的数据,来提高读性能。这样可以降低对数据库服务器的查询请求,提高系统性能。Redis以key- value(键值对)的形式为数据的保存格式。键(key)可以是一个字符串,值(value)可以是任意类型的数据。如整型、字符型、数组、列表、集合等。例如键值对:(“20231234”,“张珂”),其key:“20231234”是该数据的唯一标识,而value:“张珂”是该数据实际存储的内容。
- 数据类型
Redis支持的数据类型主要包括string类型、hash类型、set类型、list类型、zset类型、pub/sub类型。 (1)string类型:是Redis基本类型。可用于缓存层或计数器,如视频播放量、文章浏览量等。 (2)hash类型:代替string类型,节省空间。描述用户信息较为方便。 (3)set类型:无序集合,每个值不能重复。可用于去重、抽奖、初始化用户池等。 (4)list类型:双向链表结构,可以模拟栈、队列等形式。可用于回复评论、点赞。 (5)zset 类型:有序集合、每个元素有一个分数。如首页推荐 10 个最热门的帖子。
- 访问方式
引入 Redis 后,热点数据存放在 Redis 中,但由于存在“一份数据存放了多个位置”,所以要考虑数据的一致性问题。读写数据的基本步骤为: (1)读数据: $①$ 根据 key 读缓存; ② 读取成功则直接返回; ③ 若 key 不在缓存中,则根据 key 读数据库; ④ 读取成功后,写缓存; ⑤ 成功返回。 (2)写数据: $①$ 根据 key 值写数据库; ② 成功后更新缓存 key 值; ③ 成功返回。
- 过期策略
在使用 Redis 时,一般会设置 Redis 缓存空间的大小,不会让数据无限制地存放到 Redis 中,对于设置了过期时间的数据可以采用两种方式去淘汰这些数据。
(1)定期删除。Redis 每隔一段时间就会抽取一些设置了过期时间的 key。这里的抽取是随机进行的,因为无法对所有的 key 进行遍历,会给系统带来很大的负担。但是这样也会导致一些 key 到了过期时间也仍然没有被删除。 (2)惰性删除。查询 key 的时候 Redis 会对 key 进行检测,发现如果已经达到过期时间,则删除。惰性删除的缺点是如果这些过期的 key 没有被访问,那么它们就一直无法被删除,而且一直占用内存。
除了上述两种方式,Redis 又提供了一些淘汰机制,主要有:
- volatile-lfu(最近最少使用):从已设置过期时间的 key 中,移出最近最少使用的 key 进行淘汰。
- volatile-lfu(最不经常使用):从 key 中选择最不经常使用的进行淘汰。
- volatile-random(随机淘汰算法):从已设置过期时间的 key 中随机选择 key 淘汰。
- volatile-ttl(生存时间淘汰):从已设置过期时间的 key 中,移出将要过期的 key。
- allkeys-lfu:从所有 key 中选择最近最少使用的进行淘汰。
- allkeys-lfu:从所有 key 中选择最不经常使用的进行淘汰。
- allkeys-random:从所有 key 中随机选择 key 进行淘汰。
- 数据持久化
在实际应用中,一旦服务器宕机,内存中的数据将全部丢失。我们很容易想到的一个解决方案是,从后端数据库恢复这些数据,但这种方式存在两个问题:一是,需要频繁访问数据库,会给数据库带来巨大的压力;二是,这些数据是从慢速数据库中读取出来的,性能肯定比不上从 Redis 中读取来得快,这会导致使用这些数据的应用程序响应变慢。所以,对 Redis 来说,实现数据的持久化,避免从后端数据库中进行恢复,是至关重要的。Redis 数据持久化的方式有两种,见表 8.8。
表8.8Redis持久化方式
| 项目 | RDB内存快照(Redis Data Base) | AOF日志(Append Only File) |
| 说明 | 把当前内存中的数据集快照写入磁盘(数据库中所有键值对数据)、恢复时是将快照文件直接读到内存里 | 通过持续不断地保存Redis服务器所执行的更新命令来记录数据库状态,类似MySQL的binlog日志。恢复数据时需要从头开始回放更新命令 |
| 磁盘刷新频率 | 低 | 高 |
| 文件大小 | 小 | 大 |
| 数据恢复效率 | 高 | 低 |
| 数据安全 | 低 | 高 |
- 缓存异常问题
Redis 在提高数据查询效率与保护数据库方面都起到了至关重要的作用,但是在实际应用中可能会出现 Redis 异常的情况,这里总结了一些常见的异常问题与对应的解决方案。 (1)缓存穿透。大量请求访问了没有缓存的key,即大量的key在Redis里是不存在的,从而导致请求直接访问数据库,数据库压力增大。可能的原因如下:
1)恶意攻击,造成大量访问不存在的key。例如登录时使用无效的用户名,在软考网站查询成绩时输入不存在的身份证号、准考证号。 解决方案: ① 针对比较少的请求来源IP,主动限制其访问次数,或者拉入黑名单; ② 应用程序来检查key的合法性,提前拒绝不合法的请求; ③ 使用布隆过滤器。布隆过滤器缺点:1.有一定的误判率,即存在假阳性,不能准确判断元素是否在集合中! 2.一般情况下不能从布隆过滤器中删除元素。
2)大量请求访问数据库里有但Redis没有的key。例如新业务刚刚上线,此时Redis是空的。
解决方案:
① 预热Redis,运行一个批处理脚本,将可能会大量访问的数据预先加载到Redis,业务再“开张”;
② 在最前端进行流量控制,逐步把请求释放进来。给出一段时间,让Redis逐步加载热数据;
③ 如果是在数据库里也没有的key,也需要在Redis中设置key,使其值为null或空。
(2)缓存雪崩。大量请求访问到缓存中过期的key,这些key是存在的,但同时到了过期时间,从而导致请求直接访问数据库,数据库压力增大。缓存雪崩可能进而影响一系列的雪崩,影响到上下游的所有应用服务。可能的原因如下:
1)Redis故障。比如Redis宕机,网络出现抖动等。 解决方案: ① 使用主从复制提高可用性,使用cluster集群方案降低故障时影响的范围; ② 如果出现故障,则可以采取服务降级、熔断、限流等措施。 2)大量的key采用了相同的过期时间。例如在同一时刻设置了大量的key,但过期时间都是5分钟。 解决方案: ① 过期时间加上一个随机值,使得众多key均匀过期。
(3)缓存击穿。少量热点的key缓存时间失效了,使得请求直接访问数据库。 可能的原因:热点的key设置了太短的过期时间。例如秒杀业务下的“库存数量”。 解决方案: ① 将key设置较长的过期时间。对于非常重要的key,则设置永久有效。但需要解决好与数据库中的key的一致性问题; ② 使用分布式锁。如果热点key失效了,要控制好访问后端数据库的流量。只允许一个请求去访问数据库,取出最新的key,存放到Redis,其他请求则必须
等待。但分布式锁也要防止出现异常的情况。
- 分布式锁
分布式锁的核心目标是确保多个节点在访问共享资源时的互斥性。Redis分布式锁通过设置过期时间来避免死锁问题,同时利用NX特性保证锁的唯一性。
- Redis 集群
Redis 也可以采用集群的方式部署,主要有主从复制集群、哨兵集群、Cluster 集群方式。 集群切片的方式主要分为客户端分片、代理分片、服务器端分片三种方式。
| 部署方式 | 核心机制 | 特点 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|
| 主从复制集群(Master-Slave) | 一个主节点负责写操作,从节点复制主节点数据 | 读写分离,提高读性能 | 架构简单,易于部署;可提升读性能 | 主节点宕机会导致写不可用 | 读多写少的场景 |
| 哨兵集群(Sentinel) | 通过哨兵监控主从节点状态并自动故障转移 | 管理主从复制结构,实现高可用 | 自动检测主节点故障并切换 | 无法自动分片;数据量大时扩展困难 | 需要高可用但数据量较小的系统 |
| Cluster 集群(原生分片集群) | 数据按 16384 槽(slot) 自动分布到多个节点 | Redis 官方原生分布式方案 | 水平扩展性强;支持自动故障转移 | 部署复杂;不支持多键跨槽事务 | 大规模数据与高并发访问场景 |
| 切片方式 | 分片位置 | 实现方式 | 优点 | 缺点 | 代表方案 / 案例 |
|---|---|---|---|---|---|
| 客户端分片 | 客户端 | 客户端自行根据哈希规则决定 key 属于哪个节点 | 简单灵活;无额外中间层 | 客户端需维护路由逻辑,扩容需修改客户端 | Jedis、Lettuce 手动分片 |
| 代理分片 | 代理层 | 使用代理服务器转发请求到对应节点 | 客户端无感知;便于扩容 | 增加一层代理,性能略受影响 | Twemproxy、Codis |
| 服务器端分片 | Redis 服务器 | Redis Cluster 内部根据 slot 自动分片 | 官方支持;自动化程度高 | 部署复杂,需集群管理 | Redis Cluster(官方方案) |
8.9 数据挖掘技术
数据挖掘中的关键技术是进行模式和关系识别的算法。下面介绍几种数据挖掘和知识发现的技术,它们分别从不同 的角度进行数据挖掘和知识发现。 (1)决策树方法。决策树方法利用信息论中的互信息(信息增益)寻找数据库中具有最大信息量的属性,建立决策树的一个结点,再根据属性的不同取值建立树的分支。 (2)分类方法。分类方法将数据按照含义划分成组,可用该方法生成感兴趣的侧面,可用于自动发现类,例如 模式识别、侧面生成、线性聚簇和概念聚簇等。 (3)概念树方法。对数据库中记录的属性按归类方式进行抽象,建立起来的层次结构称为概念树。例如,某在线教育平台系统中的“课程”概念树的最下层是具体课程名称(例如,数据结构、系统分析与设计等),它的直接上层是课程类别(例如,软件类、网络类等),课程类别的直接上层是专业类别(例如,计算机科学与技术、通信工程等),利用概念树提升的方法可以大大浓缩数据库中的记录。对多个性的概念树进行提升,将得到高度概括的知 识基表,然后再将它转换成规则。故答案为B。 (4)依赖性分析。依赖性分析是指在数据仓库的条目或对象之间抽取依赖性,它展示了数据之间未知的依赖关系,依赖性是一个带有置信度因子的可能值。可以用依赖性分析方法从某个数据对象的信息来推断另一个数据对象的信息。
8.10 嵌入式数据库
按照数据库存储位置的不同而进行分类是目前广泛采用的分类方法,它可以划分为基于内存方式、基于文件方式和基于网络方式三类。 (1)基于内存的数据库系统(Main Memory Database System,MMDB)是实时系统和数据库系统的有机结合。实时事务要求系统能较准确地预测事务的运行时间,但对磁盘数据库而言,由于磁盘存取、内外存数据传递、缓冲区管理、排队等待及锁的延迟等,使得事务实际平均执行时间与估算的最坏情况执行时间相差很大。如果将整个数据库或其主要的"工作"部分放入内存,使每个事务在执行过程中不需要访问I0 的话,则系统就可以较精确地估算和安排事务的处理时间,这样,为系统可动态预测性提供了有力的支持,同时也为实现事务的定时限制打下基础。 (2)基于文件的数据库(File Database,FDB)系统就是以文件方式存储数据库数据,即数据按照一定格式储存在磁盘中。使用时由应用程序通过相应的驱动程序甚至直接对数据文件进行读写。这种数据库的访问方式是被动式的,只要了解其文件格式,任何程序都可以直接读取,因此它的安全性很低。 (3)基于网络的数据库(Netware Database,NDB)系统是基于手机4G15G的移动通信基础之上的数据库系统,在逻辑上可以把嵌入式设备看作远程服务器的一个客户端。实际上,嵌入式网络数据库是把功能强大的远程数据库映射到本地数据库,使嵌入式设备访问远程数据库就像访问本地数据库一样方便。嵌入式网络数据库主要由三部分组成:客户端、通信协议和远程服务器。客户端主要负责提供接口给嵌入式程序,通信协议负责规范客户端与远程服务器之间的通信,还需要解决多客户端的并发问题,远程服务器负责维护服务器上的数据库数据。
8.11 练习题
- 数据库系统与文件系统的区别不包括(
A. 对应用程序的高度独立性 B. 数据的充分共享性 C. 文件组织形式的多样化 D. 操作方便性
解析:数据库对数据的存储是按照同一种数据结构进行的,不同的应用程序都可以直接操作这些数据(即对应用程序的高度独立性)。数据库系统对数据的完整性、一致性和安全性都提供了一套有效的管理手段(数据的充分共享性)。数据库系统还提供管理和控制数据的各种简单操作命令,容易掌握,使用户编写程序简单(即操作方便性)。
答案:C
- ()描述的是DBMS向用户提供数据操纵语言,实现对数据库中数据的基本操作,如检索、插入、修改和删除。
A. 数据定义 B. 数据库操作 C. 数据库运行管理 D. 数据组织、存储与管理
解析:DBMS功能主要包括数据定义、数据库操作、数据库运行管理、数据组织、存储与管理、数据库的建立和维护。其中数据库操作是DBMS向用户提供数据操纵语言,实现对数据库中数据的基本操作,如检索、插入、修改和删除。
答案:B
- 给定关系模式R(U,F),其中:属性集 $\mathrm{U} = {\mathrm{A}1,\mathrm{A}2,\mathrm{A}3,\mathrm{A}4,\mathrm{A}5,\mathrm{A}6}$ ;函数依赖集 $\mathrm{F} = {\mathrm{A}1\rightarrow \mathrm{A}2$ $\mathrm{Al}\rightarrow \mathrm{A}3$ , $\mathrm{A}3\rightarrow \mathrm{A}4$ , $\mathrm{A}1\mathrm{A}5\rightarrow \mathrm{A}6}$ 。关系模式R的候选码为(1),由于R存在非主属性对码的部分函数依赖,所以R属于(2)。
(1)A.A1A3 B.A1A4 C.A1A5 D.A1A6 (2)A.1NF B.2NF C.3NF D.BCNF
解析:判断候选码有一种比较快速的方式,就是看哪个属性只在依赖集F中“ $\twoheadrightarrow$ ”的左边出现过,那么该关系的候选码就必定包含那个属性。很显然选项C中A1和A5都是满足要求的,所以题干给定关系模式的候选码就是A1A5。对于空(2),“R存在非主属性对码的部分函数依赖”说明不满足2NF的要求,那么该关系模式只能是1NF。
答案:CA
- 某互联网文化发展公司因业务发展,需要建立网上社区平台,为用户提供一个对网络文化产品(如互联网小说、电影、漫画等)进行评论、交流的平台。该平台的部分功能如下:
(a)用户帖子的评论计数器;(b)支持粉丝列表功能;(c)支持标签管理;(d)支持共同好友功能等;(e)提供排名功能,如当天最热前10名帖子排名、热搜榜前5排名等;(f)用户信息的结构化存储;(g)提供好友信息的发布/订阅功能。
该系统在性能上需要考虑高性能、高并发,以支持大量用户的同时访问。开发团队经过综合考虑,在数据管理上决定采用Redis+数据库(缓存+数据库)的解决方案。
【问题】Redis支持丰富的数据类型,并能够提供一些常见功能需求的解决方案。请选择题干描述的(a)~(g)功能选项,填入表8.9中(1)~(5)的空白处。
表8.9Redis数据类型与业务功能对照表
| 数据类型 | 存储的值 | 可实现的业务功能 |
| string | 字符串、整数或浮点数 | (1) |
| list | 列表 | (2) |
| set | 无序集合 | (3) |
| hash | 包括键值对的无序散列表 | (4) |
| zset | 有序集合 | (5) |
解析:Redis支持的数据类型主要包括string类型、hash类型、set类型、list类型、zset类型。
(1)string类型:是Redis基本类型。可用于缓存层或计数器,如视频播放量、文章浏览量等。(2)hash类型:代替string类型,节省空间。描述用户信息较为方便。(3)set类型:无序集合,每个值不能重复。可用于去重、抽奖、初始化用户池等。(4)list类型:双向链表结构,可以模拟栈、队列等形式。可用于回复评论、点赞。(5)zset类型:有序集合、每个元素有一个分数。如首页推荐10个最热门的帖子。
答案:
(1)(a) (2)(b)(g) (3)(c)(d) (4)(f) (5)(e)
- 引入Redis后,热点数据存放在Redis中,但由于存在“一份数据存放了多个位置”,所以要考虑数据的一致性问题。读写数据的基本步骤是什么?
答案:读写数据的基本步骤为:
(1)读数据: $①$ 根据key读缓存; $(2)$ 读取成功则直接返回; $(3)$ 若key不在缓存中,则根据key读数据库; $(4)$ 读取成功后,写缓存; $(5)$ 成功返回。
(2)写数据: $①$ 根据key值写数据库; $(2)$ 成功后更新缓存key值; $(3)$ 成功返回。
第3篇 架构设计高级知识
第9小时 系统架构设计基础知识
9.0 章节考点分析
第9小时主要学习软件架构的基本概念、基于架构的软件开发方法、软件架构风格、软件架构复用以及特定领域软件体系结构等内容。本小时内容侧重于概念知识,考查的知识点来源于教材。根据考试大纲,本小时知识点会涉及单项选择题(约占 $8\sim 15$ 分)和下午案例题(25分),论文也会有涉及。本小时知识架构如图9.1所示。
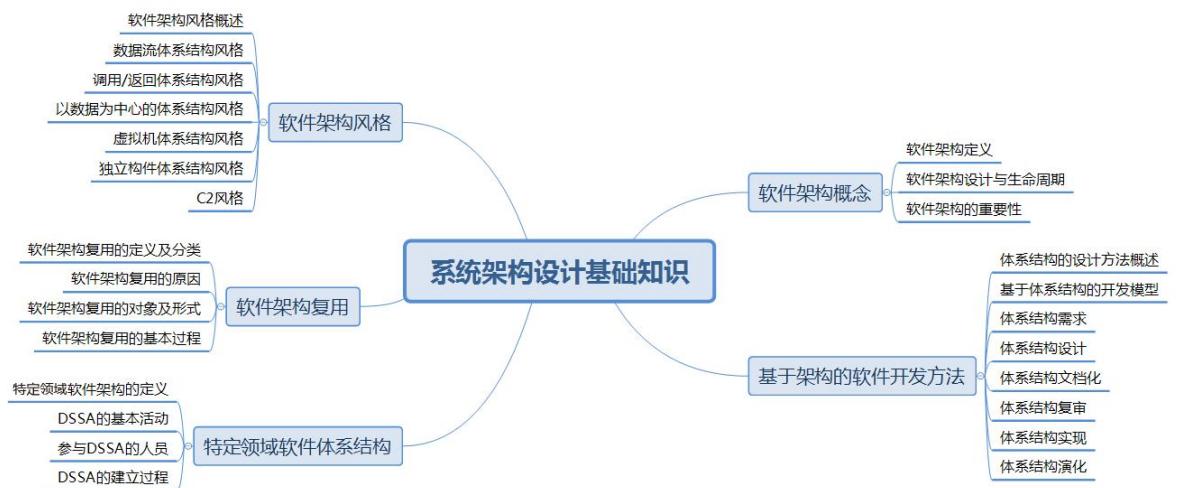
图9.1 本小时知识架构
【导读小贴士】
软件架构设计是降低成本、改进质量、按时和按需交付产品的关键因。体系架构的方法和步骤作为系统架构设计师考试最基本、最核心的方法论,需要重点理解并掌握。很多案例分析题也都来自本小时内容。
9.1 软件架构概念(SA、4+1模型、ADL)
【基础知识点】
- 软件架构定义
软件架构(Software Architecture)或称软件体系结构,是指系统的一个或者多个结构,这些结构包括软件的构件(可能是程序模块、类或者是中间件)、构件的外部可见属性及其之间的相互关系。体系结构的设计包括数据库设计和软件结构设计,后者主要关注软件构件的结构、属性和交互作用,并通过多种视图全面描述。
软件系统架构是关于软件系统的结构、行为和属性的高级抽象。在描述阶段,主要描述直接构成系统的抽象组件以及各个组件之间的连接规则,特别是相对细致地描述组件的交互关系。在实现阶段,这些抽象组件被细化为实际的组件,比如具体类或者对象。软件系统架构不仅指定了软件系统的组织和拓扑结构,而且显示了系统需求和组件之间的对应关系,包括设计决策的基本方法和基本原理。
数据作为资产需要具有以下特性:可控制、可量化、可变现。所以数据资产一般具备虚拟性、共享性、时效性、安全性、交换性和规模性。
从本质上看,需求和软件架构设计面临的是不同的对象:一个是问题空间;另一个是解空间。保持两者的可追踪性和转换,一直是软件工程领域追求的目标。从软件需求模型向SA模型的转换主要关注两个问题: 1)如何根据需求模型构建软件架构模型; 2)如何保证模型转换的可追踪性。
当考虑架构时,重要的是从不同的视角(perspective) 来检查,这促使设计师考虑具体架构的不同属性。例如: 1)展示功能组织的静态视角能判断质量特性, 2)展示并发行为的动态视角能判断系统行为特性。
软件体系结构风格 描述某一特定应用领域中系统组织方式的惯用模式。体系结构风格定义一个系统家族,即一个体系结构定义一个词汇表和一组约束。词汇表中包含一些构件和连接件类型,而这组约束指出系统是如何将这些构件和连接件组合起来的。体系结构风格反映了领域中众多系统所共有的结构和语义特性,并指导如何将各个模块和子系统有效地组织成一个完整的系统,对软件体系结构风格的研究和实践促进对设计的重用,一些经过实践证实的解决方案也可以可靠地用于解决新的问题。
架构模式、设计模式和惯用法 1)架构模式是软件设计中的高层决策,例如CS结构就属于架构模式,架构模式反映了开发软件系统过程中所作的基本设计决策; 2)设计模式主要关注软件系统的设计,与具体的实现语言无关; 3)惯用法则是实现时通过某种特定的程序设计语言来描述构件与构件之间的关系,例如引用-计数就是C++语言中的一种惯用法。
在ANSI/IEEE 1471-2000标准中,系统是为了达成利益相关人(Stakeholder)的某些使命(Mission),在特定环境(Enviroment)中构建的。每一个系统都有一个架构(Architecture)。架构(Architecture)是对所有利益相关人的关注点(Concem)的响应和回答,通过架构描述(Architecture Description)来说明。每一个利益相关人都有各自的关注点。这些关注点是指对其重要的,与系统的开发、运营或其他方面相关的利益。架构描述(Architecture Description)本质上是多视图的。每一个视图(View)是从一个特定的视角(Viewpoint)来表述架构的某一个独立的方面。试图用一个单一的视图来夏盖所有的关注点当然是最好的,但实际上这种表述方式将很难理解。视角(Viewpoint)的选择,基于要解决哪些利益相关人的哪些关注点。它决定了用来创建视图的语言、符号和模型等,以及任何与创建视图相关的建模方法或者分析技术。一个视图(View)包括一个或者多个架构模型(Model),一个模型也可能参与多个视图。模型较文本的表述的好处在于,可以更容易的可视化、检查、分析、管理和集成。
- 软件架构设计与生命周期
软件架构设计是软件开发过程中的一个重要环节,它涉及多个活动,旨在确保软件系统的结构、行为和属性满足既定的需求和目标。 软件架构设计主要关注软件组件的结构、属性和交互作用。结构指的是组件之间的组织方式,属性定义了组件的特性和行为,而交互作用则是指组件之间如何相互作用以完成系统的整体功能。 软件架构设计通过多种视图来全面描述特定系统的架构。视图是从不同角度或层面展示系统架构的一种方式,有助于不同背景的人员理解和交流系统架构。每种视图都提供了系统架构的不同方面的信息,共同构成了对系统架构的全面描述。 软件架构是贯穿整个生命周期的,不同阶段的作用和意义不同,各阶段架构工作见表9.1。
表9.1 各阶段架构工作一览表
| 阶段 | 作用和意义 |
| 需求分析阶段 | 有利于各阶段参与者的交流,也易于维护各阶段的可追踪性,主要关注问题域 |
| 设计阶段 | 关注的最早和最多的阶段 |
| 实现阶段 | 有效实现从软件架构设计向实现的转换 |
| 构件组装阶段 | 可复用构件组装的设计能够提高系统实现的效率 |
| 部署阶段 | 组织和展示部署阶段的软硬件架构、评估分析部署方案 |
| 后开发阶段 | 主要围绕维护、演化、复用进行 |
(1)需求分析阶段。需求分析阶段软件架构研究还处于起步阶段。需求关注的是问题空间,架构关注的是解空间,需要保持二者的可追踪性和转换。从软件需求模型向软件架构模型的转换主要关注两个问题:
1)如何根据需求模型构建软件架构模型 2)如何保证模型转换的可追踪性
(2)设计阶段。这一阶段的研究主要包括:软件架构模型的描述、软件架构模型的设计与分析方法,以及对软件架构设计经验的总结与复用等。其中架构模型的描述研究包括:
1)组成SA模型(软件架构模型) 的基本概念。即构件和连接子的建模。 2)体系架构描述语言(Architecture Describe Language,ADL)。是用于描述软件体系架构的语言,包括组件、组件连接口、连接件和架构配置,与其他建模语言最大的区别在于其更关注构件间互联机制(连接子),典型的ADL语言包括Unicon、Rapide、Darwin、Wright、C2SADL、Acme、XADLOL、XYZ/ADL和ABC/ADL等。
ADL三要素: ①构件:计算或数据存储单元。 ②连接件:用于构件之间交互建模的体系结构构造块及其支配这些交互的 ③规则架构配置:描述体系结构的构件与连接件的连接图。
常见的架构描述语言包括: C2SADL【基于组件和消息的软件架构描述语言】 Wright【分布、并发类型的架构描述语言】 ACME 【架构互换语言】 UniCon【基于组件和连接的架构描述语言】 Rapide【基于事件的架构描述语言】 其他【Darwin、MetaH、Aesop、Weaves、SADL、xADL】
3)多视图。反映的是一组系统的不同方面,体现了关注点分散的思想,通常与ADL结合起来描述系统的体系结构。典型的模型包括:4+1模型、Hofmesiter的4视图模型、CMU-Sei的Views and Beyond模型。视图标准包括:IEEE的I471-2000、RM-ODP、UML以及IBM的Zachman。
①4+1模型是描述软件体系结构的常用模型,“4+1"视图模型从逻辑视图、进程视图、物理视图、开发视图和场景来描述软件架构。每个视图只关心系统的一个侧面,结合在一起才能反映系统软件架构的全部内容。在该模型中,“1”指的是统一场景。
| 视图 | 关注点 | 关键词 | 常见 UML 图类型 | 典型使用场景 / 角色 |
|---|---|---|---|---|
| 逻辑视图(Logical View) | 功能需求,面向用户和设计人员,关注系统功能如何划分模块。设计元素的功能和概念接口。从系统的静态结构和动态行为角度显示系统内部如何实现系统的功能。用来描述设计的对象模型和对象之间的关系 | 模块划分、对象模型、功能接口、静态结构、动态行为 | 类图、对象图、包图、状态图、活动图 | 系统分析师、架构师、设计人员,用于理解业务逻辑和对象关系 |
| 开发视图(Development View / Implementation View) | 又叫实现视图,软件的静态组织结构,面向程序员,关注包、组件、子系统。 显示的是源代码以及实际执行代码的组织结构。软件模块的组织与管理 | 包、组件、子系统、源代码结构、模块管理 | 组件图、包图 | 开发人员、架构师,用于组织代码结构、模块划分 |
| 过程视图(Process View) | 动态并发性,面向系统集成人员,关注进程、线程、通信机制。 显示程序执行时并发的状态。 | 进程、线程、并发、通信机制、运行时状态 | 活动图、时序图、通信图、状态图 | 系统集成人员、性能工程师,用于并发控制、系统优化 |
| 物理视图(Physical View / Deployment View) | 又叫部署视图,系统的物理部署,面向运维人员,关注节点、硬件、网络拓扑。 | 节点、硬件、网络拓扑、部署结构 | 部署图、组件图、网络拓扑图 | 运维人员、系统工程师,用于部署和环境规划 |
| +1 场景视图(Use Case / Scenario) | 用例或场景,帮助把以上 4 个视图结合起来,验证架构。显示外部参与者观察到的系统功能。 | 用例、场景、外部参与者、需求验证、交互 | 用例图、时序图、活动图 | 客户、用户、业务分析师、测试人员,用于需求确认和验证 |
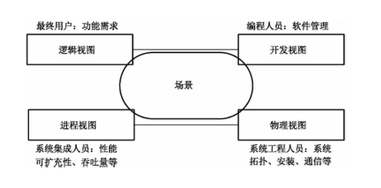
(3)实现阶段。这一阶段的体系结构研究的内容有:
1)基于SA的开发过程支持。 2)寻求从SA向实现过渡的途径。 3)研究基于SA的测试技术。
缩小软件架构设计与底层实现概念差距的手段:模型转换技术、封装底层的实现细节、在SA模型中引入实现阶段的概念(如用程序设计语言描述)。
(4)构件组装阶段。分为定制、集成和扩展三个层次,研究的内容包括: 1)如何支持可复用构件的互联,即对SA设计模型中规约的连接子的实现提供支持。 2)组装过程中,如何检测并消除体系结构失配问题。这些问题主要包括:①构件本身的失配;②连接子(互联机制)的失配;③部分和整体的失配。
(5)部署阶段。部署阶段的软件架构对软件部署的作用:一是提供高层的体系结构视图描述部署阶段的软硬件模型;二是基于软件架构模型可以分析部署方案的质量属性,从而选择合理的部署方案。
(6)后开发阶段。部署安装后(后开发阶段)的系统架构研究方向包括:动态软件体系结构、体系结构恢复与重建。体系结构重建的方法有:手工体系结构重建、工具支持的手工重建、通过查询语言来自动建立聚集、使用其他技术(如数据挖掘)。
- 软件架构的重要性
软件架构设计是降低成本、改进质量、按时和按需交付产品的关键因素。软件架构的重要性包括:
(1)架构设计能够满足系统的品质。(2)架构设计使受益人达成一致的目标。(3)架构设计能够支持计划编制过程。(4)架构设计对系统开发的指导性。(5)架构设计能够有效地管理复杂性。(6)架构设计为复用奠定了基础。(7)架构设计能够降低维护费用。(8)架构设计能够支持冲突分析。
9.2 基于架构的软件开发方法(ABSD)
【基础知识点】
- 体系结构的设计方法概述
基于体系结构(架构)的软件设计(Architecture- Based Software Design,ABSD)方法是体系结构驱动的,即指构成体系结构的商业、质量和功能需求的组合驱动的。 在基于体系结构的软件设计方法中: 1)采用视角与视图来描述软件架构, 2)采用用例来描述功能需求, 3)采用质量场景来描述质量需求。
ABSD方法具有三个基础: 1)功能分解,在功能分解中使用已有的基于模块的内聚和耦合技术。 2)通过选择体系结构风格来实现质量和商业需求。 3)软件模板的使用。
在ABSD(基于架构的软件设计)方法中,使用不同的视角来观察设计元素,一个子系统并不总是一个静态的架构元素,而是可以从动态和静态视角观察的架构元素。将选择的特定视角或视图与Kruchten提出的类似,也就是逻辑视图、进程视图、实现视图和配置视图。 1)使用逻辑视图来记录设计元素的功能和概念接口,设计元素的功能定义了它本身在系统中的角色,这些角色包括功能性能等。 2)进程视图也称为并发视图,使用并发视图来检查系统多用户的并发行为。使用“并发“来代替“进程”,是为了强调没有对进程或线程进行任何操作,一旦执行这些操作,则并发视图就演化为进程视图。 3)使用的最后一个视图是配置视图,配置视图代表了计算机网络中的节点,也就是系统的物理结构。
架构设计是一个选代过程,在建立软件架构的初期,选择一个合适的架构风格是首要的,在此基础上,开发人员通过架构模型,可以获得关于软件架构属性的理解,为将来的架构实现与演化过程建立了目标。
ABSD是自顶向下、递归细化的。软件系统的体系结构通过该方法得到细化,直到能产生软件构件和类。它以软件系统功能的分解为基础,通过选择架构风格实现质量和商业需求,并强调在架构设计过程中使用软件架构模板。迭代的每一步都有清晰的定义,有助于降低体系结构设计的随意性。
- 基于体系结构的开发模型(Architecture-Based Software Design Model,ABSDM)
传统的软件开发模型开发效率较低,ABSDM模型把整个基于体系结构的软件开发过程划分为体系结构需求、设计、文档化、复审、实现和演化六个子过程。
(1) 体系结构需求:软件架构需求是指用户对目标软件系统在功能、行为、性能和设计约束等方面的期望。 1)需求获取。体系结构需求的获取一般来自三个方面:质量目标、系统的商业目标和系统开发人员的商业目标。 2)标识构件。标识构件分三步完成:生成类图、对类进行分组、把类打包成构件。 3)架构需求评审的审查重点包括需求是否真实反映了用户的要求、类的分组是否合理、构件合并是否合理等。 (2) 体系结构设计:软件的体系设计过程:提出软件体系结构模型$\twoheadrightarrow$映射构件$\twoheadrightarrow$分析构件相互作用$\twoheadrightarrow$产生体系结构设计评审。设计评审必须邀请独立于系统开发的外部人员。 (3) 体系结构文档化:体系结构文档化过程的主要输出结果是体系结构规格说明和测试体系结构需求的质量设计说明书。 (4) 体系结构复审:一个主版本的软件体系结构分析之后,要安排一次由外部人员(用户代表和领域专家)参加的复审。复审的目的是标识潜在的风险,及早发现体系结构设计中的缺陷和错误,必要时,可搭建一个可运行的最小化系统用于评估和测试体系结构是否满足需要。 (5) 体系结构实现:体系结构的实现过程是以复审后的文档化体系结构说明书为基础的,具体为:分析与设计$\twoheadrightarrow$构件实现$\twoheadrightarrow$构件组装$\twoheadrightarrow$系统测试。体系结构说明书中定义了系统中构件与构件之间的关系。测试包括单个构件的功能性测试及被组装应用的整体功能和性能测试。 (6) 体系结构演化:体系结构演化使用系统演化步骤去修改应用,以满足新的需求。系统演化步骤为:需求变化归类$\twoheadrightarrow$体系结构演化计划$\twoheadrightarrow$构件变动$\twoheadrightarrow$更新构件的相互作用$\twoheadrightarrow$构件组装与测试$\twoheadrightarrow$技术评审$\twoheadrightarrow$演化后的体系结构。
当考虑架构时,重要的是从不同的视角(perspective)来检查,这促使设计师考虑具体架构的不同属性。例如:展示功能组织的静态视角能判断质量特性,展示并发行为的动态视角能判断系统行为特性。在ABSD(基于架构的软件设计)方法中,使用不同的视角来观察设计元素,一个子系统并不总是一个静态的架构元素,而是可以从动态和静态视角观察的架构元素。将选择的特定视角或视图与Kruchten提出的类似,也就是逻辑视图、进程视图、实现视图和配置视图。使用逻辑视图来记录设计元素的功能和概念接口,设计元素的功能定义了它本身在系统中的角色,这些角色包括功能性能等。进程视图也称为并发视图,使用并发视图来检查系统多用户的并发行为。使用“并发"来代替"进程”,是为了强调没有对进程或线程进行任何操作,一旦执行这些操作,则并发视图就演化为进程视图。使用的最后一个视图是配置视图,配置视图代表了计算机网络中的节点,也就是系统的物理结构。
9.3 软件架构风格(黑板)
【基础知识点】
- 软件架构风格概述
软件体系结构设计的核心目标是重复的体系结构模式(软件复用/重用)。软件体系结构(架构)风格是描述某一特定应用领域中系统组织方式的惯用模式。体系结构风格定义一个系统家族,即一个体系结构定义一个词汇表和一组约束。
(1)词汇表:包含构件和连接件。 (2)约束:约束定义构件和连接件的组合方式。
体系结构风格反映了领域中众多系统所共有的结构和语义特性,并指导如何将各个模块和子系统有效地组织成一个完整的系统。
1)数据流:强调数据顺序流动(批处理、管道)。 2)调用/返回:强调“分而治之”(主程序、对象、层次、C/S、B/S)。 3)数据中心:强调“中心仓库”(仓库、黑板)。 4)虚拟机:强调“虚拟环境/解释”(解释器、规则系统)。 5)独立构件:强调“解耦 & 消息传递”(进程、事件)。 6)C2:极致解耦 → 组件通过连接件通信。
| 类别 | 子风格 | 核心思想 / 特点 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|
| 数据流体系结构 | 批处理 | 独立程序顺序执行;必须完整数据整体传递;前一步结束才能进行下一步 | 结构清晰,适合离线处理、可并发处理 | 实时性差,灵活性不足 | 离线数据处理、大数据批处理 |
| 管道-过滤器 | 数据流经多个处理步骤;每步输入/输出独立;输出是下步输入;过滤器可并行 | 模块独立、易扩展、可复用 | 数据传递开销大,实时性差 | 数据流处理、ETL流程 | |
| 调用/返回体系结构 | 主程序/子程序 | 单线程控制;分解为子程序 | 简单直观,降低复杂度 | 可扩展性差 | 小规模程序或脚本 |
| 面向对象 | 构件是对象(抽象数据类型实例) | 封装性强、可复用 | 对象间通信开销大 | 面向对象软件系统 | |
| 层次型 | 分层,每层服务于上层,只与相邻层交互 | 降低复杂度、分层清晰、易维护 | 依赖严格分层,跨层调用困难 | 企业软件、操作系统架构 | |
| 客户端/服务器C/S | 二层:客户端 + 数据库服务器; 三层:表示层、功能层、数据层 | 前后端分离,结构清晰 | 客户端复杂、开发成本高 | 网络应用、数据库应用 | |
| 浏览器/服务器B/S | 三层结构:浏览器 + Web服务器 + 数据库 | 维护方便、跨平台、升级简单 | 动态性和安全性较弱,性能瓶颈 | Web应用、跨平台服务 | |
| 显示调用 | 调用方显式指定被调用对象并直接执行(函数、方法调用) | 控制流清晰、性能高、易调试 | 模块耦合高、可扩展性差 | 单体应用、传统API调用 | |
| 隐式调用 | 组件通过事件广播或回调触发执行,而非直接调用 | 松耦合、灵活、支持异步 | 控制复杂、不易调试 | GUI事件系统、事件驱动架构 | |
| MVC架构 | 将系统分为模型(Model)、视图(View)、控制器(Controller) 三部分,分别处理数据逻辑、界面显示和交互控制。 | 模块分离、提高可维护性与可扩展性、前后端协作清晰 | 控制流程复杂,层间通信需谨慎 | Web应用、桌面应用、前后端分离系统 | |
| 以数据为中心体系结构 | 仓库 | 中央数据结构说明当前状态,独立构件在中央数据存储上执行 | 数据集中,统一管理 | 中心成为瓶颈,扩展性差 | 数据仓库、企业信息系统 |
| 黑板 | 知识源(数据处理和计算)、黑板(数据共享)、控制模块;信号/模式识别 | 适合复杂推理、知识集成 | 控制复杂,效率不高 | 专家系统、人工智能推理系统、语音识别 | |
| 虚拟机体系结构 | 解释器 | 构建虚拟机解析运行语言 | 灵活性高,跨平台 | 执行效率低 | 自定义强、跨平台应用、脚本语言 |
| 规则系统 | 知识库 + 规则解释器 + 规则/数据选择器 + 工作内存 | 易于规则扩展,适合专家系统 | 性能差,依赖规则设计 | 专家系统、规则驱动系统 | |
| 独立构件体系结构 | 进程通信 | 构件独立,通过消息传递通信 ,同步 | 解耦性强 | 通信开销大,调度复杂 | 分布式系统、微服务架构 |
| 事件系统 | 隐式调用;构件触发/广播事件而非直接调用 | 松耦合、灵活 | 控制复杂,不易调试 | GUI应用、异步事件系统 | |
| 微内核架构(Microkernel Architecture) | 将系统核心功能集中在微内核(核心服务) 中,扩展功能通过插件或模块方式接入,不影响核心运行。 | 核心稳定、易扩展、模块隔离良好 | 设计复杂,插件管理和通信需规范 | 操作系统、IDE、在线教育平台、可扩展企业系统 | |
| C2风格 | —— | 构件间无直接连接,靠连接件传递消息。通过连接件绑定在一起的按照一组规则运作的并行构件网络。 | 高度解耦,组件可替换 | 实现复杂,效率不高 | 高度模块化、插件式系统 |
| 过程控制风格 | 顺序控制 | 按严格的时间/顺序执行,流程驱动 | 结构清晰,易理解 | 缺乏灵活性,难以应对动态变化 | 嵌入式系统、工业流程控制 |
| 状态驱动 | 系统根据状态转移规则执行操作 | 控制逻辑明确,适合复杂控制 | 状态空间大时维护困难 | 操作系统内核、通信协议 | |
| 实时控制 | 任务按实时约束执行,响应外部环境变化 | 满足实时性需求 | 实现复杂,对硬件依赖强 | 实时系统、机器人控制 | |
| 闭环结构 | —— | 由几个协作构件共同构成,且其中的主要构件彼此分开,能够进行替换与重用 | 自适应能力强,适合动态环境 | 适用于处理简单任务(如机器装配等),并不适用于复杂任务 | 自动控制系统、控制工程、智能控制 |
| 分层结构 | —— | 通过引入抽象层,在较低层次不确定的实现细节在较高层次会变得确定,并能够组织层间构件的协作,系统结构更加清晰 | 降低复杂度、模块化清晰 | 跨层交互困难,灵活性不足 | 网络协议(如OSI模型)、大型软件架构 |
| 事件驱动体系结构 | 事件广播模型 | 事件由发布者广播,多个订阅者异步接收并处理(发布/订阅) | 松耦合、扩展性强、支持异步 | 调试复杂,事件顺序难保证 | 消息队列系统、日志系统、实时监控 |
| 事件通道模型 | 使用事件通道传递事件,事件生产者和消费者解耦 | 解耦性强,支持高并发 | 需要可靠的中间件支持 | 微服务架构、分布式系统 | |
| 事件驱动工作流 | 基于事件触发的任务调度,动态执行工作流 | 灵活、动态适应变化 | 设计复杂,依赖事件管理器 | IoT系统、金融风控、供应链系统 | |
| 中间件体系结构 | RPC中间件 | 模拟本地调用的远程通信,面向过程,性能高 | 性能好,实现直接 | 耦合高、灵活性差 | 分布式服务、传统后端系统 |
| 分布式对象中间件 | 对象远程调用,支持多语言互操作(如CORBA) | 跨平台、面向对象 | 复杂、部署难 | 异构分布式系统 | |
| 消息中间件 | 异步通信、松耦合,基于队列或发布订阅模型 | 解耦强、可靠传输 | 延迟、调试复杂 | MQ系统、微服务通信 | |
| 事务中间件 | 管理跨系统事务一致性 | 一致性强 | 性能损耗大 | 金融、电商系统 | |
| 进程通信结构体系结构 | 消息传递模型 | 系统由多个独立进程组成,通过消息(Message) 交换数据与指令,可采用同步或异步通信。构件是独立的过程,连接件是消息传递 | 支持并发、分布式计算,解耦性高 | 通信开销大、同步复杂 | 分布式系统、微服务架构、操作系统进程间通信 |
| 共享内存模型 | 多个进程通过共享内存区域进行数据交换,需协调同步与互斥。 | 通信速度快、效率高 | 同步控制复杂,易出现竞争条件 | 实时系统、高性能计算、嵌入式系统 | |
| 套接字通信模型 | 使用Socket接口在网络上传输数据,支持跨主机通信。 | 跨平台、通用性强、支持远程进程通信 | 通信延迟大,协议复杂 | 网络应用、客户端-服务器通信 | |
| 管道 / FIFO 模型 | 使用管道(Pipe)或命名管道(FIFO) 在进程间传输数据。 | 简单易用、操作系统支持广 | 只能单向通信,扩展性差 | UNIX/Linux系统进程通信、小型并发程序 | |
| 模型驱动体系结构(MDA) | 模型驱动架构(Model Driven Architecture) | 以模型为核心,通过模型之间的映射与转换(CIM(计算无关模型)→PIM(平台无关模型)→PSM(平台相关模型)→Code)实现平台无关的软件开发 | 平台无关、标准化强、可自动生成代码、可移植性高 | 转换工具链复杂,学习成本高 | 企业级应用开发、跨平台系统、模型驱动工程(MDE) |
- 数据流体系结构风格
(1)批处理体系结构风格:每个处理步骤是一个独立的程序,每一步必须在前一步结束后才能开始,且数据必须是完整,以整体的方式传递。 (2)管道和过滤器:把系统分为几个序贯地处理步骤,每个步骤之间通过数据流连接,一个步骤的输出是另一个步骤的输入,每个处理步骤都有输入和输出,如图9.3所示。
图9.3 管道和过滤器风格
- 调用/返回体系结构风格
调用-返回风格在系统中采用了调用与返回机制。利用调用-返回实际上是一种分而治之的策略,主要思想是将一个复杂的大系统分解为若干个子系统,降低复杂度,增加可修改性。
(1)主程序/子程序风格:采用单线程控制,把问题划分为若干处理步骤,构件即为主程序和子程序。 (2)面向对象体系结构风格:构件是对象,即抽象数据类型的实例,如图9.4所示。
图9.4 数据抽象和面向对象组
(3)层次型体系结构风格:每一层为上层服务,并作为下层的接口。仅相邻层间具有层接口,如图9.5所示。
图9.5 层次型体系结构风格
(4)客户端/服务器体系结构风格
1)二层C/S模式。主要组成部分:数据库服务器(后台:负责数据管理)、客户应用程序(前台:完成与用户交互任务)和网络。
优点:客户应用和服务器构件分别运行在不同的计算机上。 缺点:开发成本高,客户端设计复杂,信息内容和形式单一,不利于推广,软件移植困难,软件维护和升级困难。
关于服务端构件模型的典型解决方案包括: ①适用于应用服务器的EJB模型(Sun公司J2EE的一部分)和COM+模型(微软公司), ②以及适用于Web服务器的servlet模型(基于Sun公司JSP技术)和Visual Basic及其他微软的技术(基于微软公司ASP技术)。 ③NET框架还引入了一种新的同时适用于客户端和服务端的基于CL(Command LineInterface)的构件模型。
2)三层C/S模式:瘦客户端模式。应用该功能分为表示层、功能层和数据层。
①表示层:用户接口与应用逻辑层的交互,不影响业务逻辑,通常使用图形用户界面。 ②功能层:实现具体的业务处理逻辑。 ③数据层:数据库管理系统。
C/S系统开发时可以采用不同的分布式计算架构: 1)分布式表示架构是将表示层和表示逻辑层迁移到客户机,应用逻辑层、数据处理层和数据层仍保留在服务器上; 2)分布式数据架构是将数据层和数据处理层放置于服务器,应用逻辑层、表示逻辑层和表示层放置于客户机; 3)分布式数据和应用架构数据层和数据处理层放置在数据服务器上,应用逻辑层放置在应用服务器上,表示逻辑层和表示层放置在客户机。
| 架构类型 | 客户端承担内容 | 服务器承担内容 | 典型场景/类比 |
|---|---|---|---|
| 分布式表示架构 | 表示层、表示逻辑 | 1个服务器 应用逻辑、数据处理、数据存储 | 传统 B/S,浏览器展示,后端做逻辑 |
| 分布式数据架构 | 表示层、表示逻辑、应用逻辑 | 数据处理、数据存储 | 早期 C/S,客户端厚重软件 |
| 分布式数据和应用架构 | 表示层、表示逻辑 | 2个服务器 应用逻辑(应用服务器)、数据处理+存储(数据库服务器) | 现代 Web/三层架构系统 |
分布式系统开发分为五个逻辑计算层: 1)表示层实现用户界面; 2)表示逻辑层为了生成数据表示而必须进行的处理任务,如输入数据编辑等; 3)应用逻辑层包括为支持实际业务应用和规则所需的应用逻辑和处理过程,如信用检查、数据计算和分析等; 4)数据处理层包括存储和访问数据库中的数据所需的应用逻辑和命令,如查询语句和存储过程等; 5)数据层是数据库中实际存储的业务数据。
(5)浏览器/服务器风格(B/S)。
1)B/S风格:是三层应用结构的实现方式,其三层结构分别为:浏览器;Web服务器;数据库服务器。 2)相比于C/S的不足之处:动态页面的支持能力弱、系统拓展能力差、安全性难以控制、响应速度不足、数据交互性不强。
- 以数据为中心的体系结构风格
(1)仓库体系结构风格:存储和维护数据的中心场所。由中央数据结构(说明当前数据状态)和一组独立构件(对中央数据进行操作)组成,如图9.6所示。
图9.6 仓库体系结构风格
(2)黑板体系结构风格:是一种问题求解模型,是组织推理步骤、控制状态数据和问题求解之领域知识的概念框架。可通过选取各种黑板、知识源和控制模块的构件来设计,应用于信号处理领域,如语音识别和模式识别,如图9.7所示。
图9.7 黑板体系结构风格
- 虚拟机体系结构风格
虚拟机体系结构风格基本思想是人为构建一个运行环境,可以解析与运行自定义的一些语言,增加架构的灵活性。
(1)解释器体系结构风格:通常被用来建立一种虚拟机以弥合程序语义与硬件语义之间的差异,缺点是执行效率较低,典型例子是专家系统,如图9.8所示。
图9.8 解释器体系结构风格
(2)规则系统体系结构风格:包括知识库、规则解释器、规则/数据选择器及工作内存(程序运行存储区),如图9.9所示。
图9.9 规则系统体系结构风格
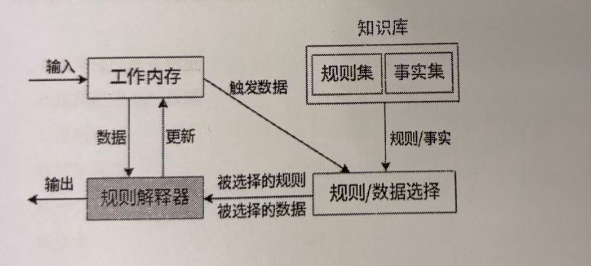
- 独立构件体系结构风格
独立构件体系结构风格强调系统中的每个构件都是相对独立的个体,它们之间不直接通信,以降低耦合度,提升灵活度。
(1)进程通信体系结构风格:构件是独立的过程,连接件是消息传递。
(2)事件系统体系结构风格:基于事件的隐式调用风格,构件不直接调用一个过程,而是触发或广播一个或多个事件(强调被动、触发)。
- C2风格
C2风格通过连接件连接构件或某个构件组,构件与构件之间无连接,如图9.10所示。
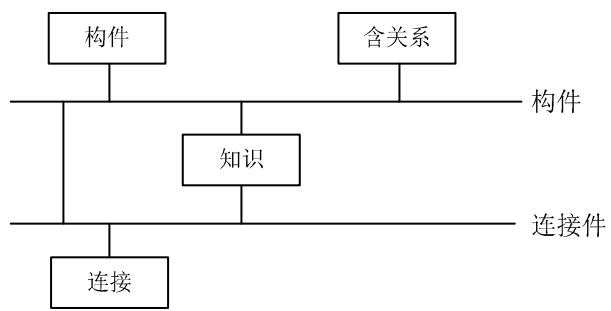
图9.10 C2风格
【练习】
(1)传统的编译器设计中,编译处理过程都以独立功能模块的形弍存在,程序源代码作为一个整体,依次在不同模块中进行传递,最终完成编译过程。针对这种设计思路,传统的编译器采用顺序批处理架构风格比较合适,因为在顺序批处理架构风格中,数据以整体的方式在不同的处理模块之间传递,符合题目要求。 (2)集成开发环境(IDE)需要面对不同的数据结构,不同的数据类型与形态,在这种以数据为核心的系统中,采用数据共享机制显然是最为合适的。 (3)IDE强调交互式编程,用户在修改程序代码后,会同时触发语法高亮显示、语法错误提示、程序结构更新等多种功能的调用与结果呈现,这一需求的核心在于根据事件进行动作响应,采用隐式调用的架构风格最为合适。 (4)公司需要对IDE进行适应性改造,支持采用现有编程语言进行编程,生成符合新操作系统要求的运行代码,并能够在现有操作系统上模拟出新操作系统的运行环境,以支持代码调试工作。针对上述要求,为了使IDE能够生成符合新操作系统要求的运行代码,应该是现有操作系统对新系统的一个适配过程,因此应该采用适配器架构设计策略比较合适 (5)模拟新操作系统的运行模式通常会采用虚拟机架构风格。 (6)编译器是跟管道过滤器和数据仓储这两种有关系。其中传统编译器采用的是管道过滤器,将文本形式的代码一步步的转化为各种形式,最终生成可执行代吗。现代编译器是以程序语法分析树为数据共享中心,然后围绕这个中心可以进行各种操作,比如编辑、语法高亮、代码编译、运行调试等等。,属于现代编译器,采用数据仓储(数据共享中心)。
在一个典型的基于MVC(Model View Controller)的J2EE应用中, 1)系统的界面由JSP构件实现, 2)分发客户请求有效组织其他构件为客户端提供服务的控件器由Servlet构件实现, 3)数据库相关操作由Entity Bean构件实现, 4)系统核心业务逻辑由Session Bean构件实现。
9.4 软件架构复用
【基础知识点】
(1)软件架构复用的定义及分类。软件复用是系统化的软件开发过程:开发一组基本的软件构件模块,以覆盖不同的需求/体系结构之间的相似性,提高系统开发的效率、质量和性能。软件架构复用的类型包括机会复用和系统复用。 机会复用是在开发过程中,只要发现有可复用的资产就复用。 系统复用是在开发前进行规划,决定哪些复用。 (2)软件架构复用的原因:减少开发工作、减少开发事件、降低开发成本、提高生产力、提高产品质量,更好的互操作性。 (3)软件架构复用的对象及形式。软件元素包括需求分析文档、设计过程、设计文档、程序代码、测试用例、领域知识等。一般形式的复用包括:函数的复用、库的复用、面向对象开发中的类、接口和包的复用。 (4)软件复用过程的主要阶段包括构造/获取可复用的软件资产、管理可复用资产、使用可复用资产。
架构重建 当前系统的开发很少是从头开始的,大量的软件开发任务是基于已有的遗产系统进行升级、增强或移植。这些系统在开发的时候没有考虑架构,在将这些系统进行构件化包装、复用的时候,会得不到体系结构的支持。因此,从这些系统中恢复或重构体系结构是有意义的,也是必要的。架构重建是指从已实现的系统中获取体系结构的过程。一般地,架构重建的输出是一组体系结构视图。现有的体系结构重建方法可以分为4类。 (1)手工体系结构重建。 (2)工具支持的手工重建。通过工具对手工重建提供辅助支持,包括获得基本体系结构单元、提供图形界面允许用户操作架构模型、支持分析架构模型等。如KLOCworkinSight工具使用代码分析算法直接从源代码获得架构构 件视图,用户可以通过操作图形化的架构来设定体系结构规则,并可在工具的支持下实现对体系结构的理解、自动控制和管理。 (3)通过查询语言来自动建立聚集。这类方法适用于较大规模的系统,基本思路是:在逆向工程工具的支持下分析程序源代码,然后将得到的体系结构信息存入数据库,并通过适当的查询语言得到有效的体系结构显示。 (4)使用其他技术,比如数据挖掘等。
9.5 特定领域软件体系结构(DSSA)
【基础知识点】
- 特定领域软件架构的定义
特定领域软件架构(Domain Specific Software Architecture,DSSA) 是在一个特定应用领域中为一组应用提供组织结构参考的标准软件体系结构,即用于某一类特定应用领域的标准软件构件集合。由领域参考模型、参考需求、参考架构等组成的开发基础架构,支持一个特定领域中多个应用的生成。DSSA的特征:领域性、普遍性、抽象性、可复用性。
从功能覆盖的范围角度理解DSSA中领域的含义有两种方法: (1)垂直域。定义了一个特定的系统族,导出在该领域中可作为系统的可行解决方案的一个通用软件架构。 (2)水平域。定义了在多个系统和多个系统族中功能区域的共有部分,在子系统级上涵盖多个系统(族)的特定部分功能。 在特定领域架构中,垂直域关注的是与行业相关的,聚焦于行业特性的内容,而水平域关注的是各行业共性部分的内容。
- DSSA的基本活动
DSSA的基本活动有领域分析、领域设计、领域实现 1)领域分析的主要目的是获得领域模型,领域模型描述领域中系统之间共同的需求,即领域需求; 2)领域设计的主要目标是获得DSSA,DSSA描述领域模型中表示需求的解决方案; 3)领域实现的主要目标是依据领域模型和DSSA开发和组织可重用信息,并对基础软件架构进行实现。
- 参与DSSA的人员
参与DSSA的人员有领域专家、领域分析师、领域设计人员和领域实现人员。其中 领域专家的主要任务是提供关于领域中系统的需求规约和实现的知识; 领域分析师的任务是控制整个领域分析过程,进行知识获取,将获取的知识组织到领域模型中; 领域设计者的任务是根据领域模型和现有系统开发出DSSA,并对DSSA的准确性和一致性进行验证。 领域实现人员主要任务包括根据领域模型和DSSA,或者从头开发可重用构件,或者利用再工程的技术从现有系统中提取可重用构件,对可重用构件进行验证,建立DSSA与可重用构件间的联系。领域实现人员应熟悉软件重用、领域实现及软件再工程技术;熟悉程序设计;具有一定的该领域的经验
- DSSA的建立过程
DSSA的建立过程是并发的、递归的、反复的螺旋模型
分为三个层次: 1)领域开发环境(领域架构师); 2)领域特定应用开发环境(应用工程师); 3)应用执行环境(操作员)
分为五个阶段: 因所在的领域不同,DSSA的创建和使用过程也各有差异,Tract曾提出一个通用的DSSA应用过程,这些过程也需要根据所应用到的领域来进行调整。DSSA的建立过程分为5个阶段,每个阶段可以进一步划分为一些步骤或子阶段。每个阶段包括一组需要回答的问题,一组需要的输入,一组将产生的输出和验证标准。本过程是并发的(Concurrent)、递归的(Recursive)、反复的(lterative)。或者可以说,它是螺旋模型(Spiral)。完成本过程可能需要对每个阶段经历几遍,每次增加更多的细节。 (1)定义领域范围。本阶段的重点是确定什么在感兴趣的领域中以及本过程到何时结束。这个阶段的一个主要输出是领域中的应用需要满足一系列用户的需求。 (2)定义领域特定的元素。本阶段的目标是编译领域字典和领域术语的同义词词典。在领域工程过程的前一个阶段产生的高层块圈将被增加更多的细节,特别是识别领域中应用间的共同性和差异性。 (3)定义领域特定的设计和实现需求约束。本阶段的目标是描述解空间中有差别的特性。不仅要识别出约束,并且要记录约束对设计和实现决定造成的后果,还要记录对处理这些问题时产生的所有问题的讨论。 (4)定义领域模型和体系结构。本阶段的目标是产生一般的体系结构,并说明构成它们的模块或构件的语法和语 (5)产生、搜集可重用的产品单元。本阶段的目标是为DSSA增加构件,使它可以被用来产生问题域中的新应用。 DSSA 的建立过程是并发的、递归的和反复进行的。
软件产品线过程模型
| 模型名称 | 主要组成 / 生命周期阶段 | 核心思想 / 特点 | 适用场景 |
|---|---|---|---|
| 双生命周期模型(Two-Lifecycle Model) | 分为两个重叠的生命周期:① 领域工程(Domain Engineering);② 应用工程(Application Engineering) | 通过领域工程开发可复用的核心资产(如体系结构、构件、需求模板);再通过应用工程快速派生具体产品。强调复用与变异管理。 | 适用于核心资产稳定、产品族成员多样的组织。 |
| SEI 模型(SEI Product Line Practice Framework) | 由核心资产开发、产品开发、管理活动三部分组成 | SEI 模型是实践框架(Framework),强调组织级管理、过程改进、资源复用与度量机制。 | 适用于成熟的软件企业或过程改进组织。 |
| 三生命周期模型(Three-Lifecycle Model) | 包含三个并行的生命周期:① 领域工程;② 应用工程;③ 管理生命周期 | 在双生命周期基础上,增加独立的管理生命周期,负责资源、进度、配置与变更控制。强调并行协同开发与组织管理。 | 适用于大规模软件产品线或跨部门协作开发环境。 |
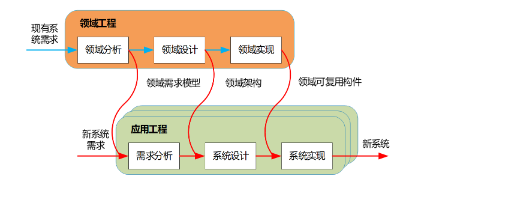
9.6 构件与中间件
- 中间件
中间件是一种独立的系统软件或服务程序,可以帮助分布式应用软件在不同的技术之间共享资源。中间件可以: 1)负责客户机与服务器之间的连接和通信,以及客户机与应用层之间的高效率通信机制。 2)提供应用的负载均衡和高可用性、安全机制与管理功能,以及交易管理机制,保证交易的一致性 3)提供应用层不同服务之间的互操作机制,以及应用层与数据库之间的连接和控制机制。 4)提供多层架构的应用开发和运行的平台,以及应用开发框架,支持模块化的应用开发。 5)屏蔽硬件、操作系统、网络和数据库的差异。 6)提供一组通用的服务去执行不同的功能,避免重复的工作,使应用之间可以协作。
| 类型 | 核心机制 / 模型 | 主要功能与特点 | 代表技术 / 案例 | 优点 | 缺点 / 局限 | 典型应用场景 |
|---|---|---|---|---|---|---|
| 分布式对象中间件(Distributed Object Middleware) | 基于对象请求代理(ORB)机制,实现跨语言、跨平台的对象透明调用 | - 面向对象模型,支持远程访问对象 - 强调接口与实现分离(IDL) - 通过对象引用实现位置透明 - 对象可被远程调用、传参和返回值 | CORBA、DDS | - 高度抽象,支持多语言互操作 - 接口定义独立于平台 - 支持复杂对象交互 | - 实现复杂,学习曲线陡峭 - 性能低于RPC - 部署复杂、兼容性差 | 金融、电信、军工等跨平台分布式系统 |
| 远程过程调用中间件(RPC Middleware) | 模拟本地函数调用实现远程调用,基于存根(Stub)与骨架(Skeleton) 机制 | - 面向过程模型 - 屏蔽底层通信细节 - 支持同步远程调用 - 协议绑定明确,性能高 | gRPC、Thrift、RMI、Dubbo(RPC框架) | - 高性能、延迟低 - 使用简单,开发效率高 - 调用过程透明 | - 客户端与服务端耦合较高 - 不适合复杂交互或异步通信 | 微服务架构、分布式系统内服务调用 |
| 消息中间件(Message-Oriented Middleware,MOM) | 基于异步消息队列,提供可靠、松耦合的消息传递机制 | - 异步通信 - 支持点对点(Queue)与发布-订阅(Topic)模式 - 提供消息持久化、事务、路由与重试 | Kafka、RabbitMQ、ActiveMQ、RocketMQ | - 高可用、高吞吐、可解耦 - 支持异步与削峰填谷 - 易扩展、容错性强 | - 实时性略差 - 需维护消息一致性 - 设计复杂性较高 | 大型分布式系统、异步解耦、日志采集、消息通知、订单系统等 |
| 对比维度 | 分布式对象中间件 | RPC 中间件 | 消息中间件 |
|---|---|---|---|
| 通信方式 | 同步调用(远程对象方法) | 同步调用(函数/过程) | 异步消息传递 |
| 耦合度 | 较低(通过ORB屏蔽平台差异) | 较高(接口与协议绑定) | 最低(完全解耦) |
| 主要模型 | 面向对象(Object-Oriented) | 面向过程(Procedure-Oriented) | 面向消息(Message-Oriented) |
| 适用规模 | 跨平台大型系统 | 企业内部或微服务系统 | 高并发、异步、分布式场景 |
| 开发复杂度 | 高 | 中 | 中等偏高(需架构设计) |
分布式对象中间件 核心是对象请求代理(ORB),支持跨平台对象透明调用,好比不同语言写的对象像在同一台机器上直接对 话。它采用面向对象模型,对象可被远程访问和调用,典型如CORBA、DDS,强调接口定义与平台无关性。在一个分布式系统中,中间件通常提供两种不同类型的支持: 1)交互支持,中间件协调系统中的不同组件之间的交互。 2)提供公共服务,即中间件提供对服务的可复用的实现。这些服务可能会被分布式系统中的很多组件所需要。公共服务是指被不同组件需求的服务,不管这些组件的功能是什么。你可以把这些服务看作是中间件容器提供的。可以在这个容器中部署你的组件并且这些组件可以访问和使用这些公共服务。
公共对象请求代理架构(Common Object Request Broker Architecture,CORBA) 1)伺服对象(Servant):CORBA对象的真正实现,负责完成客户端请求。 2)对象适配器(Obiect Adapter):用于屏蔽ORB内核的实现细节,为服务器对象的实现者提供抽象接口,以便他们使用ORB内部的某些功能。 3)对象请求代理(Obiect Request Broker,ORB):解释调用并负责査找实现该请求的对象,将参数传给找到的对象,并调用方法返回结果。客户方不需要了解服务对象的位置、通信方式、实现、激活或存储机制。
POA是对象实现与ORB其他组件之间的中介,它将客户请求传送到伺服对象,按需创建子POA,提供管理伺服对象的策略。 CORBA对象可看作是一个具有对象标识、对象接口及对象实现的抽象实体。之所以称为抽象的,是因为并没有硬性规定CORBA对象的实现机制。由于独立于程序设计语言和特定ORB产品一个CORBA对象的引用又称可互操作的对象引用(Interoperable Object Reference)。从客户程序的角度看,IOR中包含了对象的标识、接口类型及其他信息以查找对象实现。同服对象(Servant)是指具体程序设计语言的对象或实体,通常存在干一个服务程序进程之中。客户程序通过对象引用发出的请求经过ORB担当中介角色,转换为对特定的伺服对象的调用。在一个CORBA对象的生命期中,它可能与多个同服对象相关联,因而对该对象的请求可能被发送到不同的伺服对象。对象标识(ObjectID)是一个用于在POA中标识一个CORBA对象的字符串。它既可由程序员指派,也可由对象适配器自动分配,这两种方式都要求对象标识在创建它的对象适配器中必须具有唯一性。
远程过程调用(RPC)中间件 模拟本地函数调用方式实现远程调用,好比你打电话让同事办事,过程透明但面向过程。RPC强调协议绑定和存根/骨架机制,性能高但耦合度较分布式对象更高,常见于传统分布式系统。
消息中间件 是在消息的传输过程中保存信息的容器。消息中间件在将消息从它的源中继到它的目标时充当中间人的作用。队列的主要目的是提供路由并保证消息的传递;如果发送消息时接收者不可用,消息队列会保留消息,直到可以成功地传递它为止,当然,消息队列保存消息也是有期限的。 消息中间件的特点: (1)采用异步处理模式。消息发送者可以发送一个消息而无须等待响应。消息发送者将消息发送到一条虚拟的通道(主题或队列)上,消息接收者则订阅或是监听该通道。一条信息可能最终转发给一个或多个消息接收者,这些接收者都无需对消息发送者做出同步回应。整个过程都是异步的。 (2)应用程序和应用程序调用关系为松耦合关系。主要体现在如下两点:发送者和接受者不必了解对方、只需要确认消息;发送者和接受者不必同时在线。比如在线交易系统为了保证数据的最终一致,在支付系统处理完成后会把支付结果放到消息中间件里通知订单系统修改订单支付状态。两个系统通过消息中间件解。 消息中间件的传输模式: (1)点对点模型。点对点模型用于消息生产者和消息消费者之间点到点的通信。消息生产者将消息发送到由某个名字标识的特定消费者。这个名字实际上对应于消费服务中的一个队列(Queue),在消息传递给消费者之前它被存储在这个队列中。队列消息可以放在内存中也可以是持久的,以保证在消息服务出现故障时仍然能够传递消息。 (2)发布-订阅模型(Pub/Sub)。发布-订阅模型支持向一个特定的消息主题生产消息。0或多个订阅者可能对接收来自特定消息主题的消息感兴趣。在这种模型下,发布者和订阅者彼此不知道对方。这种模式就好比是匿名公告板。这种模式被概况为:多个消费者可以获得消息,在发布者和订阅者之间存在时间依赖性。发布者需要建立一个订阅(subscription),以便能够消费者订阅。订阅者必须保持持续的活动状态及接收消息,除非订阅者建立了持久的订阅。
IDL是一种接口定义语言,具体的定义会涉及接口以及相关部分。文件包含的主要元素有:接口描述、模块定义、类型定义、常量定义、异常、值类型。接口描述是IDL文件中最核心的内容。由于IDL只是一种接口定义语言,最终还是要落地与语言对接的,所以IDL的数据类型要与实现语言进行映射。以Java为例,IDL接口映射为Java类,而该接口的操作映射为相应的成员函数。模块定义映射为Java语言中的包(Package) 或C++中的Namespace。
- 构件
构件的定义 1)软件构件是一种组装单元,它具有规范的接口规约和显式的语境依赖。软件 构件可以被独立地部署并由第三方任意地组装。 2)构件是某系统中有价值的、几乎独立的并可替换的一个部分,它在良好定义的体系构语境内满足某清晰的功能。 3)构件是一个独立发布的功能部分,可以通过其接口访问它的服务。
构件的特性 1)独立部署单元: 2)作为第三方的组装单元: 3)没有(外部的)可见状态。 一个构件可以包含多个类元素,但是一个类元素只能属于一个构件。将一个类拆分进行部署通常没什么意义。 对象的特性是: 1)一个实例单元,具有唯一的标志。 2)可能具有状态,此状态外部可见。 3)封装了自己的状态和行为。
构件、原子构件、模块 1)构件是一组通常需要同时部署的原子构件。 构件和原子构件之间的区别在于,大多数原子构件永远都不会被单独部署,尽管它们可以被单独部署。相反,大多数原子构件都属于一个构件家族,一次部署往往涉及整个家族。一个原子构件是一个模块和一组资源。 2)原子构件是部署、版本控制和替换的基本单位。原子构件通常成组地部署,但是它也能够被单独部署。一个模块是不带单独资源的原子构件(在这个严格定义下,java 包不是模块–在 java 中部署的原子单元是类文件。一个单独的包被编译成多个单独的类文件–每个公共类都有一个)原子构件是不可以在多个构建家族中被共享的。 3)模块是一组类和可能的非面向对象的结构体,比如过程或者函数。一个原子构件是一个模块和一组资源。所以一个模块只能看做不带资源的原子构件。
构件的分类 如果把软件系统看成是构件的集合,那么从构件的外部形态来看,构成一个系统的构件可分为5类: (1)独立而成熟的构件。独立而成熟的构件得到了实际运行环境的多次检验,该类构件隐藏了所有接口,用户只需用规定好的命令进行使用。例如,数据库管理系统和操作系统等。 (2)有限制的构件。有限制的构件提供了接口,指出了使用的条件和前提,这种构件在装配时,会产生资源冲突、覆盖等影响,在使用时需要加以测试。例如,各种面向对象程序设计语言中的基础类库等。 (3)适应性构件。适应性构件进行了包装或使用了接口技术,把不兼容性、资源冲突等进行了处理,可以直接使用。这种构件可以不加修改地使用在各种环境中。例如ActiveX等。 (4)装配的构件。装配(assemble)的构件在安装时,已经装配在操作系统、数据库管理系统或信息系统不同层次上,使用胶水代码(glue code)就可以进行连接使用。目前一些软件商提供的大多数软件产品都属这一类。 (5)可修改的构件。可修改的构件可以进行版本替换。如果对原构件修改错误、增加新功能,可以利用重新“包装”或写接口来实现构件的替换。这种构件在应用系统开发中使用得比较多。
构件分类
目前,已有的构件分类方法可以分为三大类,分别是关键字分类法、刻面分类法和超文本组织方法。 1)关键字分类法:是一种最简单的构件库组织方法,其基本思想是:根据领域分析的结果将应用领域的概念按照从抽象到具体的顺序逐次分解为树状或有向无回路图结构。每个概念用一个描述性的关键字表示。不可分解的原子级关键字包含隶属于它的某些构件。 2)刻面分类法:在刻面分类机制中,定义若干用于刻画构件特征的”面”(facet),每个面包含若干概念,这些概念表述构件在面上的特征。刻画可以描述构件执行的功能、被操作的数据、构件应用的语境或任意其他特征。 3) 超文本组织方法:超文本组织方法与基于数据库系统的构件库组织方法不同,它基于全文检索技术,主要思想是:所有构件必须辅以详尽的功能或行为说明文档:说明中出现的重要概念或构件以网状链接方式相互连接;检索者在阅读文档的过程中可按照人类的联系思维方式任意跳转到包含相关概念或构件的文档;全文检索系统将用户给出的关键字与说明文档中的文字进行匹配,实现构件的浏览式检索。
如果把软件系统看成是构件的集合,那么从构件的外部形态来看,构成一个系统的构件可分为5类: (1)独立而成熟的构件。独立而成熟的构件得到了实际运行环境的多次检验,该类构件隐藏了所有接口,用户只需用规走好的命令进行使用。例如,数据库管理系统和操作系统等。 (2)有限制的构件。有限制的构件提供了接口,指出了使用的条件和前提,这种构件在装配时,会产生资源冲突、夏盖等影响,在使用时需要加以测试。例如,各种面向对象程序设计语言中的基础类库等。 (3)适应性构件。适应性构件进行了包装或使用了接口技术,把不兼容性、资源冲突等进行了处理,可以直接使用。这种构件可以不加修改地使用在各种环境中。例如ActiveX等。 (4)装配的构件。装配(assemble)的构件在安装时,已经装配在操作系统、数据库管理系统或信息系统不同层次上,使用胶水代码(glue code)就可以进行连接使用。目前一些软件商提供的大多数软件产品都属这一类。 (5)可修改的构件。可修改的构件可以进行版本替换。如果对原构件修改错误、增加新功能,可以利用重新“包装”或写接口来实现构件的替换。这种构件在应用系统开发中使用得比较多。
关于服务端构件模型的典型解决方案包括 1)适用于应用服务器的EJB模型(Sun公司J2EE的一部分)和COM+模型(微软公司), 2)以及适用于Web服务器的servlet模型(基于Sun公司JSP技术)和VisualBasic及其他微软的技术(基于微软公司ASP技术)。NET框架还引入了一种新的同时适用于客户端和服务端的基于CL(Command LineInterface)的构件模型
构件组装 是指将构件库中的构件经过适当修改后相互连接,或者将它们与当前开发项目中的构件元素相连接,最终构成新的目标软件。构件组装技术大致可分为基于功能的组装技术、基于数据的组装技术和面向对象的组装技术。 1)基于功能的构件组装技术:这种技术侧重于根据软件系统的功能需求来组装构件 2)基于数据的构件组装技术:这种技术首先根据当前软件问题的核心数据结构设计一个框架,然后根据框架中各个结点的需求提取构件并进行适应性修改。 3)面向对象的构件组装技术:面向对象技术提供了封装、继承和多态等特性,这些特性使得面向对象比其他的软件开发方法更适合支持软件复用。 在构件组装的常规分类中,并没有“基于实现的构件组装技术”这一类别。构件组装更多地关注于功能、数据或面向对象的角度,而不是具体的实现细节。
构件的组装方式包括: 1)顺序组装:按顺序调用己经存在的构件,可以用两个已经存在的构件来创造一个新的构件 2)层次组装:被调用构件的“提供”接口必须和调用构件的“请求”接口兼容。 3)叠加组装:多个构件合并形成新构件,新构件整合原构件的功能,对外提供新的接口。
组装可能出现3种不兼容: 1)【参数不兼容】接口每一侧的操作有相同的名字,但参数类型或参数个数不相同. 2)【操作不兼容】提供接口和请求接口的操作名不同。 3)【操作不完备】一个构件的提供接口是另一个构件请求接口的一个子集,或者相反。
系统构件组装分为三个不同的层次:定制(Customization)、集成(Integration)、扩展(Extension) 。这三个层次对应于构件组装过程中的不同任务, 1)定制阶段是构件组装过程的第一个层次,它主要关注于根据特定需求对构件进行个性化的调整或修改。 2)集成阶段是构件组装过程的第二个层次它主要关注于将多个定制好的构件组合成一个完整的软件系统。 3)扩展阶段是构件组装过程的第三个层次,“它主要关注于在现有软件系统的基础上增加新的功能或构件。
构件组装是指构件相互直接集成或是用“胶水代码"将其整合在一起来创造一个系统或另一个构件的过程。常见的方式包括:顺序组装、层次组装、叠加组装。同时,构件组装中经常会面临接口不兼容的问题,如果一个构件的提供接口是另一个构件请求接口的一个子集,则属于操作不完备的情况。
面向构件的编程(Component Oriented Programming,COP) 关注于如何支持建立面向构件的解决方案。一个基于一般 OOP 风格的 COP 定义如下(Szyperski,1995):面向构件的编程需要下列基本的支持: 1)多态性(可替代性); 2)模块封装性(高层次信息的隐藏): 3)后期的绑定和装载(部署独立性) 4)安全性(类型和模块安全性)。
对象管理组织(OMG)基于CORBA基础设施定义了4种构件标准: 1)实体(Entity) 构件需要长期持久化并主要用于事务性行为,由容器管理其持久化。 2)加工(Process)构件同样需要容器管理其持久化,但没有客户端可访问的主键。 3)会话(Session)构件不需要容器管理其持久化,其状态信息必须由构件自己管理。 4)服务(Service)构件是无状态的。
EJB全 Enterprise JavaBeans,是Java EE(企业级 Java 平台)的核心组件之一。它是一种分布式、事务性、基于组件的服务器端软件模型,用来简化企业级应用开发。分为会话Bean,实体Bean和消息驱动Bean。 1)会话Bean:用于实现业务逻辑,它可以是有状态的,也可以是无状态的。每当客户端请求时,容器就会选择个会话Bean来为客户端服务。会话Bean可以直接访问数据库,但更多时候,它会通过实体Bean实现数据访问。 2)实体Bean:用于实现O/R映射,负责将数据库中的表记录映射为内存中的实体对象,事实上,创建一个实体Bean对象相当于新建一条记录,删除一个实体Bean会同时从数据库中删除对应记录,修改一个实体Bean时,容器会自动将实体Bean的状态和数据库同步。 3)消息驱动Bean:是EJB3.0中引入的新的企业Bean,它基于JMS消息,只能接收客户端发送的JMS消息然后处理。MDB实际上是一个异步的无状态会话Bean,客户端调用MDB后无需等待,立刻返回,MDB将异步处理客户请求。这适合于需要异步处理请求的场合,比如订单处理,这样就能避免客户端长时间的等待一个方法调用直到返回结果。
构件和对象对比
| 概念 | 特性 |
|---|---|
| 构件 | (1) 独立部署单元 (2) 作为第三方的组装单元 (3) 没有外部可见状态 |
| 构件与类 | 一个构件可以包含多个类元素,但一个类元素只能属于一个构件 |
| 对象 | (1) 一个实例单元,具有唯一标志 (2) 可能具有状态,状态对外部可见 (3) 封装了自己的状态和行为 |
9.6 练习题
- 软件架构风格是描述某一特定应用领域中系统组织方式的惯用模式。架构风格定义了一类架构所共有的特征,主要包括架构定义、架构词汇表和架构()。
A.描述 B.组织 C.约束 D.接口
解析:本题主要考查软件架构风格的定义。软件架构风格是描述某一特定应用领域中系统组织方式的惯用模式。架构风格定义了一类架构所共有的特征,主要包括架构定义、架构词汇表和架构约束。
答案:C
- 以下叙述中,()不是软件架构的主要作用。
A.在设计变更相对容易的阶段,考虑系统结构的可选方案B.便于技术人员与非技术人员就软件设计进行交互C.展现软件的结构、属性与内部交互关系D.表达系统是否满足用户的功能性需求
解析:本题主要考查软件架构基础知识。软件架构能够在设计变更相对容易的阶段,考虑系统结构的可选方案,便于技术人员与非技术人员就软件设计进行交互,能够展现软件的结构、属性与内部交互关系。但是软件架构与用户对系统的功能性需求没有直接的对应关系。
答案:D
- 特定领域软件架构(DSSA)是在一个特定应用领域中,为一组应用提供组织结构参考的标准软件体系结构。DSSA通常是一个具有三个层次的系统模型,包括(1)环境、领域特定应用开发环境和应用执行环境,其中(2)主要在领域特定应用开发环境中工作。
(1)A.领域需求 B.领域开发 C.领域执行 D.领域应用 (2)A.操作员 B.领域架构师 C.应用工程师 D.程序员
解析:本题主要考查特定领域软件架构的基础知识。特定领域软件架构是在一个特定应用领域中,为一组应用提供组织结构参考的标准软件体系结构。DSSA通常是一个具有三个层次的系统模型,包括领域开发环境、领域特定应用开发环境和应用执行环境,其中应用工程师主要在领域特定应用开发环境中工作。
答案:B C
第10小时 系统质量属性与架构评估(性能、可用性)
10.0 章节考点分析
第10小时主要学习软件系统质量属性、系统架构评估以及ATAM方法评估实践等内容。
本小时内容侧重于概念知识,根据以往全国计算机技术与软件专业技术资格(水平)考试的出题规律,考查的知识点多来源于教材,扩展内容较少。根据考试大纲,本小时知识点会涉及单项选择题(约占 $8\sim 15$ 分)和下午案例题(25分),论文也会有覆盖。本小时知识架构如图10.1所示。
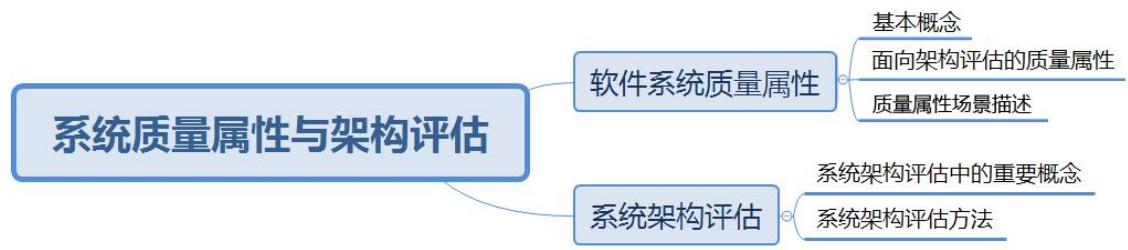
图10.1 本小时知识架构
【导读小贴士】
软件架构的基本需求是在满足功能属性的前提下,关注软件系统的质量属性。在精准描述软件质量场景后,可通过对架构的评估决定架构策略以及架构评审。因此,我们有必要了解架构质量属性和架构评估。这部分内容也是案例和论文的考试重点。
10.1 软件系统质量属性(质量属性、场景)
【基础知识点】
- 基本概念
软件系统质量属性是一个系统的可测量或可测试的属性,基于软件系统的生命周期,可将软件系统的质量属性分为开发期质量属性和运行期质量属性,见表10.1。
表10.1软件系统质量属性一览表
口诀: 【开发期】:理扩重测维移 【运行期】:性全伸操靠用棒
| 属性 | 子属性 | 作用及要点 |
|---|---|---|
| 开发期质量属性 | 易理解性 | 指设计被开发人员理解的难易程度 |
| 可扩展性 | 软件因适应新需求或需求变化而增加新功能的能力,也称灵活性 | |
| 可重用性 | 指重用软件系统或某一部分的难易程度 | |
| 可测试性 | 对软件测试以证明其满足需求规范的难易程度 | |
| 可维护性 | 当需要修改缺陷、增加功能、提高质量属性时,识别修改点并实施修改的难易程度 | |
| 可移植性 | 将软件系统从一个运行环境转移到另一个不同的运行环境的难易程度 | |
| 运行期质量属性 | 性能 | 软件系统及时提供相应服务的能力,如速度、吞吐量和容量等 |
| 安全性 | 软件系统同时兼顾向合法用户提供服务,以及阻止非授权使用的能力 | |
| 可伸缩性 | 当用户数和数据量增加时,软件系统维持高服务质量的能力 | |
| 互操作性 | 软件系统与其他系统交换数据和相互调用服务的难易程度 | |
| 可靠性 | 软件系统在一定的时间内持续无故障运行的能力 | |
| 可用性 | 系统在一定时间内正常工作的时间所占比例 | |
| 鲁棒性 | 软件系统在非正常情况(用户进行非法操作、相关软硬件系统发生故障)下仍能运行的能力,也称健壮性或容错性 |
- 面向架构评估的质量属性
在架构评估过程中,评估人员普遍关注的质量属性见表10.2。
表10.2 评估属性一览表
| 属性 | 子属性 | 作用及要点 |
|---|---|---|
| 性能 | - | 效率指标:处理任务所需时间或单位时间内的处理量 |
| 可靠性 | 容错 | 出现错误后仍能保证系统正常运行,且自行修正错误 |
| 健壮性 | 错误不对系统产生影响,按既定程序忽略错误 | |
| 可用性 | - | 正常运行的时间比例 |
| 安全性 | - | 系统向合法用户提供服务并阻止非法用户的能力 |
| 可修改性 | 可维护性 | 局部修复使故障对架构的负面影响最小化 |
| 可扩展性 | 因松散耦合更易实现新特性/功能,不影响架构 | |
| 结构重组 | 不影响主体进行的灵活配置 | |
| 可移植性 | 适用于多样的环境(硬件平台、语言、操作系统等) | |
| 功能性 | - | 需求的满足程度 |
| 可变性 | - | 总体架构可变 |
| 互操作性 | - | 通过可视化或接口方式提供更好的交互操作体验 |
就系统架构设计师考试而言,我们针对上表梳理了一些考试常考的质量属性,以及提升或保证这些质量属性的应对措施。
(1)可用性。提升可用性的策略可以从以下几个方面考虑:
- 错误检测:心跳、Ping/Echo、异常。
- 错误恢复:表决、主动冗余、被动冗余、重新同步、内测、检查点/回滚。
- 错误避免:服务下线、事务、进程监控器。
(2)性能。提升性能的策略可以从以下几个方面考虑:
- 资源的需求:减少处理事件时对资源的占用、减少处理事件的数量、控制资源的使用。
- 资源管理:并发机制、增加资源。
- 资源仲裁:先来先服务、固定优先级、动态优先级、静态调度。
(3)可修改性。提升性能的策略可以从以下几个方面考虑: 1) 局部化修改:高内聚低耦合、预测变更、使模块通用。 2) 防止连锁反应:信息隐藏、抽象、维持现有接口、接口-实现分离、限制通信路径、使用中介。 3) 推迟绑定时间:运行时注册、多态、配置文件。
(4)安全性。提升安全性的策略可以从以下几个方面考虑: 1) 抵抗攻击:用户身份验证、用户授权、维护数据机密性与完整性、限制暴露、限制访问。 2) 检测攻击:入侵检测系统。 3) 从攻击中恢复:恢复状态、识别攻击者。
- 质量属性场景描述
质量属性场景是一种面向特定质量属性的需求,由刺激源、刺激、环境、制品、响应、响应度量组成。
1)刺激源(Source):某个生成该刺激的实体(人、计算机系统或者任何其他刺激器)。 2)刺激(Stimulus):指当刺激到达系统时需要考虑的条件。 3)环境(Environment):指该刺激在某些条件内发生。当激励发生时,系统可能处于过载、运行或者其他情况。 4)制品(Artifact):某个制品被激励,可能是整个系统,也可能是系统的一部分。 5)响应(Response):指在激励到达后所采取的行动。 6)响应度量(Measurement):当响应发生时,应当能够以某种方式对其进行度量,以对需求进行测试。
环境(办公室)中,手机(制品) 的 通知模块(刺激源) 发出一条 消息提醒(刺激), 用户 点击打开(响应),系统记录 反应时间(响应度量)。
| 概念 | 定义 | 举例说明(以手机通知为例) |
|---|---|---|
| 刺激源(Stimulus Source) | 引发刺激的“根源”或“实体”。可以是外部事物、系统内部、系统组件或环境变化。 | 手机系统本身(通知模块)就是刺激源。 |
| 刺激(Stimulus) | 从刺激源发出的具体信号(崩溃、损坏)、事件或信息,是作用于个体(或系统)的直接输入。 | 手机屏幕亮起、提示音响起、通知栏出现新消息。 |
| 环境(Environment) | 发生刺激与响应的背景条件,包括物理环境、系统状态或用户情境。 | 用户所在的环境:办公室、静音模式、光线强弱等。 |
| 制品(Artifact / Product) | 供用户使用或交互的对象(通常是系统或产品本身)。 | 手机APP或手机界面。 |
| 响应(Response) | 个体或系统对刺激做出的反应,可以是行为、心理或系统输出。 | 用户拿起手机、点击通知、关闭声音等。 |
| 响应度量(Response Measure) | 对响应的客观测量或评估指标,用于分析性能或行为特征。 | 用户反应时间、点击率、误触率、情绪评分等。 |
10.2 系统架构评估(ATAM、SAAM、敏感点)
【基础知识点】
系统架构评估是在对架构分析、评估的基础上,对架构策略的选取进行决策,通常分为:
(1)基于调查问卷或检查表的方法:缺点是很大程度上依赖于评估人员的主观判断。 (2)基于场景的评估方法:应用在架构权衡分析法(ATAM) 和软件架构分析方法(SAAM) 中。 (3)基于度量的评估方法:建立质量属性和度量之间的映射原则 $\twoheadrightarrow$ 在软件文档中获取度量信息 $\twoheadrightarrow$ 分析推导系统质量属性。
- 系统架构评估中的重要概念
(1)风险点:指架构设计中潜在的、存在问题的架构决策所带来的隐患 (2)非风险点:某些做法是可行的、可接受的 (3)敏感点:实现质量目标时应注意的点,是一个或多个构件的特性。 (4)权衡点:影响多个质量属性的敏感点。 (5)风险承担者或利益相关人:影响体系结构或被体系结构影响的群体。 (6)场景(scenarios): 在进行体系结构评估时,一般首先要精确地得出具体的质量目标,并以之作为判定该体系结构优劣的标准。为得出这些目标而采用的机制叫做场景。场景是从风险承担者的角度对与系统的交互的简短描述。在体系结构评估中,一般采用刺激(stimulus)、环境(environment)和响应(response)三方面来对场景进行描述。
| 概念 | 定义 | 特性 | 示例 |
|---|---|---|---|
| 风险点 | 可能引起风险的因素,非严格专业术语,泛指潜在问题来源。 | 与潜在风险相关,强调“可能出问题”。 | 某个接口可能因异常输入导致系统崩溃。 |
| 敏感点 | 一个或多个构件(及其关系)的特性,对质量目标有较大影响。 | 针对质量属性,提示设计/分析中应关注的关键点。 | 系统响应时间对性能敏感。 |
| 权衡点 | 同时影响多个质量属性的特性,是多个敏感点的交集。 | 涉及不同质量目标之间的矛盾或取舍。 | 加密级别:提高安全性但降低性能。 |
- 系统架构评估方法
(1)软件架构分析方法(Software Architecture Analysis Method,SAAM)。SAAM是卡耐基梅隆大学软件工程研究所的Kartman等人于1983年提出的一种非功能质量属性的架构分析方法,是最早形成文档并得到广泛应用的软件架构分析方法。 SAAM的主要输入是问题描述、需求说明和架构描述 其分析过程主要包括场景开发、架构描述、单个场景评估、场景交互、总体评估,如图10.2所示。
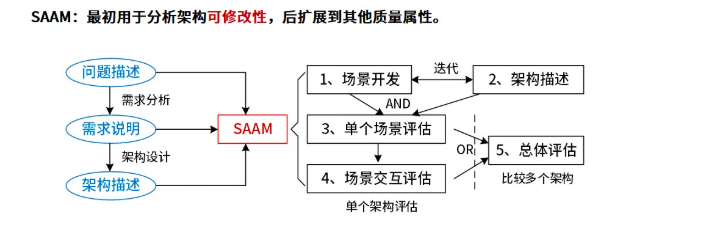
图10.2 SAAM的输入与评估过程
(2)架构权衡分析法(Architecture Tradeoff Analysis Method,ATAM)。ATAM是一种系统架构评估方法,该框架主要关注系统的需求说明,主要在系统开发之前,针对性能、可用性、安全性和可修改性等质量属性进行评价和折中。传统的 ATAM 可以分为 4 个主要的活动阶段,包括场景和需求收集、体系结构视图和场景实现、属性模型构造和分析、架构决策与折中,整个评估过程强调以属性作为架构评估的核心概念。现代的 ATAM 方法采用效用树对质量属性进行分类和优先级排序。用 ATAM 方法评估软件体系结构分为演示、调查和分析、测试和报告。
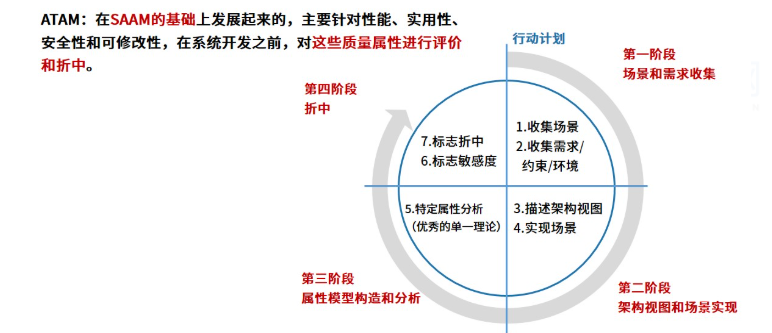

1)演示(Presentation) 。使用 ATAM 评估软件体系结构的初始阶段,包括 3 个步骤: $(1)$ 介绍 ATAM:描述 ATAM 评估过程 $(2)$ 介绍业务驱动因素:着重业务视角,提供有关系统功能、主要利益相关方、业务目标和其他限制等信息。 $(3)$ 介绍要评估的体系结构:侧重可用性以及体系结构的质量要求。
2)调查和分析。使用 ATAM 技术评估架构第 2 阶段,对一些关键问题彻底调查,包括 3 个步骤:
$(1)$ 确定架构方法:涉及能够理解系统关键需求的关键架构方法。
$(2)$ 生成质量属性效用树:确定最重要的质量属性,并确定优先次序。
生成质量属性效用树过程:可以选取这样一棵树:根 – 质量属性 – 属性分类(细分)– 质量属性场景(叶)。修剪这棵树,保留重要场景(不超过50 个),再对场景按重要性给定优先级(用 H/M/L的形式),再按场景实现的难易度来确定优先级(用 H/M/L的形式),这样对所选定的每个场景就有一个优先级对(重要度,难易度),如(H,L)表示该场景重要且易实现。如下图:
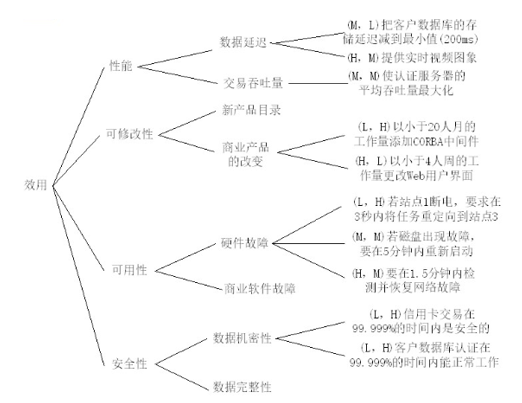
$(3)$ 分析体系结构方法:彻底调查和分析,找出处理相应质量属性架构的方法。包括 4 个主要阶段:调查架构方法 $\twoheadrightarrow$ 创建分析问题 $\twoheadrightarrow$ 分析问题的答案 $\twoheadrightarrow$ 找出风险、非风险、敏感点和权衡点。
3)测试。 $(1)$ 头脑风暴和优先场景:将头脑风暴的优先列表与生成质量属性效用树中所获取的优先方案进行比较。 $(2)$ 分析架构方法。
4)报告ATAM。提供评估期间收集的所有信息,呈现给利益相关者。
上述两种主要评估方法的对比,见表10.3。
表10.3 评估方法的对比
| 项目 | SAAM | ATAM |
| 特定目标 | 通过程序文档验证体系结构,注重发现潜在问题,可用于评价单系统或进行多系统比较 | 确定在多个质量属性之间折中的必要性 |
| 评估技术 | 场景技术 | 场景技术、启发式分析方法 |
| 质量属性 | 可修改性是主要分析内容 | 性能、可用性、安全性和可修改性 |
| 风险承担者 | 所有参与者 | 场景和需求收集过程中的相关人 |
| 架构描述 | 围绕功能、结构和分配描述 | 五个基本结构及其映射关系 |
| 方法活动 | 场景开发、体系结构描述、单个场景评估、场景交互和总体评估 | 场景和需求收集、体系结构视图和场景实现、属性模型构造和分析、折中 |
| 知识库可复用性 | 不涉及 | 有基于属性的体系模型,可复用 |
| 方法验证 (应用领域) | 空中交通管制系统、嵌入式音频系统、修正控制系统 | 仍处于研究中 |
(3)成本效益分析法(CostBenefitAnalysisMethod,CBAM)分为整理场景 $\twoheadrightarrow$ 对场景进行求精 $\twoheadrightarrow$ 确定场景的优先级 $\twoheadrightarrow$ 分配效用 $\twoheadrightarrow$ 架构策略涉及哪些质量属性及响应级别 $\twoheadrightarrow$ 使用内插法确定“期望的”质量属性响应级别的效用 $\twoheadrightarrow$ 计算各架构策略的总收益 $\twoheadrightarrow$ 根据受成本限制影响的ROI选择架构策略。
(4)其他评估方法。
1)SAEM方法:将软件架构看作一个最终产品以及涉及过程中的一个中间产品,从外部质量属性和内部质量属性阐述的评估模型。
2)SAABNet方法:辅助架构的定性评估,帮助诊断软件问题的可能原因,分析架构中的修改给质量属性带来的影响、预测架构的质量属性,帮助架构设计人员做决策。SAABNet度量的对象包括架构属性、质量准则和质量因素。
3)SACMM方法:一种软件架构修改的度量方法,首先基于内核定义差异度量准则来计算两个软件架构之间的距离,然后分析对象之间的相似性。
4)SASAM方法:通过对预期架构和实际架构进行映射和比较来静态地评估软件架构。
5)ALRRA方法:是软件架构可靠性风险评估方法,使用动态复杂度准则和动态耦合度准则来定义组件和连接件的复杂性因素。
6)AHP方法:把定性分析和定量计算相结合,对各种决策因素进行处理。
7)COSMIC+UML方法:针对不同表达方式的软件架构,采用统一的软件度量COSMIC方法来进行度量和评估。
10.3 练习题
- 识别风险、非风险、敏感点和权衡点是进行软件架构评估的重要过程。“改变业务数据编码方式会对系统的性能和安全性产生影响”是对(1)的描述,“假设用户请求的频率为每秒1个,业务处理时间小于30毫秒,则将请求响应时间设定为1秒钟是可以接受的”是对(2)的描述。
(1)A.风险点 B.非风险 C.敏感点 D.权衡点(2)A.风险点 B.非风险 C.敏感点 D.权衡点
解析:风险是某个存在问题的架构设计决策,可能会导致问题;非风险与风险相对,是良好的架构设计决策;敏感点是一个或多个构件的特性;权衡点是影响多个质量属性的特性,是多个质量属性的敏感点。根据上述定义,可以看出“改变业务数据编码方式会对系统的性能和安全性产生影响”是对权衡点的描述,“假设用户请求的频率为每秒1个,业务处理时间小于30毫秒,则将请求响应时间设定为1秒钟是可以接受的”是对非风险的描述。
答案:DB
- 请详细阅读有关软件架构评估方面的说明,回答下列问题
【说明】某电子商务公司拟升级目前正在使用的在线交易系统,以提高客户网上购物时在线支付环节的效率和安全性。公司研发部门在需求分析的基础上,给出了在线交易系统的架构设计。公司组织相关人员召开了针对架构设计的评估会议,会上用户提出的需求、架构师识别的关键质量属性场景和评估专家的意见等内容部分列举如下:
(a)在正常负载情况下,系统必须在0.5秒内响应用户的交易请求。(b)用户的信用卡支付必须保证 $99.999%$ 的安全性。(c)系统升级后用户名要求至少包含8个字符。(d)网络失效后,系统需要在2分钟内发现错误并启用备用系统。(e)在高峰负载情况下,用户发起支付请求后系统必须在10秒内完成支付功能。(f)系统拟采用新的加密算法,这会提高系统的安全性,但同时会降低系统的性能。(g)对交易请求处理时间的要求将影响系统数据传输协议和交易处理过程的设计。(h)需要在30人·月内为系统添加公司新购买的事务处理中间件。(i)现有架构设计中的支付部分与第三方支付平台紧耦合,当系统需要支持新的支付平台时,这种设计会导致支付部分代码的修改,影响系统的可修改性。(j)主站点断电后,需要在3秒内将访问请求重定向到备用站点。(k)用户信息数据库授权必须保证 $99.999%$ 可用。(l)系统需要对Web界面风格进行修改,修改工作必须在4人·月内完成。(m)系统需要为后端工程师提供远程调试接口,并支持远程调试。
【问题1】在架构评估过程中,质量属性效用树(Utility Tree)是对系统质量属性进行识别和优先级排序的重要工具。请给出合适的质量属性,填入下图中(1)、(2)空白处;并选择题干描述的(a)~(m),填入(3)~(6)空白处,完成该系统的效用树。
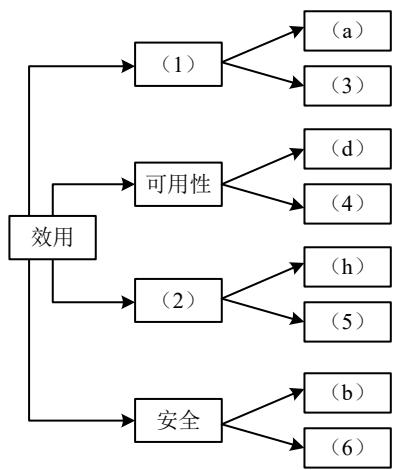
答案:在架构评估过程中,质量属性效用树(Utility Tree)是对系统质量属性进行识别和优先级排序的重要工具。效用树主要关注性能、可修改性、可用性和安全4个方面。
| 编号 | 答案 |
| (1) | 性能 |
| (2) | 可修改性 |
| (3) | (e) |
| (4) | (j) |
| (5) | (l) |
| (6) | (k) |
【问题2】在架构评估过程中,需要正确识别系统的架构风险、敏感点和权衡点,并进行合理的架构决策。请用300字以内的文字给出系统架构风险、敏感点和权衡点的定义,并从题干(a)~(m)中各选出1个对系统架构风险、敏感点和权衡点最为恰当的描述。
答案:系统架构风险是指架构设计中潜在的、存在问题的架构决策所带来的隐患。敏感点是为了实现某种特定质量属性,一个或多个系统组件所具有的特性。权衡点是影响多个质量属性,并对多个质量属性来说都是敏感点的系统属性。根据上述分析可知题干描述中,(i)描述的是系统架构风险;(g)描述的是敏感点;(f)描述的是权衡点。
第11小时 软件可靠性基础知识
11.0 章节考点分析
第11小时主要学习软件可靠性基本概念、建模、管理、设计、测试和评价等内容。本小时内容侧重于概念知识,根据以往全国计算机技术与软件专业技术资格(水平)考试的出题规律,考查的知识点多来源于教材,扩展内容较少。根据考试大纲,本小时知识点会涉及单项选择题(约占$2\sim 3$分),论文也会有涉及。本小时知识架构如图11.1所示。
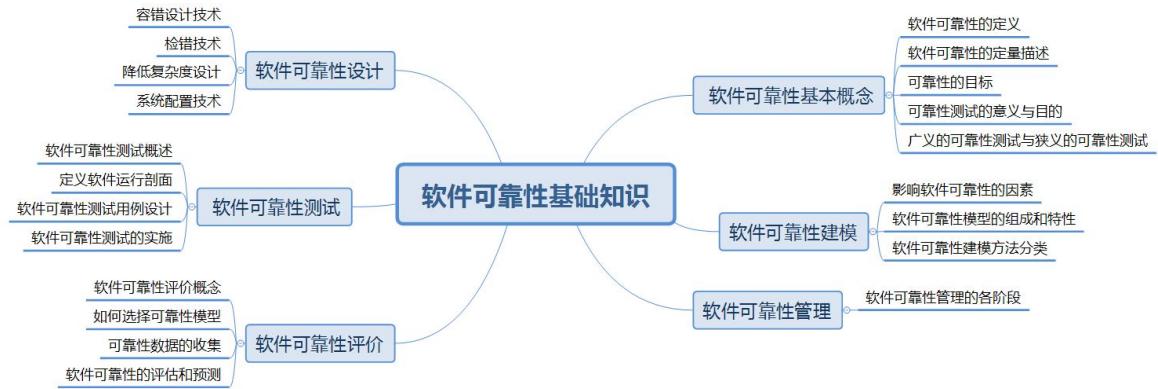
图11.1 本小时知识架构
【导读小贴士】
软件可靠性和其他属性一样是衡量软件的重要指标,保障软件可靠性最有效、最经济、最重要的手段是在软件设计阶段采用措施进行可靠性控制。考试中很多案例分析题甚至论文题会出自本小时内容。本章建议以读教材为主,多分析历年真题,以把握命题人对本章的出题思路。
11.1 软件可靠性基本概念
【基础知识点】
- 软件可靠性的定义
软件可靠性是指在规定的时间内,软件不引起系统失效的概率。该概率是系统输入和系统使用的函数,也是软件中存在的缺陷函数;系统输入将确定是否会遇到已存在的缺陷。
- 软件可靠性的定量描述
软件的可靠性是在软件使用条件、在规定时间内、系统的输入/输出、系统使用等变量构成的数学表达式
(1)规定时间:自然时间、运行时间(启动到结束)、执行时间(cpu执行指令的时间) (2)失效概率:从软件运行开始,到某一时刻t为止,出现失效的概率。可以看作是关于软件运行时间的一个随机函数 (3)可靠度:表示可靠性最为直接的方式,是指软件系统在规定的条件下、规定的时间内不发生失效的概率 (4)失效强度:单位时间软件系统出现失效的概率 (5)平均失效前时间:软件运行后,到下一次失效的平均时间,更直观地反映软件的可靠度 (6)平均恢复前时间:从出现故障到修复成功的这段时间 (7)平均故障间隔时间:失效或维护中所需的平均时间,包括故障时间以及检测和维护设备的时间。
- 可靠性的目标
软件可靠性是指用户对所使用的软件的性能满意程度的期望。可以用可靠度、平均失效时间和故障强度等来描述。
- 可靠性测试的意义与目的
可靠性测试的意义是: (1)软件失效可能造成灾难性的后果。 (2)软件的失效在整个计算机系统失效中的比例较高。 (3)相比硬件可靠性技术,软件可靠性技术不成熟。 (4)软件可靠性问题会造成软件费用增长。 (5)系统对软件的依赖性强,对生产活动和社会生活影响日益增大。
可靠性测试的目的是: (1)发现软件系统的缺陷。 (2)为软件的使用和维护提供可靠性依据。 (3)确认软件是否达到可靠性的定量要求。
- 广义的可靠性测试与狭义的可靠性测试
(1)广义的可靠性测试是为了最终评价软件系统的可靠性而运用建模、统计、试验、分析和评价等一系列手段对软件系统实施的一种测试。 (2)狭义的可靠性测试是为了获取可靠性数据,按预先确定好的测试用例,在软件预期使用环境中,对软件实施的一种测试。
11.2 软件可靠性建模
【基础知识点】
(1)影响软件可靠性的因素包括:运行环境、软件规模、软件的内部结构、软件的开发方法和开发环境、软件的可靠性投入。
(2)软件可靠性模型的组成和特性,如图11.4所示
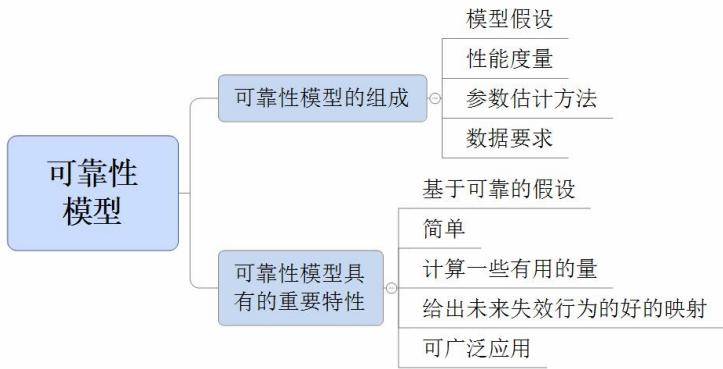
图11.4 可靠性模型的组成和特性
(3)软件可靠性建模方法包括:种子法、失效率类、曲线拟合类、可靠性增长、程序结构分析、输入域分类、执行路径分析方法、非齐次泊松过程、马尔可夫过程、贝叶斯分析。
11.3 软件可靠性管理
【基础知识点】
软件可靠性管理的各阶段,如图11.5所示
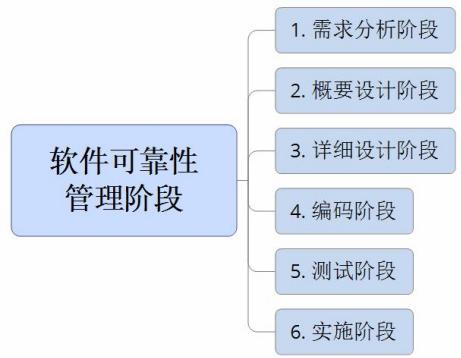
图11.5 软件可靠性管理的各阶段
软件可靠性管理是软件工程管理的一部分,它以全面提高和保证软件可靠性为目标,以软件可靠性活动为主要对象,是把现代管理理论用于软件生命周期中的可靠性保障活动的一种管理形式。软件可靠性管理的内容包括软件工程各个阶段的可靠性活动的目标、计划、进度、任务和实施阶段修正措施等,基中,详细设计阶段任务: (1)可靠性设计。 (2)可靠性预测(确定可靠性度量估计值) (3)调整可靠性活动计划。 (4)收集可靠性数据。 (5)明确后续阶段的可靠性活动的详细计划,编制可靠性文档。
11.4 软件可靠性设计
【基础知识点】
软件可靠性设计技术有:容错设计技术、检错技术、降低复杂度设计、系统配置技术。
(1)容错设计技术:恢复块设计、N版本程序设计、冗余设计。 1)恢复块设计:选择一组操作作为容错设计单元,把普通的程序块变成恢复块。 2)N版本程序设计:通过设计多个模块或不同版本,对相同初始条件和相同输入的操作结果,实行多数表决,防止其中某一软件模块/版本的故障提供错误的服务。 3)冗余设计:在一套完整的软件系统之外,设计一种不同路径、不同算法或不同实现方式方法的模块或系统作为备份,在出现故障时可使用冗余部分进行替换。
前向恢复:使当前的计算继续下去,把系统恢复成连贯的正确状态,弥补当前状态的不连贯情况。 后向恢复:系统恢复到前一个正确状态,继续执行。
(2)检错技术。 1)检错技术代价低于容错技术和冗余技术,但是不能自动解决故障,需要人工干预。 2)检错技术着重考虑检测对象、检测延时、实现方式、处理方式四个要素。
(3)降低复杂度设计。 降低复杂度设计思想是在保证实现软件功能基础上,简化软件结构、缩短程序代码长度、优化软件数据流向、降低软件复杂度、提高软件可靠性。
(4)系统配置技术:可以分为双机热备技术和服务器集群技术。 1)双机热备技术。 ① 采用心跳方法保证主系统与备用系统的联系。 ② 根据两台服务器的工作方式分为双机热备模式(一台工作,一台后备)、双机互备模式(两台运行相对独立应用,互为后备)、双机双工模式(两台同时运行相同应用,互为后备)。 2)服务器集群技术。 集群内各节点服务器通过内部局域网相互通信,若某节点服务器发生故障,这台服务器运行的应用被另一节点服务器自动接管。
11.5 软件可靠性测试
【基础知识点】
- 软件可靠性测试概述
软件可靠性测试包括:可靠性目标的确定、运行剖面的开发、测试用例的设计、测试实施、测试结果分析等。
- 定义软件运行剖面
为软件的使用行为建模,开发使用模型,明确需测试内容。
- 软件可靠性测试用例设计
测试用例要能够反映实际的使用情况,优先测试最重要的和最频繁使用的功能,其组成如图11.6所示。设计测试用例,针对组合功能或特定功能,编写成相关文档。
测试用例的组成:
(1)测试用例标识(2)被测对象(3)测试环境及条件(4)测试输入(5)操作步骤(6)预期输出(7)判断输出结果是否符合标准(8)测试对象的特殊需求
- 软件可靠性测试的实施
用时间定义的软件可靠性数据分为4类:失效时间数据、失效间隔时间数据、分组时间内的失效数、分组时间的累积失效数。
测试记录与测试报告的组成如图11.7所示
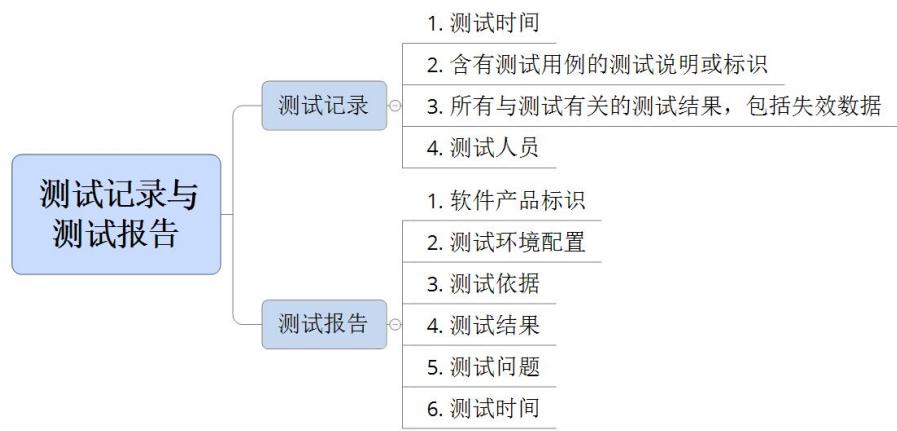
图11.7 测试记录与测试报告的组成
平均无故障时间 →(MTTF)系统无故障运行的平均时间。 平均故障修复时间 →(MTTR)从出现故障到修复成功中间的这段时间。 平均故障间隔时间→(MTBF)MTBF=MTTR +MTTF 平均检测时间 →(MTTD)故障发生到被检测出来的时间【潜伏期】。 系统可用性→ MTTF/(MTTR+MTTF)x100%

| 中文名 | 英文全称 | 英文缩写 | 解释 |
|---|---|---|---|
| 平均无故障时间 | Mean Time To Failure | MTTF | 系统从启动到第一次故障发生的平均时间(适用于不可修复系统,如一次性设备或组件) |
| 平均故障修复时间 | Mean Time To Repair | MTTR | 从发生故障到修复完成、系统恢复正常运行的平均时间 |
| 平均故障间隔时间 | Mean Time Between Failures | MTBF | 系统两次故障之间的平均运行时间;公式:MTBF = MTTF + MTTR(适用于可修复系统) |
| 平均检测时间 | Mean Time To Detect(或 Mean Time To Discovery) | MTTD | 从故障发生到被检测到的平均时间,也称为潜伏检测时间 |
11.6 软件可靠性评价
【基础知识点】
- 软件可靠性评价概念
可靠性: 指在规定的时间内和规定条件下能有效地实现规定功能的能力。它不仅取决于规定的使用条件等因素,还与设计技术有关。常用的度量指标主要有故障率(或失效率)、平均失效等待时间、平均失效间隔时间和可靠度等。其中, 1)可靠度是系统在规定工作时间内无故障的概率。 2)可用性是系统能够正常运行的时间比例。经常用两次故障之间的时间长度或出现故障时系统能够恢复正常的速度来表示。 3)可测试性:是指验证软件程序正确的难易程度。可测试性好的软件,通常意味着软件设计简单,复杂性低。因为软件的复杂性越大,测试的难度也就越大。 4)可理解性:通过阅读源代码和相关文档,了解程序功能及其如何运行的容易程度。综上,答案应该为AD。
评估和预测软件可靠性过程包括:
(1)选择可靠性模型。(2)收集可靠性数据。(3)可靠性评估和预测。
- 如何选择可靠性模型
可以从以下几方面选择可靠性模型:
(1)模型假设的适用性(2)预测的能力与质量。(3)模型输出值能否满足可靠性的评价需求。(4)模型使用的简便性。
- 可靠性数据的收集
数据收集可行的办法有:
(1)尽可能早地确定可靠性模型(2)数据收集计划要有较强的可操作性。(3)重视测试数据的分析和整理。(4)充分利用技术手段(数据库技术)来完成分析和统计。
- 软件可靠性的评估和预测
(1)软件可靠性的评估和预测的目的是评估软件系统的可靠性状况和预测将来一段时间的可靠性水平。 (2)软件可靠性的评估和预测以软件可靠性模型分析为主,以失效数据的图形分析法和试探性数据分析技术等为辅。
失效严重程度分类
| 失效严重程度类 | 定义 |
|---|---|
| 1 | 系统崩溃,重要数据不可恢复 |
| 2 | 系统出错停止响应,重要数据可恢复 |
| 3 | 用户重要操作无响应,可恢复 |
| 4 | 部分操作无响应,但可用其他操作方式替代 |
11.7 其他
11.7 练习题
- 采用检错设计技术要着重考虑四个要素:检测对象、()、实现方法和处理方式。
A.检测延时 B.测试结果 C.性能测试 D.功能测试
解析:对软件可靠性管理的检错技术的考查。
采用检错设计技术要着重考虑4个要素:检测对象、检测延时、实现方法和处理方式。
答案:A
- ()是通常所说的Active/Standby方式,Active服务器处于工作状态,Standby服务器处于监控准备状态,服务器数据包括数据库数据同时往两台或多台服务器写入,保证数据的即时同步。
A.双机热备 B.双机互备 C.双机双工 D.服务器集群
解析:对软件可靠性管理的检错技术的考查。一台服务器处于工作状态,另一台处于后备状态,是双机热备模式。
答案:A
第12小时 软件架构的演化和维护
12.0 章节考点分析
第12小时学习软件架构的演化和维护问题,包括基本概念、演化类型、原则、评估方法和维护手段,以及对大型网站系统的架构演化实例等方面进行分析等。
本小时内容侧重于概念知识,根据以往全国计算机技术与软件专业技术资格(水平)考试的出题规律,考查的知识点多来源于教材,扩展内容较少。根据考试大纲,本小时知识点会涉及单项选择题(约占$3\sim 5$分)和下午案例题(25分),论文也会有涉及。本小时知识架构如图12.1所示。
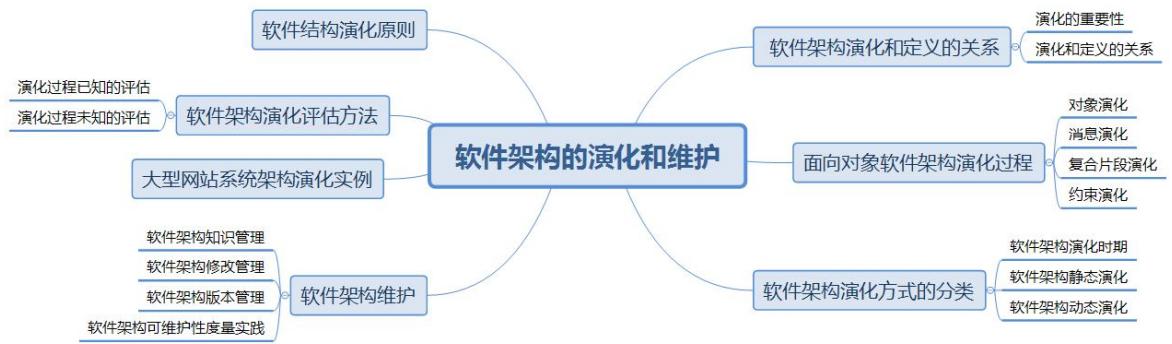
图12.1 本小时知识架构
【导读小贴士】
为了使软件能适应环境变化和满足用户需求,在软件架构生命周期中,不断迭代的演化和维护至关重要。考试中很多案例分析题甚至论文题会出自本小时内容。建议除了掌握核心知识点外,还要多留意平时的项目经历。
12.1 软件架构演化和定义的关系
【基础知识点】
- 演化的重要性
(1)保障软件系统具备诸多好的特性。(2)有效管控软件系统的整体复杂性和变化性,降低软件检修和修改成本。(3)保证软件系统演化的一致性和正确性,增加便捷性。
- 演化和定义的关系
软件架构包括组件、连接件和约束三大要素,此软件架构演化主要关注组件、连接件和约束的添加、修改和删除。
12.2 面向对象软件架构演化过程
【基础知识点】
- 对象演化
对架构设计的动态行为产生影响的演化包括Add Object(AO)和Delete Object(DO)。
(1)AO是在系统需要添加新的对象来实现某种新的功能,或需将现有对象的某个功能独立以增加架构灵活性时发生。 (2)DO是在系统需要移除某个现有的功能,或需合并某些对象及其功能来降低架构的复杂度的时候发生。
- 消息演化
消息演化包括Add Message(AM)、Delete Message(DM)、Swap Message Order(SMO)、Overturn Message(OM)、Change Message Module(CMM)。
(1)AM:增添一条新的消息,产生在对象之间需要增加新的交互行为的时候。 (2)DM:删除当前的一条消息,产生在需要移除某交互行为的时候。 (3)SMO:交换两条消息的时间顺序,发生在需要改变两个交互行为之间的时候。 (4)OM:反转消息的发送对象与接收对象,发生在需要修改某个交互行为本身的时候。 (5)CMM:改变消息的发送或接收对象,发生在需要修改某个交互行为本身的时候。
- 复合片段演化
复合片断的演化包括Add Fragment(AF)、Delete Fragment(DF)、Fragment Type Change(FTC)、Fragment Condition Change(FCC)。
(1)AF:在某几条消息上新增复合片段,发生在需要增添新的控制流时。 (2)DF:删除某个现有的复合片段,发生在需要移除当前某段控制流时。(3)FTC:改变复合片段的类型,发生在需要改变某段控制流时。(4)FCC:改变复合片段内部执行的条件,发生在改变当前控制流的执行条件时。
- 约束演化
约束演化包括Add Constraint(AC)、Delete Constraint(DC)。
(1)AC:直接添加新的约束信息,需判断当前设计是否满足新添加的约束要求。 (2)DC:直接移除某条约束信息,发生在去除某些不必要条件的时候。
12.3 软件架构演化方式的分类
【基础知识点】
三种比较典型的软件架构演化方式的分类,如图12.2所示
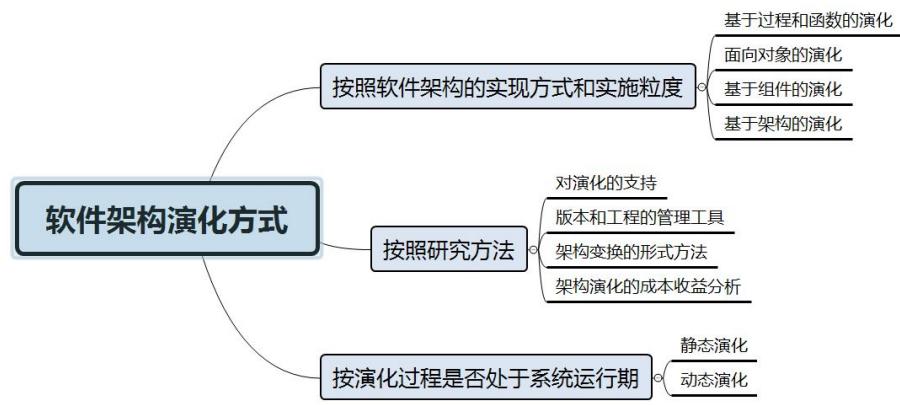
图12.2 软件架构演化方式分类
- 软件架构演化时期
(1)设计时演化:发生在体系结构模型与之相关的代码编译之前。 (2)运行前演化:发生在执行之前、编译之后。 (3)有限制运行时演化:只发生在某些特定约束满足时。 (4)运行时演化:发生在运行时不能满足要求时。
- 软件架构静态演化
(1)静态演化需求:设计时演化需求、运行前演化需求。(2)静态演化的一般过程:软件理解 $\twoheadrightarrow$ 需求变更分析 $\twoheadrightarrow$ 演化计划 $\twoheadrightarrow$ 系统重构 $\twoheadrightarrow$ 系统测试(3)静态演化的原子演化操作。
1)与可维护性相关的架构演化操作:AMD(Add Module Dependence)、RMD(Remove Module Dependence)、AMI(Add Module Interface)、RMI(Remove Module Interface)、AM(Add Module)、RM(Remove Module)、SM(Split Module)、AGM(Aggregate Modules)。
2)与可靠性相关的架构演化操作:AMS(Add Message)、RMS(Remove Message)、AO(Add Object)、RO(Remove Object)、AF(Add Fragment)、RF(Remove Fragment)、CF(Change Fragment)、AU(Add Use Case)、RU(Remove Use Case)、AA(Add Actor)、RA(Remove Actor)。
- 软件架构动态演化
(1)动态演化需求:软件内部执行所导致的体系结构改变、软件系统外部的请求对软件进行的重配置。
(2)动态演化的类型。
1)软件动态性的等级:交互动态性、结构动态性、架构动态性。 2)动态演化的内容:属性改名、行为变化、拓扑结构改变、风格变化。
(3)动态软件架构(DSA)。
1)基于DSA实现动态演化的基本原理是运行时刻体系结构相关信息的改变可用来触发、驱动系统自身的动态调整。 2)DSA描述语言:基于行为视角的 $\pi$ -ADL、基于反射视角的Pilar、基于协调视角的LIME。 3)DSA演化工具:使用反射机制、基于组件操作、基于 $\pi$ 演算、利用外部的体系结构演化管理器
(4)动态软件架构应用实例——PKUAS:包括容器系统、公共服务、工具和微内核4种类型。
(5)动态重配置。
1)动态重配置模式:主从模式、中央控制模式、客户端/服务器模式、分布式控制模式。 2)例子:可重用、可配置的产品线架构。 3)动态配置难点:约束定义困难、性能约束难以静态衡量、难以管理所有方面、需同时保证组件系统完整性和重配置策略的正确和安全性。
体系结构演化 是使用系统演化步骤去修改应用,以满足新的需求,主要包括以下6个步骤。 (1)需求变化归类首先必须对用户需求的变化进行归类,使变化的需求与已有构件对应。对找不到对应构件的变动,也要做好标记在后续工作中,将创建新的构件,以对应这部分变化的需求, (2)制订体系结构演化计划在改变原有结构之前,开发组织必须制订一个周密的体系结构演化计划,作为后续演化开发工作的指南。 (3)修改、增加或删除构件在演化计划的基础上,开发人员可根据在第1步得到的需求变动的归类情况,决定是否修改或删除存在的构件、增加新构件。最后,对修改和增加的构件进行功能性测试 (4)更新构件的相互作用随看构件的增加、删除和修改,构件之间的控制流必须得到更新 (5)构件组装与测试通过组装支持工具把这些构件的实现体组装起来,完成整个软件系统的连接与合成,形成新的体系结构。然后对组装后的系统整体功能和性能进行测试, (6)技术评审对以上步骤进行确认,进行技术评审。评审组装后的体系结构是否反映需求变动、符合用户需求。如果不符合,则需要在第2到第6步之间进行迭代。
12.4 软件结构演化原则
【基础知识点】
软件结构包括18种可持续演化原则:
(1)演化成本控制原则:演化成本要控制在预期的范围之内。 (2)进度可控原则:架构演化要在预期的时间内完成。 (3)风险可控原则:架构演化中的经济风险、时间风险、人力风险、技术风险和环境风险在可控范围内。 (4)主体维持原则:软件演化的平均增量的增长须保持平稳,保证软件系统主体行为稳定。 (5)系统总体结构优化原则:使演化后的软件系统整体结构(布局)更加合理。 (6)平滑演化原则:软件的演化速率趋于稳定。 (7)目标一致原则:架构演化的阶段目标和最终目标要一致。 (8)模块独立演化原则:软件中各模块自身的演化最好相互独立。 (9)影响可控原则:如果一个模块发生变更,给其他模块带来的影响在可控范围内。 (10)复杂性可控原则:必须控制架构的复杂性,保障软件的复杂性在可控范围内。 (11)有利于重构原则:使演化后软件架构便于重构。 (12)有利于重用原则:演化最好能维持,甚至提高整体架构的可重用性。 (13)设计原则遵循性原则:架构演化最好不能与架构设计原则冲突。 (14)适应新技术原则:软件要独立于特定的技术手段,可运行于不同平台。 (15)环境适应性原则:架构演化后的软件版本比较容易适应新的硬件环境和软件环境。 (16)标准依从性原则:演化不违背相关质量标准(国际标准、国家标准、行业标准等)。 (17)质量向好原则:使所关注的某个质量指标或质量指标的综合效果变更好。 (18)适应新需求原则:很容易适应新的需求变更。
12.5 软件架构演化评估方法
【基础知识点】
(1)演化过程已知的评估。
评估流程:将架构度量应用到演化过程中,通过对演化前后的不同版本的架构分别进行度量,得到度量结果的差值及其变化趋势,并计算架构间质量属性距离,进而对相关质量属性进行评估。
(2)演化过程未知的评估,其架构演化评估过程如图12.3所示。
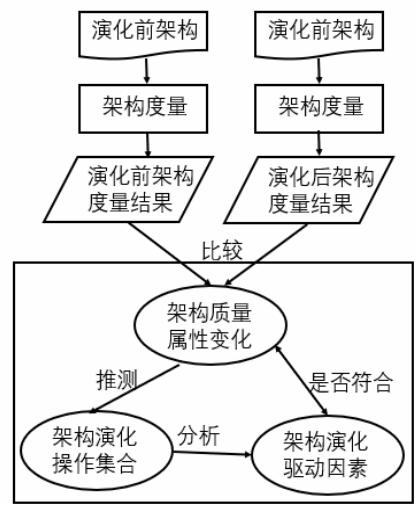
图12.3 演化过程未知时的架构演化评估过程示意图
12.6 大型网站系统架构演化实例
【基础知识点】
第一阶段:单体架构。
应用程序、数据库、文件等所有资源都在一台服务器上。
第二阶段:垂直架构。
将应用和数据分离,整个网站使用3台服务器:应用服务器、文件服务器、数据服务器。
第三阶段:使用缓存改善网站性能。
包括在应用服务器上的本地缓存和在专门的分布式缓存服务器上的远程缓存。
第四阶段:使用服务集群改善网站并发处理能力。
通过负载均衡调度服务器,将来自用户浏览器的访问请求分发到应用服务器集群中的任何一台服务器上,解决高并发、海量数据问题。
第五阶段:数据库读写分离。
应用服务器在写数据时,访问主数据库,主服务器通过主从复制机制将数据更新同步到从服务器。在应用服务器读数据时,访问从数据库。
第六阶段:使用反向代理和CDN加速网站响应。CDN和反向代理的基本原理都是缓存。
(1)CDN部署在网络提供商的机房,用户在请求网站服务时,可在距离最近的网络提供商机房获取数据。
(2)反向代理部署在网站的中心机房,用户请求到达中心机房后,先访问反向代理服务器。
第七阶段:使用分布式文件系统和分布式数据库系统。
进行业务分库,将不同业务的数据部署在不同的物理服务器上。
第八阶段:使用NoSQL和搜索引擎。
第九阶段:业务拆分。
将一个网站拆分成许多不同的应用,每个应用独立部署。
第十阶段:分布式服务。
12.7 软件架构维护
【基础知识点】
软件架构维护过程包括软件架构知识管理、软件架构修改管理、软件架构版本管理等。
(1)软件架构知识管理。
1)架构知识的定义:架构知识 $\equiv$ 架构设计 $^+$ 架构设计决策。
2)架构知识管理的含义:侧重于软件开发和实现过程所涉及的架构静态演化,在架构文档等信息来源中捕捉架构知识,提供架构的质量属性及其设计依据进行记录和评价。
3)架构知识管理的需求:防止关键的设计知识沉没在软件架构中。
(2)软件架构修改管理。
主要是建立一个隔离区域,保障该区域中任何修改对其他部分影响最小。
(3)软件架构版本管理。
为软件架构演化的版本演化控制、使用和评价提供可靠依据。
(4)软件架构可维护性度量实践。
架构可维护性的6个度量指标:圈复杂度(CNN)、扇入扇出度(FPC)、模块间耦合度(CBO)、模块的响应(RFC)、紧内聚度(TCC)、松内聚度(LCC)。
12.8 练习题
- 在软件系统的生命周期里,软件的演化速率趋于稳定,如相邻版本的更新率相对稳定。此描述是软件架构演化的( )原则。
A.主体维持 B.系统总体结构优化 C.平滑演化 D.目标一致
解析:主体维持原则:软件演化的平均增量的增长须保持平稳,保证软件系统主体行为稳定。系统总体结构优化原则:使演化后的软件系统整体结构(布局)更加合理。平滑演化原则:软件的演化速率趋于稳定。目标一致原则:架构演化的阶段目标和最终目标要一致。
答案:C
- 软件架构维护过程不包括()
A.架构知识管理 B.架构修改管理 C.架构版本管理 D.架构构件管理
解析:软件架构维护过程包括架构知识管理、架构修改管理、架构版本管理等。
答案:D
- 下列软件架构演化时期,()是在系统设计时规定了演化的具体条件,将系统置于“安全”模式下,演化只发生在某些特定约束满足时,可以进行一些规定好的演化操作。
A.设计时演化 B.运行前演化 C.有限制运行时演化 D.运行时演化
解析:设计时演化:发生在体系结构模型与之相关的代码编译之前;运行前演化:发生在执行之前、编译之后;有限制运行时演化:只发生在某些特定约束满足时;运行时演化:发生在运行不能满足要求时。
答案:C
- 根据所修改的内容不同,软件的动态演化不包括()
A.属性改名 B.行为变化 C.拓扑结构改变 D.格式变化
解析:动态演化的内容:属性改名、行为变化、拓扑结构改变、风格变化。
答案:D
第13小时 未来信息综合技术
13.0 章节考点分析
第13小时主要学习信息物理系统技术、人工智能技术、机器人技术、边缘计算、数字孪生体技术以及云计算和大数据技术等内容。
根据考试大纲,本小时知识点会涉及单项选择题(约占 $3\sim 5$ 分)和下午案例题(25分),论文也会有覆盖。本小时知识架构如图13.1所示。
图13.1 本小时知识架构
【导读小贴士】
近几年新技术发展提出了一些新概念、新知识、新产品,作为系统架构师需要掌握当前应用技术发展前沿。本章建议以读教材为主,课外多了解,以把握命题人对本章的出题思路。
13.1 信息物理系统技术概述
【基础知识点】
- 信息物理系统的概念
信息物理系统(Cyber-Physical System,CPS),最早由美国国家航空航天局于1992年提出,后科学家海伦·吉尔给出详细描述。信息物理系统是控制系统、嵌入式系统的扩展与延伸。CPS通过集成先进的感知、计算、通信、控制等信息技术和自动控制技术,构建了物理空间与信息空间中人、机、物、环境、信息等要素相互映射、适时交互、高效协同的复杂系统,实现系统内资源配置和运行的按需响应、快速迭代、动态优化。CPS的本质是构建一套信息空间与物理空间之间基于数据自动流动的状态感知、实时分析、科学决策、精准执行的闭环赋能体系,解决生产制造、应用服务过程中的复杂性和不确定性问题,提高资源配置效率,实现资源优化。
1)物理系统:由物理层、感应层(传感器)和执行层(执行器)组成 感应层(传感器):用于实时数据采集。 执行层(执行器):控制命令由相应的致动器执行,实现期望的物理动作 2)信息系统包:括网络层、决策层 决策层:负责接收传感器测量的数据。控制中心通过分析接收到的数据,做出相应的控制决策,保证物理过程的正确执行。 网络层:为决策层和物理系统提供通信平台。精确地说,传感器获得的测量数据通过通信网络传输到决策中心。控制信号或决策通过通信网络从决策中心传送到执行机构。
- CPS的实现
CPS的体系结构分为:单元级、系统级、SOS级。CPS技术体系主要包括CPS总体技术(顶层设计技术)、CPS支撑技术(基于应用支撑)、CPS核心技术(基础技术)。CPS技术了分为四大核心技术要素:“一硬”(感知和自动控制,是CPS实现的硬件支撑)、“一软”(工业软件,CPS核心)、“一网”(工业网络,是网络载体)、“一平台”(工业云和智能服务平台,是支撑上层解决方案的基础)。
- 信息物理系统的建设和应用
CPS典型应用场景有:
(1)智能设计方面:产品及工艺设计、生产线/工厂设计。 (2)智能生产方面:设备管理应用场景、生产管理应用场景、柔性制造应用场景。 (3)智能服务方面:健康管理、智能维护、远程征兆诊断、协同优化、共享服务。 (4)智能应用方面:无人装备、产业链互动、价值链共赢。
CPS的建设路径是:CPS体系设计、单元级CPS建设、系统级CPS建设、SOS级CPS建设。
13.2 人工智能技术概述
【基础知识点】
- 人工智能的概念
人工智能是利用数字计算机或数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。人工智能根据是否能真正实现推理、思考和解决问题,分为弱人工智能和强人工智能。
- 人工智能的发展历程
图灵测试 $\twoheadrightarrow$ “人工智能”术语 $\twoheadrightarrow$ 机器学习 $\twoheadrightarrow$ 专家系统 $\twoheadrightarrow$ 计算机战胜双晶棋世界冠军 $\twoheadrightarrow$ 决策树模型和神经网络 $\twoheadrightarrow$ IBM深蓝战胜国际象棋世界冠军 $\twoheadrightarrow$ 深度学习 $\twoheadrightarrow$ 爆发式发展。
- 人工智能关键技术
(1) 自然语言处理:包括机器翻译、语义理解、问答系统等。 (2) 计算机视觉:如自动驾驶、机器人、智能医疗。 (3) 知识图谱:可用于发欺诈、不一致性验证、组团欺诈等对公共安全保障形成威胁的领域。 (4) 人机交互:传统的基本交互、图形交互、语音交互、情感交互、体感交互及脑机交互等。 (5) 虚拟现实或增强现实:在一定范围内生成与真实环境在视觉、听觉等方面高度近似的数字化环境。 (6) 机器学习。 1)按学习模式不同分为监督学习(需提供标注的样本集)、无监督学习(不需提供标注的样本集)、半监督学习(需提供少量标注的样本集)、强化学习(需反馈机制)。 2)按学习方法不同分为传统机器学习(需手动完成)、深度学习(需大量训练数据集和强大GPU服务器提供算力)。 3)机器学习常见算法:迁移学习、主动学习、演化学习。
| 技术方案 | 英文全称 | 核心思想 | 典型作用 | 优点 | 局限性 | 典型应用场景 |
|---|---|---|---|---|---|---|
| 大模型(LLM) | Large Language Model | 通过大规模语料预训练,具备强大的自然语言理解与生成能力 | 生成文本、总结、翻译、问答 | 通用性强、语言理解好 | 缺乏实时性与知识准确性,容易“幻觉” | 智能客服、报告生成、聊天问答 |
| 提示词(Prompt) | Prompt Engineering | 通过优化输入提示,引导大模型输出更符合需求的内容 | 提问设计、任务约束、风格控制 | 成本低、实现快 | 效果依赖提示质量 | 编写报告摘要、规范化生成内容 |
| 智能体(AI Agent) | Artificial Intelligence Agent | 具备自主任务执行与决策能力,可调用工具、记忆与环境交互 | 任务自动化、协作执行 | 自主性强,可持续运行 | 实现复杂、依赖多组件协作 | 自动会议纪要、邮件分类、数据处理 |
| MCP(模型控制协议) | Model Control Protocol | 定义模型与外部系统通信的统一接口协议,实现跨系统协同 | 调用不同模型、服务互联 | 扩展性强、兼容多模型 | 需标准化接入、系统复杂 | 企业内部模型集成、API 调度 |
| 检索增强生成(RAG) | Retrieval-Augmented Generation | 在生成前检索外部知识库,使模型基于事实回答问题 | 文档问答、知识更新 | 减少幻觉、提升准确性,不会改变模型本身,成本较低,需要构建和维护一个外部知识库 | 检索质量影响结果 | 企业知识库问答、资料查询系统 |
| 模型微调(Fine-tuning) | Model Fine-tuning | 在预训练模型基础上,使用特定领域数据进行再训练,使模型更贴合特定任务或语气 | 定制化输出、行业专用模型 | 精度高、个性化强.会改变模型本身,成本较高,需要准备好训练数据集。 | 成本较高、需大量高质量数据 | 行业专用问答、品牌定制AI助手、语气风格训练 |
RAG技术
AI芯片主要有三种技术架构 第一种是GPU,可以高效支持AI 应用的通用芯片,但是相对于FPGA和ASIC来说,价格和功耗过高; 第二种是FPGA(现场可编程门阵列),可对芯片硬件层进行编程和配置,实现半定制化,相对于GPU有更低的功耗: 第三种是ASIC(专用集成电路),专门为特定的 AI产品或者服务而设计,主要是侧重加速机器学习(尤其是神经网络、深度学习),它针对特定的计算网络结构采用了硬件电路实现的方式,能够在很低的功耗下实现非常高的能效比,这也是目前AI芯片中最多的形式。答案选择A选项。
AI芯片的特点包括:新型计算范式
AI芯片的关键特征: 1)新型的计算范式 AI计算既不脱离传统计算,也具有新的计算特质,如处理的内容往往是非结构化数据(视频、图片等)。处理的过程通常雲要很大的计算量,基本的计算主要是线性代数运算,而控制流程则相对简单。处理的过程参数量大。 2)训练和推断 AI 芯片通常涉及训练和推断过程。简单来说,训练过程是指在已有数据中学习,获得某些能力的过程;而推断过程则是指对新的数据,使用这些能力完成特定任务(比如分类、识别等)。 3)大数据处理能力 人工智能的发展高度依赖海量的数据。满足高效能机器学习的数据处理要求是A 芯片需要考虑的最重要因素。 4)数据精度 低精度设计是A1芯片的一个趋势,在针对推断的芯片中更加明显。对一些应用来说,降低精度的设计不仅加速了机器学习算法的推断(也可能是训练),甚至可能更符合神经形态计算的特征。 5)可重构的能力 针对特定领域而不针对特定应用的设计,将是A! 芯片设计的一个指导原则,具有可重构能力的A1 芯片可以在更多应用中大显身手,并且可以通过重新配置,适应新的AI算法、架构和任务, 6)开发工具 就像传统的CPU需要编译工具的支持, A1 芯片也需要软件工具链的支持,才能将不同的机器学习任务和神经网络转换为可以在AI 芯片上高效执行的指令代码。
13.3 机器人技术概述
【基础知识点】
- 机器人的定义和发展历程
(1)定义:具体脑、手、脚等三要素个体;具有非接触传感器和接触传感器;具有平衡觉和固定觉的传感器。(2)发展历程:第一代机器人(示教再现型机器人) $\twoheadrightarrow$ 第二代机器人(感觉型机器人) $\twoheadrightarrow$ 第三代机器人(智能型机器人)。
- 机器人4.0核心技术
机器人4.0核心技术包括云一边一段的无缝协同计算、持续学习与协同学习、知识图谱、场景自适应和数据安全。
- 机器人分类
(1)按控制方式分类包括:操作机器人、程序机器人、示教再现机器人、智能机器人和综合机器人。(2)按应用行业分类包括:工业机器人、服务机器人、特殊领域机器人。
13.4 边缘计算
【基础知识点】
- 边缘计算概念
边缘计算就是将数据的处理、应用程序的运行以及一些功能服务的实现,由网络中心下放到网络边缘节点上。关于边缘计算的具体定义目前有以下几种观点: (1)边缘计算产业联盟对边缘计算的定义:云计算在数据中心之外汇聚节点的延伸和演进,包括云边缘、边缘云和云化网关三类落地形态;以“边云协同”和“边缘智能”为核心和发展方向。 (2)OpenStack社区的定义概念:为应用开发者和服务提供商在网络边缘侧提供云服务和IT环境服务,目标是在靠近数据输入或用户的地方提供计算、存储和网络带宽。 (3)ISO/IEC JTC1/SC38对边缘计算给出的定义:在靠近物或数据源头的网络边缘侧,融合网络、计算、存储、应用核心能力的开放平台,就近提供边缘智能服务。 (4)国际标准组织定义:提供移动网络边缘IT服务和计算能力,靠近移动用户。
- 边缘计算的特点
边缘计算的特点包括联接性、数据第一入口、约束性、分布性。具体内容如下:
(1)联接性:所联接物理对象的多样性及应用场景的多样性,需要边缘计算具备丰富的联接功能,如各种网络接口、网络协议等。 (2)数据第一入口:边缘计算拥有大量、实时、完整的数据,可基于数据全生命周期进行管理与价值创造,将更好地支撑预测性维护、资产效率与管理等创新应用。 (3)约束性:边缘计算产品需适配工业现场相对恶劣的工作条件与运行环境。在工业互联场景下,对边缘计算设备的功耗、成本、空间也有较高的要求。边缘计算产品需要考虑通过软硬件集成与优化,以适配各种条件约束,支撑行业数字化多样性场景。 (4)分布性:边缘计算实际部署天然具备分布式特征。这要求边缘计算支持分布式计算与存储、实现分布式资源的动态调度与统一管理、支撑分布式智能、具备分布式安全等能力。
- 边云协同
(1)资源协同:边缘节点提供计算、存储、网络、虚拟化等基础设施资源,具有本地资源调度管理能力,同时可与云端协同,接受并执行云端资源调度管理策略,包括边缘节点的设备管理、资源管理以及网络连接管理。 (2)数据协同:边缘节点主要负责现场/终端数据的采集,按照规则或数据模型对数据进行初步处理与分析,并将处理结果以及相关数据上传给云端;云端提供海量数据的存储、分析与价值挖掘。边缘与云的数据协同,支持数据在边缘与云之间可控有序流动,形成完整的数据流转路径,高效低成本对数据进行生命周期管理与价值挖掘。 (3)智能协同:边缘节点执行推理,实现分布式智能;云端开展模型训练,并将模型下发边缘节点。 (4)应用管理协同:边缘节点提供应用部署与运行环境,并对本节点多个应用的生命周期进行管理调度;云端主要提供应用开发、测试环境,以及应用的生命周期管理能力。 (5)业务管理协同:边缘节点提供模块化、微服务化的应用/数字孪生/网络等应用实例;云端主要提供按照客户需求实现应用/数字孪生/网络等的业务编排能力。 (6)服务协同:边缘节点按照云端策略实现部分ECSaaS服务,通过ECSaaS与云端SaaS的协同实现面向客户的按需SaaS服务;云端主要提供SaaS服务在云端和边缘节点的服务分布策略,以及云端承担的SaaS服务能力。
- 边缘计算的安全
边缘安全的价值体现在:提供可信的基础设施、为边缘应用提供可信赖的安全服务、提供安全可信的网络和覆盖。
- 边缘计算应用场合
边缘计算应用场合包括智慧园区、安卓云与云游戏、视频监控、工业物联网、Cloud VR。
13.5 数字孪生体技术概述
【基础知识点】
- 数字孪生体的定义
数字孪生体是现有或将有的物理实体对象的数字模型,通过实测、仿真和数据分析来实时感知、诊断、预测物理实体对象的状态,通过优化和指令来调控物理实体对象的行为,通过相关数字模型间的相互学习来进化自身,同时改进利益相关方在物理实体对象生命周期内的决策。
- 数字孪生体的关键技术
数字孪生体的核心技术:建模、仿真和基于数据融合的数字线程。
- 数字孪生体的应用
数字孪生体主要应用于制造、产业、城市和战场。
数字孪生生态系统由基础支撑层、数据互动层、模型构建与仿真分析层、共性应用层和行业应用层组成。 1)基础支撑层由具体的设备组成,包括工业设备、城市建筑设备、交通工具、医疗设备组成。 2)数据互动层包括数据采集、数据传输和数据处理等内容。 3)模型构建与仿真分析层包括数据建模、数据仿真和控制。 4)共性应用层包括描述、诊断、预测、决策四个方面。 5)行业应用层则包括智能制造、智慧城市在内的多方面应用。
13.6 云计算和大数据技术概述
【基础知识点】
(1)云计算技术概述:“云计算”是同时描述一个系统平台或一类应用程序的术语,包含平台和应用。
(2)云计算的服务方式与部署模式。云计算的服务方式有:
1)软件即服务(SaaS):服务提供商将应用软件统一部署在云计算服务器上。 2)平台即服务(PaaS):服务提供商将分布式开发环境与平台作为一种服务来提供。 3)基础设施即服务(IaaS):服务提供商将多台服务器组成“云端”基础设施作为计量服务提供给客户。
云计算的部署模式:公有云、社区云、私有云、混合云。
(3)大数据分析步骤:数据获取/记录 $\twoheadrightarrow$ 信息抽取/清洗/注记 $\twoheadrightarrow$ 数据集成/聚集/表现 $\twoheadrightarrow$ 数据分析/建模 $\twoheadrightarrow$ 数据解释。
(4)大数据应用领域:制造业、服务业、交通行业、医疗行业。
目前比较常见的三种虚拟化技术: 1、OpenVz,操作系统级别的虚拟化技术,配置起来比较灵活; 2、Xen,是半虚拟化技术,可以自由加载内核模块,虚拟内存和I0; 3、KVM,完全虚拟的,支持任何类型的操作系统。
13.7 物联网
物联网应用的典型架构分为三层,这三层分别是: 1)感知层:也被称为物理层,主要负责收集和感知外界环境或监测对象的信息。这一层通常包括各种传感器、RFID标签、摄像头等信息采集设备,它们负责收集温度、湿度、光照强度、位置、图像等各类数据。 2)网络传输层:负责将感知层收集到的数据通过有线或无线网络传输到数据处理中心。这一层包括各种通信技术,如Wi-Fi、蓝牙、Zigbee、LoRa、NB-IoT、5G等,用于实现数据的安全、可靠传输。 3)应用层:这是物联网系统的最高层,负责数据的处理、分析和应用展现。应用层可以是各种基于物联网数据的智能应用,如智能家居、智慧城市、工业监控、健康监测等。这一层通过数据分析和处理,实现对感知数据的智能化识别、定位、跟踪、监管等功能,从而为用户提供有价值的服务。
13.8 练习题
- CPS技术体系的四大核心技术要求中“一平台”是()。
A.感知和自动控制 B.工业软件 C.工业网络 D.工业云和智能服务平台
解析:CPS技术分为四大核心技术要素:“一硬”(感知和自动控制,是CPS实现的硬件支撑)、“一软”(工业软件,CPS核心)、“一网”(工业网络,是网络载体)、“一平台”(工业云和智能服务平台,是支撑上层解决方案的基础)。
答案:D
- 人工智能的关键技术包括自然语言处理、计算机视觉、知识图谱、机器学习。机器学习分类中()是利用已标记的有限训练数据集,通过某种学习策略/方法建立一个模型,从而实现对新数据/实例标记/映射。
A.监督学习 B.无监督学习 C.半监督学习 D.强化学习
解析:按学习模式不同分为监督学习(需提供标注的样本集)、无监督学习(不需提供标注的样本集)、半监督学习(需提供少量标注的样本集)、强化学习(需反馈机制)。
答案:A
- 云计算的服务方式不包括(
A.软件即服务 B.计算即服务 C.平台即服务 D.基础设施即服务
解析:云计算的服务方式包括:
(1)软件即服务(SaaS):服务提供商将应用软件统一部署在云计算服务器上。(2)平台即服务(PaaS):服务提供商将分布式开发环境与平台作为一种服务来提供。(3)基础设施即服务(IaaS):服务提供商将多台服务器组成“云端”基础设施作为计量服务提供给客户。
答案:B
第14小时 系统规划
14.0 章节考点分析
第14小时主要了解系统规划知识,此部分考点非常少,因此不作为重点掌握的知识。本小时知识架构如图14.1所示。
图14.1 本小时知识架构
【导读小贴士】
系统规划属于信息系统生命周期的第一个阶段,其任务是对企业的环境、目标及现有系统的状况进行初步调查,研究建设新系统的必要性和可能性。根据需要与可能,给出拟建系统的备选方案。对这些方案进行可行性分析,写出可行性研究报告。可行性研究报告审议通过后,将新系统建设方
案及实施计划编写成系统设计任务书。
14.1 系统规划概述
【基础知识点】
系统规划的主要步骤包括:
(1)对现有系统进行初步调查。(2)分析和确定系统目标。(3)分析子系统的组成和基本功能。(4)拟定系统的实施方案。(5)进行系统的可行性研究,编写可行性研究报告,召开可行性论证会。(6)制订系统建设方案。
14.2 系统调查
【基础知识点】
系统调查可以分为初步调查与详细调查两个阶段。
(1)初步调查。在规划阶段进行初步调查可了解企业的组织结构和系统功能等。具体包括:初步需求分析、企业基本状况、管理方式和基础数据管理状况、现有系统状况。
(2)详细调查。详细调查则可以深入了解系统的处理流程。调查的内容有:现有系统的运行环境和状况、组织结构、业务流程、系统功能、数据资源与数据流程、资源情况、约束条件和薄弱环节等。
14.3 成本效益分析技术
【基础知识点】
- 成本
按照成本性态分类,可以分为固定成本、变动成本和混合成本。
(1)固定成本:是指其总额在一定时期和一定业务量范围内,不受业务量变动的影响而保持固定不变的成本。如管理人员的工资、办公费、固定资产折旧费、员工培训费等。
(2)变动成本:也叫可变成本,指在一定时期和一定业务量范围内其总额随着业务量的变动而成正比例变动的成本。如直接材料费、产品包装费、外包费用、开发奖金等。
(3)混合成本:即混合了固定成本和变动成本的性质的成本。这些成本通常有一个基数,超过这个基数就会随业务量的增大而增大。如质量保证人员的工资、设备动力费等成本在一定业务量内是不变的,超过了这个量便会随业务量的增加而增加。
- 盈亏临界点
盈亏临界点也称盈亏平衡点或保本点,是指项目收入和成本相等的经营状态,就是既不盈利又不亏损的状态。相关公式如下:
(1)利润 $=$ (销售单价-单位变动成本) $\times$ 销售量-总固定成本。(2)盈亏临界点销售量 $=$ 总固定成本/(销售单价-单位可变成本)。(3)盈亏临界点销售额 $=$ 总固定成本/(1-总可变成本/销售收入)。
14.4 练习题
- ()的内容是调查现有系统的运行环境和状况、组织结构、业务流程、系统功能等。
A.初步调查 B.详细调查 C.系统调查 D.可行性研究
解析:详细调查可以深入了解系统的处理流程。调查的内容有:现有系统的运行环境和状况、组织结构、业务流程、系统功能、数据资源与数据流程、资源情况、约束条件和薄弱环节等。
答案:B
- 管理人员的工资属于()
A.固定成本 B.混合成本 C.变动成本 D.长期成本
解析:固定成本是指其总额在一定时期和一定业务量范围内,不受业务量变动的影响而保持固定不变的成本。如管理人员的工资、办公费、固定资产折旧费、员工培训费等。
答案:A
- 某厂生产的某种电视机,销售价为每台2500元,去年的总销售量为25000台,固定成本总额为250万元,可变成本总额为4000万元,税率为 $16%$ ,则该产品年销售量的盈亏平衡点为()台(只有在年销售量超过它时才能盈利)。
A.5000 B.10000 C.15000 D.20000
解析:设销售量达到盈亏平衡点时的销售量为 $N$ ,每台电视机的可变成本为 $4000 / 2.5 = 1600$ 元,总收入是 $0.25N\times (1 - 16%) = 0.21N$ 。根据公式:盈亏临界点销售量 $\coloneqq$ 总固定成本/(销售单价- 单位可变成本),将公式变形:盈亏临界点销售量 $\times$ 销售单价 $\coloneqq$ 总固定成本 $^+$ 盈亏临界点销售量 $\times$ 单位可变成本。则有 $0.21N = 250 + 0.16N$ ,解得 $N$ 为5000。
答案:A
第4篇 架构设计实践知识
第15小时 信息系统架构设计理论与实践
15.0 章节考点分析
第15小时主要学习信息系统架构设计的理论和工作中的实践。根据考试大纲,本小时知识点会涉及单项选择题(约占 $3\sim 5$ 分)和下午案例题(25分),论文也会有涉及。本章节内容理论性较强,较多内容适合作为论文写作素材。本小时内容侧重于知识点记忆和理解,按照以往的考查规律,信息系统架构设计基础知识点基本来源于教材内,偶尔有超出教材的考查内容也是基于对教材内知识点的理解。本小时知识架构如图15.1所示。
图15.1 本小时知识架构
【导读小贴士】
信息系统架构(Information System Architecture,ISA)是一种总体架构,其自顶向下体现政府、企(事)业单位的信息系统的各个组成部分和各部分之间的关系,表现为信息系统与相关业务的关系,体现了信息系统与信息技术的关系,是展示了信息、技术与企业及其业务之间关系的模型。
15.1 基本概念
【基础知识点】
- 信息系统架构定义
目前关于信息系统架构较为权威的定义有:
(1)信息系统架构是系统的结构,由软件元素、元素外部可见属性和元素间关系组成。(2)信息系统架构是软件系统结构、行为和属性的高级抽象,由系统元素描述、元素间相互作用、元素集成模式及模式约束组成。(3)信息系统架构是系统的基础组织,体现为构件、构件间关系、构件和环境间关系、构件设计和演进的原则。
对于定义的理解:
(1)架构是系统的抽象:元素、元素外部可见属性和元素间关系反映系统的抽象。(2)架构是结构的组合:结构从功能角度描述元素间关系。(3)系统必然存在架构:无论是否存在抽象、模型和具体的描述文档。(4)架构是元素的集合:元素组成系统,元素外部可见属性表现系统功能,元素间关系表现系统对外部刺激的响应;从静态角度,架构关注系统的总体结构(模式);从动态角度,架构关注系统行为的共同特征。(5)架构具有基础特性:架构具有重复性问题的通用解决方案的复用性,架构在系统设计过程中通过设计决策对系统造成深远影响,这种影响反映架构敏感。(6)架构隐含设计决策:架构是对关键功能和非功能性需求进行设计与决策的最终设计结果。
- 信息系统架构的影响
影响架构的因素有:
(1)外部干系人:对系统有不同的关注和需求。(2)内部干系人:知识结构、素质、经验、技术环境影响需求和设计。架构对影响因素也具有反作用: (1)影响外部干系人:业务影响组织结构。(2)影响内部干系人:架构具有示范性、复用性,提供商机。
15.2 信息系统架构风格与分类
【基础知识点】
- 信息系统架构风格
信息系统架构遵循通用的架构风格,详见第9小时相关内容,这里不再赘述。
- 数据流体系结构风格:批处理,管道-过滤器。
- 调用/返回体系结构风格:主程序/子程序,面向对象,层次结构。
- 独立构件体系结构风格:进程通信,事件系统。
- 虚拟机体系结构风格:解释器,规则系统。
- 仓库体系结构风格:数据库,超文本,黑板。
- 信息系统架构分类
(1)信息系统物理结构包括: ①单体应用; ②分布式结构。 (2)信息系统逻辑结构如下所述。1)横向综合:将同一管理层次的各个业务职能综合到一起。2)纵向综合:将同一业务的各个管理层次智能综合到一起。3)纵横综合:将各个业务的各个管理层次统一综合到一起,主要从信息模型和处理模型两方面着手,建立公用的数据库和统一的信息处理系统。
15.3 信息系统常用架构模型
【基础知识点】
- 单体应用
单体应用指运行在单台物理机器上的独立应用程序。应用领域就是信息系统领域,也就是以数据处理为核心的系统。
- 客户机/服务器
客户机/服务器是信息系统中最常见的模式,这种模式下客户端和服务器间通过TCP/UDP进行请求和应答。常见的客户机/服务器形式有以下几种:
(1)二层C/S(Client/Server)。这是一种胖客户端,主要是指前台客户端 + 后台数据库的形式。如图15.2所示。
(2)三层C/S和B/S(Browser/Server) 如下所述。
1)三层C/S:前台客户端 + 后台服务端 + 后台数据库,如图15.3所示。
图15.2 客户端/服务器胖客户端架构图
图15.3 客户端/服务器三层架构图
2)瘦客户端:前台界面和业务逻辑处理分离,前台客户端仅含前台界面。
3)三层B/S:Web浏览器 + Web服务器 + 后台数据库。
B/S本质是浏览器与服务器间采用基于TCP/IP或UDP的HTTP协议。前台客户端与后台服务端通信协议有:TCP/IP协议,基于TCP/IP协议通过Socket自定义实现的协议,RPC协议,CORBA/IIOP协议,JavaRMI协议,J2EE JMS协议,HTTP协议。
(3)多层C/S和B/S结构。
1)多层C/S:是指三层以上的结构,如图15.4所示。形式是前台客户端 $+$ 后台服务端 $+$ 中间件/应用层 $+$ 数据库,其中,中间件/应用层的作用有以下3点: $①$ 提高并发性能和可伸缩性; $(2)$ 请求转发,业务逻辑处理; $(3)$ 增加数据安全性。

图15.4客户端/服务器多层架构
2)多层B/S:是指三层以上的结构,形式是Web浏览器 $+$ Web服务器 $+$ 中间件/应用层 $+$ 数据库。
(4)模型-视图-控制器(Model-View-Controller,MVC)。在J2EE架构中,形式是:Web浏览器(View) $+$ Web服务器(Controller) $+$ 数据库,关于模型层可根据实际情况与MV一起置于Web服务器,或单独置于应用层。
在一个典型的基于MVC的J2EE应用中,系统的界面由JSP构件实现,分发客户请求、有效组织其他构件为客户端提供服务的控制器由Servlet 构件实现,数据库相关操作由Entity Bean构件实现,系统核心业务逻辑由Session Bean 构件实现。
- 面向服务架构(SOA)
在SOA中服务的概念是指能提供一组整体功能的独立应用系统。这个应用系统被去掉任何一层服务,都将不能正常工作。在实践中,要实现SOA可以借助诸如消息中间件、交易中间件等中间件来实现。SOA的应用模式最典型、最流行的就是WebService,即两个互联网应用之间可以互相向对方开放一些功能模块、函数、过程等“服务”,然后通过消息机制或远程过程调用(RemoteProcedureCall,RPC)这样的中间件去调用对方的服务。面向服务架构主要实践有异构系统集成、同构系统聚合、联邦架构等。
- 企业服务总线(ESB)/企业数据总线(EDB)
企业总线是企业应用间信息交换的公共通道,具有如下特征:
1)连接软件系统,主要提供服务代理功能和服务注册表。 2)按照协议消息头进行数据、请求、回复的接收和分发。 3)可以基于消息中间件、事务中间件、CORBA/IIOP协议开发构建。
15.4 企业信息系统总体框架
【基础知识点】
- 基本概念
信息系统的架构(Information System Architecture,ISA)是多维度、分层次、高度集成化的模型。
组织信息化需求通常包含三个层次,其中战略需求的目标是提升组织的竞争能力,为组织的可持续发展提供支持环境。运作需求包含实现信息化战略目标的需求、运营策略的需求和人才培养的需求等三个方面。技术需求主要强调在信息层技术层面上对系统的完善、升级、集成和整合提出的需求。
- 信息系统的架构内容
要在企业中建立一个有效集成的ISA,必须考虑企业中的4个方面:战略系统、业务系统、应用系统和企业信息基础设施。
(1)战略系统。战略系统是指企业中与战略制定、高层决策有关的管理活动和计算机辅助系统。战略系统由企业战略规划体系、以计算机为基础的高层决策支持系统组成。战略系统是信息系统对企业高层管理者决策支持的能力,也是企业战略规划对信息系统建设的影响和要求。企业战略可以分为长期与短期两种,长期规划较为稳定,如调整产品结构。而短期规划适用于如决定新产品的类型的情况。
(2)业务系统。是指企业中完成一定业务功能的各个部分组成的系统,其中的功能通过一些业务过程来完成,业务过程由一系列相互依赖的业务活动、业务活动先后次序、业务活动执行角色、业务活动处理相关数据组成。业务系统的作用有: $(1)$ 对企业现有业务系统,过程,活动建模; $(2)$ 在企业战略指导下,采用业务过程重组优化业务过程; $(3)$ 对企业优化业务系统,过程,活动建模; $(4)$ 确定相对稳定数据; $(5)$ 以稳定数据为基础,进行应用系统开发和信息基础设施建设。
(3)应用系统。应用系统是指信息系统中的应用软件部分。应用系统包括内部功能和外部界面两个部分。界面部分是应用系统中相对变化较多的部分,主要由用户对界面形式要求的变化引起;功能实现部分中,相对来说处理的数据变化较小,而程序的算法和控制结构的变化较多,主要由用户对应用系统功能需求的变化和对界面形式要求的变化引起。
(4)企业信息基础设施。企业信息基础设施(Enterprises Information Infrastructure,EII)是指根据企业当前业务和可预见的发展趋势,及对信息采集、处理、存储和流通的要求,构筑由信息设备、通信网络、数据库、系统软件和支持性软件等组成的环境。
15.5 信息系统架构设计方法(关键成功因素法)
【基础知识点】
- TOGAF架构框架
TOGAF是国际权威组织TheOpenGroup(TOG)制订的企业架构标准框架。TOGAF目标有4个:
(1)节省时间和成本,更有效、合理地利用资源。
(2)实现可观的投资回报率。
(3)确保从关键利益相关方到团队成员的所有用户都使用相同的语言。
(4)避免被锁定到企业架构的专有解决方案。
TOGAF的核心思想是模块化架构,为架构产品提供内容框架,为大型组织开发提供扩展指南,适用于不同架构风格。
TOGAF的组件有架构开发方法、架构开发方法指南和技术、架构内容框架、企业连续序列和工具、架构框架参考模型、架构能力框架。
- 架构开发方法
架构开发方法(Architecture Development Method,ADM) 由一组按照架构领域的架构开发顺序而排列成一个环的多个阶段所构成。这些阶段是:预备、需求管理、架构愿景、业务架构、信息系统架构、技术架构、机会和解决方案、迁移规划、实施治理、架构变更管理。
- 信息化内容与模式
信息化包括4个方面的内容:信息网络体系、信息产业基础、社会运行环境、效用积累过程。
信息化具有6个要素:开发利用信息资源、建设国家信息网络、推进信息技术应用、发展信息技术和产业、培育信息化人才、制订和完善信息化政策。
通常信息化包括了7个平台:知识管理平台、日常办公平台、信息集成平台、信息发布平台、协同工作平台、公文流转平台、企业通信平台。
企业集成平台是一个支持复杂信息环境下信息系统开发、集成、协同运行的软件支撑环境,包括硬件、软件、软件工具和系统。基本功能包括: ①通信服务:提供分布环境下透明的同步/异步通信服务功能; ②信息集成服务:为应用提供透明的信息访问服务,实现异种数据库系统之间数据的交换、互操作、分布数据管理和共享信息模型定义: ③应用集成服务:通过高层应用编程接口来实现对相应应用程序的访问,能够为应用提供数据交换和访问操作,使各种不同的系统能够相互协作; ④二次开发工具:是集成平台提供的一组帮助用户开发特定应用程序的支持工具; ⑤平台运行管理工具:是企业集成平台的运行管理和控制模块。
信息化也具有9个特征:易用性、健壮性、平台化、灵活性、扩展性、安全性、门户化、整合性、移动性。
信息化架构具有两种模式:
(1)数据导向架构。关注数据模型和数据质量。
(2)流程导向架构。关注端到端流程整合及对流程变化的适应度。
- 信息化建设生命周期
信息化建设生命周期具体分为:系统规划、系统分析、系统设计、系统实施、系统运行和维护几个阶段。
- 信息化工程总体规划方法
| 方法名称 | 英文全称 | 核心思想 / 要点 | 优点 | 缺点 | 记忆关键词 |
|---|---|---|---|---|---|
| 关键成功因素法 (CSF) | Critical Success Factors | 从组织目标出发,识别影响目标实现的关键成功因素,提炼关键信息需求 | 抓住主要矛盾,突出重点;经理熟悉,易于接受 | 随环境和时期变化需不断重新识别,稳定性不足 | 抓重点 |
| 战略目标集转化法 (SST) | Strategy Set Transformation | 将组织使命、目标、战略转化为信息系统目标的结构化方法 | 目标全面,考虑多方需求,疏漏较少 | 突出重点的能力不如 CSF,可能导致冗余 | 全覆盖 |
| 企业系统规划法 (BSP) | Business System Planning | 自上而下识别目标/过程/数据,再自下而上设计系统;通过过程与数据分析推导系统目标 | 保证企业目标与系统目标一致;信息一致性好;适应组织变化 | 过程复杂,目标导向不明显,对人员要求高 | 自上而下+自下而上 |
| 企业信息分析与集成技术 (BIAIT) | Business Information Analysis & Integration Technology | 通过分析企业信息资源,强调集成与整体规划 | 系统性强,适合大型复杂企业 | 技术要求高,实施难度大 | 信息集成 |
| 产出/方法分析 (E/MA) | Ends/Means Analysis | 通过分析“产出”和“方法”的关系来确定系统目标和过程 | 思路清晰,目标与方法对应关系直观 | 对复杂组织可能不够细致,容易遗漏 | 产出-方法 |
| 投资分析法 (Investment/Chargout) | — | 从投资回报和成本角度分析信息系统建设的可行性和优先级 | 强调经济效益,便于资金决策 | 可能忽视非经济性目标(如战略价值) | 算钱 |
| 零基预算卡法 | Zero-based Budgeting Card | 以零为基点重新规划和分配预算,确保资源分配合理性 | 有助于控制成本,避免资源浪费 | 工作量大,执行成本高 | 从零开始 |
| 阶石法 | Step Stone Method | 将规划过程划分为逐步推进的阶段,每一步都是后续的基础 | 实施渐进,风险可控 | 周期长,整体效率较低 | 一步一步 |
(1)关键成功因素法(Critical Success Factors,CSF)。关键成功因素指的是对企业的成功起关键作用的因素。CSF就是通过分析找出使得企业成功的关键因素,然后再围绕这些关键因素来确定系统的需求,并进行规划。通过分析找出使得企业成功的关键因素,然后再围绕这些关键因素来确定系统的需求,并进行规划。在现行系统中,总存在着多个变量影响系统目标的实现,其中若干个因素是关键的和主要的(即关键成功因素)。通过对关键成功因素的识别,找出实现目标所需的关键信息集合,从而确定系统开发的优先次序。关键成功因素来自于组织的目标,通过组织的目标分解和关键成功因素识别、性能指标识别,一直到产生数据字典。
(2)战略目标集转化法(Strategy Set Transformation,SST)。SST反映了各种人的要求,而且给出了按这种要求的分层,然后转化为信息系统目标的结构化方法。将整个过程看成是一个“信息集合”,并将组织的战略目标转变为管理信息系统的战略目标。
(3)企业系统规划法(Business System Planning,BSP)。BSP通过自上而下地识别系统目标、企业过程和数据,然后对数据进行分析,自下而上地设计信息系统。
15.6 练习题
- 在信息化工程总体规划的方法论中,()是通过分析找出使得企业成功的关键因素,然后再围绕这些关键因素来确定系统的需求,并进行规划。
A.战略目标集转化法 B.关键成功因素法 C.企业系统规划法 D.信息系统工程法
解析:关键成功因素指的是对企业的成功起关键作用的因素。关键成功因素法就是通过分析找出使得企业成功的关键因素,然后再围绕这些关键因素来确定系统的需求,并进行规划。
答案:B
- 信息化建设生命周期的顺序是()
A. 系统设计、系统分析、系统规划、系统实施、系统运行和维护
B. 系统规划、系统分析、系统设计、系统实施、系统运行和维护
C. 系统规划、系统分析、系统设计、系统实施、系统运行和维护
D. 系统分析、系统规划、系统设计、系统实施、系统运行和维护
解析:信息化建设生命周期是:系统规划、系统分析、系统设计、系统实施、系统运行和维护几个阶段。
答案:C
- 请列举信息系统架构中较为常用的架构模型
解析:传统的信息系统架构中架构模型主要关注应用系统架构,典型的应用系统架构包括单体应用、二层/三层/多层的客户端/服务器或浏览器/服务器以及面向服务几种架构模式。在企业应用中,复杂的面向服务架构会加重信息系统开发和管理负担,为了规避成本问题,多采用企业服务总线或企业数据总线架构模式。
答案:单体应用架构,二层客户端/服务器架构,三层客户端/服务器架构,三层浏览器/服务器架构,多层客户端/服务器架构,面向服务的架构,企业服务总线。
- 企业服务总线(ESB)是企业应用间信息交换的公共通道,请简述它的特征。
答案:企业服务总线是企业应用间信息交换的公共通道,具有如下特征:
(1)连接软件系统,主要提供服务代理功能和服务注册表。(2)按照协议消息头进行数据、请求、回复的接收和分发。(3)可以基于消息中间件、事务中间件、CORBA/IOP协议开发构建。
第16小时 层次式架构设计理论与实践
16.0 章节考点分析
第16小时主要学习层次式架构设计理论与实践。根据考试大纲,本小时知识点会涉及单选题型(约占$2\sim 5$分)和案例题(25分),本小时内容偏重于方法的掌握和应用,根据以往全国计算机技术与软件专业技术资格(水平)考试的出题规律,概念知识的考查内容多数来源于实际应用,还需要灵活运用相关知识点。本小时知识架构如图16.1所示。
本小时知识架构如图16.1所示。
图16.1 本小时知识架构图
【导读小贴士】
层次式架构是软件体系结构设计中最为常用的一种架构形式,它为软件系统提供了一种在结构、行为和属性方面的高级抽象,其核心思想是将系统组成为一种层次结构,每一层为上层服务,并作为下层客户。本章重点介绍了层次式架构中的表现层、中间层、访问层和数据层的体系结构设计技术,给出了层次式架构的案例分析。
16.1 层次式体系结构概述
【基础知识点】
- 定义
软件体系结构为软件系统提供了结构、行为和属性的高级抽象,由构成系统的元素描述这些元素的相互作用、指导元素集成的模式以及这些模式的约束组成。层次式体系结构设计是一种常见的架构设计方法,它将系统组成为一个层次结构,每一层为上层服务,并作为下层客户。在一些层次系统中,除了一些精心挑选的输出函数外,内部的层接口只对相邻的层可见。层次式体系结构的每一层最多只影响两层,同时只要给相邻层提供相同的接口,也允许每层用不同的方法实现,这种方式也为软件重用提供了强大的支持。
- 层次式应用的组成
大部分的应用会分成表现层(或称为展示层)、中间层(或称为业务层)、访问层(或称为持久层)和数据层,如图16.2所示。
图16.2 常用的层次式架构
- 特点与注意事项
采用分层架构设计的一个特点就是关注点分离。每层中的组件只负责本层的逻辑,组件的划分也很容易明确组件的角色和职责,比较容易开发、测试、管理和维护。层次式体系结构是一个可靠的通用的架构,但是设计时要注意以下两点:
1)容易成为污水池反模式(Architecture Sinkhole Anti-patter):请求流简单地穿过几个层,每层里面基本没有做任何业务逻辑,或者做了很少的业务逻辑。比如一些Java EE例子,业务逻辑层只是简单地调用了持久层的接口,本身没有什么业务逻辑。
2)分层架构可能会让应用变得庞大。
16.2 表现层框架设计
【基础知识点】
- MVC(Model-View-Controller)模式
MVC是一种软件设计模式。MVC把一个应用的输入、处理、输出流程按照视图、控制、模型的方式进行分离,形成了控制器、模型、视图3个核心模块。其中:
(1)控制器(Controller):接受用户的输入,并调用模型和视图去完成用户的需求。
(2)模型(Model):应用程序的主体部分,表示业务数据和业务逻辑。
(3)视图(View):用户看到并与之交流的界面。
三者协作关系如图16.3所示
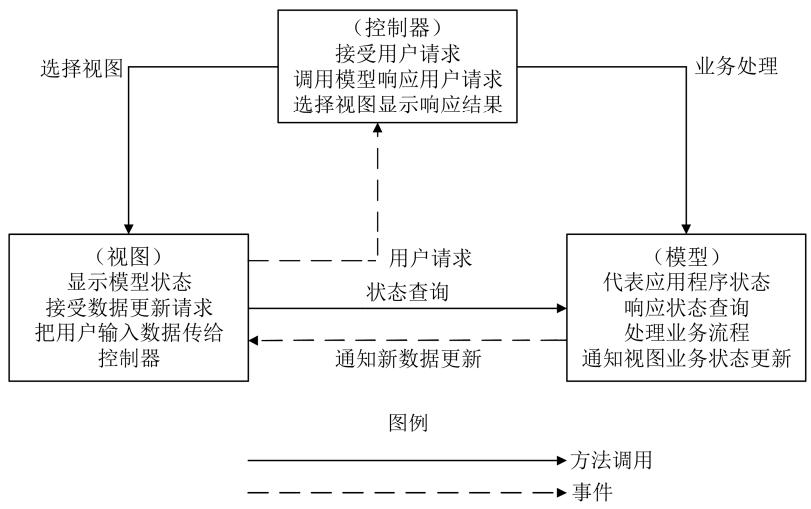
图16.3 MVC三者协作关系图
使用MVC模式来设计表现层,可以有以下的优点:
(1)允许多种用户界面的扩展。(2)易于维护。(3)易于构建功能强大的用户界面。(4)增加应用的可拓展性、强壮性、灵活性。
- MVP(Model-View-Presenter)模式
在MVP模式中Model提供数据,View负责显示,Controller/Presenter负责逻辑的处理。MVP不仅仅避免了View和Model之间的耦合,还进一步降低了Presenter对View的依赖。MVP设计模式如图16.4所示。
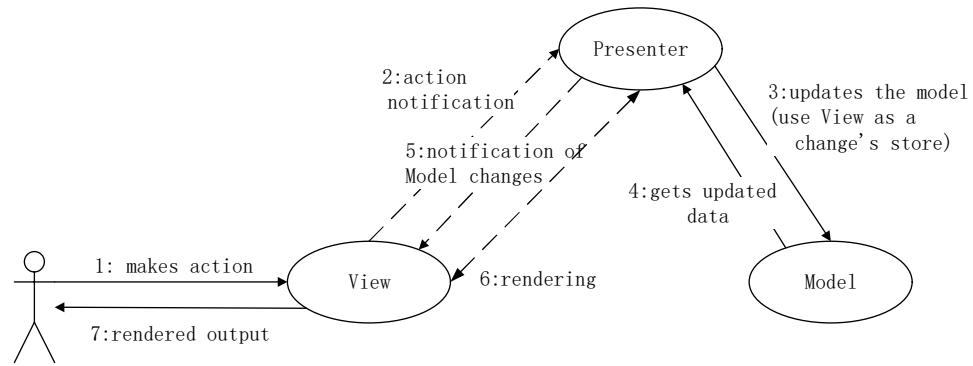
图16.4 MVP设计模式
使用MVP模式来设计表现层,可以有以下的优点:
(1)模型与视图完全分离,可以修改视图而不影响模型。(2)所有的交互都发生在一个地方——Presenter内部,因此可以更高效地使用模型。(3)可以将一个Presenter用于多个视图,而不需要改变Presenter的逻辑。因为视图的变化总是比模型的变化频繁。(4)如果把逻辑放在Presenter中,就可以脱离用户接口来测试这些逻辑(单元测试)。
- MVVM(Model-View-View Model)模式
MVVM和MVC、MVP类似,主要目的都是为了实现视图和模型的分离。不同的是MVVM中,View与Model的交互通过ViewModel来实现,也就是View和Model不能直接通信,两者的通信只能通过ViewModel来实现。ViewModel是MVVM的核心,通过DataBinding实现View与Model之间的双向绑定,其内容包括数据状态处理、数据绑定及数据转换。MVVM流程设计模式如图16.5所示。
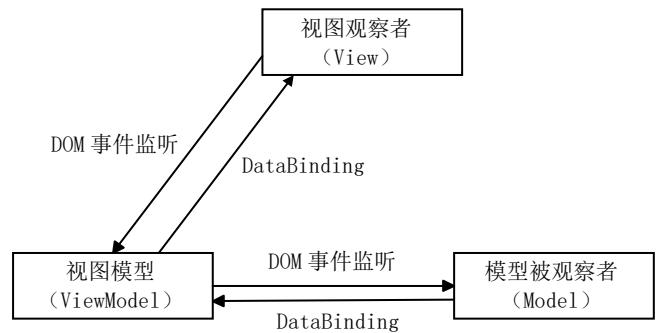
图16.5 MVVM流程设计模式
16.3 中间层框架设计
【基础知识点】
- 业务逻辑层组件设计
业务逻辑层组件分为接口和实现类两个部分。接口用于定义业务逻辑组件,定义业务逻辑组件必须实现的方法是整个系统运行的核心。通常按模块来设计业务逻辑组件,每个模块设计一个业务逻辑组件,并且每个业务逻辑组件以多个数据访问对象(Data Access Object,DAO)组件作为基础,从而实现对外提供系统的业务逻辑服务。
- 业务逻辑层工作流设计
工作流管理联盟(Workflow Management Coalition,WFMC)将工作流定义为:业务流程的全部或部分自动化,在此过程中,文档、信息或任务按照一定的过程规则流转,实现组织成员间的协调工作以达到业务的整体目标。工作流参考模型如图16.6所示。
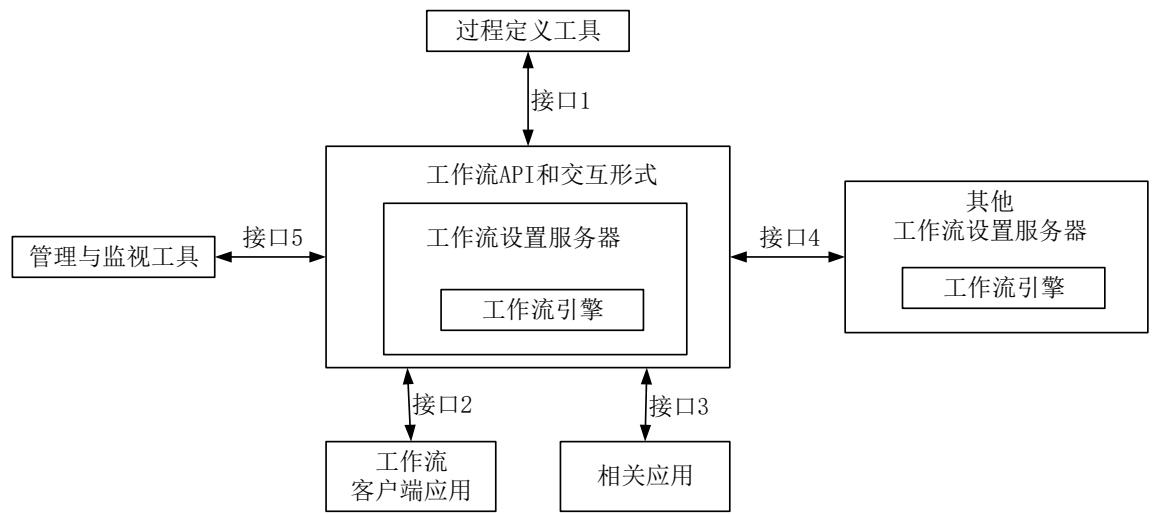
图16.6 工作流参考模型
- 业务逻辑层实体设计
逻辑层实体提供对业务数据及相关功能(在某些设计中)的状态编程访问。业务逻辑层实体可以使用具有复杂架构的数据来构建,这种数据通常来自数据库中的多个相关表。业务逻辑层实体数据可以作为业务过程的部分I/O参数传递。业务逻辑层实体是可序列化的,以保持它们的当前状态。
- 业务逻辑层框架
业务逻辑框架位于系统架构的中间层,是实现系统功能的核心组件。采用容器的形式,便于系统功能的开发、代码重用和管理。在业务容器中,业务逻辑是按照Domain Model-Service-Control思想来实现的。其中:
1)Domain Model 是仅仅包含业务相关的属性的领域层业务对象。2)Service 是业务过程实现的组成部分,是应用程序的不同功能单元,通过在这些服务之间定义良好的接口和契约联系起来。3)Control 服务控制器,是服务之间的纽带,不同服务之间的切换就是通过它来实现的。
16.4 数据访问层设计
【基础知识点】
- 数据访问模式
数据访问模式有5种,分别是:在线访问、Data Access Object、Data Transfer Object、离线数据模式、对象/关系映射(Object/Relation Mapping)。
(1)在线访问:最常用的方式。访问占用一个数据库连接,读取数据,每个数据库操作都会通过这个连接不断地与后台的数据源进行交互。
(2)Data Access Object:DAO 是标准J2EE设计模式,这种方式将底层数据访问操作与高层业务逻辑分离开。一个典型的DAO实现通常会有一个DAO工厂类、一个DAO接口、一个实现了DAO接口的具体类、数据传输对象。
(3)Data Transfer Object:DTO属于EJB设计模式之一。DTO是一组对象或容器,需要跨越不同的进程或是网络的边界来传输数据。
(4)离线数据模式:离线数据模式是以数据为中心,数据从数据源获取之后,将按照某种预定义的结构存放在系统中,成为应用的中心。这种方式对数据的各种操作独立于各种与后台数据源之间的连接或是事务。
(5)对象/关系映射:这种方式利用工具或平台能够帮助将应用程序中的数据转换成关系型数据库中的记录;或是将关系数据库中的记录转换成应用程序中代码便于操作的对象。
- 工厂模式在数据访问层的应用
工厂模式定义一个用于创建对象的接口,让子类决定实例化哪一个类。工厂方法使一个类的实例化延迟到其子类。这里可能会处理对多种数据库的操作,因此,需要首先定义一个操纵数据库的接口,然后根据数据库的不同,由类工厂决定实例化哪个类。
- ORM,Hibernate与CMP2.0设计思想
ORM(Object- Relation Mapping)在关系型数据库和对象之间作一个映射,这样,在具体操纵数据库时,就不需要再去和复杂的SQL语句打交道,只要像平时操作对象一样操作即可。Hibernate是一个功能强大,可以有效地进行数据库数据到业务对象的O/R映射方案。Hibernate推动了基于普通Java对象模型,用于映射底层数据结构的持久对象的开发。
- XML Schema
XML Schema用来描述XML文档合法结构、内容和限制,提供丰富的数据类型。
- 事务处理设计
事务处理设计事务必须服从 ISO/IEC 所制定的 ACID 原则。ACID 是原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)的缩写。事务的原子性表示事务执行过程中的任何失败都将导致事务所做的任何修改失效。一致性表示当事务执行失败时,所有被该事务影响的数据都应该恢复到事务执行前的状态。隔离性表示在事务执行过程中对数据的修改,在事务提交之前对其他事务不可见。持久性表示已提交的数据在事务执行失败时,数据的状态都应该正确。
- 连接对象管理设计
建立一个数据库连接池,提供一套高效的连接分配、使用策略,保证了数据库连接的有效复用。
16.5 数据架构规划与设计
【基础知识点】
(1)数据库设计与类的设计融合。对类和类之间关系的正确识别是数据模型的关键所在。好模型的目标是将工程项目整个生存期内的花费减至最小,同时也会考虑到随时间的推移系统将可能发生的变化,因而设计时也要考虑能适应这些变化。
(2)数据库设计与XML设计融合。XML文档的存储方式有两种:基于文件的存储方式和数据库存储方式。
16.6 物联网层次架构设计
【基础知识点】
(1)感知层:用于识别物体、采集信息。感知层包括二维码标签和识读器、RFID标签和读写器、摄像头、GPS、传感器、M2M终端、传感器网关等,主要功能是识别对象、采集信息,与人体结构中皮肤和五官的作用类似。
(2)网络层:用于传递信息和处理信息。网络层包括通信网与互联网的融合网络、网络管理中心、信息中心和智能处理中心等。网络层将感知层获取的信息进行传递和处理,类似于人体结构中的神经中枢和大脑。
(3)应用层:实现广泛智能化。应用层是物联网与行业专业技术的深度融合,结合行业需求实现行业智能化,这类似于人们的社会分工。
16.7 练习题
- 软件体系结构为软件系统提供了()的高级抽象,由构成系统的元素描述这些元素的相互作用、指导元素集成的模式以及这些模式的约束组成。
A.继承、多态、实现 B.关联、扩展、泛化C.结构、行为、属性 D.构件定义、访问方式、组织部署
解析:软件体系结构为软件系统提供了结构、行为和属性的高级抽象,由构成系统的元素描述这些元素的相互作用、指导元素集成的模式以及这些模式的约束组成。
答案:C
- MVC模式是一种目前广泛流行的软件设计模式。近年来,随着JavaEE的成熟,MVC成为了JavaEE平台上推荐的一种设计模式。MVC强制性地把一个应用的()流程进行分离,形成了控制器、模型、视图三个核心模块。
A.启动、运行、结束 B.输入、处理、输出 C.前端/客户端、服务端、数据库 D.接受请求、处理请求、返回请求
解析:MVC模式是一种目前广泛流行的软件设计模式。近年来,随着JavaEE的成熟,MVC成为了JavaEE平台上推荐的一种设计模式。MVC强制性地把一个应用的输入、处理、输出流程进行分离,形成了控制器、模型、视图三个核心模块。
答案:B
- 工作流管理联盟(WorkflowManagementCoalition)将工作流定义为:业务流程的全部或部分自动化,在此过程中,文档、信息或任务按照一定的过程规则流转,实现组织成员间的协调工作以达到业务的整体目标。工作流参考模型包括的组件是()。
A. 过程定义工具、工作流引擎、工作流客户端应用、相关应用、管理与监视工具 B. 工作流定义工具、工作流引擎、工作流客户端应用、相关应用、管理与监视工具 C. 工作流定义工具、工作流引擎、工作流客户端应用、工作流API、管理与监视工具 D. 过程定义工具、工作流引擎、工作流客户端应用、工作流API、管理与监视工具
解析:工作流参考模型包括的组件是过程定义工具、工作流引擎、工作流客户端应用、相关应用、管理与监视工具。
答案:A
- 事务必须服从ISO/IEC所制定的ACID原则。关于ACID,以下说法错误的是()。
A. 事务的原子性表示事务执行过程中的任何失败都将导致事务所做的任何修改失效 B. 一致性表示当事务执行失败时,所有被该事务影响的数据都应该恢复到事务执行前的状态 C. 隔离性表示在事务执行过程中对数据的修改,在事务提交之后对其他事务不可见 D. 持久性表示已提交的数据在事务执行失败时,数据的状态都应该正确
解析:隔离性表示在事务执行过程中对数据的修改,在事务提交之“前”对其他事务不可见。答案:C
- 物联网的感知层用于识别物体、采集信息。下列()不属于感知层设备。
A.摄像头 B.GPS C.扫描仪 D.指纹
解析:感知层主要功能是识别对象、采集信息,与人体结构中皮肤和五官的作用类似。但指纹是人的特征属性,不是感知层设备。
答案:D
第17小时 云原生架构设计理论与实践
17.0 章节考点分析
第17小时主要学习云原生架构设计理论与实践。根据考试大纲,本小时知识点会涉及单选题型(约占2~4分)、案例题(25分)和论文题,本小时节内容偏重于方法掌握和应用,根据以往全国计算机技术与软件专业技术资格(水平)考试的出题规律,概念知识的考查内容多数来源于实际应用,还需要灵活运用相关知识点。本小时知识架构如图17.1所示。
本小时知识架构如图17.1所示。
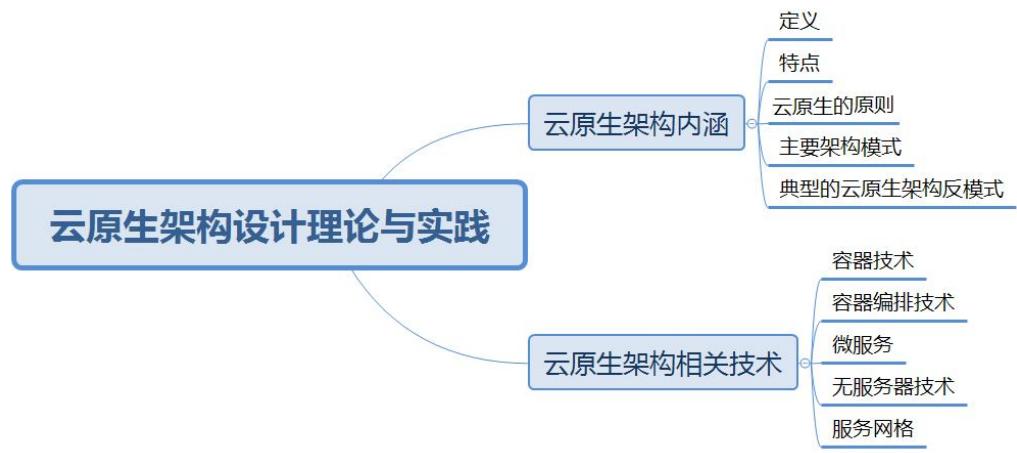
图17.1 本小时知识架构
【导读小贴士】
云原生(Cloud Native)是近几年云计算领域炙手可热的话题,云原生技术已成为驱动业务增长的重要引擎。同时,作为新型基础设施的重要支撑技术,云原生也逐渐在人工智能、大数据、边缘计算、5G等新兴领域崭露头角。伴随各行业上云的逐步深化,云原生化转型进程将进一步加速。
17.1 云原生架构内涵
【基础知识点】
1.定义
云原生架构是基于云原生技术的一组架构原则和设计模式的集合,旨在将云应用中的非业务代码部分进行最大化地剥离,从而让云设施接管应用中原有的大量非功能特性(如弹性、韧性、安全、可观测性、灰度等),使业务不再有非功能性业务中断困扰的同时,具备轻量、敏捷、高度自动化的特点。
2.特点
基于云原生架构的应用特点包括:
(1)代码结构发生巨大变化:不再需要掌握文件及其分布式处理技术,不再需要掌握各种复杂的网络技术,简化让业务开发变得更敏捷、更快速。(2)非功能性特性大量委托给云原生架构来解决:比如高可用能力、容灾能力、安全特性、可运维性、易用性、可测试性、灰度发布能力等。(3)高度自动化的软件交付:基于云原生的自动化软件交付可以把应用自动部署到成千上万的节点上。
- 云原生的原则
云原生具有以下原则:
(1)服务化原则:通过服务化架构把不同生命周期的模块分离出来,分别进行业务迭代。(2)弹性原则:弹性是指系统的部署规模可以随着业务量的变化而自动伸缩。(3)可观测原则:通过日志、链路跟踪和度量等手段,使得多次服务调用的耗时、返回值和参数都清晰可见。(4)韧性原则:软件所依赖的软硬件组件出现各种异常时,软件表现出来的抵御能力。(5)所有过程自动化原则:让自动化工具理解交付目标和环境差异,实现整个软件交付和运维的自动化。(6)零信任原则:不应该信任网络内部和外部的任何人/设备/系统,需要基于认证和授权重构访问控制的信任基础。(7)架构持续演进原则:架构具备持续演进能力。
- 主要架构模式
云原生涉及的主要架构模式有:
(1)服务化架构模式:要求以应用模块为颗粒度划分一个应用软件,以接口契约(例如IDL)定义彼此业务关系,以标准协议(HTTP、gRPC等)确保彼此的互联互通,结合领域模型驱动(Domain Driven Design,DDD)、测试动开发(Test Driven Design,TDD)、容器化部署提升每个接口的代码质量和迭代速度。
(2)Mesh化架构模式:Mesh化架构是把中间件框架(如RPC、缓存、异步消息等)从业务进程中分离,让中间件SDK与业务代码进一步解耦,从而使得中间件升级对业务进程没有影响,甚至迁移到另外一个平台的中间件也对业务透明。 (3)Serverless模式:业务流量到来/业务事件发生时,云会启动或调度一个已启动的业务进程进行处理,处理完成后云自动会关闭/调度业务进程,等待下一次触发。开发者不用关心应用运行地点、操作系统、网络配置、CPU性能等,将应用的整个运行都委托给云。Serverless模式适合事件驱动的数据计算任务、计算时间短的请求/响应应用、没有复杂相互调用的长周期任务。 (4)存储计算分离模式:分布式环境中的CAP困难主要是针对有状态应用,由于一致性(Consistency,C),可用性(Availability,A),分区容错性(PartitionTolerance,P)三者无法同时满足,最多满足其中两个。所以无状态应用不存在一致性这个维度,可以获得很好的可用性和分区容错性,因而获得更好的弹性。 (5)分布式事务模式。由于业务需要访问多个微服务,所以会带来分布式事务问题,否则数据就会出现不一致。因此架构师需要根据不同的场景选择合适的分布式事务模式,常用的有:
- XA模式(传统采用XA模式):由于XA规范是实现分布式事务处理的标准,通常采用两阶段提交(2 Prepare Commit,2PC)的方法,具有很强的一致性,但是由于需要两次网络交互,所以性能差。
- 基于消息的最终一致性(BASE):在可用性和一致性相冲突的情况下,为了权衡二者,BASE提出只要满足基本可用(BA)和最终一致性(E),接受数据的软状态或未确定状态(S),来优先实现性能,所以这类系统通常具备很高的性能。但正是由于应用的特点,选择可用性和一致性的妥协方案,导致通用性有限。
- TCC模式:采用Try-Confirm-Cancel二阶段模式,事务隔离性可控,高效,但需要应用代码将业务模型拆成二阶段,所以对业务侵入性强,设计开发维护等成本很高。
- SAGA模式:每个正向事务都对应一个补偿事务,若正向事务执行失败,则会执行补偿事务进行回滚。所以开发维护成本高。
- 开源项目SEATA的AT模式:它将TCC模式中的二阶段委托给底层代码框架,并且取消了行锁,所以非常高性能且无代码开发工作量,且可以自动执行回滚操作,但存在一些使用场景限制。
(6)可观测架构:可观测架构包括Logging、Tracing、Metrics,其中Logging提供多个级别跟踪,例如 INFO/ DEBUG/WARNING/ERROR;Tracing收集一个请求从前端到后端的访问日志聚合,形成完整调用链路跟踪;Metrics则提供对系统量化的多维度度量,包括并发度、耗时、可用时长、容量等。
(7)事件驱动架构:事件驱动架构(Event Driven Architecture,EDA)是一种应用/组件间的集成架构模式。适用于增强服务韧性、数据变化通知、构建开放式接口、事件流处理、命令查询的责任分离(Command Query Responsibility Segregation,CQRS) 把对服务状态有影响的命令用事件来发起,而对服务状态没有影响的查询才使用同步调用的 API 接口等。
- 典型的云原生架构反模式
架构设计有时候需要根据不同的业务场景选择不同的方式,常见的云原生反模式有:
(1)庞大的单体应用:缺乏依赖隔离,代码耦合,责任和模块边界不清晰,模块间接口缺乏治理,变更影响扩散,不同模块间的开发进度和发布时间要求难以协调,一个子模块不稳定导致整个应用都变慢,扩容时只能整体扩容而不能对达到瓶颈的模块单独扩容等。 (2)单体应用“硬拆”为微服务:强行把耦合度高、代码量少的模块进行服务化拆分;拆分后服务的数据是紧密耦合的;拆分后成为分布式调用,严重影响性能。 (3)缺乏自动化能力的微服务:人均负责模块数上升,人均工作量增大,也增加了软件开发成本。
17.2 云原生架构相关技术
【基础知识点】
- 容器技术
容器作为标准化软件基础单元,它将应用及其所有依赖项打包发布,由于依赖项齐备,应用不再受环境限制,在不同计算环境间快速、可靠地运行。容器部署模式与其他模式的比较如图 17.2 所示。
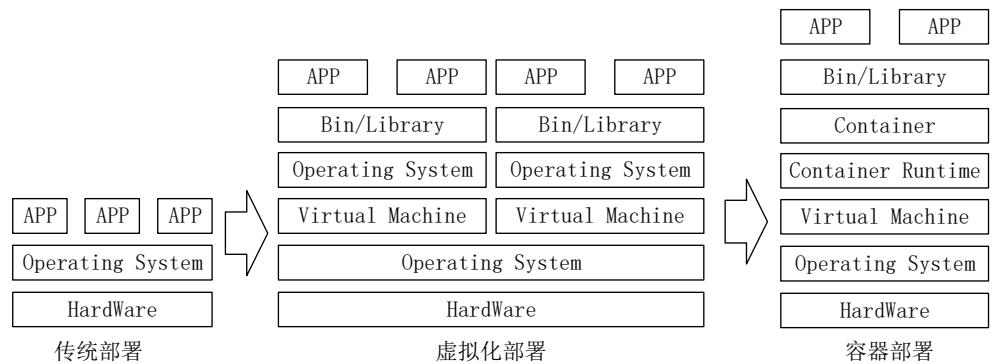
图17.2 传统、虚拟化、容器部署模式的比较
- 容器编排技术
容器编排技术包括资源调度、应用部署与管理、自动修复、服务发现与负载均衡、弹性伸缩、声明式API、可扩展性架构、可移植性。
- 微服务
微服务模式将后端单体应用拆分为松耦合的多个子应用,每个子应用负责一组子功能。这些子应用称为“微服务”,多个“微服务”共同形成了一个物理独立但逻辑完整的分布式微服务体系。这些微服务相对独立,通过解耦研发、测试与部署流程,提高整体迭代效率。微服务设计约束如下:
(1)微服务个体约束:微服务应用的功能在业务领域划分上应是相互独立的。 (2)微服务与微服务之间的横向关系:在合理划分好微服务间的边界后,从可发现性和可交互性处理微服务间的横向关系。可发现性是指当服务A发布和扩/缩容的时候,依赖服务A的服务B在不重新发布的前提下,能够自动感知到服务A的变化。可交互性是指服务A采用什么样的方式可以调用服务B。 (3)微服务与数据层之间的纵向约束:提倡数据存储隔离(DataStorageSegregation,DSS)原则,对于数据的访问都必须通过相对应的微服务提供的API来访问。 (4)全局视角下的微服务分布式约束:高效运维整个系统,从技术上实现全自动化的CI/CD流水线满足对开发效率的诉求,并在这个基础上支持蓝绿、金丝雀等不同发布策略,以满足对业务发布稳定性的诉求。
- 无服务器技术
无服务器技术的特点:
(1)全托管的计算服务——客户只需要编写代码构建应用,无须关注同质化的、负担繁重的基于服务器等基础设施的开发、运维、安全、高可用等工作。 (2)通用性——结合云BaaS(后端云服务)API的能力,能够支撑云上所有重要类型的应用。 (3)自动弹性伸缩——让用户无须为资源使用提前进行容量规划。 (4)按量计费——让企业的使用成本有效降低,无须为闲置资源付费。
无服务器技术的关注点是:计算资源弹性调度(容错、资源利用率、性能、数据驱动)、负载均衡和流控、安全性。
- 服务网格(ServiceMesh)
服务网格旨在将那些微服务间的连接、安全、流量控制和可观测等通用功能下沉为平台基础设施,实现应用与平台基础设施的解耦。图17.3展示了服务网格的典型架构。服务A调用服务B的所有请求,都被其下的服务代理截获,代理服务A完成到服务B的服务发现、熔断、限流等策略,而这些策略的总控是在**控制平面(ControlPlane)**上配置。
服务网格的主要技术:Istio、Linkerd、Consul。
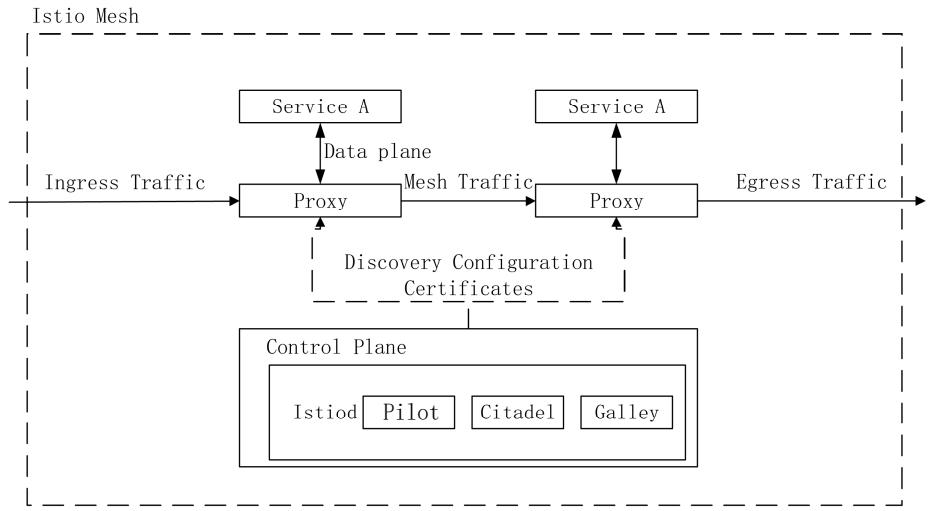
图17.3 服务网格的典型架构
17.3 练习题
- 云的时代需要新的技术架构,来帮助企业应用能够更好地利用云计算优势,充分释放云计算的技术红利。云计算无法为企业带来的改进是()。
A.通过DevSecOps应用开发模式,业务功能开发更加敏捷,提升迭代速度,成本更低 B.企业软件架构可以获得强大的可伸缩性和高可用性 C.结合云平台全方位企业级安全服务和安全合规能力,保障企业应用在云上安全构建,业务安全运行 D.企业的开发人员只须关注业务代码部分的开发,非业务功能可以完全委托给云原生架构来解决
解析:云原生架构旨在将云应用中的非业务代码部分进行最大化的剥离,从而让云设施接管应用中原有的大量非功能特性(如弹性、韧性、安全、可观测性、灰度等),但无法接管所有的非功能特性。
答案:D
- 下列关于云原生架构原则的描述,错误的是()
A.服务化原则、弹性原则、韧性原则B.可观测原则、所有过程自动化原则C.零信任原则、接口隔离原则D.架构持续演进原则
解析:接口隔离原则是面向对象设计原则,其含义是使用多个专门的接口比使用单一的总接口
好。它不是云原生架构原则。
答案:C
- 关于微服务的描述,错误的是()
A. 微服务是将后端单体应用拆分为松耦合的多个子应用,每个子应用负责一组子功能
B. 微服务相对独立,通过解耦研发、测试与部署流程,提高整体迭代效率
C. 微服务与数据层之间的纵向约束的含义是:在合理划分好微服务间的边界后,主要从微服务的可发现性和可交互性处理服务间的关系
D. 驾驭微服务的前提是:高效运维整个系统,从技术上要准备全自动化的CI/CD流水线满足对开发效率的诉求,并在这个基础上支持蓝绿、金丝雀等不同发布策略
解析:在合理划分好微服务间的边界后,主要从微服务的可发现性和可交互性处理服务间的关系,是属于微服务之间的横向关系。正确的纵向约束是:对于微服务的私有数据的访问都必须通过当前微服务提供的API来访问。
答案:C
- 无服务器技术的特点之一是全托管的计算服务:客户只需要编写代码构建应用,无须关注同质化的、负担繁重的基于服务器等基础设施的()等工作。
A.开发、测试、发布、交付 B.开发、运维、安全、高可用 C.机房建设、服务器装机、操作系统安装、软件安装 D.资源调度、性能压测、负载均衡、数据统计
解析:无服务器技术的特点如下。
全托管的计算服务:客户只需要编写代码构建应用,无须关注同质化的、负担繁重的基于服务器等基础设施的开发、运维、安全、高可用等工作。
通用性:结合云BaaSAPI的能力,能够支撑云上所有重要类型的应用。
自动弹性伸缩:让用户无须为资源使用提前进行容量规划
按量计费:让企业的使用成本有效降低,无须为闲置资源付费。
答案:B
- 容器作为标准化软件单元,它将应用及其所有依赖项打包,使应用不再受()限制,在不同计算环境间快速、可靠地运行。
A.环境 B.操作系统 C.硬件 D.网络
解析:在容器的帮助下,应用程序无须关注操作系统及更加低层的硬件、网络、存储的限制。选项B、C、D的说法有局限性,选项A更贴切。
答案:A
第18小时 面向服务架构设计理论与实践
18.0 章节考点分析
第18小时主要学习面向服务架构设计理论与实践。根据考试大纲,本小时知识点会涉及单选题型(约占 $2\sim 5$ 分)和案例题(25分),本小时内容偏重于方法的掌握和应用,根据以往全国计算机技术与软件专业技术资格(水平)考试的出题规律,概念知识的考查内容多数来源于实际应用,还需要灵活运用相关知识点。本小时知识架构如图18.1所示。
本小时知识架构如图18.1所示。
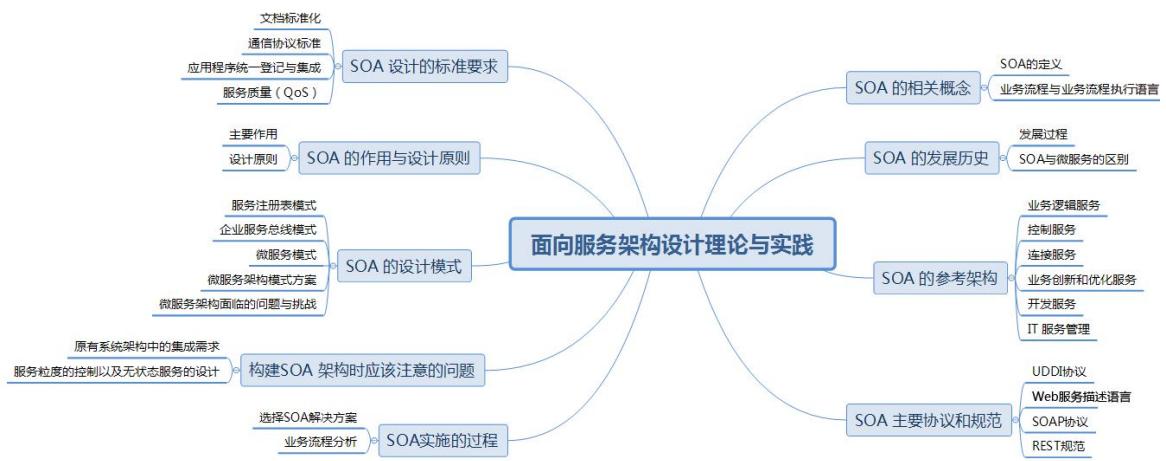
图18.1 本小时知识架构
【导读小贴士】
在面向服务的体系结构(Service- Oriented Architecture,SOA)中,服务的概念有了延伸,泛指系统对外提供的功能集。例如,在一个大型企业内部,可能存在进销存、人事档案和财务等多个系统,在实施SOA后,每个系统用于提供相应的服务,财务系统作为资金运作的重要环节,也向整个企业信息化系统提供财务处理的服务,那么财务系统的开放接口可以看成是一个服务。
18.1 SOA的相关概念
【基础知识点】
(1)SOA的定义。从软件的基本原理定义,可以认为SOA是一个组件模型,它将应用程序的不同功能单元(称为服务)通过这些服务之间定义良好的接口和契约联系起来。接口是采用中立的方式进行定义的,它应该独立于实现服务的硬件平台、操作系统和编程语言。这使得构建在各种这样的系统中的服务可以一种统一和通用的方式进行交互。
(2)业务流程与业务流程执行语言(Business Process Execution Language,BPEL)。业务流程是指为了实现某种业务目的行为所进行的流程或一系列动作。使用BPEL,用户可以通过组合、编排和协调Web服务自上而下地实现面向服务的体系结构。BPEL目前用于整合现有的Web Services,将现有的Web Services按照要求的业务流程整理成为一个新的Web Services,在这个基础上,形成一个从外界看来和单个Service一样的Service。
18.2 SOA的发展历史
【基础知识点】
发展过程
(1)萌芽阶段:这种广泛使用的XML,允许组织定义文档的元数据,实现企业内部和企业之间的电子数据交换,规定了服务之间以及服务内部数据交换的格式和结构。 (2)标准化阶段:国际标准和规范—— 1)简单对象访问协议(Simple Object Access Protocol,SOAP)、 2)Web服务描述语言(Web Services Description Language,WSDL)及 3)通用服务发现和集成协议(Universal Description, Discovery and Integration,UDDI)。 (3)成熟应用阶段:3个重量级规范——SCA、SDO、WS-Policy。SCA和SDO构成了SOA编程模型的基础,而WS-Policy建立了SOA组件之间安全交互的规范。
WSDL(Web Services Description Language,Web服务描述语言),是一个用来描述Web服务和说明如何与Web服务通信的XML语言。它是 Web服务的接口定义语言,由Ariba、Intel、IBM和 M S等共同提出,通过WSDL,可描述Web服务的三个基本属性。 (1)服务做些什么–服务所提供的操作(方法)。 (2)如何访问服务–和服务交互的数据格式以及必要协议。 (3)服务位于何处–协议相关的地址,如URL。
- SOA与微服务的区别
(1)微服务相比于SOA更加精细,微服务更多地以独立的进程的方式存在,互相之间并无影响。SOA架构与微服务架构的对比如图18.2所示。 (2)微服务提供的接口方式更加通用化,例如HTTP RESTful方式,各种终端都可以调用,无关语言、平台限制。 (3)微服务更倾向于分布式去中心化的部署方式,在互联网业务场景下更适合。
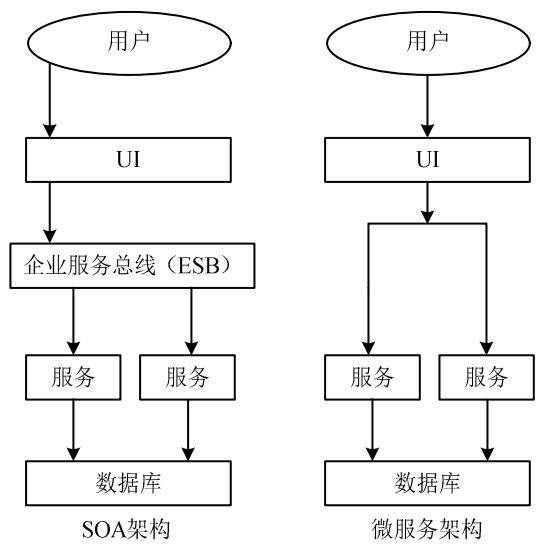
图18.2 SOA架构与微服务架构对比图
18.3 SOA的参考架构
IBM的Websphere业务集成参考架构是典型的以服务为中心的企业集成架构,它可划分为6大类:
(1)业务逻辑服务(Business Logic Service)。用于实现业务逻辑的服务和执行业务逻辑的能力,其中包括业务应用服务(Business Application Service)、业务伙伴服务(Partner Service)以及应用和信息资产(Application and Information Asset)。 (2)控制服务(Control Service)。包括实现人(People)、流程(Process)和信息(Information)集成的服务,以及执行这些集成逻辑的能力。 (3)连接服务(Connectivity Service)。通过提供企业服务总线,实现分布在各种架构元素中服务间的连接性。 (4)业务创新和优化服务(Business Innovation and Optimization Service)。用于监控业务系统运行时服务的业务性能,并通过及时了解到的业务性能和变化,采取措施适应变化的市场。 (5)开发服务(Development Service)。贯彻整个软件开发生命周期的开发平台,从需求分析到建模、设计、开发、测试和维护等全面的工具支持。 (6)IT 服务管理(IT Service Management)。支持业务系统运行的各种基础设施管理能力或服务,如安全服务、目录服务、系统管理和资源虚拟化。
18.4 SOA 主要协议和规范
Web 服务最基本的协议包括 UDDI、WSDL、SOAP,通过它们可以提供直接而又简单的 Web Service 支持,如图 18.3 所示。
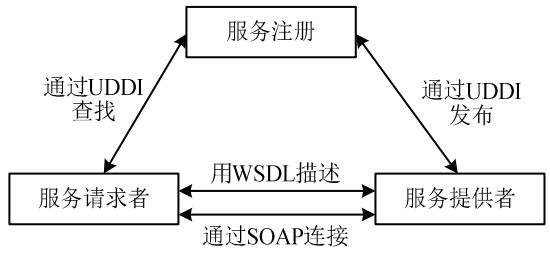
图 18.3 基本 Web 服务协议
(1)通用服务发现和集成协议(Universal Description, Discovery and Integration,UDDI):统一描述、发现和集成协议。包含了服务描述与发现的标准规范,它使得商业实体能够彼此发现;定义它们怎样在 Internet 上互相作用,并在一个全球的注册体系架构中共享信息。UDDI用于Web服务注册和服务查找 (2)Web 服务描述语言(Web Services Description Language,WSDL):WSDL是一个用来描述 Web 服务和说明如何与 Web 服务通信的 XML 语言。描述了 Web 服务的 3 个基本属性。用于描述Web服务的接口和操作功能 (3)SOAP(Simple ObjectAccess Protocol),SOAP为建立Web服务和服务请求之间的通信提供支持。用于实现Web服务的远程调用。 (4)BPEL (Business Process Execution Language For Web Services) 翻译成中文的意思是面向Web 服务的业务流程执行语言,也有的文献简写成BPEL4WS,它是一种使用 Web 服务定义和执行业务流程的语言。使用BPEL,用户可以通过组合、编排和协调 Web 服务自上而下地实现面向服务的体系结构(SOA)。BPEL 提供了一种相对简单易懂的方法,可将多个 Web 服务组合到一个新的复合服务(称作业务流程)中。
1)服务做些什么——服务所提供的操作(方法)。 2)如何访问服务——和服务交互的数据格式以及必要协议。 3)服务位于何处——协议相关的地址,如 URL。
(5)REST 规范:为了让不同的软件或者应用程序在任何网络环境下都可以进行信息的互相传递。微服务对外就是以 REST API 的形式暴露给调用者。RESTful即 REST 形式的,是对遵循 REST 设计思想同时满足设计约束的一类架构设计或应用程序的统称,这一类都可称为 RESTful,可以理解为资源表述性状态转移:
1)资源:将互联网中一切暴露给客户端的事物都可以看作是一种资源。 2)表述:REST 中用表述描述资源在 Web 中某一个时间的状态。 3)状态转移:分为两种,应用状态——对某个时间内用户请求会话相关信息的快照,保存在客户端。资源状态——在服务端保存,是对某个时间资源请求表述的快照。 4)超链接:通过在页面中嵌入链接和其他资源建立联系。
REST的状态转移是借助HTTP方法来实现:这是正确的。RESTU架构风格强调使用HTTP协议中的方法(如GET、POST、PUT、DELETE等)来表示对资源的不同操作,从而实现状态的转移。这些HTTP方法分别对应着资源的读取、创建、更新和删除等操作。 URI和资源是多对多关系:这是不正确的。在RESTU架构中,URI(统一资源标识符)应该与资源之间建立–对应的关系。每个URI都唯一地标识一个资源,并且这个资源通过该URI可以被访问和操作。REST是一种设计风格而不是一个架构:这是正确的。REST是以资源为中心构建的:这也是正确的。RESTul架构的核心思想是以资源为中心,所有的数据(即资源都通过网络以某种表现形式(如JSON、XML等)进行交换,客户端通过HTTP协议与服务器端进行资源的交互以实现对资源的访问和操作。
18.5 SOA设计的标准要求
SOA 设计的标准要求(1)文档标准化。SOA 服务具有平台独立的自我描述 XML 文档。Web 服务描述语言是用于描述服务的标准语言。(2)通信协议标准。SOA 服务用消息进行通信,该消息通常使用 XML Schema 来定义(也称作 XML Schema Definition,XSD)。(3)应用程序统一登记与集成。在一个企业内部,SOA 服务通过一个扮演**目录列表(Directory Listing)角色的登记处(Registry)来进行维护。应用程序在登记处(Registry)**寻找并调用某项服务。统一描述、定义和集成是服务登记的标准。(4)服务质量(QoS) 主要包括: 1)可靠性:服务消费者和服务提供者之间传输文档时的传输特性(且仅仅传送一次、最多传送一次、重复消息过滤、保证消息传送)。 2)安全性:Web 服务安全规范用来保证消息的安全性。 3)策略:服务提供者有时候会要求服务消费者与某种策略通信。例如,服务提供商可能会要求消费者提供 Kerberos 安全标示才能取得某项服务。 4)控制:在 SOA 中,进程是使用一组离散的服务创建的。BPEL4WS 或者 WSBPEL(Web Service Business Process Execution Language)是用来控制这些服务的语言。 5)管理:针对运行在多种环境下的所有服务,必须有一个统一管理系统,以便系统管理员能够有效管理。任何根据 WSDM实现的服务都可以由一个 WSDM 适应(WSDM- compliant) 的管理方案来管理。
18.6 SOA的作用与设计原则
SOA 的作用与设计原则 (1)SOA 的主要作用:打破信息孤岛,把应用和资源转换成服务。以及把这些服务变成标准的服务,形成资源的共享。 (2)SOA 的设计原则主要有: 1)无状态。以避免服务请求者依赖于服务提供者的状态。 2)单一实例。以高内聚的实现方法,来避免功能冗余。 3)明确定义的接口。服务的接口由 WSDL 定义,用于指明服务的公共接口与其内部专用实现之间的界线。 4)自包含和模块化。服务封装了那些在业务上稳定、重复出现的活动和组件,实现服务的功能实体是完全独立自主的,独立进行部署、版本控制、自我管理和恢复。 5)粗粒度。服务数量不应该太大,依靠消息交互而不是远程过程调用(Remote Procedure Call,RPC),通常消息量较大,但是服务之间的交互频度较低。 6)服务之间的松耦合性。服务使用者看到的是服务的接口,其位置、实现技术和当前状态等对使用者是不可见的,服务私有数据对服务使用者是不可见的。 7)重用能力。服务应该是可以复用的。 8)互操作性、兼容和策略声明。为了确保服务规约的全面和明确,利用策略来定义可配置的互操作语义,来描述特定服务的期望、控制其行为。利用策略声明确保服务期望和语义兼容性方面的完整和明确。
18.7 SOA的设计模式
- 服务注册表模式
服务注册表支持驱动SOA治理的服务合同、策略和元数据的开发、发布和管理。 (1)服务注册:应用开发者,也叫服务提供者,向注册表公布它们的功能。 (2)服务位置:也就是服务应用开发者,帮助它们查询注册服务,寻找符合自身要求的服务。 (3)服务绑定:服务的消费者利用检索到的服务合同来开发代码,开发的代码将与注册的服务绑定、调用注册的服务以及与它们实现互动。
- 企业服务总线模式(ESB)
企业服务总线模式提供一种标准的软件底层架构,各种程序组件能够以服务单元的方式“插入”到该平台上运行,并且组件之间能够以标准的消息通信方式来进行交互。其核心功能如下: (1)提供位置透明性的消息路由和寻址服务。程序组件之间无须关注对方的路由和寻址。 (2)提供服务注册和命名的管理功能。 (3)支持多种消息传递范型(如请求/响应、发布/订阅等)。 (4)支持多种可以广泛使用的传输协议。 (5)支持多种数据格式及其相互转换。 (6)提供日志和监控功能。
ESB的定义通常如下:企业服务总线是由中间件技术实现的支持面向服务架构的基础软件平台,支持异构环境中的服务以及基于消息和事件驱动模式的交互,并且具有适当的服务质量和可管理性。这种交互过程不再是点对点的直接交互模式,而是由事件驱动的消息交互模式。通过这种方式,ESB最大限度上解耦了组件之间的依赖关系,降低了软件系统互连的复杂性。ESB不支持服务请求者与服务提供者之间的直接链接,二者之间仍然存在关系,只是这种关系是松耦合的。
SOA和微服务区别 1)微服务是SOA的演进形态,但其核心是服务解耦与独立部署,不强调中间件基础设施。 2)ESB才是由中间件实现、支持SOA的标准交互基础设施,负责服务中介与解耦。 3)好比快递站代替点对点送件,ESB作为’中转站’消除服务直连,而微服务更像"分拣后各自派送’
- 微服务模式
微服务架构将一个大型的单个应用或服务拆分成多个微服务,可扩展单个组件而不是整个应用程序堆栈,从而满足服务等级协议。微服务架构围绕业务领域将服务进行拆分,每个服务可以独立进行开发、管理和迭代,彼此之间使用统一接口进行交流,实现了在分散组件中的部署、管理与服务功能,使产品交付变得更加简单,从而达到有效拆分应用,实现敏捷开发与部署的目的。微服务模式的特点如下: (1)复杂应用解耦:微服务架构将单一模块应用分解为多个微服务,同时保持总体功能不变。 (2)独立:微服务在系统软件生命周期中是独立开发、测试及部署的。 (3)技术选型灵活:微服务架构下系统应用的技术选型是去中心化的,每个开发团队可根据自身应用的业务需求发展状况选择合适的体系架构与技术。 (4)容错:由于各个微服务相互独立,故障会被隔离在单个服务中,并且系统其他微服务可通过重试、平稳退化等机制实现应用层的容错,从而提高系统应用的容错性 (5)松耦合,易扩展:微服务架构中每个服务之间都是松耦合的,可以根据实际需求实现独立扩展,体现微服务架构的灵活性。单体应用架构与微服务架构的示意如图18.4所示。
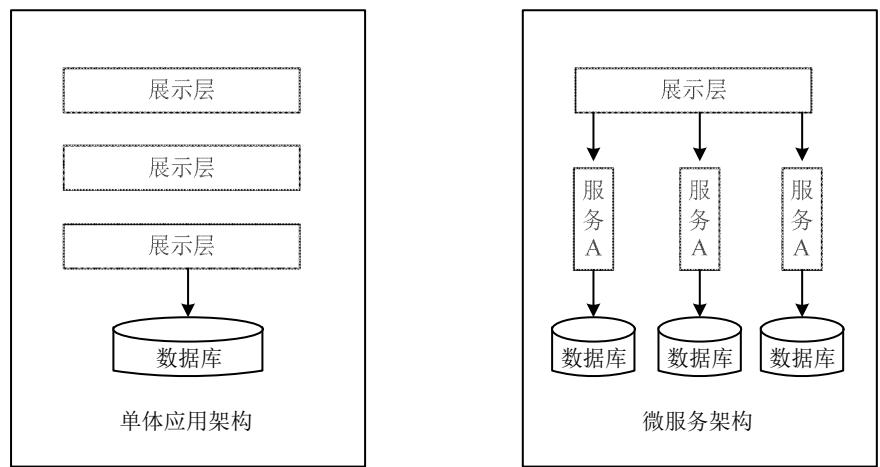
图18.4单体应用架构与微服务架构示意图
- 微服务架构模式方案
微服务架构模式方案主要包括: (1)聚合器微服务:聚合器充当流程指挥者,调用多个微服务实现系统应用程序所需功能。 (2)链式微服务:客户端或服务在收到请求后,会发生多个服务间的嵌套递归调用,返回经过合并处理的响应。 (3)数据共享微服务:该模式适用于在单体架构应用到微服务架构的过渡阶段,服务之间允许存在强耦合关系,例如存在多个微服务共享缓存与数据库存储的现象。 (4)异步消息传递微服务:对于一些不必要以同步方式运行的业务逻辑,可以使用消息队列代替REST实现请求、响应,加快服务调用的响应速度。
- 微服务架构面临的问题与挑战
(1)服务发现与服务调用链跟踪变得困难。 (2)很难实现传统数据库的强一致性,转而追求最终一致性。
18.8 构建SOA架构时应该注意的问题
(1)原有系统架构中的集成需求包括:应用程序集成的需求、终端用户界面集成的需求、流程集成的需求以及已有系统信息集成的需求。 (2)服务粒度的控制以及无状态服务的设计的表述如下。 1)服务粒度的控制:对于将暴露在整个系统外部的服务推荐使用粗粒度的接口,而相对较细粒度的服务接口通常用于企业系统架构的内部。 2)无状态服务的设计:SOA系统架构中的具体服务应该都是独立的、自包含的请求,在实现这些服务的时候不需要前一个请求的状态,也就是说服务不应该依赖于其他服务的上下文和状态,即SOA架构中的服务应该是无状态的服务。
18.9 SOA实施的过程
(1)选择SOA解决方案主要从以下3个方面进行:
1)尽量选择能进行全局规划的方案。 2)选择时充分考虑企业自身的需求。 3)从平台、实施等技术方面进行考察。
(2)业务流程分析主要关注:
1)建立服务模型:自顶向下分解法、业务目标分析法、自底向上分析法。 2)建立业务流程:建立业务对象(实体、过程、事件等业务对象)、建立服务接口、建立服务流程。
18.10 练习题
- 下列关于SOA与微服务的描述,错误的是()
A.微服务相比于SOA更加精细,微服务更多地以独立的进程的方式存在,互相之间并无影响 B.微服务提供的接口方式更加通用化,例如HTTP、RESTful方式,各种终端都可以调用,无关语言、平台限制 C.微服务更倾向于分布式去中心化的部署方式,在互联网业务场景下更适合 D.微服务更容易实现出高并发的特性,有助于实现互联网业务的秒杀促销活动
解析:微服务在实现高并发方面是局限的。只有没有调用关系的微服务,相对于单体服务来说,才有并发性的提升。
答案:D
- 下列选项( )不是关于SOA的服务架构。
A.业务逻辑服务 B.中间件服务 C.连接服务 D.控制服务
解析:SOA的参考架构中包括业务逻辑服务(Business Logic Service)、控制服务(Control Service)、连接服务(Connectivity Service)、业务创新和优化服务(Business Innovation and Optimization Service)、开发服务(Development Service)、IT服务管理(IT Service Management)。
答案:B
- WSDL规范:Web服务描述语言(Web Services Description Language)是一个用来描述Web服务和说明如何与Web服务通信的XML语言,描述了Web服务的三个基本属性,即()。
a. 服务做些什么 b. 如何访问服务 c. 服务位于何处 d. 服务是否可用
A. abc B. acd C. bcd D. abd
解析:服务做些什么:服务所提供的操作(方法)。如何访问服务:和服务交互的数据格式以及必要协议。服务位于何处:协议相关的地址,如URL。
答案:A
- SOA的设计原则为无状态、单一实例、明确定义的接口、()、粗粒度、服务之间的松耦合性、重用能力、互操作性。
A. 复用性和构件化 B. 自包含和模块化 C. 独立性和构件化 D. 隔离性和归一化
解析:SOA的设计原则为无状态、单一实例、明确定义的接口、自包含和模块化、粗粒度、服务之间的松耦合性、重用能力、互操作性。
答案:B
- 微服务架构将一个大型的单个应用或服务拆分成多个微服务,可扩展单个组件而不是整个应用程序堆栈,从而满足服务等级协议。微服务架构围绕业务领域将服务进行拆分,每个服务可以(),彼此之间使用统一接口进行交流,实现了在分散组件中的部署、管理与服务功能,使产品交付变得更加简单,从而达到有效拆分应用,实现敏捷开发与部署的目的。
A. 独立进行开发、管理、迭代 B. 独立进行部署、运维、升级 C. 独立进行测试、交付、验收 D. 独立进行发布、发现、访问
解析:微服务架构围绕业务领域将服务进行拆分,每个服务可以独立进行开发、管理和迭代,彼此之间使用统一接口进行交流,实现了在分散组件中的部署、管理与服务功能。
答案:A
第19小时 嵌入式系统架构设计理论与实践
19.0 章节考点分析
第19小时主要学习嵌入式系统架构设计的理论和工作中的实践。根据新版考试大纲,本小时知识点会涉及案例分析题(25分)。在历年考试中,案例题对该部分内容都有固定考查,综合知识选择题目中有固定分值的考查。本小时内容侧重于对知识点的记忆、理解和应用,按照以往的出题规律,嵌入式系统架构设计基础知识点基本来源于教材内。本小时知识架构如图19.1所示。
图19.1 本小时知识架构
【导读小贴士】
嵌入式系统由硬件和软件组成,常被视为独立运行的器件或智能设备。相比于一般的微型计算机处理系统而言,嵌入式系统有着较大的特殊性和差异性,但其又与计算机系统工程和软件工程有着极大的相似性。经过之前内容的学习,本小时可以通过相似知识的关联,快速记忆。
19.1 嵌入式系统发展历程
【基础知识点】
嵌入式系统发展历程见表19.1。
表19.1 嵌入式系统发展历程表
| 发展历程 | 硬件 | 软件 | 主要特点 |
| 单片微型计算机(SCM) | 单片机 | 无操作系统 汇编语言 | 结构和功能相对单一 处理效率低 存储容量十分有限 几乎没有用户接口 |
| 微控制器(MCU) | 单片机 嵌入式微处理器 外围电路 接口电路 | 以简单操作系统为核心 | 微处理器、微控制器种类繁多 通用性比较弱 系统开销小,处理效率高 智能化控制能力突出 |
| 片上系统(SoC) | 嵌入式微处理器 | 嵌入式操作系统 | 嵌入式系统兼容性好 操作系统内核小 处理效率高 |
| 以 Internet 为基础的嵌入式系统 | 嵌入式微处理器 | 嵌入式操作系统 | 微处理器集成网络接口 应用域网络环境中 |
| 智能化、云技术推动下的嵌入式系统 | 微型传感器 智能服务设备 | — | 低能耗,高速度,高集成,高可信,适应环境广 |
19.2 嵌入式系统硬件
【基础知识点】
- 传统嵌入式系统
传统嵌入式系统主要硬件包括:
(1)微处理器:微控制器(MCU),微处理器(MPU)。(2)存储器:RAM、ROM。(3)总线:内总线,外总线。(4)定时器/计数器(Timer)。(5)看门狗(WatchDog)(6)I/O接口:串口,网络,USB,JTAG。(7)外部设备:UART,LED。
- 嵌入式处理器的分类
嵌入式处理器可以分为:
(1)微处理器(MicroProcessor Unit,MPU)。特点是体积小,重量轻,成本低,可靠性高,但技术保密性差。(2)微控制器(Micro Control Unit,MCU)。特点是单片化,体积小,功耗低,成本低,可靠性更高。(3)信号处理器(Digital Signal Processor,DSP)。特点是系统结构和指令采用特殊设计,通常采用哈佛结构,编译效率高,指令执行速度也高。(4)图形处理器(Graphics Processing Unit,GPU)。专注于浮点运算,弥补了CPU运算速度不足。(5)片上系统(System on Chip,SoC)。采用了片内再编程技术,可使片上系统内硬件的功能像软件一样通过编程来配置,从而可以实时地进行灵活而方便的修改和开发。
- 存储器
存储器就是一种存储程序和数据用的时序逻辑电路。存储器具有如下分类:
(1)随机存取存储器(Random Access Memory,RAM)。它的特点是一旦系统断电,存放在里面的所有数据和程序都会自动清空掉,并且再也无法恢复。根据组成元件的不同,RAM内存又可分为以下18种: $(1)$ 动态随机存取存储器(DRAM); $(2)$ 静态随机存取存储器(SRAM); $(3)$ 视频内存(VRAM); $(4)$ 快速页切换模式动态随机存取存储器(FPMDRAM); $(5)$ 延伸数据输出动态随机存取存储器(EDODRAM); $(6)$ 爆发式延伸数据输出动态随机存取存储器(BEDODRAM); $(7)$ 多插槽动态随机存取存储器(MDRAM); $(8)$ 窗口随机存取存储器(WRAM); $(9)$ 高频动态随机存取存储器(RDRAM); $(10)$ 同步动态随机存取存储器(SDRAM); $(11)$ 同步图形随机存取存储器(SGRAM); $(12)$ 同步爆发式静态随机存取存储器(SBSRAM); $(13)$ 管线爆发式静态随机存取存储器(PBSRAM); $(14)$ 工倍速率同步动态随机存取存储器(DDRSDRAM); $(15)$ 同步链环动态随机存取存储器(SLDRAM); $(16)$ 同步缓存动态随机存取存储器(CDRAM); $(17)$ 第二代同步双倍速率动态随机存取存储器(DDRII); $(18)$ 直接内存总线动态随机存取存储器(DRDRAM)。
(2)只读存储器(Read Only Memory,ROM)。ROM在元件正常工作的情况下,其中的代码数据将永久保存,并且不能够进行修改。ROM一般应用于PC系统程序码和主机板BIOS上。ROM可以分为以下5种: $(1)$ 掩模型只读存储器(MASKROM); $(2)$ 可编程只读存储器(PROM); $(3)$ 可擦可编程只读存储器(EPROM); $(4)$ 电可擦可编程只读存储器(EEPROM); $(5)$ 快闪存储器(Flash Memory)。
- 总线
总线是功能部件间传输信息的公共通信干线。总线的拓扑结构有星型、树状、环型、总线型和交叉开关型等5种。总线的类型可以按照计算机所传输的信息种类、按连接部件进行划分。
(1)按照计算机所传输的信息种类可以分为:
1)数据总线:用于处理器与RAM间传输待处理和待存储的数据。2)地址总线:用于传输RAM中存储数据的地址。3)控制总线:用于传输处理器控制单元信号到周边设备。
(2)按连接部件分类。
1)片内总线:内部总线,连接ALU、寄存器、指令部件等芯片内部元件。2)系统总线:内部总线,又称板级总线,连接微控制器/处理器,主存,I/O接口。3)局部总线:内部总线,连接少量组件用于交换数据。4)通信总线:外部总线,又称外设总线,连接外部设备或外部系统。
- 看门狗
看门狗为嵌入式系统提供必需的系统恢复能力,在系统发生软件问题和程序跑飞时重新启动系统。它的基本原理是由计数器自动计数,程序定期将其重置,如果系统卡死或程序跑飞,计数器溢出,进入中断处理,在设定时间间隔内,系统保留状态后复位重启。
19.3 嵌入式系统软件
【基础知识点】
- 嵌入式操作系统的定义及特点
嵌入式操作系统(EmbeddedOperatingSystem,EOS)是指用于嵌入式系统的操作系统。与通用的操作系统相比,嵌入式操作系统具有:可剪裁性,可移植性,强实时性,强紧凑性,高质量代码,强定制性,标准接口,强稳定性,弱交互性,强确定性,操作简捷、方便,较强的硬件适应性,可固化性的特点。
- 嵌入式系统的架构
嵌入式操作系统分为面向控制、通信领域以及面向消费电子产品两类。嵌入式操作系统的架构如图19.2所示。
- 嵌入式操作系统的基本功能
(1)操作系统内核架构
1)宏内核。用于管理用户程序和硬件间的系统资源,在宏内核中用户服务和内核服务在同一空间中实现,代码耦合度非常高,内核的功能组件代码可以互相调用。
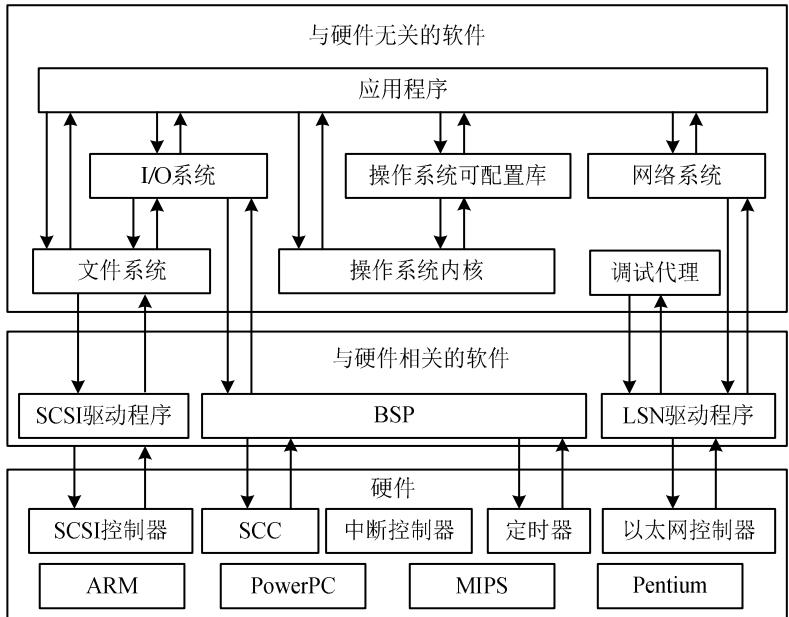
图19.2 嵌入式操作系统的架构
2)微内核。微内核管理所有系统资源,在微内核中用户服务和内核服务在不同空间中实现,系统结构清晰,代码量少。
(2)任务管理
任务是嵌入式操作系统调度最小单位,类似于计算机操作系统中进程的概念。任务有3种工作状态:1)执行状态:任务获得处理机,程序在处理机中执行。2)就绪状态:任务已获得处理机以外资源,待获得处理机即可执行。3)阻塞状态:执行状态任务因等待事件发生无法执行而放弃处理机。
嵌入式操作系统大都支持优先级抢占调度算法和时间片轮转调度算法。在实时系统的任务调度中,存在大量的实时调度方法,大致可以分为:1)离线调度算法:系统运行前确定调度信息,如时间驱动,确定性,缺乏灵活性。2)在线调度算法:系统运行中动态获得调度信息,如优先级驱动,灵活性较大。3)抢占调度算法:运行任务可能被打断,更复杂,更耗资源。4)非抢占调度算法:运行任务不被打断。5)静态调度算法:任务优先级在设计时确定,不变化,简单,缺乏灵活性。6)动态调度算法:任务优先级在运行中确定,不断变化,灵活,耗资源。
实时调度算法中还有强实时调度算法,具体可以分为:1)最早截止时间优先(Earliest Deadline First,EDF)调度算法:根据任务截止时间确定优先级,截止时间越早,其优先级越高。2)最低松弛度优先(Least Laxity First,LLF)调度算法:根据任务紧急或松弛程度确定优先级,紧急程度越高,优先级越高。3)单调速率(Rate Monotonic Scheduling,RMS)调度算法:根据任务周期确定有限期,周期越短,优先级越高。这种算法被认为是最优的。
(3)存储管理。存储管理的主要目的是解决多个用户使用主存的问题,存储管理方法主要包括分区、分页、分段、段页式存储管理以及虚拟存储管理等。
(4)任务间通信。任务间通信管理也是嵌入式操作系统的关键功能之一。它主要为操作系统的应用程序提供多种类型的数据传输、任务同步/异步操作等手段。
- 嵌入式数据库
嵌入式数据库具有嵌入式、实时性、移动性、伸缩性的特点。嵌入式数据库可以按照如下方式分类:
(1)按嵌入对象分为:软件嵌入数据库、设备嵌入数据库、内存数据库。(2)按系统结构分为:嵌入数据库、移动数据库、小型C/S结构数据库。(3)按存储位置分为: 1)基于内存的数据库系统:采用内存存储,属于实时事务最佳技术; 2)基于文件的数据库:以文件方式磁盘存储,安全性低; 3)基于网络的数据库:远程服务器存储,无须解析SQL,支持更多SQL操作,客户端小,便于代码重用。
- 嵌入式数据库架构
数据库管理系统与嵌入式数据库对比见表19.2
表19.2 数据库管理系统与嵌入式数据库使用对比
| 对比页 | 数据库管理系统 | 嵌入式数据库 |
| 操作用户 | 允许非开发人员操作 | 只允许应用程序访问和控制 |
| 访问控制 | 数据与程序分离,便于访问控制 | 应用程序负责访问和控制 |
| 发布部署 | 独立安装、部署和管理 | 与应用程序一同发布 |
(1)基于内存的数据库系统。典型产品是eXtremeDB嵌入式数据库,它具有:最小化资源消耗、保持极小堆空间、维持极小代码体积、消除额外代码层、提供动态数据结构本地支持等特点。
(2)基于文件的嵌入式数据库系统架构。典型产品是SQLite,它的特点是:开源的内嵌式关系型数据库、集成在程序中,无须配置管理,服务器客户端同进程,简化管理,减少网络开销、对数据类型有独特处理。
(3)基于网络的嵌入式数据库系统架构。C/S架构的数据库、B/S架构的数据库以及云数据库等都属于这种类型。
- 嵌入式数据库主要功能
除了具有与通用数据库相似的功能外,嵌入式数据库还具有的功能包括:足够高效的数据存储机制、数据安全控制(锁机制)、实时事务管理机制、数据库恢复机制(历史数据存储)。
- 嵌入式中间件
嵌入式中间件嵌入式中间件是在嵌入式系统中处于嵌入式应用和操作系统之间层次的中间软件,其主要作用是对嵌入式应用屏蔽底层操作系统的异构性,常见功能有网络通信、内存管理和数据处理等。典型的嵌入式中间件有消息中间件、分布式对象中间件。
- 嵌入式系统软件开发环境
嵌入式系统软件开发环境嵌入式系统软件开发环境的特点是:集成开发环境,交叉开发,开放式架构,可扩展性,可操作性,可移植性,可配置性,实时性,可维护性,用户界面友好。
19.4 嵌入式系统软件架构设计方法
【基础知识点】
(1)基于架构的软件设计开发方法(Architecture-Based Software Design,ABSD)。这种方法的详细内容在第9小时中,这里不再赘述。
(2)属性驱动的软件设计方法(Attribute-Driven Design,ADD)。ADD是把一组质量属性(可用性、性能、安全性等)场景作为输入,利用对质量属性实现与架构设计之间的关系的了解(如体系结构风格、质量战术等)对软件架构进行设计的一种方法。这种方法在满足质量属性的基础上建立模块分解过程,通过输入质量场景,利用质量属性战术实现架构设计。采用ADD方法进行软件开发时,需要经历评审、选择驱动因子、选择系统元素、选择设计概念、实体化元素和定义接口、草拟视图和分析评价等7个阶段。
(3)实时系统设计方法(Design Approach for Real-Time System,DARTS)。DARTS基于传统结构化分析方法,扩展了行为建模部分。DARTS方法分为5个部分:用实时结构化分析方法开发系统规范、将系统划分为多个并发任务、定义任务间接口、设计每个任务、设计过程的成果。
DARTS方法的优势如下:1)强调将系统分解为并发任务,并提供确认任务的标准。2)提供定义任务间接口的指南。3)强调用任务架构图的重要性。4)提供从实时结构化分析规格到实时结构化设计的转换。
DARTS方法的不足如下:1)DARTS使用信息隐藏技术封装数据存储,封装性不好。2)如果实时结构化分析阶段完成得不好,那么任务的结构化工作就会更加困难。
19.5 嵌入式系统软件架构实践
【基础知识点】
- 鸿蒙操作系统
鸿蒙操作系统架构采用了分布式设计理念,实现了分布式软总线、分布式设备系统的虚拟化、分布式数据管理和分布式任务调度4种分布式能力。
鸿蒙操作系统的架构是一种层次式架构,由内核层、系统服务层、应用框架层、应用层组成,如图19.3所示。
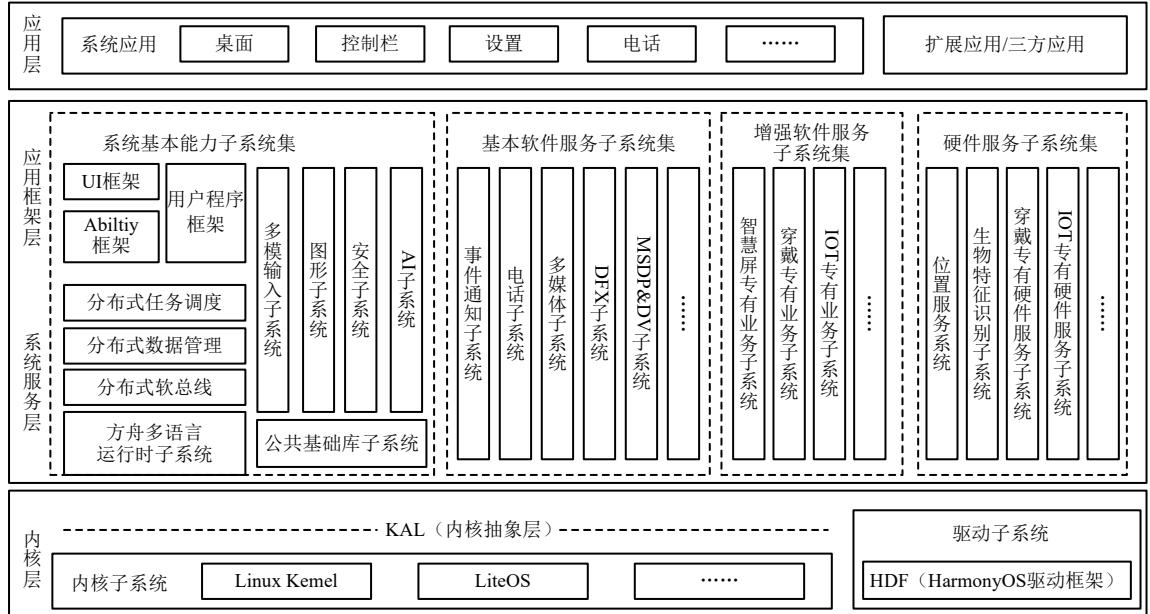
图19.3 鸿蒙操作系统层次式架构
(1)内核层。内核层采用微内核设计,内核层中的内核抽象层屏蔽多内核差异,对上层提供基础内核能力,如进程/线程管理、内存管理、文件系统、网络管理、外设管理等。驱动子系统则提供统一外设访问能力,驱动开发框架,驱动管理框架。 (2)系统服务层。属于核心能力集合的部分,为应用程序提供服务。 (3)应用框架层。为应用服务提供多语言用户程序框架、能力框架,以及各种硬件服务对外开放的API。 (4)应用层。包括系统应用和第三方非系统应用,能够实现特定的业务功能,支持跨设备调度与分发,为用户提供一致、高效的应用体验。
鸿蒙操作系统架构具有4个技术特性:
(1)分布式架构用于终端操作系统,实现跨终端无缝协同体验。(2)确定时延引擎和高性能进程间通信技术,实现系统的流畅。(3)基于微内核架构,重塑终端设备的可信安全。(4)统一集成开发环境,一次开发,多端部署,实现跨终端生态共享。
- 面向安全攸关系统的跨领域系统架构(Generic Embedded System,GENESYS)
GENESYS 是一种跨领域的通用嵌入式架构平台。GENESYS 采用消息交换方式实现软硬件构件的抽象级别的提升,使得构件在接口规范基础上可以被重用,而不需要知道构件的内部实现。GENESYS 设计了故障或错误的隔离框架,构件在瞬态故障引起失效后,可选择性地重启和用构件复制来屏蔽瞬态和永久错误。同时 GENESYS 可以减少构件的功率需求或者在不需要时(功率门)完全关闭构件。因此 GENESYS 的出现解决了复杂性管理、系统健壮性、能量有效使用 3 个方面的挑战。
GENESYS 架构主要提供了 3 组服务,即领域无关服务、领域专用服务和应用专用服务(包含中间件),如图 19.4 所示。
图 19.4 GENESYS 架构
(1)领域无关服务。包括核心服务和选择服务,如嵌入式系统中的全局时间和消息传输等服务为核心服务。信息安全服务、外部存储器管理器或者 Internet 网关服务等属于选择服务。
(2)领域专用服务是由领域特有的服务子集加上待开发领域特征的特定服务组合。GENESYS 架构从硬件、软件的观点遵循了面向构件的风格,分离了计算与通信,将计算构件和通信设施作为独立构件进行设计。GENESYS 架构的主要特征及优势包括:
1)精确的构件定位。具体体现为简单化、跨领域重用、规模的经济型、健壮性、可降低系统集成工作量这 5 个特征。
2)开放性。体现为具有可集成性、可升级性、可扩展性、遗产系统集成、降低成本这 5 个特征。
3)三级集成。具有芯片级集成、设备级集成、系统级集成的集成。
4)分层的服务。体现具有可重用性、领域定位、工效经济型的特性。
5)确定的核心。体现在具有及时性、降低复杂性、可测试性、认证、故障掩蔽的特征。
6)标准的互联集成。体现在对远程访问的保护、降低集成工作难度、常规人机交互、具有安全性4个方面。
- 物联网操作系统软件架构
物联网操作系统至今没有一个明确的定义。物联网操作系统通常包括芯片层、终端层、边缘层、云端层等多个层面内容。物联网操作系统使用的软件以及技术主要有:开源物联网操作系统(FreeRTOS)、公共服务组件(网络协议、外设支持、可移植操作系统接口POSIX等)定制性服务组件有:消息队列遥测传输协议(MQTT),安全超文本传输协议(HTTPS),加密消息标准PKCS#11支持,安全套件等。物联网操作系统主要特征有:内核实时性、内核尺寸伸缩性、架构可扩展性、高可靠性、低功耗。
19.6 练习题
- 以下关于鸿蒙操作系统的叙述中,不正确的是()
A.鸿蒙操作系统整体架构采用分层的层次化设计,从下向上依次为:内核层、系统服务层、框架层和应用层 B.鸿蒙操作系统内核层采用宏内核设计,拥有更强的安全特性和低时延特点 C.鸿蒙操作系统架构采用了分布式设计理念,实现了分布式软总线、分布式设备系统的虚拟化、分布式数据管理和分布式任务调度等四种分布式能力 D.架构的系统安全性主要体现在搭载HarmonyOS的分布式终端上,可以保证“正确的人,通过正确的设备,正确地使用数据”
解析:鸿蒙操作系统采用微内核架构,整体采用层次式架构,采用分布式理念且实现了分布式安全框架。
答案:B
- GENESYS架构的主要特征及优势是什么?
答案:GENESYS架构的主要特征及优势包括:
(1)精确的构件定位。具体体现为简单化、跨领域重用、规模的经济型、健壮性、可降低系统集成工作量这5个特征。(2)开放性。体现为具有可集成性、可升级性、可扩展性、遗产系统集成、降低成本这5个特征。(3)三级集成。具有芯片级集成、设备级集成、系统级集成。(4)分层的服务。体现具有可重用性、领域定位、工效经济型的特性。(5)确定的核心。体现在具有及时性、降低复杂性、可测试性、认证、故障掩蔽的特征。(6)标准的互联集成。体现在对远程访问的保护、降低集成工作难度、常规人机交互、具有安全性4个方面。
- 鸿蒙操作系统架构具有哪几个技术特性?
答案:鸿蒙操作系统架构具有4个技术特性:
(1)分布式架构用于终端操作系统,实现跨终端无缝协同体验。(2)确定时延引擎和高性能进程间通信技术,实现系统的流畅。(3)基于微内核架构,重塑终端设备的可信安全。(4)统一集成开发环境,一次开发,多端部署,实现跨终端生态共享。
- 嵌入式系统软件架构设计方法中的实时系统设计方法(DARTS)具有哪些优势和不足?
答案:DARTS方法的优势:
(1)强调将系统分解为并发任务,并提供确认任务的标准。(2)提供定义任务间接口的指南。(3)强调用任务架构图的重要性。(4)提供从实时结构化分析规格到实时结构化设计的转换。
DARTS方法的不足:
(1)DARTS使用信息隐藏技术封装数据存储,封装性不好。(2)如果实时结构化分析阶段完成得不好,那么任务的结构化工作就会更加困难。
第20小时 通信系统架构设计理论与实践
20.0 章节考点分析
第20小时主要学习通信系统架构设计的理论和工作中的实践。根据新版考试大纲,本小时知识点会涉及案例分析题(25分),而在历年考试中,案例题对该部分内容的考查并不多,虽在综合知识选择题目中经常考查,但分值也不高。本小时内容侧重于对知识点的记忆和理解,按照以往的出题规律,通信系统架构设计基础知识点多来源于教材内的基础网络设备、网络架构和教材外最新时事热点技术。本小时知识架构如图20.1所示。
图20.1 本小时知识架构
【导读小贴士】
通信系统架构是软件架构的基础设施和系统环境,在架构实践中,软件的性能、可用性、可靠性等质量属性很大程度上,受到基础设施和环境的影响,良好的基础设施能够有效地帮助提高系统架构的性能和可用性,增强可靠性。
20.1 通信系统网络架构
【基础知识点】
通信网络主要形式:局域网、广域网、移动通信网。
- 局域网网络架构
局域网是单一机构专用计算机的网络。通常由计算机、交换机、路由器等设备组成。特点是覆盖地理范围小、数据传输速率高、低误码率、可靠性高、支持多种传输介质、支持实时应用。局域网按网络拓扑分类有总线型、环型、星型、树型、层次型等类型,按传输介质分类有有线局域网、无线局域网。
局域网网络架构有4种类型:
(1)单核心架构。使用单台核心二层或三层交换设备作为网络核心。优点:结构简单,设备投资节约,接入方便。缺点:地理范围受限,核心单点故障,扩展能力有限,接入设备较多时核心端口密度要求高。 (2)双核心架构。采用两台核心三层及以上交换机作为网络核心。优点:网络拓扑结构可靠性高,接入较为方便。缺点:投资较单核心高,核心端口密度要求较高。 (3)环型架构。采用多台核心三层及以上交换机组成双动态弹性分组环(Resilient Packet Ring,RPR),作为网络核心。优点:RPR具备自愈保护,节省光纤资源,提供多等级、可靠的QoS服务,有效利用带宽资源。缺点:投资较高,路由冗余设计实施难度较高且易形成环路,多环智能通过业务接口互通无法直通。 (4)层次型架构。由核心层、汇聚层、接入层三层交换设备和用户设备组成层次模型。
1)核心层:负责高速数据转发。 2)汇聚层:提供充足接口,与接入层间实现互访控制。 3)接入层:用户设备接入。
层次型架构的优点:易扩展,分级排查网络故障便于维护。
- 广域网网络架构
广域网利用公用分组交换网、无线分组交换网、卫星通信网构建通信子网连接分布的局域网以实现资源子网的共享。广域网由骨干网、分布网、接入网组成。广域网网络架构可以分为:
| 架构类型 | 核心组成 | 优点 | 缺点 |
|---|---|---|---|
| 单核心架构 | 单台核心三层交换设备 | 结构简单;设备投资节约;局域网互访效率高;新局域网接入方便 | 核心单点故障;扩展能力欠佳;核心设备端口密度要求高 |
| 双核心架构 | 两台核心三层及以上交换机 | 网络拓扑可靠;路由可热切换;可靠性高;局域网接入方便 | 投资较高;路由冗余设计难度大;核心端口密度要求高 |
| 环型架构 | 多台核心三层及以上交换机构成路由环路 | 接入方便 | 投资高;路由冗余设计复杂;易形成环路;核心端口密度要求高 |
| 半/全冗余架构 | 多台核心路由设备互连; 任意核心间存在两条以上链路为半冗余, 任意两核心间均有链路为全冗余 | 结构灵活;路由灵活;方便扩展;可靠性高 | 结构零散;管理复杂;排障困难 |
| 对等子域架构 | 将半冗余核心划为两个独立子域,子域间通过一条或多条链路互连 | 路由控制灵活 | 子域冗余设计复杂;易形成环路或非法路由;互连设备性能要求高 |
| 层次子域架构 | 半冗余核心划为多个独立子域,存在层次关系;高层子域连接多个低层子域 | 扩展性好;路由控制灵活 | 冗余设计复杂;易形成环路或非法路由;互连设备性能要求高 |
(1)单核心架构。以单台核心三层交换设备作为网络核心。优点:结构简单,设备投资节约,局域网互访效率高,新局域网接入方便。缺点:核心单点故障,扩展能力欠佳,核心设备端口密度要求较高。 (2)双核心架构。以两台核心三层及以上交换机作为网络核心。
优点:网络拓扑结构可靠,路由可热切换,可靠性高,局域网接入较为方便。 缺点:投资较单核心高,路由冗余设计实施难度较高,核心端口密度要求较高。
(3)环型架构。以多台核心三层及以上交换机组成路由环路作为网络核心。 优点:接入方便。 缺点:投资较高,路由冗余设计实施难度较高且易形成环路,核心端口密度要求较高。
(4)半/全冗余架构。以多台核心路由设备间互连组成网络核心,如任意核心存在两条以上到其他核心的链路为半冗余架构,如任何两个核心间均存在链路为全冗余架构。 优点:结构灵活,路由灵活,方便扩展,可靠性高。 缺点:结构零散,不便管理,不便排障。
(5)对等子域架构。将半冗余核心划为两个独立子域,子域间通过一条或多条链路互连。
优点:路由控制灵活。 缺点:子域间冗余设计实施难度较高,易形成环路或存在非法路由风险,子域互连设备性能要求高。
(6)层次子域架构。半冗余核心划为多个独立子域,子域间存在层次关系,高层次子域连接多个低层次子域。
优点:扩展性较好,路由控制灵活。 缺点:子域路由冗余设计实施难度较高,易形成环路或存在非法路由风险,子域互连设备性能要求高。
- 移动通信网网络架构
5G系统为移动终端用户提供数据网络互连,数据网络可以是互联网、IP媒体子系统、专用网络。用户设备通过5G系统接入数据网络的方式有透明模式和非透明模式。在透明模式下5G系统通过用户面功能接口接入运营商网络,然后通过防火墙或者代理连至Internet。非透明模式下,5G系统可以直接或通过其他网络连接至运营商网络或Internet。
- 5G网络边缘计算
5G网络边缘计算能为垂直行业提供诸如以时间敏感、高带宽为特征的业务就近分流服务。一来为用户提供极佳的服务体验,二来降低了移动网络后端处理的压力。
- 软件定义网络(SoftwareDefinedNetwork,SDN)
SDN是一种新型网络创新架构,核心思想是通过控制与转发分离,将网络中交换设备的控制逻辑集中到一个计算设备上,控制面集中管控,提升网络管理配置能力。
1)应用层(Application Layer):这是最上层,包括各种网络应用程序和服务,它们可以通过SDN控制器提供的API来定制网络行为,比如流量路由、访问控制策略等。 2)控制层(ControlLayer):这一层的核心是SDN控制器,它集中管理网络视图、计算数据包转发路径,并下发相应的转发规则到数据平面设备。控制器是网络智能和策略决策的中心。 3)转发层(Data Plane or Forwarding Layer):数据平面由网络交换机和其他数据转发设备组成,它们根据从控制层接收的指令转发数据包,而不再需要了解完整的网络拓扑或做出复杂的路由决策。
- 存储网络架构
存储网络设计磁盘存储访问方式:直连式存储,网络附加存储,存储区域网络。
(1)直连式存储(DirectAttachedStorage,DAS):存储设备通过IDE/ATA/SCSI接口或光纤通道直接连接到单台计算机,计算机通过I/O访问存储设备,存储设备可以是硬盘驱动器、RAID阵列、CD、DVD、磁带驱动器。
(2)网络附加存储(Network Attached Storage,NAS):存储设备通过标准的网络拓扑结构连接到计算机群组,计算机通过IP局域网或广域网TPC或UDP协议,通过RPC接口访问NAS存储设备。
(3)存储区域网络(Storage Area Network,SAN):一种采用网状通道技术专门为存储建立的独立于TCP/IP网络之外的专用网络,通过网状通道交换机连接存储阵列和服务器。
3种存储网络架构的对比见表20- 1。
表20-1 存储网络架构的对比
| 对比项 | DAS | NAS | SAN |
| 架构类别 | 单机存储架构 | 网络存储架构 | 网络存储架构 |
| 访问方式 | I/O 总线 | 网络 | 网络 |
| 资源利用 | 单机存储 | 共享存储 | 共享存储 |
| 访问媒介 | 总线 | 以太网 | 以太网/光纤通道 |
| 优势特点 | 易用易管理设备成本低 | 易用易管理可扩展性高设备成本较低 | 高性能低延迟灵活性高 |
20.2 网络构建关键技术
【基础知识点】
IPv4与IPv6融合组网技术。目前网络演进还存在较长时间IPv4到IPv6过渡期或IPv4和IPv6网络共存期。现阶段主要存在3种过渡技术:双协议栈、隧道技术、网络地址翻译技术。
(1)双协议栈:两种协议在同一平台上双栈共存,同时运行。(2)隧道技术:包括ISATAP隧道、6to4隧道、over6隧道、6over4隧道。(3)网络地址翻译(Network Address Translator,NAT)技术:将IPv4地址和IPv6地址分别看作内部地址和外部地址,或者相反,以实现地址转换。
20.3 网络构建
【基础知识点】
- 网络需求分析
网络需求分析主要从业务需求、用户需求、应用需求、计算机平台需求和网络需求来进行分析。
- 网络技术选及设计
网络技术选及设计可以使用生成树协议、虚拟局域网(VLAN)、无线局域网(WLAN)、线路冗余设计、服务器冗余设计等方式。
- 广域网技术选
广域网技术遴选广域网技术遴选可以采用远程接入技术、广域网互连技术,如数字数据网络(DDN)、同步数字体系(SDH)、多业务传送平台(MSTP)、虚拟专用网络(VPN) 等。广域网性能优化策略有:预留带宽、利用拨号线路、传输数据压缩、链路聚合、数据基于优先级排序、基于协议预留带宽等方式。
- 层次化网络模型设计
层次化设计的优点是能降低成本,充分利用模块化设备/部件,网络变化或演化容易。层次化网络设计一般采用三层模型设计思路:接入层、汇聚层、核心层。每层的特点已经在第3小时的内容中介绍过了,这里不再赘述。
层次化设计的原则:
(1)控制网络层次。(2)从接入层开始,向上分析规划。(3)尽量采用模块化设计。(4)严格控制网络结构。(5)严格控制层次化结构。
- 网络安全控制技术
实施网络安全控制的相关技术主要有:
(1)防火墙。防护墙是网络间的安全屏障,可以保护本地网络资源。防火墙可以允许/拒绝/重定向数据流以及审计进出网络的访问或服务。防火墙的体系有:硬件防火墙、软件防火墙、嵌入式防火墙。防火墙的种类有包过滤、应用层网关、代理服务等。
(2)虚拟专用网络技术。该技术利用公共网络建立私有专用网络,具有成本低、接入方便、可扩展性强、管理和控制方便等优点。
(3)访问控制技术。访问控制技术主要有:自主访问控制(DAC)、强制访问控制(MAC)、基于角色的访问控制(RBAC)、基于任务的访问控制(TBAC)和基于对象的访问控制(OBAC)。
(4)网络安全隔离。将攻击隔离在网络外,保证网络内信息不外泄。形式有:子网隔离、物理隔离、VLAN隔离、逻辑隔离。
(5)网络安全协议。网络安全协议可参考第5小时的内容,这里不再赘述。
- 网络安全审计
网络安全审计用来测试、评估和分析网络脆弱性,能够实现自动响应、数据生成、分析、浏览、事件存储、事件选择等功能。
- 绿色网络设计方法
绿色网络设计采用精简设计、重用设计、回收设计的思路。设计原则有:
(1)标准化:减少转换设备,兼容异构方案。(2)集成化:减少设备总量,降低资源需求。(3)虚拟化:灵活调配,按需使用。(4)智能化:降低人力成本,降低资源占用。
20.4 练习题
- 以下不属于网络安全协议的是()。
A. FTP B. SSL C. HTTPS D. SET
解析:文件传输协议(File Transport Protocol,FTP)是网络上两台计算机传送文件的协议,运行在TCP之上,是通过Internet将文件从一台计算机传输到另一台计算机的一种途径。
答案:A
- 以下关于层次化网络设计原则的叙述中,错误的是()。
A. 一般将网络划分为核心层、汇聚层、接入层三个层次B. 应当首先设计核心层,再根据必要的分析完成其他层次设计C. 为了保证网络的层次性,不能在设计中随意加入额外连接D. 除去接入层,其他层次应尽量采用模块化方式,模块间边界应非常清晰
解析:按照层次式网络设计原则,首先要控制网络层次,一般将网络划分为核心层、汇聚层、接入层三个层次;再从接入层开始向上分析规划,因此B选项错误;其次尽量采用模块化设计,除去接入层,其他层次应尽量采用模块化方式;再次要严格控制网络结构,模块间边界应非常清晰;最后严格控制层次化结构,为了保证网络的层次性,不能在设计中随意加入额外连接。
答案:B
- ()是一种新型网络创新架构,核心思想是通过控制与转发分离,将网络中交换设备的控制逻辑集中到一个计算设备上,控制面集中管控,提升网络管理配置能力。
A.5G网络架构 B.软件定义网络 C.移动通信网网络 D.存储网络
解析:软件定义网络是一种新型网络创新架构,核心思想是通过控制与转发分离,将网络中交换设备的控制逻辑集中到一个计算设备上,控制面集中管控,提升网络管理配置能力。
答案:B
第21小时 安全架构设计理论与实践
21.0 章节考点分析
第21小时主要学习信息系统中安全架构设计的理论和工作中的实践。根据考试大纲,本小时知识点会涉及案例分析题和论文题(各占25分),而在历年考试中,综合知识选择题目中也有过诸多考查。本小时内容侧重于知识点记忆,按照以往的出题规律,安全架构设计基础知识点主要来源于教材,但随着形势和技术的发展,也可能会联系最新时事考查新颁布的安全标准。本小时知识架构如图21.1所示。
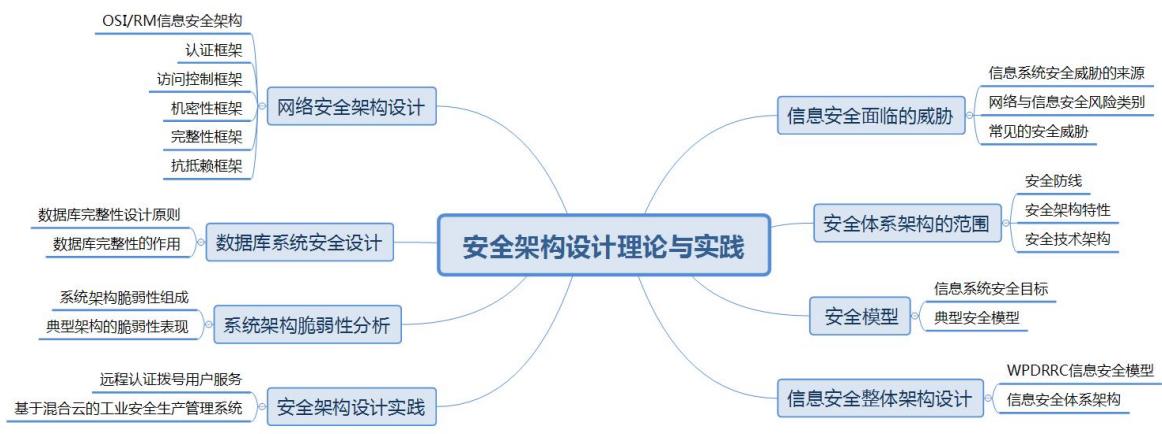
图21.1 本小时知识架构
【导读小贴士】
随着科技的发展,信息系统的安全受到诸多方面的威胁,设计信息系统安全架构需要从各个方面考虑,这是一项具有相当技术含量的工作。信息系统的安全跨越物理、网络、硬件、操作系统、软件、管理等诸多层面,是一个复杂的立体空间工程,为此业界组织了诸多机构,制定了诸多标准,也形成了不少设计方法和框架。
伴随多年的技术发展,网络安全政策法规和制度标准体系基本形成,关键信息基础设施安全保护体系和能力显著增强,数据安全治理和个人信息保护工作取得积极进展。在顶层设计框架下,数据与文件加密、数据完整性、通信安全、访问控制技术、抗攻击技术和安全评估与认证是主要的考查内容。
21.1 信息安全面临的威胁
【基础知识点】
- 信息系统安全威胁的来源
威胁可以来源于物理环境、通信链路、网络系统、操作系统、应用系统、管理系统。
- 网络与信息安全风险类别
网络与信息安全风险类别可以分为人为蓄意破坏(被动型攻击,主动型攻击)、灾害性攻击、系统故障、人员无意识行为,如图21.2所示。
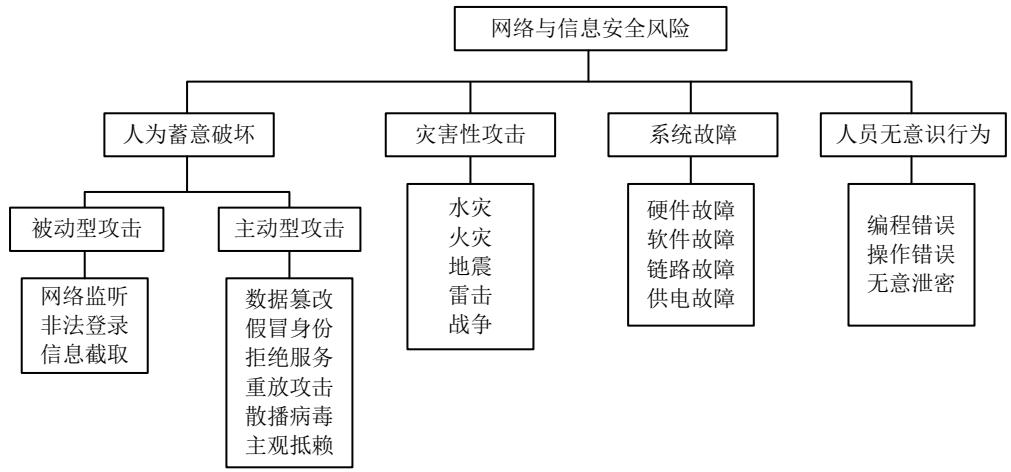
图21.2 网络与信息安全风险类别
- 常见的安全威胁
常见的威胁主要有:
(1)信息泄露。信息被泄露或透露给某个非授权的实体。(2)破坏信息的完整性。数据被非授权地进行增删、修改或破坏而受到损失。(3)拒绝服务。对信息或其他资源的合法访问被无条件地阻止。(4)非法使用(非授权访问)。某一资源被某个非授权的人或以非授权的方式使用。(5)窃听。用各种可能的合法或非法的手段窃取系统中的信息资源和敏感信息。如对通信线路中传输的信号进行搭线监听,或利用通信设备在工作过程中产生的电磁泄漏截取有用信息等。(6)业务流分析。通过对系统进行长期监听,利用统计分析方法对诸如通信频度、通信的信息流向、通信总量的变化等态势进行研究,从而发现有价值的信息和规律。(7)假冒。通过欺骗通信系统(或用户)达到非法用户冒充成为合法用户,或者特权小的用户冒充成为特权大的用户的目的。黑客大多是采用假冒的方式进行攻击。(8)旁路控制。攻击者利用系统的安全缺陷或安全性上的脆弱之处获得非授权的权利或特权。如,攻击者通过各种攻击手段发现原本应保密,但是却又暴露出来的一些系统特性。利用这些特性,攻击者就可以绕过防线守卫者侵入系统的内部。(9)授权侵犯。被授权以某一目的使用某一系统或资源的某个人,却将此权限用于其他非授权的目的,也称作内部攻击。(10)特洛伊木马。软件中含有一个察觉不出的或者无害的程序段,当它被执行时,会破坏用户的安全。这种应用程序称为特洛伊木马。(11)陷阱门。在某个系统或某个部件中设置了机关,使得当提供特定的输入数据时,允许违反安全策略。(12)抵赖。这是一种来自用户的攻击,例如,否认自己曾经发布过的某条消息、伪造一份对方来信等。(13)重放。所截获的某次合法的通信数据备份,出于非法的目的而被重新发送。(14)计算机病毒。所谓计算机病毒,是一种在计算机系统运行过程中能够实现传染和侵害的功能程序。(15)人员渎职。一个授权的人为了钱或利益,或由于粗心,将信息泄露给一个非授权的人。(16)媒体废弃。信息被从废弃的磁盘或打印过的存储介质中获得。(17)物理侵入。侵入者通过绕过物理控制而获得对系统的访问。(18)窃取。重要的安全物品遭到窃取,如令牌或身份卡被盗。(19)业务欺骗。某一伪系统或系统部件欺骗合法的用户,或使系统自愿地放弃敏感信息。
21.2 安全体系架构的范围
【基础知识点】
安全体系架构的范围包括:
(1)安全防线。分别是产品安全架构、安全技术架构、审计架构。
(2)安全架构特性。安全架构应具有:可用性、完整性、机密性的特性。
(3)安全技术架构。安全技术架构主要包括身份鉴别、访问控制、内容安全、冗余恢复、审计响应、恶意代码防范、密码技术。
21.3 安全模型
【基础知识点】
- 信息系统安全目标
信息系统安全目标是控制和管理主体对客体的访问,从而实现:
(1)保护系统可用性。(2)保护网络服务连续性。(3)防范非法非授权访问。(4)防范恶意攻击和破坏。(5)保护信息传输机密性和完整性。(6)防范病毒侵害。(7)实现安全管理。
- 典型安全模型
(1)状态机模型。一个安全状态模型系统,总是从一个安全状态启动,并且在所有迁移中保持安全状态,只允许主体以和安全策略相一致的安全方式访问资源。
(2)BLP模型(Bell-LaPadula Model)。该模型为数据规划机密性,依据机密性划分安全级别,按安全级别强制访问控制。BLP模型的基本原理是:
1)安全级别是机密的主体访问安全级别为绝密的客体时,主体对客体可写不可读。
2)安全级别是机密的主体访问安全级别为机密的客体时,主体对客体可写可读。
3)安全级别是机密的主体访问安全级别为秘密的客体时,主体对客体可读不可写。
BLP模型安全规则:
1)简单规则:低级别主体读取高级别客体受限。
2)星型规则:高级别主体写入低级别客体受限。
3)强星型规则:对不同级别读写受限。
4)自主规则:自定义访问控制矩阵。
(3)Biba模型。该模型建立在完整性级别上。模型具有完整性的三个目标:保护数据不被未授权用户更改、保护数据不被授权用户越权修改(未授权更改)、维持数据内部和外部的一致性。
Biba模型基本原理:
1)完整性级别为中完整性的主体访问完整性为高完整性的客体时,主体对客体可读不可写,也不能调用主体的任何程序和服务。
2)完整性级别为中完整性的主体访问完整性为中完整性的客体时,主体对客体可读可写。
3)当完整性级别为中完整性的主体访问完整性为低完整性的客体时,主体对客体可写不可读。
Biba模型可以防止数据从低完整性级别流向高完整性级别,其安全规则如下:
1)星完整性规则。表示完整性级别低的主体不能对完整性级别高的客体写数据。
2)简单完整性规则。表示完整性级别高的主体不能从完整性级别低的客体读取数据。
3)调用属性规则。表示一个完整性级别低的主体不能从级别高的客体调用程序或服务。
(4)CWM模型(Clark-Wilson Model)。将完整性目标、策略和机制融为一体,提出职责分离目标,应用完整性验证过程,实现了成型的事务处理机制,常用于银行系统。CWM模型具有以下特征:
1)包含主体、程序、客体三元素,主体只能通过程序访问客体。
2)权限分离原则,功能可分为多主体,防止授权用户进行未授权修改。
3)具有审计能力。
(5)Chinese Wall模型,是一种混合策略模型,应用于多边安全系统,防止多安全域存在潜在的冲突。该模型为投资银行设计,常见于金融领域。工作原理是通过自主访问控制(DAC)选择安全域,通过强制访问控制(MAC)完成特定安全域内的访问控制。
Chinese Wall模型的安全规则:
1)墙内客体可读取。2)不同利益冲突组客体可读取。3)访问其他公司客体和其他利益冲突组客体后,主体对客体写入受限。
21.4 信息安全整体架构设计
【基础知识点】
(1)WPDRRC信息安全模型。WPDRRC模型包括6个环节:预警(Warning)、保护(Protect)、检测(Detect)、响应(React)、恢复(Restore)、反击(Counterattack);3个要素:人员、策略、技术。
(2)信息安全体系架构。具体可以从以下5个方面开展安全体系的架构设计工作:
1)物理安全(前提),包括环境安全、设备安全、媒体安全。
2)系统安全(基础),包括网络结构安全、操作系统安全、应用系统安全。
3)网络安全(关键),包括访问控制、通信保密、入侵检测、网络安全扫描、防病毒。
4)应用安全:包括资源共享、信息存储。
5)安全管理:包括健全的体制、管理平台、人员安全防范意识。
21.5 网络安全架构设计
【基础知识点】
(1)OSI/RM信息安全架构,如图21.3所示。其中,安全服务和安全机制的对应关系如图21.4所示。
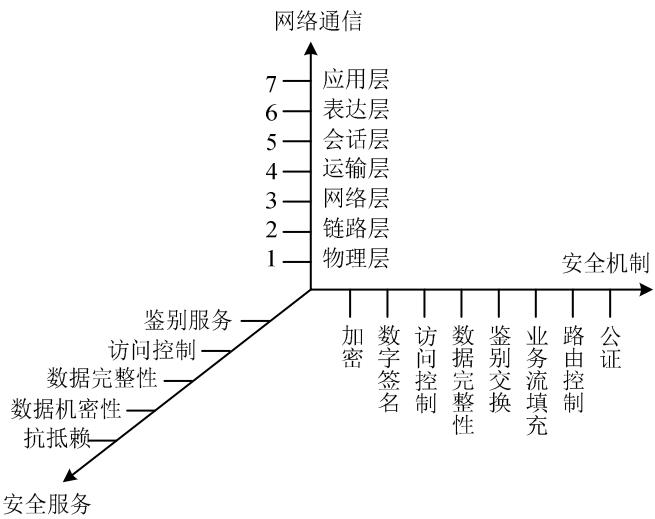
图21.3 OSI/RM信息安全架构
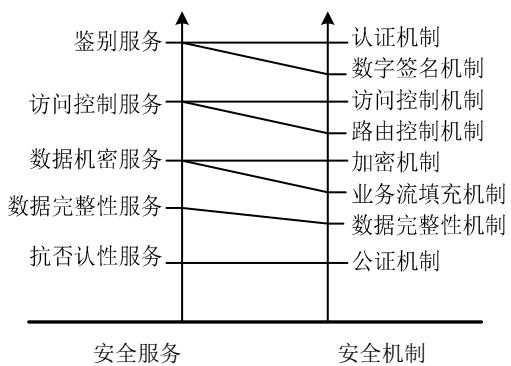
图21.4 安全服务和安全机制的对应关系
OSI定义了分层多点的安全技术体系架构,又叫深度防御安全架构,它通过以下3种方式将防御能力分布至整个信息系统中。
1)多点技术防御:通过网络和基础设施,边界防御(流量过滤、控制、如前检测),计算环境等方式进行防御。
2)分层技术防御:外部和内部边界使用嵌套防火墙,配合入侵检测进行防御。
3)支撑性基础设施:使用公钥基础设施以及检测和响应基础设施进行防御。
(2)认证框架。认证又叫鉴权,其目的是防止其他实体占用和独立操作被鉴别实体的身份。鉴别的方式有:已知的(口令)、拥有的(IC卡,令牌等)、不可变特征(生物特征)、受信第三方鉴别、环境(主机地址)。鉴别服务阶段分为:安装、修改鉴权信息、分发、获取、传送、验证、停活、重新激活、取消安装。
(3)访问控制框架。当发起者请求对目标进行特殊访问时,访问控制管制设备(Access Control Enforcement Facilities,ADF)就通知访问控制决策设备(Access Control Decision Facilities,ADF),ADF可以根据上下文信息(包括发起者的位置、访问时间或使用中的特殊通信路径)以及可能还有以前判决中保留下来的访问控制决策信息(Access Control Decision Information,ADI)做出允许或禁止发起者试图对目标进行访问的判决。
(4)机密性框架。机密性服务目的是确保信息仅仅是对被授权者可用。机密性机制包括:通过禁止访问提供机密性、通过加密提供机密性。
(5)完整性框架。完整性服务目的是组织威胁或探测威胁,保护数据及其相关属性的完整性。完整性服务分类有:未授权的数据创建、数据创建、数据删除、数据重放。完整性机制类型分为阻止媒体访问与探测非授权修改两种。
(6)抗抵赖框架。抗抵赖服务的目的是提供特定事件或行为的证据。抗抵赖服务阶段分为:证据生成、证据传输、存储及回复、证据验证、解决纠纷这5个阶段。
21.6 数据库系统安全设计
【基础知识点】
- 数据库完整性设计原则
完整性设计原则具体包括:
(1)依据完整性约束类型设计其实现的系统层次和方式,并考虑性能。(2)在保障性能的前提下,尽可能应用实体完整性约束和引用完整性约束。(3)慎用触发器。(4)制订并使用完整性约束命名规范。(5)测试数据库完整性,尽早排除冲突和性能隐患。(6)设有数据库设计团队,参与数据库工程全过程。(7)使用CASE工具,降低工作量,提高工作效率。
- 数据库完整性的作用
数据库完整性的作用体现在以下几个方面:
(1)防止不合语义的数据入库。(2)降低开发复杂性,提高运行效率。(3)通过测试尽早发现缺陷。
21.7 系统架构脆弱性分析
【基础知识点】
- 系统架构脆弱性组成
系统架构脆弱性包括物理装备脆弱性、软件脆弱性、人员管理脆弱性、规章制度脆弱性、安全策略脆弱性等。
- 典型架构的脆弱性表现
(1)分层架构。分层脆弱性体现在:
1)层间脆弱性:一旦某个底层发生错误,那么整个程序将会无法正常运行。
2)层间通信脆弱性:如在面向对象方法中,将会存在大量对象成员方法的调用(消息交互),这种层层传递,势必造成性能的下降。
(2)C/S架构。这种架构的脆弱性有:客户端脆弱性、网络开放性脆弱性、网络协议脆弱性。
(3)B/S架构。如果B/S架构使用的是HTTP协议,会更容易被病毒入侵。
(4)事件驱动架构。事件驱动架构的脆弱性体现在:组件脆弱性、组件间交换数据的脆弱性、组件间逻辑关系的脆弱性、事件驱动容易死循环、高并发脆弱性、固定流程脆弱性。
(5)MVC架构。MVC架构的脆弱性体现在以下3方面:
1)复杂性脆弱性。如一个简单的界面,如果严格遵循MVC方式,使得模型、视图与控制器分离,会增加结构的复杂性,并可能产生过多的更新操作,降低运行效率。
2)视图与控制器连接紧密脆弱性。视图与控制器是相互分离但却是联系紧密的部件,如果没有控制器的存在,视图应用是有限的。反之亦然,这就妨碍了它们的独立重用。
3)视图对模型低效率访问脆弱性。依据模型操作接口的不同,视图可能需要多次调用才能获得足够的显示数据。对未变化数据的不必要的频繁访问也将损害操作性能。
(6)微内核架构。微内核架构的脆弱性体现在:
1)整体优化脆弱性。微内核系统的核心态只实现了最基本的系统操作,因此内核以外的外部程序之间的独立运行使得系统难以进行良好的整体优化。
2)进程通信开销脆弱性。微内核系统的进程间通信开销也较单一内核系统要大得多。
3)通信损失脆弱性。微内核把系统分为各个小的功能块,从而降低了设计难度,系统的维护与修改也容易,但带来的问题是通信效率的损失。
(7)微服务架构。微服务架构的脆弱性体现在:
1)分布式结构复杂带来的脆弱性。开发人员需要处理分布式系统的复杂结构。
2)服务间通信带来的脆弱性。开发人员要设计服务之间的通信机制,通过写代码来处理消息传递中速度过慢或者不可用等局部实效问题。
3)服务管理复杂性带来的脆弱性。在生产环境中要管理多个不同的服务实例,这意味着开发
团队需要全局统筹。
21.8 安全架构设计实践
【基础知识点】
- 远程认证拨号用户服务(Remote Authentication Dial-In User Service,RADIUS)
RADIUS 是应用最广泛的高安全级别认证、授权、审计协议(Authentication,Authorization,Accounting,AAA),具有高性能和高可扩展性,且可用多种协议实现。
RADIUS 通常由协议逻辑层,业务逻辑层和数据逻辑层 3 层组成层次式架构。
(1)协议逻辑层:起到分发处理功能,相当于转发引擎。(2)业务逻辑层:实现认证、授权、审计三种类型业务及其服务进程间的通信。(3)数据逻辑层:实现统一的数据访问代理池,降低数据库依赖,减少数据库压力,增强系统的数据库适应能力。
- 基于混合云的工业安全生产管理系统
混合云融合了公有云和私有云。在基于混合云的工业安全生产管理系统中,工厂内部的产品设计、数据共享、生产集成使用私有云实现。公有云则用于公司总部与智能工厂间的业务管理、协调和统计分析等。整个生产管理系统架构采用层次式架构,分为设备层、控制层、设计/管理层、应用层,如图 21.5 所示。
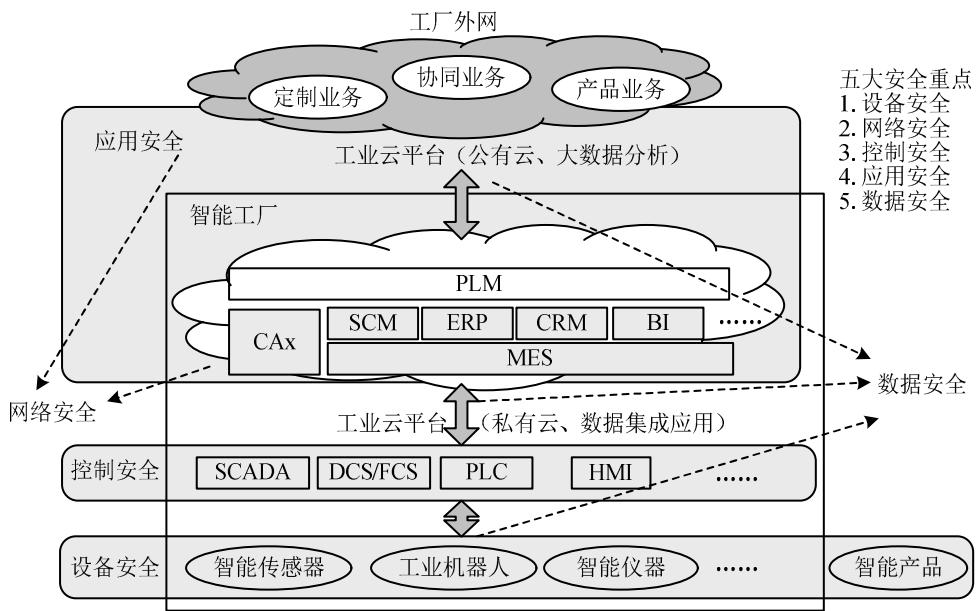
图 21.5 基于混合云的安全生产管理系统架构图
(1)设备层:包括智能工厂生产用设备,包括智能传感器、智能仪器仪表、工业机器人、其他生产设备。
(2)控制层:包括智能设备控制用自动控制系统,包括采集与监视控制系统(Supervisory Control and Data Acquisition,SCADA)、分布式控制系统(Distributed Control System,DCS)、现场总线控制系统(Fieldbus Control System,FCS)、可编程控制器(Programmable Logic Controller,PLC)(内置编程程序)、人机接口(Human Machine Interface,HMI),其他现场控制程序。
(3)设计/管理层:包括智能工厂所有控制开发,业务控制和数据管理相关系统及其功能的集合,实现了数据集成和应用,包括制造执行系统(Manufacturing Execution System,MES)(很多企业称之为生产信息管理系统)、计算机辅助设计/工程/制造CAD/CAE/CAM、供应链管理(Supply Chain Management,SCM)、企业资源规划(ERP)、客户关系管理(Customer Relationship Management,CRM)、供应商关系管理(Supplier Relationship Management,SRM)、商业智能分析(Business Intelligence,BI)、产品生命周期管理(Product Life-Cycle Management,PLM)。
(4)应用层:云平台上的信息处理,包括数据处理与管理、数据与行业应用相结合,如定制业务、协同业务、产品服务。
在设计基于混合云的工业安全生产管理系统时,需要考虑的安全问题有:设备安全、网络安全、控制安全、应用安全和数据安全。
21.9 练习题
- 以下属于主动攻击的是()
A.网络监听 B.信息截取 C.非法登录 D.假冒身份
解析:主动攻击会对信息进行修改、伪造,而被动攻击只是非法获取信息,不会对信息进行任何修改。
答案:D
- 信息安全策略应该全面地保护信息系统整体的安全,网络安全体系设计是网络逻辑设计工作的重要内容之一,可从物理线路安全、网络安全、系统安全、应用安全等方面来进行安全体系的设计与规划。其中,数据库的容灾属于()的内容。
A.物理线路安全与网络安全 B.网络安全与系统安全 C.物理线路安全与系统安全 D.网络安全与应用安全
解析:依据信息安全体系架构,物理安全包括环境、设备和媒体,系统安全包括网络结构、操作系统、应用系统,网络安全包括访问控制、通信保密、入侵检测、网络安全扫描、防病毒,应用安全包括资源共享和信息存储。数据库容灾属于对信息存储方面的安全和网络方面的安全。
答案:D
- ()模型为数据规划机密性,依据机密性划分安全级别,按安全级别强制访问控制。
A.BLP模型 B.状态机模型 C.Biba模型 D.CWM模型
解析:Bell- LaPadula 模型(BLP 模型)。该模型为数据规划机密性,依据机密性划分安全级别,按安全级别强制访问控制。
答案:A
- “在某个系统或某个部件中设置了‘机关’,使得当提供特定的输入数据时,允许违反安全策略。”属于哪一种安全威胁?
A.特洛伊木马 B.陷阱门 C.窃取 D.非法使用
解析:陷阱门是在某个系统或某个部件中设置了“机关”,使得当提供特定的输入数据时,允许违反安全策略。
答案:B
- 软件脆弱性是软件中存在的弱点(或缺陷),利用它可以危害系统安全策略,导致信息丢失、系统价值和可用性降低。嵌入式系统软件架构通常采用分层架构,它可以将问题分解为一系列相对独立的子问题,局部化在每一层中,从而有效地降低单个问题的规模和复杂性,实现复杂系统的分解。但是,分层架构仍然存在脆弱性。常见的分层架构的脆弱性包括()等两方面。
A.底层发生错误会导致整个系统无法正常运行、层与层之间功能引用可能导致功能失效B.底层发生错误会导致整个系统无法正常运行、层与层之间引入通信机制势必造成性能下降C.上层发生错误会导致整个系统无法正常运行、层与层之间引入通信机制势必造成性能下降D.上层发生错误会导致整个系统无法正常运行、层与层之间的功能引用可能导致功能失效
解析:层次式架构的软件脆弱性主要表现在层间脆弱性和层间通信脆弱性两个方面,层间脆弱性体现在某个底层的错误会导致整个系统都无法正常工作,层间通信脆弱性表现在层次间引入通信机制会造成大量消息交互,从而造成系统性能下降。
答案:B
第22小时 大数据架构设计理论与实践
22.0 章节考点分析
第22小时主要学习大数据方向软件架构的发展和工作中的实践。根据考试大纲,本小时知识点会涉及案例分析题和论文题(各占25分)。本小时内容侧重于理解性记忆,按照以往的出题规律,部分基础知识点来源于教材,部分考查内容需要灵活运用相关知识点。本小时知识架构如图22.1所示。
图22.1 本小时知识架构
【导读小贴士】
大数据架构主要面向大数据的容量体量、类型多样、高速实时、客观真实、价值可观、变化多样和复杂多源的特性,既要构建高质量属性的架构解决方案,又受制于成本、性能、可扩展性等诸多条件。同时,云计算、物联网以及边缘计算等客观环境的发展,也对大数据架构的设计提出了弹性、容器化等新的要求。
伴随多年的研究,当前主要技术实践中以Lambda架构、Kappa架构和IOTA架构较为典型,但新版考试大纲中主要考查Lambda架构、Kappa架构在设计中的理论、理解及实践。
22.1 传统数据处理系统的问题
【基础知识点】
- 传统数据库的数据过载问题
传统应用的数据系统架构设计时,应用直接访问数据库系统。当用户访问量增加时,数据库无法支撑日益增长的用户请求的负载,从而导致数据库服务器无法及时响应用户请求,出现超时的错误。关于这个问题的常用解决方法如下:
(1)增加异步处理队列,通过工作处理层批量处理异步处理队列中的数据修改请求。(2)建立数据库水平分区,通常建立Key分区,以主键/唯一键Hash值作为Key。(3)建立数据库分片或重新分片,通常专门编写脚本来自动完成,且要进行充分测试。(4)引入读写分离技术,主数据库处理写请求,通过复制机制分发至从数据库。(5)引入分库分表技术,按照业务上下文边界拆分数据组织结构,拆分单数据库压力。
2.大数据的特点
大数据具有体量大、时效性强的特点,并非构造单调,而是类型多样;处理大数据时,传统数据处理系统因数据过载,来源复杂,类型多样等诸多原因性能低下,需要采用以新式计算架构和智能算法为代表的新技术;大数据的应用重在发掘数据间的相关性,而非传统逻辑上的因果关系;因此,大数据的目的和价值就在于发现新的知识,洞悉并进行科学决策。现代大数据处理技术,主要分为以下几种:
(1)基于分布式文件系统Hadoop。(2)使用Map/Reduce或Spark数据处理技术。(3)使用Kafka数据传输消息队列及Avro二进制格式。
3.大数据利用过程
大数据的利用过程分为:采集、清洗、统计和挖掘4个过程。
22.2 大数据处理系统架构分析
【基础知识点】
(1)大数据处理系统面临的挑战主要有:
1)如何利用信息技术等手段处理非结构化和半结构化数据。
2)如何探索大数据复杂性、不确定性特征描述的刻画方法及大数据的系统建模。
3)数据异构性与决策异构性的关系对大数据知识发现与管理决策的影响。
(2)大数据处理系统应具有的属性和特征包括:鲁棒性和容错性、低延迟、横向扩展(通过增强机器性能扩展)、通用、可扩展、即席查询(用户按照自己的要求进行查询)、最少维护和可调试。
22.3 典型的大数据架构
【基础知识点】
- Lambda架构
Lambda架构是一种用于同时处理离线和实时数据的、可容错的、可扩展的分布式系统,如图22.2所示。
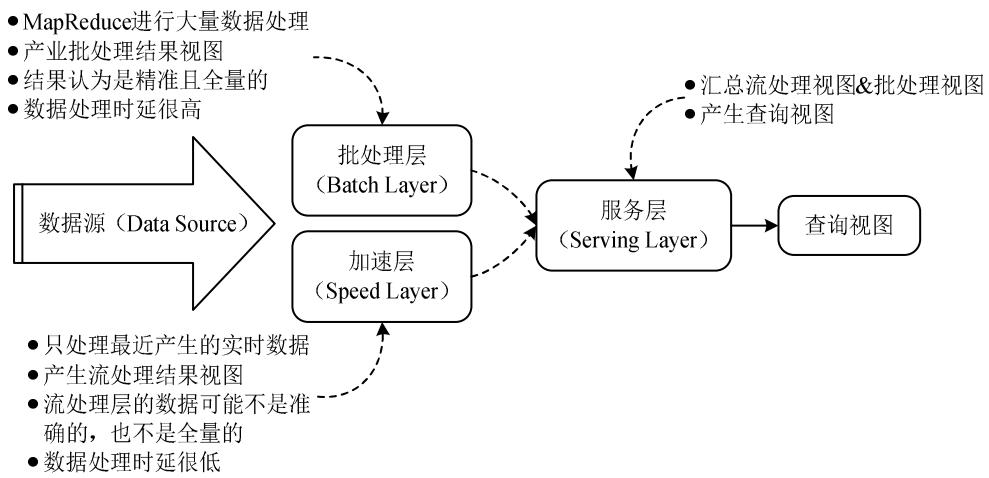
图22.2 Lambda架构
Lambda架构分为以下3层:
(1)批处理层。该层核心功能是存储主数据集,主数据集数据具有原始、不可变、真实的特征。批处理层周期性地将增量数据转储至主数据集,并在主数据集上执行批处理,生成批视图。架构实现方面可以使用Hadoop HDFS或HBase存储主数据集,再利用Spark或MapReduce执行周期批处理,之后使用MapReduce创建批视图。
(2)加速层。该层的核心功能是处理增量实时数据,生成实时视图,快速执行即席查询。架构实现方面可以使用 Hadoop HDFS 或 HBase 存储实时数据,利用 Spark 或 Storm 实现实时数据处理和实时视图。
(3)服务层。该层的核心功能是响应用户请求,合并批视图和实时视图中的结果数据集得到最终数据集。具体来说就是接收用户请求,通过索引加速访问批视图,直接访问实时视图,然后合并两个视图的结果数据集生成最终数据集,响应用户请求。架构实现方面可以使用 HBase 或 Cassandra 作为服务层,通过 Hive 创建可查询的视图。
Lambda架构的优点:容错性好,查询灵活度高,弹性伸缩,易于扩展。
Lambda架构的缺点:编码量大,持续处理成本高,重新部署和迁移成本高。
与Lambda架构相似的模式有事件溯源模式、命令查询职责分离模式。
- Kappa架构
Kappa架构是在Lambda架构的基础上进行了优化,删除了Batch Layer的架构,将数据通道以消息队列进行替代,如图22.3所示。
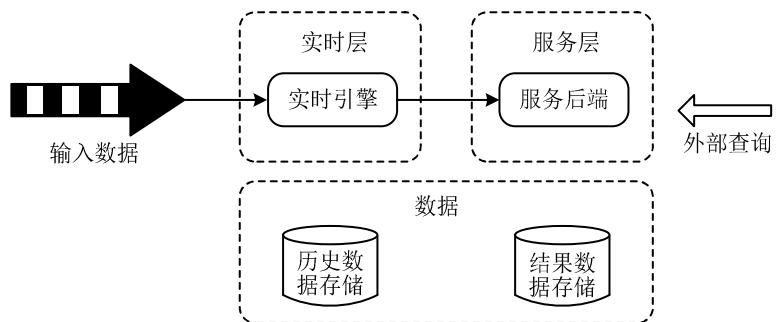
图22.3 Kappa架构
Kappa架构分为如下2层:
(1)实时层。该层核心功能是处理输入数据,生成实时视图。具体来说是采用流式处理引擎逐条处理输入数据,生成实时视图。架构实现方式是采用Apache Kafka回访数据,然后采用Flink或Spark Streaming进行处理。
(2)服务层。该层核心功能是使用实时视图中的结果数据集响应用户请求。实践中使用数据湖中的存储作为服务层。
因此Kappa架构本质上是通过改进Lambda架构中的加速层,使它既能够进行实时数据处理,同时也有能力在业务逻辑更新的情况下重新处理以前处理过的历史数据。
Kappa架构的优点是将离线和实时处理代码进行了统一,方便维护。缺点是消息中间件有性能瓶颈、数据关联时处理开销大、抛弃了离线计算的可靠性。
Kappa架构常见变形是Kappa+架构,如图22.4所示;混合分析系统Kappa架构,如图22.5所示。
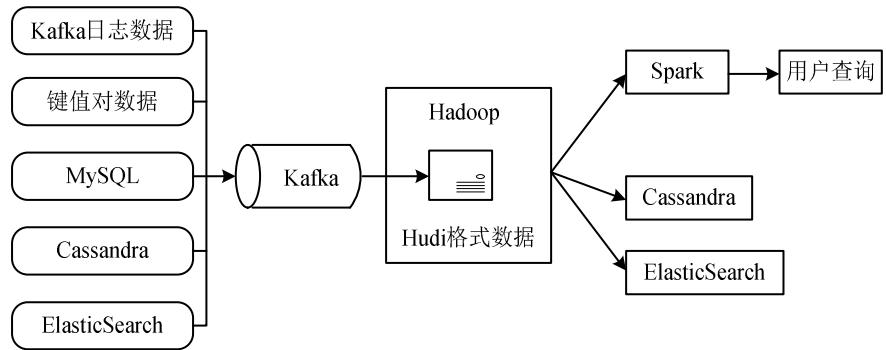
图22.4 Kappa+架构
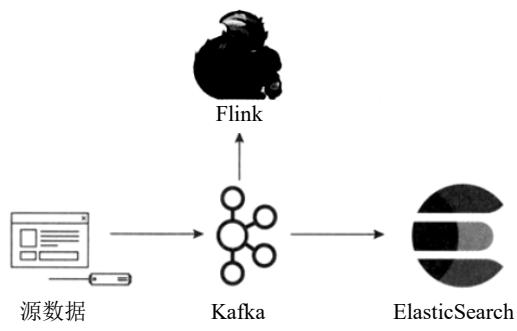
图22.5 混合分析系统Kappa架构
- Lambda架构与Kappa架构的对比
两种架构特性对比,见表22.1。
表22.1 Lambda架构和Kappa架构特性对比
| 对比内容 | Lambda架构 | Kappa架构 |
| 复杂度与开发维护成本 | 维护两套系统(引擎),复杂度高,成本高 | 维护一套系统(引擎)复杂度低,成本低 |
| 计算开销 | 周期性批处理计算,持续实时计算计算开销大 | 必要时进行全量计算计算开销相对较小 |
| 实时性 | 满足实时性 | 满足实时性 |
| 历史数据处理能力 | 批式全量处理,吞吐量大历史数据处理能力强批视图与实时视图存在冲突可能 | 流式全量处理,吞吐量相对较低历史数据处理能力相对较弱 |
对于两种架构设计的选择可以从以下4个方面考虑,见表22.2。
表22.2 影响Lambda架构和Kappa架构选择的决策因素
| 设计考虑 | Lambda架构 | Kappa架构 |
| 业务需求与技术要求 | 依赖 Hadoop、Spark、Storm 技术 | 依赖 Flink 计算引擎,偏流式计算 |
| 复杂度 | 实时处理和离线处理结果可能不一致 | 频繁修改算法模型参数 |
| 开发维护成本 | 成本预算充足 | 成本预算有限 |
| 历史数据处理能力 | 频繁使用海量历史数据 | 仅使用小规模数据集 |
22.4 大数据架构的实践
【基础知识点】
- 大规模视频网络
某网采用以Lambda架构搭建的大数据平台处理里约奥运会大规模视频网络观看数据,具体平台架构设计如图22.6所示。
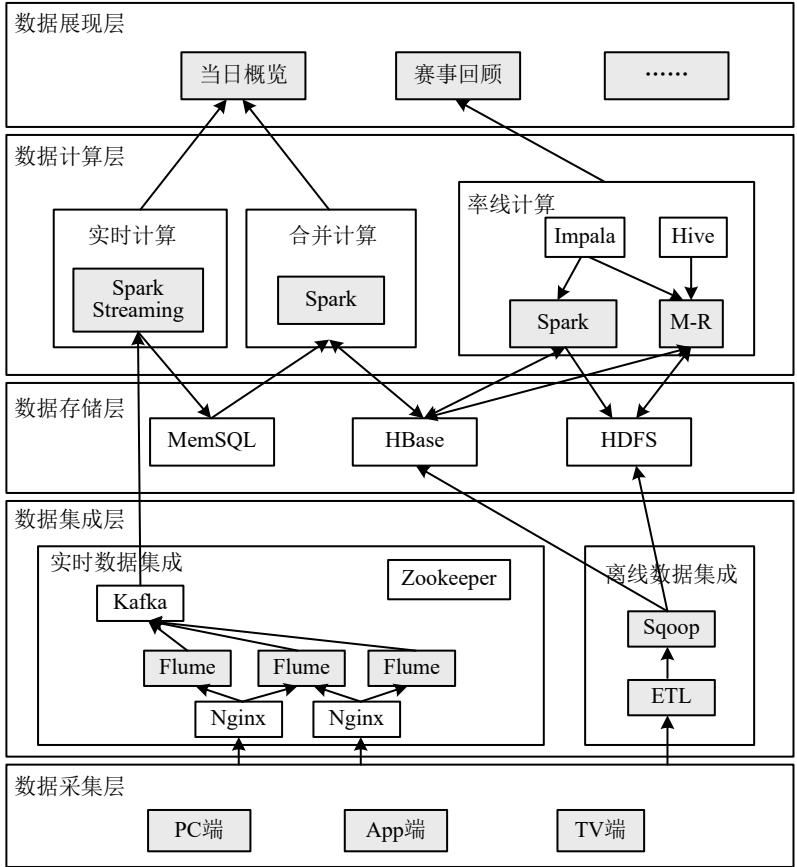
图22.6 某网奥运会视频网络平台架构设计
对于图22.6中的数据计算层可以分为离线计算、实时计算、合并计算3个部分。
(1)离线计算部分:用于存储持续增长的批量离线数据,并且会周期性地使用Spark和Map/Reduce进行批处理,将批处理结果更新到批视图之后使用Impala或者Hive建立数据仓库,将结果写入HDFS中。
(2)实时计算部分:采用Spark Streaming,只处理实时增量数据,将处理后的结果更新到实时视图。
(3)合并计算部分:合并批视图和实时视图中的结果,生成最终数据集,将最终数据集写入HBase数据库中用于响应用户的查询请求。
- 广告平台
广告平台某网基于Lambda架构的广告平台,分为批处理层(Batch Layer)、加速层(Speed Layer)、服务层(Serving Layer),如图22.7所示。
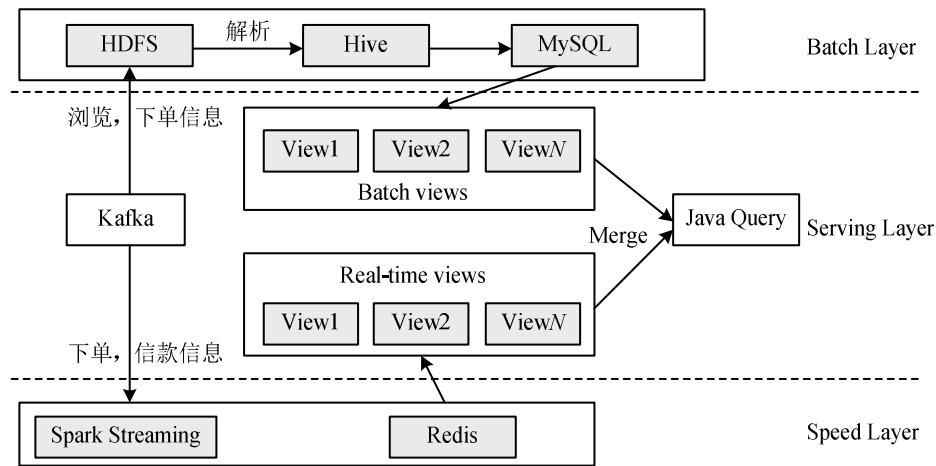
图22.7 某网广告平台Lambda架构
(1)批处理层:每天凌晨将Kafka中浏览、下单等消息同步到HDFS中,将HDFS中数据解析为Hive表,然后使用HQL或Spark SQL计算分区统计结果Hive表,将Hive表转储到MySQL中作为批视图。
(2)加速层:使用Spark Streaming实时监听Kafka下单、付款等消息,计算每个追踪链接维度的实时数据,将实时计算结果存储在Redis中作为实时视图。
(3)服务层:采用Java Web服务,对外提供HTTP接口,Java Web服务读取MySQL批视图表和Redis实时视图表。
- 公司智能决策大数据系统
某证券公司智能决策大数据系统是一个基于Kappa架构的实时日志分析平台,如图22.8所示。具体的实时处理过程如下:
(1)日志采集:用统一的数据处理引擎Filebeat实时采集日志并推送给Kafka缓存。
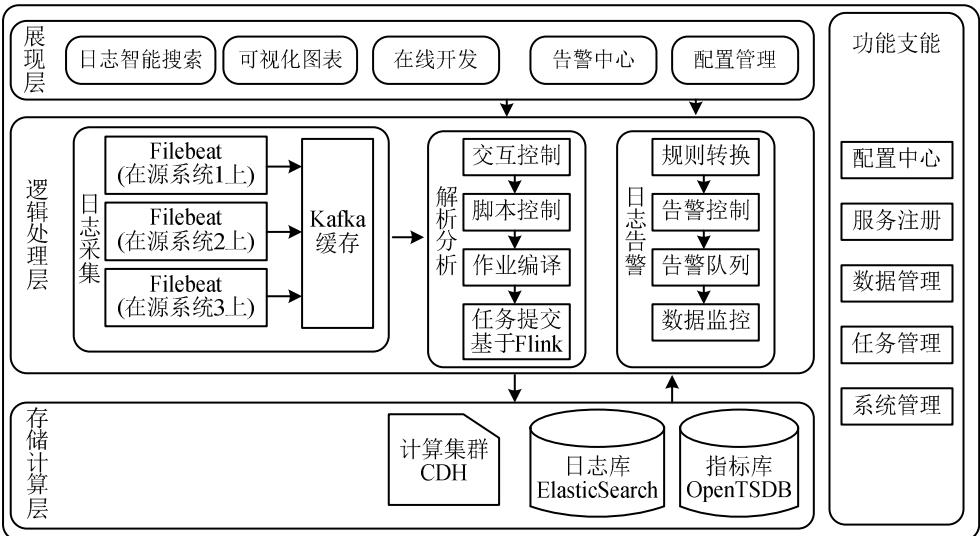
图22.8 某证券公司大数据系统Kappa架构
(2)日志清洗解析:利用基于大数据计算集群的Flink计算框架实时读取Kafka消息并进行清洗,解析日志文本转换成指标。
(3)日志存储:日志转储到ElasticSearch日志库,指标转储到OpenTSDB指标库。
(4)日志监控:单独设置告警消息队列,保持监控消息时序管理和实时推送。
- 电商智能决策大数据系统
该智能决策大数据平台基于Kappa架构,使用统一的数据处理引擎Flink可实时处理流数据,并将其存储到数据仓库工具Hive与分布式缓存Tair中,以供后续决策服务的使用。如图22.9所示。
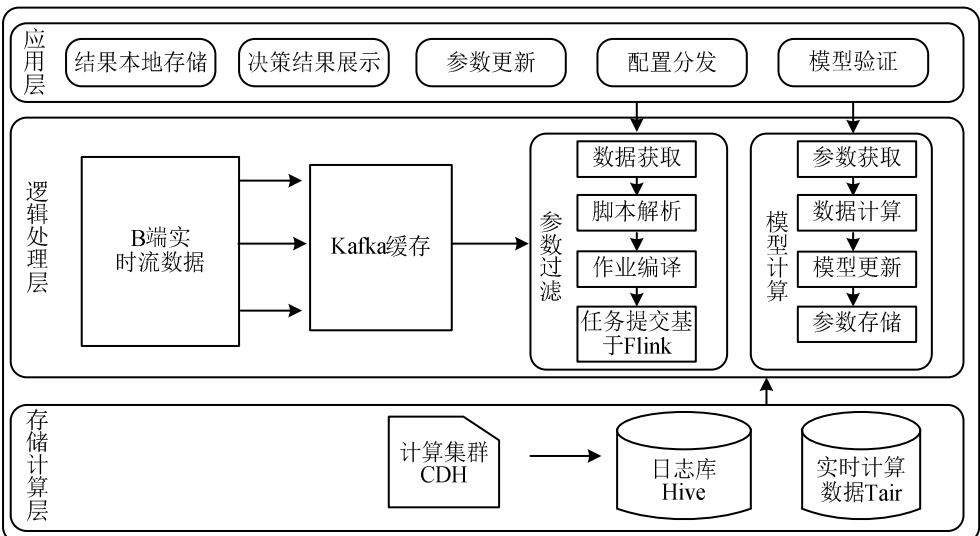
图22.9 某电商智能决策Kappa架构
实时处理的过程如下:
(1)数据采集:B端实时采集用户点击、下单、广告曝光、出价等数据然后推送给Kafka缓存。(2)数据清洗聚合:由Flink实时读取Kafka消息,按需过滤参与业务需求的指标,将聚合时间段的数据转换成指标。(3)数据存储:Flink将计算结果转储至Hive日志库,将模型需要的参数转储至实时计算数据库Tair缓存,然后后续决策服务从Tair中获取数据进行模型训练。
22.5 练习题
- 以下关于大数据的说法中,错误的是()。
A. 大数据拥有体量大、构造单调、时效性强等特点
B. 处理大数据需要采用新式计算架构和智能算法等新技术
C. 大数据的应用着重相关剖析,而不是因果剖析
D. 大数据的目的在于发现新的知识,洞悉并进行科学决策
解析:大数据具有体量大、时效性强的特征,并非构造单调,而是类型多样;处理大数据时,传统数据处理系统因数据过载,来源复杂,类型多样等诸多原因性能低下,需要采用以新式计算架构和智能算法为代表的新技术;大数据的应用重在发掘数据间的相关性,而非传统逻辑上的因果关系;因此,大数据的目的和价值就在于发现新的知识,洞悉并进行科学决策。
答案:A
- Lambda 架构分为三层:(1)的核心功能是存储主数据集。(2)的核心功能是处理增量实时数据,生成实时视图,快速执行即席查询。(3)的核心功能是响应用户请求,合并批视图和实时视图中的结果数据集得到最终数据集。
(1)A. 批处理层 B. 流处理层 C. 加速层 D. 存储层
(2)A. 批处理层 B. 服务层 C. 加速层 D. 视图层
(3)A. 视图层 B. 流处理层 C. 服务层 D. 存储层
解析:Lambda 架构分为 3 层:
(1)批处理层。该层的核心功能是存储主数据集,主数据集数据具有原始、不可变、真实的特征。批处理层周期性地将增量数据转储至主数据集,并在主数据集上执行批处理,生成批视图。架构实现方面可以使用 Hadoop HDFS 或 HBase 存储主数据集,再利用 Spark 或 Map/Reduce 执行周期批处理,之后使用 Map/Reduce 创建批视图。
(2)加速层。该层的核心功能是处理增量实时数据,生成实时视图,快速执行即席查询。架构实现方面可以使用 Hadoop HDFS 或 HBase 存储实时数据,利用 Spark 或 Storm 实现实时数据处理和实时视图。
(3)服务层。该层的核心功能是响应用户请求,合并批视图和实时视图中的结果数据集得到
最终数据集。具体来说就是接收用户请求,通过索引加速访问批视图,直接访问实时视图,然后合并两个视图的结果数据集生成最终数据集,响应用户请求。架构实现方面可以使用 HBase 或 Cassandra 作为服务层,通过 Hive 创建可查询的视图。
答案:A C C
3.某互联网公司近期为其旗下产品升级架构,架构图如图 22.10 所示,请指出该架构图采用的是什么架构,并结合架构图说明该架构的层次结构。
解析:根据题目给出的架构图可发现,该产品通过 Collector 收集结构化数据推送给主 Kafka。主 Kafka 再将数据写入 HDFS 分布式文件系统,而异构数据通过 DataX/Sqoop 写入 HDFS。HDFS 中的数据会通过 Offline 采用 Hive、MapReduce 或 Spark 进行离线处理,还会通过 OLAP 采用 Kylin 或 Naix 进行联机分析处理后存储至由非各类关系型数据库组成的处理结果存储。主 Kafka 会通过分发机制将数据分发给 Kafka,从而将数据转交给 Flink/Storm 订阅者。Flink/Storm 会对数据进行流式实时处理,再将处理结果存储至处理结果存储。OneDataAPI 通过非关系型数据库中的处理结果对数据平面 DataFace 和业务系统提供数据服务。通过分析架构图可知,该架构图采用的是 Lambda 架构。
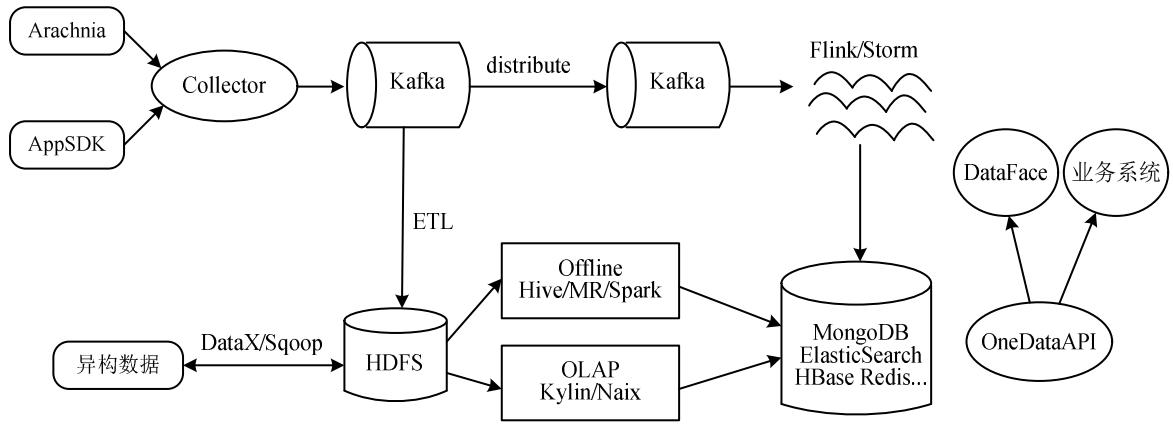
图 22.10 练习题用图
答案:该架构图采用的是 Lambda 架构,该架构由如下层次组成:
(1)数据采集层:Collector、DataX/Sqoop。(2)数据源:HDFS。(3)批处理层:Offline(Hive/MR/Spark),OLAP(Kylin/Naix)。(4)加速层:Flink/Storm。(5)服务层:结果视图存储(MongoDB、ElasticSearch、HBase、Redis…),OneDataAPI。
第5篇 架构设计补充知识
第23小时 知识产权
23.0 章节考点分析
第23小时主要学习国家与行业标准、知识产权的内容。根据考试大纲,本小时知识点会涉及单项选择题,按以往全国计算机技术与软件专业技术资格(水平)考试的命题规律约占3分。本小时内容属于补充知识范畴,考题类型固定。本小时知识架构如图23.1所示。
图23.1 本小时知识架构
【导读小贴士】
作为一个合格的系统架构设计师不仅要技术水平过硬,更要懂得法律法规的重要性,以作为衡量日常工作行为规范的准绳。本小时精选了一些考试中会涉及的知识产权方面的法律法规的条款,
这部分内容不难理解,希望广大考生认真学习。
23.1 知识产权的特性
知识产权具有如下特性。
1. 无体性
知识产权的对象没有具体形体,不能用五官触觉去感受,是一种抽象财富。
2. 专有性
知识产权的专有性指除权利人同意或法律规定外,权利人以外的任何人不得享有或使用该项权利。
3. 地域性
知识产权的地域性是指知识产权只在授予其权利的国家或确认其权利的国家产生,并且只能在该国范围内受法律保护,而其他国家则对其没有必须给予法律保护的义务。
4. 时间性
知识产权一旦超过规定的法律期限,相关知识产品即成为整个社会的共同财富,为全人类共同使用。
23.2 中华人民共和国著作权法
第三条本法所称的作品,是指文学、艺术和科学领域内具有独创性并能以一定形式表现的智力成果,包括:
(一)文字作品;(二)口述作品;(三)音乐、戏剧、曲艺、舞蹈、杂技艺术作品;(四)美术、建筑作品;(五)摄影作品;(六)视听作品;(七)工程设计图、产品设计图、地图、示意图等图形作品和模型作品;(八)计算机软件;(九)符合作品特征的其他智力成果。
第五条 本法不适用于:
(一)法律、法规,国家机关的决议、决定、命令和其他具有立法、行政、司法性质的文件,及其官方正式译文;(二)单纯事实消息;(三)历法、通用数表、通用表格和公式。
第十条 著作权包括下列人身权和财产权:
(一)发表权,即决定作品是否公之于众的权利;(二)署名权,即表明作者身份,在作品上署名的权利;(三)修改权,即修改或者授权他人修改作品的权利;(四)保护作品完整权,即保护作品不受歪曲、篡改的权利;(五)复制权,即以印刷、复印、拓印、录音、录像、翻录、翻拍、数字化等方式将作品制作一份或者多份的权利;(六)发行权,即以出售或者赠与方式向公众提供作品的原件或者复制件的权利;(七)出租权,即有偿许可他人临时使用视听作品、计算机软件的原件或者复制件的权利,计算机软件不是出租的主要标的的除外;(八)展览权,即公开陈列美术作品、摄影作品的原件或者复制件的权利;(九)表演权,即公开表演作品,以及用各种手段公开播送作品的表演的权利;(十)放映权,即通过放映机、幻灯机等技术设备公开再现美术、摄影、视听作品等的权利;(十一)广播权,即以有线或者无线方式公开传播或者转播作品,以及通过扩音器或者其他传送符号、声音、图像的类似工具向公众传播广播的作品的权利,但不包括本款第十二项规定的权利;(十二)信息网络传播权,即以有线或者无线方式向公众提供,使公众可以在其选定的时间和地点获得作品的权利;(十三)摄制权,即以摄制视听作品的方法将作品固定在载体上的权利;(十四)改编权,即改变作品,创作出具有独创性的新作品的权利;(十五)翻译权,即将作品从一种语言文字转换成另一种语言文字的权利;(十六)汇编权,即将作品或者作品的片段通过选择或者编排,汇集成新作品的权利;(十七)应当由著作权人享有的其他权利。
著作权人可以许可他人行使前款第五项至第十七项规定的权利,并依照约定或者本法有关规定获得报酬。
著作权人可以全部或者部分转让本条第一款第五项至第十七项规定的权利,并依照约定或者本法有关规定获得报酬。
第十八条自然人为完成法人或者非法人组织工作任务所创作的作品是职务作品,除本条第二款的规定以外,著作权由作者享有,但法人或者非法人组织有权在其业务范围内优先使用。作品完成两年内,未经单位同意,作者不得许可第三人以与单位使用的相同方式使用该作品。
有下列情形之一的职务作品,作者享有署名权,著作权的其他权利由法人或者非法人组织享有,法人或者非法人组织可以给予作者奖励:
(一)主要是利用法人或者非法人组织的物质技术条件创作,并由法人或者非法人组织承担责任的工程设计图、产品设计图、地图、示意图、计算机软件等职务作品;
(二)报社、期刊社、通讯社、广播电台、电视台的工作人员创作的职务作品;
(三)法律、行政法规规定或者合同约定著作权由法人或者非法人组织享有的职务作品。
第十九条受委托创作的作品,著作权的归属由委托人和受托人通过合同约定。合同未作明确
约定或者没有订立合同的,著作权属于受托人。
第二十条 作品原件所有权的转移,不改变作品著作权的归属,但美术、摄影作品原件的展览权由原件所有人享有。
作者将未发表的美术、摄影作品的原件所有权转让给他人,受让人展览该原件不构成对作者发表权的侵犯。
第二十二条 作者的署名权、修改权、保护作品完整权的保护期不受限制。
第二十四条 在下列情况下使用作品,可以不经著作权人许可,不向其支付报酬,但应当指明作者姓名或者名称、作品名称,并且不得影响该作品的正常使用,也不得不合理地损害著作权人的合法权益:
(一)为个人学习、研究或者欣赏,使用他人已经发表的作品;(二)为介绍、评论某一作品或者说明某一问题,在作品中适当引用他人已经发表的作品;(三)为报道新闻,在报纸、期刊、广播电台、电视台等媒体中不可避免地再现或者引用已经发表的作品;(四)报纸、期刊、广播电台、电视台等媒体刊登或者播放其他报纸、期刊、广播电台、电视台等媒体已经发表的关于政治、经济、宗教问题的时事性文章,但著作权人声明不许刊登、播放的除外;
(五)报纸、期刊、广播电台、电视台等媒体刊登或者播放在公众集会上发表的讲话,但作者声明不许刊登、播放的除外;
(六)为学校课堂教学或者科学研究,翻译、改编、汇编、播放或者少量复制已经发表的作品,供教学或者科研人员使用,但不得出版发行;
(七)国家机关为执行公务在合理范围内使用已经发表的作品;
(八)图书馆、档案馆、纪念馆、博物馆、美术馆、文化馆等为陈列或者保存版本的需要,复制本馆收藏的作品;
(九)免费表演已经发表的作品,该表演未向公众收取费用,也未向表演者支付报酬,且不以营利为目的;
(十)对设置或者陈列在公共场所的艺术作品进行临摹、绘画、摄影、录像;
(十一)将中国公民、法人或者非法人组织已经发表的以国家通用语言文字创作的作品翻译成少数民族语言文字作品在国内出版发行;
(十二)以阅读障碍者能够感知的无障碍方式向其提供已经发表的作品;
(十三)法律、行政法规规定的其他情形。
23.3 计算机软件保护条例
第二条 本条例所称计算机软件(以下简称软件),是指计算机程序及其有关文档。
第三条 本条例下列用语的含义:
(一)计算机程序,是指为了得到某种结果而可以由计算机等具有信息处理能力的装置执行的代码化指令序列,或者可以被自动转换成代码化指令序列的符号化指令序列或者符号化语句序列。同一计算机程序的源程序和目标程序为同一作品。
(二)文档,是指用来描述程序的内容、组成、设计、功能规格、开发情况、测试结果及使用方法的文字资料和图表等,如程序设计说明书、流程图、用户手册等。
(三)软件开发者,是指实际组织开发、直接进行开发,并对开发完成的软件承担责任的法人或者其他组织;或者依靠自己具有的条件独立完成软件开发,并对软件承担责任的自然人。
(四)软件著作权人,是指依照本条例的规定,对软件享有著作权的自然人、法人或者其他组织。
第四条 受本条例保护的软件必须由开发者独立开发,并已固定在某种有形物体上。
第五条 中国公民、法人或者其他组织对其所开发的软件,不论是否发表,依照本条例享有著作权。
第六条 本条例对软件著作权的保护不延及开发软件所用的思想、处理过程、操作方法或者数学概念等。
第九条 软件著作权属于软件开发者,本条例另有规定的除外。
如无相反证明,在软件上署名的自然人、法人或者其他组织为开发者。
第十条 由两个以上的自然人、法人或者其他组织合作开发的软件,其著作权的归属由合作开发者签订书面合同约定。无书面合同或者合同未作明确约定,合作开发的软件可以分割使用的,开发者对各自开发的部分可以单独享有著作权;但是,行使著作权时,不得扩展到合作开发的软件整体的著作权。合作开发的软件不能分割使用的,其著作权由各合作开发者共同享有,通过协商一致行使;不能协商一致,又无正当理由的,任何一方不得阻止他方行使除转让权以外的其他权利,但是所得收益应当合理分配给所有合作开发者。
第十一条 接受他人委托开发的软件,其著作权的归属由委托人与受托人签订书面合同约定;无书面合同或者合同未作明确约定的,其著作权由受托人享有。
第十四条 软件著作权自软件开发完成之日起产生。
自然人的软件著作权,保护期为自然人终生及其死亡后50年,截止于自然人死亡后第50年的12月31日;软件是合作开发的,截止于最后死亡的自然人死亡后第50年的12月31日。
法人或者其他组织的软件著作权,保护期为50年,截止于软件首次发表后第50年的12月31日,但软件自开发完成之日起50年内未发表的,本条例不再保护。
23.4 中华人民共和国专利法
第二条 本法所称的发明创造是指发明、实用新型和外观设计。
发明,是指对产品、方法或者其改进所提出的新的技术方案。
实用新型,是指对产品的形状、构造或者其结合所提出的适于实用的新的技术方案。
外观设计,是指对产品的整体或者局部的形状、图案或者其结合以及色彩与形状、图案的结合
所作出的富有美感并适于工业应用的新设计。
第六条 执行本单位的任务或者主要是利用本单位的物质技术条件所完成的发明创造为职务发明创造。职务发明创造申请专利的权利属于该单位,申请被批准后,该单位为专利权人。该单位可以依法处置其职务发明创造申请专利的权利和专利权,促进相关发明创造的实施和运用。
非职务发明创造,申请专利的权利属于发明人或者设计人;申请被批准后,该发明人或者设计人为专利权人。
利用本单位的物质技术条件所完成的发明创造,单位与发明人或者设计人订有合同,对申请专利的权利和专利权的归属作出约定的,从其约定。
第七条 对发明人或者设计人的非职务发明创造专利申请,任何单位或者个人不得压制。
第八条 两个以上单位或者个人合作完成的发明创造、一个单位或者个人接受其他单位或者个人委托所完成的发明创造,除另有协议的以外,申请专利的权利属于完成或者共同完成的单位或者个人;申请被批准后,申请的单位或者个人为专利权人。
第九条 同样的发明创造只能授予一项专利权。但是,同一申请人同日对同样的发明创造既申请实用新型专利又申请发明专利,先获得的实用新型专利权尚未终止,且申请人声明放弃该实用新型专利权的,可以授予发明专利权。
两个以上的申请人分别就同样的发明创造申请专利的,专利权授予最先申请的人。
第二十五条 对下列各项,不授予专利权:
(一)科学发现;(二)智力活动的规则和方法;(三)疾病的诊断和治疗方法;(四)动物和植物品种;(五)原子核变换方法以及用原子核变换方法获得的物质;(六)对平面印刷品的图案、色彩或者二者的结合作出的主要起标识作用的设计。对前款第(四)项所列产品的生产方法,可以依照本法规定授予专利权。
23.5 中华人民共和国商标法
第五条 两个以上的自然人、法人或者其他组织可以共同向商标局申请注册同一商标,共同享有和行使该商标专用权。
第六条 法律、行政法规规定必须使用注册商标的商品,必须申请商标注册,未经核准注册的,不得在市场销售。
第十条 下列标志不得作为商标使用:
(一)同中华人民共和国的国家名称、国旗、国徽、国歌、军旗、军徽、军歌、勋章等相同或者近似的,以及同中央国家机关的名称、标志、所在地特定地点的名称或者标志性建筑物的名称、图形相同的;
(二)同外国的国家名称、国旗、国徽、军旗等相同或者近似的,但经该国政府同意的除外;(三)同政府间国际组织的名称、旗帜、徽记等相同或者近似的,但经该组织同意或者不易误导公众的除外;(四)与表明实施控制、予以保证的官方标志、检验印记相同或者近似的,但经授权的除外;(五)同“红十字”、“红新月”的名称、标志相同或者近似的;(六)带有民族歧视性的;(七)带有欺骗性,容易使公众对商品的质量等特点或者产地产生误认的;(八)有害于社会主义道德风尚或者有其他不良影响的。
县级以上行政区划的地名或者公众知晓的外国地名,不得作为商标。但是,地名具有其他含义或者作为集体商标、证明商标组成部分的除外;已经注册的使用地名的商标继续有效。
第十一条 下列标志不得作为商标注册:
(一)仅有本商品的通用名称、图形、型号的;(二)仅直接表示商品的质量、主要原料、功能、用途、重量、数量及其他特点的;(三)其他缺乏显著特征的。前款所列标志经过使用取得显著特征,并便于识别的,可以作为商标注册。
第三十一条 两个或者两个以上的商标注册申请人,在同一种商品或者类似商品上,以相同或者近似的商标申请注册的,初步审定并公告申请在先的商标;同一天申请的,初步审定并公告使用在先的商标,驳回其他人的申请,不予公告。
第五十六条 注册商标的专用权,以核准注册的商标和核定使用的商品为限。
第五十七条 有下列行为之一的,均属侵犯注册商标专用权:
(一)未经商标注册人的许可,在同一种商品上使用与其注册商标相同的商标的;(二)未经商标注册人的许可,在同一种商品上使用与其注册商标近似的商标,或者在类似商品上使用与其注册商标相同或者近似的商标,容易导致混淆的;(三)销售侵犯注册商标专用权的商品的;(四)伪造、擅自制造他人注册商标标识或者销售伪造、擅自制造的注册商标标识的;(五)未经商标注册人同意,更换其注册商标并将该更换商标的商品又投入市场的;(六)故意为侵犯他人商标专用权行为提供便利条件,帮助他人实施侵犯商标专用权行为的;(七)给他人的注册商标专用权造成其他损害的。
23.6 中华人民共和国反不正当竞争法
第九条 经营者不得实施下列侵犯商业秘密的行为:
(一)以盗窃、贿赂、欺诈、胁迫、电子侵入或者其他不正当手段获取权利人的商业秘密;(二)披露、使用或者允许他人使用以前项手段获取的权利人的商业秘密;(三)违反保密义务或者违反权利人有关保守商业秘密的要求,披露、使用或者允许他人使用其所掌握的商业秘密;(四)教唆、引诱、帮助他人违反保密义务或者违反权利人有关保守商业秘密的要求,获取、披露、使用或者允许他人使用权利人的商业秘密。
经营者以外的其他自然人、法人和非法人组织实施前款所列违法行为的,视为侵犯商业秘密。第三人明知或者应知商业秘密权利人的员工、前员工或者其他单位、个人实施本条第一款所列违法行为,仍获取、披露、使用或者允许他人使用该商业秘密的,视为侵犯商业秘密。
本法所称的商业秘密,是指不为公众所知悉、具有商业价值并经权利人采取相应保密措施的技术信息、经营信息等商业信息。
23.7 软件产品管理办法
第四条软件产品的开发、生产、销售、进出口等活动应遵守我国有关法律、法规和标准规范。任何单位和个人不得开发、生产、销售、进出口含有以下内容的软件产品:
(一)侵犯他人知识产权的;(二)含有计算机病毒的;(三)可能危害计算机系统安全的;(四)含有国家规定禁止传播的内容的;(五)不符合我国软件标准规范的。
23.8 练习题
- 以下关于软件著作权产生时间的叙述中,正确的是()。
A.软件著作权产生自软件首次公开发表时B.软件著作权产生自开发者有开发意图时C.软件著作权产生自软件开发完成之日起D.软件著作权产生自软件著作权登记时
解析:根据《计算机软件保护条例》第十四条规定,软件著作权自软件开发完成之日起产生。答案:C
- X公司接受Y公司的委托开发了一款应用软件,双方没有订立任何书面合同。在此情形下,()享有该软件的著作权。
A.X、Y公司共同 B.X公司 C.Y公司 D.X、Y公司均不
解析:根据《中华人民共和国著作权法》第十九条以及《计算机软件保护条例》第十一条规定,受委托创作的作品,著作权的归属由委托人和受托人通过合同约定。合同未作明确约定或者没有订立合同的,著作权属于受托人。
答案:B
- 谭某是CZB物流公司的业务系统管理员。任职期间,谭某根据公司的业务要求开发了“报关业务系统”,并由公司使用。以下说法正确的是()。
A.报关业务系统V1.0的著作权属于谭某 B.报关业务系统V1.0的著作权属于CZB物流公司 C.报关业务系统V1.0的著作权属于谭某和CZB物流公司 D.报关业务系统V1.0的著作权不属于谭某和CZB物流公司
解析:根据题干,谭某是在任职期间根据公司业务要求开发的该系统,因此根据《中华人民共和国著作权法》第十八条规定,谭某开发的软件属于职务作品。
答案:B
- 著作权中,( )的保护期不受期限限制。
A.发表权 B.发行权 C.展览权 D.署名权
解析:著作权中的人身权的保护期不受限制。即作者的署名权、修改权、保护作品完整权的保护期不受限制。
答案:D
- 甲、乙两人在同一天就同样的发明创造提交了专利申请,专利局将分别向各申请人通报有关情况,并提出多种可能采用的解决办法。下列说法中,不可能采用()。
A.甲、乙作为共同申请人 B.甲或乙一方放弃权利并从另一方得到适当的补偿 C.甲、乙都不授予专利权 D.甲、乙都授予专利权
解析:根据《中华人民共和国专利法》第九条规定,“同一的发明创造只能被授予一项专利”,因此在同一天,两个不同的人就同样的发明创造申请专利的,专利局将分别向各申请人通报有关情况,请他们自己去协商解决这一问题,解决的方法一般有两种,一种是两申请人作为一件申请的共同申请人;另一种是其中一方放弃权利并从另一方得到适当的补偿。
答案:D
第24小时 应用数学
24.0 章节考点分析
根据考试大纲,本小时涉及单项选择题,占2分左右。考查运筹学的相关知识,涉及题型范围较广,难度较大。本小时节选部分常规考题类型,希望广大考生尽量掌握。本小时知识架构如图24.1所示。
图24.1 本小时知识架构
【导读小贴士】
运筹学属于管理科学的一种,经常用于解决现实生活中的复杂问题,特别是改善或优化现有系统的效率。考试中大概有4分左右的题目出自运筹学。由于运筹学研究的内容十分广泛,本小时精选了一些基础的、难度不大的、多次出现的题目进行解析,供广大考生学习。尽管我们不需要掌握太多、太复杂的运筹学方法,但学好运筹学有助于启发思维,对日后的工作、学习都会有一定的帮助。
24.1 图论之最小生成树
【基础知识点】
(1)定义:在连通的带权图的所有生成树中,权值和最小的那棵生成树(包含图中所有顶点的树),称作最小生成树。
(2)针对问题:带权图的最短路径问题。
(3)最小生成树的解法有普里姆(Prim)算法和克鲁斯卡尔(Kruskal)算法,我们常用克鲁斯卡尔算法。
【例】图24.2标明了六个城市( $\mathrm{A}\sim \mathrm{F}$ )之间的公路(每条公路旁标注了其长度公里数)。为将部分公路改造成高速公路,使各个城市之间均可通过高速公路通达,至少要改造总计()公里的公路,这种总公里数最少的改造方案共有()个。
A.1000 B.1300 C.1600 D.2000
A.1 B.2 C.3 D.4
图24.2 由线路相连接的城市
【解】依次选取长度最小的边,图24.2中有6个节点,则需要5条边(边数 $\equiv$ 节点数- 1),因此有:AE、FD为200,AB、BF、AF、CD为400,所以最终方案有3种,如图24.3所示。
图24.3 3种最终方案
24.2 图论之最大流量
【基础知识点】
(1)最大流量问题是一个特殊的线性规划问题。(2)针对问题:道路运输能力问题,管道流量问题等。
【例】图24.4标出了某地区的运输网。
图24.4 某地区的运输网
各节点之间的运输能力见表24.1。
表24.1各节点之间的运输能力 单位:万吨每小时
| 节点 | ① | ② | ③ | ④ | ⑤ | ⑥ |
| ① | 6 | 10 | 10 | |||
| ② | 6 | 4 | 7 | |||
| ③ | 10 | 1 | 14 | |||
| ④ | 10 | 4 | 1 | 5 | ||
| ⑤ | 7 | 14 | 21 | |||
| ⑥ | 5 | 21 |
从节点 $①$ 到节点 $(\widehat{\theta})$ 的最大运输能力(流量)可以达到()万吨每小时。
A.26 B.23 C.22 D.21
【解】在本题中,从节点 $①$ 到节点 $(\widehat{\theta})$ 可以同时沿多条路径运输,总的最大流量应是各条路径上的最大流量之和,每条路径上的最大流量应是其各段流量的最小值。
解题时,每找出一条路径算出流量后,该路径上各段线路上的流量应扣除已经算过的流量,形成剩余流量。剩余流量为0的线段应将其删除(断开)。例如,路径 $①③④⑥$ 的最大流量为10万吨,计算过后,该路径上各段流量应都减少10万吨。从而 $①③$ 之间断开, $③⑤$ 之间的剩余流量是4万
吨, $(5)(6)$ 之间的剩余流量为11万吨,如图24.5所示。
图24.5 $①③$ 之间断开后的运输网
同理,依次执行类似步骤:
(1)路径 $①②⑤⑥$ 的剩余最大流量为6万吨。计算过后,该路径上各段流量应都减少6万吨。从而 $①②$ 之间断开, $②⑤$ 之间的剩余流量是1万吨, $⑤⑥$ 之间的剩余流量为5万吨,如图24.6所示。
图24.6 $①②$ 之间断开后的运输网
(2)路径 $①④⑥$ 的剩余最大流量为5万吨。计算过后,该路径上各段流量应都减少5万吨。从而 $④⑥$ 之间将断开, $①④$ 之间的剩余流量是5万吨,如图24.7所示。
图24.7 $④⑥$ 之间断开后的运输网
(3)路径 $①④③⑤⑥$ 的剩余最大流量为1万吨。计算过后,该路径上各段流量应都减少1万吨。从而 $④③$ 之间断开, $①④$ 之间的剩余流量是4万吨, $③⑤$ 之间的剩余流量是3万吨, $⑤⑥$ 之间的剩余流量是4万吨,如图24.8所示。
图24.8 $④③$ 之间断开后的运输网
(4)路径 $①④②⑤⑥$ 的剩余最大流量为1万吨。计算过后,该路径上各段流量应都减少1万吨。从而 $②⑤$ 之间断开, $①④$ 之间、 $④②$ 之间、 $⑤⑥$ 之间的剩余流量是3万吨,如图24.9所示。
图24.9 $②⑤$ 之间断开后的运输网
至此,从节点 $①$ 到节点 $(\widehat{G})$ 已经没有可通的路径,因此,从节点 $①$ 到节点 $(\widehat{\theta})$ 的最大流量应该是所有可能运输路径上的最大流量之和,即 $10 + 6 + 5 + 1 + 1 = 23$ 万吨。
24.3 线性规划
【基础知识点】
(1)定义:线性规划是研究在有限的资源条件下,如何有效地使用这些资源达到预定目标的数学方法。从数学的角度来说,就是在一组约束条件下寻找目标表达式的极值问题。
(2)针对问题:在资源约束下的生产问题等。
(3)线性规划的常用解法是图解法和联立方程组法。
【例】某工厂计划生产甲、乙两种产品。生产每套产品所需的设备台时,A、B两种原材料,可获取利润以及可利用资源数量见表24.2,则应按()方案来安排计划以使该工厂获利最多。
表24.2 设备、原材料资源表
| 项目 | 甲 | 乙 | 可利用资源 |
| 设备/台时 | 2 | 3 | 14 |
| 原材料 A/千克 | 8 | 0 | 16 |
| 原材料 B/千克 | 0 | 3 | 12 |
| 利润/万元 | 2 | 3 |
A.生产甲2套,乙3套 B.生产甲1套,乙4套 C.生产甲3套,乙4套 D.生产甲4套,乙2套
【解】设甲生产 $x$ 套,乙生产 $y$ 套,则有:
$$ \left{ \begin{array}{l}\text{①} 2x + 3y \leqslant 14 \ \text{②} x \leqslant 2 \ \text{③} y \leqslant 4 \end{array} \right. $$
(1)图解法:将3个不等式均转化为方程,并在二维直角坐标系中表达为对应的直线。则这三条直线与 $X$ 轴和 $Y$ 轴围成的公共区间即为解区间。根据不等号判定,解区间是在三条直线的左方、下方。据此画图如图24.10所示。利润 $N = 2x + 3y$ ,若 $N$ 是一个常数,则该式表现为一条等值直线,当 $N$ 变化时该式为一组平滑移动的等值线族。
图24.10 图解法解线性规划问题
三条直线有 $P_{1}$ $P_{2}$ $P_{3}$ 三个交点,其中 $P_{2}$ 在解区间以外,显然是不可行解。 $P_{1}$ $P_{3}$ 均为可行
解,又在同一条等值线上( $N$ 相同,均为14),因此均为数学最优解。
而根据题意, $x$ 与 $y$ 均应为整数,所以 $P_{1}$ 不符合,只有 $P_{3}$ (1,4)符合,对应的答案为B。
(2)联立方程组法:
1)将不等式 $①②$ 变形为等式,并联立解方程得
$$ \left{ \begin{array}{l}x = 2 \ y = 10 / 3 \end{array} \right. $$
代入不等式 $(3)$ ,符合,表明这是一组可行解。
代入表达式 $2x + 3y$ ,得到14。
2)同样联立等式 $②③$ 解得
$$ \left{ \begin{array}{l}x = 2 \ y = 4 \end{array} \right. $$
代入不等式 $①$ ,不符合,表明这是一组不可行解。
3)同样联立等式 $①③$ 解得
$$ \left{ \begin{array}{l}x = 1 \ y = 4 \end{array} \right. $$
代入不等式 $(2)$ ,符合,表明这是一组可行解。
代入表达式 $2x + 3y$ ,得到14。
显然,1)、3)两组解在数学上均能得到最大获利,但是10/3套显然并不符合题义要求,只有 $x$ 取1, $y$ 取4时,利润最大,是14万元。答案为B。
总结:
图解法很直观,有解、无解、最优解所在位置一目了然,不会丢失正解;而联立方程组法可能丢失正解(例如最优解在 $X$ 轴或 $Y$ 轴交点上,而不在各直线之间的交点上)。同时,如果条件不等式很多( $n > 3$ ),图解法也有明显的计算优势,其计算量是 $O(n)$ ;而联立方程组法的计算量是 $O(n^{2})$ 。但是,如果未知数为3个或以上,则图解法的难度将增大,这时联立方程组法将成为主要的方法。
线性规划问题的解有以下可能:
(1)有唯一最优解,在解区间多边形的某个顶点上。 (2)有无穷多最优解,只要能找到两个不同的最优解,则一定有无穷多个最优解。 (3)无界解,有无穷多的解,但是没有最优解,原因是缺少必要的约束条件。 (4)无可行解,原因是约束条件互相矛盾。
有定义:若X、Y是是某线性规划问题的最优解,则Z=λX+(1-λ)Y(0≤λ≤1)也是该问题的最优解。所以μ=1-λ,因此应满足λ+μ=1,又因为0≤λ≤1,所以0≤1-λ≤1,所以入,u≥0。
24.4 动态规划
【基础知识点】
(1)定义:动态规划是一种将问题实例分解为更小的、相似的子问题,并存储子问题的解而避免计算重复的子问题,以解决最优化问题的算法策略。
(2)针对问题:装货最大价值问题。
【例】用一辆载重量为10吨的卡车装运某仓库中的货物(不用考虑装车时货物的大小),这些货物单件的重量和运输利润见表24.3。适当选择装运一些货物各若干件,就能获得最大总利润()元。
表24.3 重量运输和利润表
| 货物 | A | B | C | D | E | F |
| 每件重量/吨 | 1 | 2 | 3 | 4 | 5 | 6 |
| 每件运输利润/元 | 53 | 104 | 156 | 216 | 265 | 318 |
A.530 B.534 C.536 D.538
【解】若想获得最高利润最理想的方式是10吨都装满,且装的货物是单位利润最高的那些货物。因此,将每种货物的单位利润计算出来,见表24.4。由表中数据可知,D单位利润最大,可以装2件8吨,剩余2吨可以选择单位利润第二大的A,装2件,此时的最大利润为538元。答案为D。
表24.4 运输利润表
| 货物(类) | A | B | C | D | E | F |
| 每件重量/吨 | 1 | 2 | 3 | 4 | 5 | 6 |
| 每件运输利润/元 | 53 | 104 | 156 | 216 | 265 | 318 318 |
| 单位利润/元 | 53 | 53 | 52 | 54 | 53 | 53 |
24.5 决策分析
【基础知识点】
(1)定义:决策分析指从若干可能的方案中通过决策分析技术,例如期望值法或决策树法等选择其一的决策过程,是一种定量分析方法。
(2)针对问题:期望值问题,决策树问题
(3)预期货币价值或者期望货币值(Expected Monetary Value,EMV):把某方案的每个可能结果所获得的收益与其发生概率相乘之后加总,即得到该方案的EMV。通过比较各方案的EMV来决策采用哪一个方案。该方法常常与决策树技术相辅相成。
(4)解题技巧:决策树在最左边做决策,所以需要从右向左逐层计算化简,特别是条件复杂时更应如此。
【例】某货运公司要从A地向B地的用户发送一批价值为9000元的货物。从A地到B地有水、陆两条路线。走陆路时比较安全,其运输成本为1000元;走水路时一般情况下的运输成本只要700元,不过一旦遇到暴风雨天气,则会造成相当于这批货物总价值 $10%$ 的损失。根据历年情况,这期间出现暴风雨天气的概率为 $15%$ ,那么该货运公司该选哪一个方案?
【解】先画出决策树,如图24.11所示。
图24.11 运输问题的决策树
根据图24.11,走水路时,成本为700元的概率为 $85%$ ,成本为1600元的概率为 $15%$ ,因此,走水路的期望成本为 $(700\times 85%) + (1600\times 15%) = 835$ 元;走陆路时,其成本为 $(1000\times 85%) + (1000\times 15%) = 1000$ 元。所以,走水路的期望成本小于走陆路的成本,应该选择走水路。
24.6 不确定型决策论
【基础知识点】
(1)定义:不确定型决策是在无法估计系统行动方案所处状态概率的情况下进行的决策。它与决策分析相反,决策分析是根据不同方案的收益与概率来量化计算出客观决策依据的方法论。(2)决策者根据自己的主观倾向进行决策,可分为5种准则,分别为乐观主义准则、悲观主义准则、折中主义准则、等可能性准则和后悔值准则。1)乐观主义准则,也称为“最大最大准则”,其决策原则是“大中取大”。决策者依次在决策表中的各个投资方案所对应的各个结果中选择出最大结果并记录,最后再从这些结果中选出最大者,其所对应的方案就是应该采取的决策方案。2)悲观主义准则,也称为“最大最小准则”,其决策原则是“小中取大”。决策者依次在决策表中的各个投资方案所对应的各个结果中选择出最小结果并记录,再从这些结果中选出最大者,其所对应的方案就是应该采取的决策方案。3)后悔值准则,也称为“最小最大后悔值”,该决策法的基本原理为:将每种自然状态的最高值(指收益矩阵,如果是损失矩阵应取最低值)定为该状态的理想目标,并将该状态中的其他值与最高值相比,所得之差作为未达到理想的后悔值。为了提高决策的可靠性,在每一方案中选 取最大的后悔值,再在各方案的最大后悔值中选取最小值作为决策依据,与该值所对应的方案即为入选方案。
【例】某公司需要根据下一年度宏观经济的增长趋势预测决定投资策略。宏观经济增长趋势有不景气、不变和景气3种,投资策略有积极、稳健和保守3种,各种状态收益见表24.5。
表24.5 各种状态收益
| 预计收益/百万元 | 经济趋势预测 | |||
| 不景气 | 不变 | 景气 | ||
| 投资策略 | 积极 | 50 | 150 | 500 |
| 稳健 | 150 | 200 | 300 | |
| 保守 | 400 | 250 | 200 | |
【解】
(1)若根据乐观主义准则,表24.5中积极方案的最大结果是500,稳健方案的最大结果是300,保守方案的最大结果是400,三者的最大值是500。因此,选择其对应的积极投资方案。
(2)若根据悲观主义准则,表24.5中积极方案的最小结果是50,稳健方案的最小结果是150,保守方案的最小结果是200,三者的最大值是200。因此,选择其对应的保守投资方案。
(3)若根据后悔值准则,根据表24.5可以得出后悔值矩阵,见表24.6。
表24.6 各种状态后悔值
| 预计收益/百万元 | 经济趋势预测 | |||
| 不景气 | 不变 | 景气 | ||
| 投资策略 | 积极 | 350 | 100 | 0 |
| 稳健 | 250 | 50 | 200 | |
| 保守 | 0 | 0 | 300 | |
在表24.6中,积极方案的最大后悔值为350,稳健方案的最大后悔值为250,保守方案的最大后悔值为300,三者中的最小值者为250。因此,选择其对应的稳健投资方案。
24.7 练习题
1.某小区有七栋楼房 $(1)\sim (7)$ ,如图24.12所示,各楼房之间可修水管路线的长度(单位:百米)已标记在连线旁。为修建连通各个楼房的水管,该小区内部水管的总长度至少为()百米。
图24.12 水管线路网络
A. 20 B. 21 C. 24 D. 27
解析:
采用最小生成树的克鲁斯卡尔算法。
找出所有长度为2的边,试图将它们连接,有 $①③$ 、 $④⑥$ ,检验后没有形成闭环,可行。
找出所有长度为3的边,试图将它们连接,有 $①⑦$ 、 $③⑥$ ,检验后没有形成闭环,可行。
找出所有长度为4的边,试图将它们连接。有 $①②$ 和 $②⑥$ 。如果全部连接则形成闭环,需舍弃其中一个,这里舍弃 $①②$ 。
找出所有长度为5的边,试图将它们连接,有 $③④$ ,如连接则形成闭环,需舍弃。
找出所有长度为6的边,试图将它们连接,有 $①④$ 、 $⑤⑥$ ,如连接 $①④$ 则形成闭环,需舍弃;连接 $⑤⑥$ 可行。
至此所有节点均完成连接,如图24.13所示。总长度为 $2\times 2 + 3\times 2 + 4 + 6 = 20$ 百米。
图24.13 最短水管线路网络
答案:A
- 图24.14标出了某产品从产地Vs到销地Vt的运输网,箭线上的数字表示这条输线的最大通过能力(流量)(单位:万吨每小时)。产品经过该运输网从Vs到Vt的最大运输能力可以达到
( )万吨每小时。
图24.14 运输网
A.5 B.6 C.7 D.8
解析:从Vs到 $\mathrm{Vt}$ ,每条路径的最大流量等于该路径中各段流量的最小值,如 $\mathrm{Vs}\to \mathrm{V}2\to \mathrm{V}4\to$ Vt,最小值为3,因此该条路径最大流量为3。同理, $\mathrm{Vs}\to \mathrm{V}1\to \mathrm{V}3\to \mathrm{V}4$ 最小值为2。两条路径相加,最大流量为5,其他路径没有剩余流量可供使用,因此总的最大流量为5。
答案:A
- 已知在如下线性约束条件下: $2x + 3y\leq 30$ $x + 2y\geq 10$ $x\geq y$ $x\geq 5$ $y\geq 0$ ,则目标函数 $2x + 3y$ 的极小值为()。
A.16.5 B.17.5 C.20 D.25
解析:由于约束条件较多,应采用图解法。根据题意画出可行区域,如图24.15中阴影部分所示。
图24.15 图解法解题示意图
显然,该题有唯一的最优解,在 $x = 5$ 与 $x + 2y = 10$ 的交点处,联立解得 $x = 5$ , $y = 2.5$ ,因此 $2x + 3y$ 最小值为 $2 \times 5 + 3 \times 2.5 = 17.5$ 。
答案:B
- 生产某种产品有两个建厂方案: $①$ 建大厂,需要初期投资500万元。如果产品销路好,每年可以获利200万元;如果销路不好,每年会亏损20万元。 $②$ 建小厂,需要初期投资200万元。如果产品销路好,每年可以获利100万元;如果销路不好,每年只能获利20万元。
市场调研表明,未来2年,这种产品销路好的概率为 $70%$ 。如果这2年销路好,则后续5年销路好的概率上升为 $80%$ ;如果这2年销路不好,则后续5年销路好的概率仅为 $10%$ 。为取得7年最大总收益,决策者应()。
A.建大厂,总收益超500万元 B.建大厂,总收益略多于300万元C.建小厂,总收益超500万元 D.建小厂,总收益略多于300万元
解析:采用决策分析方法解答如下:
首先根据题意画出决策树示意图,如图24.16所示
图24.16 决策树示意图
从右往左逐层计算各个节点。
首先计算 $④⑤⑥⑦$ 四个节点的期望值:
(1)建大厂后5年销路好期望值: $[200\times 0.8 + (-20)\times 0.2]\times 5 = 780$
(2)建大厂后5年销路不好期望值: $[200\times 0.1 + (-20)\times 0.9]\times 5 = 10$
(3)建小厂后5年销路好期望值: $(100\times 0.8 + 20\times 0.2)\times 5 = 420$
(4)建小厂后5年销路好不期望值: $(100\times 0.1 + 20\times 0.9)\times 5 = 140$
再在 $(2)③$ 节点处按如下算式计算两年的期望值(扣除投资额),并将结果(7年总收益)写在节点处。
(1)建大厂2年期望值: $[200\times 0.7 + (-20)\times 0.3]\times 2 + (780\times 0.7 + 10\times 0.3) - 500 = 317$
(2)建小厂2年期望值: $(100\times 0.7 + 20\times 0.3)\times 2 + (420\times 0.7 + 140\times 0.3) - 200 = 288$
由于建大厂的总收益值大于建小厂的总收益值,因此决定建大厂。
答案:B
- 某企业要投产一种新产品,生产方案有四个:A——新建全自动生产线;B——新建半自动生产线;C——购置旧生产设备;D——外包加工生产。未来该产品的销售前景估计为较好、一般和较差三种不同情况下该产品的收益值见表24.7(单位:百万元)。
用后悔值(在同样的条件下,宣传方案所产生的收益损失值)的方案决策应该选()方案。
A.新建全自动生产线 B.新建半自动生产线C.购置旧生产设备 D.外包加工生产
表24.7 三种情况下的产品收益值 单位:百万元
| 生产方案 | 较好 | 一般 | 较差 |
| A | 800 | 200 | -300 |
| B | 600 | 250 | -150 |
| C | 450 | 200 | -100 |
| D | 300 | 100 | -20 |
解析:
第一步:分别计算每个方案在收益较好、一般和较差情况下的后悔值。如:在收益较好的情况下,方案A的利润最高是800,因此A的后悔值 $= 800 - 800 = 0$ ;方案B的后悔值 $= 800 - 600 = 200$ ;方案C的后悔值 $= 800 - 450 = 350$ ;方案D的后悔值 $= 800 - 300 = 500$ 。同理计算收益一般、较差情况下的后悔值,然后得到表24.8。
表24.8 三种情况下的后悔值 单位:百万元
| 生产方案 | 较好 | 一般 | 较差 |
| A | 0 | 50 | 280 |
| B | 200 | 0 | 130 |
| C | 350 | 50 | 80 |
| D | 500 | 150 | 0 |
第二步:确定每个方案的最大后悔值。A的最大后悔值为280,B为200,C为350,D为500。第三步:确定决策方案。选择各方案最大后悔值最小的,即方案B为最佳方案。
答案:B
第25小时 专业英语
25.0 章节考点分析
第25小时主要学习专业英语知识。根据考试大纲,上午单选题会有5道英文选择题(分值为5分),主要涉及信息技术与管理类的一些概念性的知识。这部分知识对于一些考生来说是难点所在,在本小时内容里总结出一些软考中常考的英文知识点供广大考生参考。
【导读小贴士】
系统架构设计师考试英文试题的出题范围基本局限于系统架构设计方面基础性的、概念性的知识,大多属于名词解释范畴。如果考生具有一定的英文水平,同时对于基本概念掌握得比较牢固,这部分分值不难拿到。
25.1 架构风格
An architectural style defines as a family of such systems in terms of a pattern of structural organization. More specifically, an architectural style defines a vocabulary of components and connector types, and a set of constraints on how they can be combined. For many styles there may also exist one or more semantic models that specify how to determine a system’s overall properties from the properties of its parts. Many of architectural styles have been developed over the years.The best- known examples of pipe- and- filter architectures are programs written in the UNIX shell.
一种架构风格以一种结构化组织模式定义一组这样的系统。具体来说,一种架构风格定义了一个构件及连接器类型的词汇表,以及一组关于它们如何能够被关联的约束。对于许多风格来说,可能也存在一个或多个语义模型,从系统部件的特性来确定系统的整体特性。许多架构风格已经发展了很多年,众所周知的管道- 过滤器架构就是用 UNIX shell 编写的程序。
25.2 非功能需求
【基础知识点】
The architecture design specifies the overall architecture and the placement of software and hardware that will be used. Architecture design is a very complex process that is often left to experienced architecture designers and consultants. The first step is to refine the nonfunctional requirements into more detailed requirements that are then employed to help select the architecture to be used and the software components to be placed on each device. In a client- based architecture, one also has to decide whether to use a two- tier, three- tier, or n- tier architecture. Then the requirements and the architecture design are used to develop the hardware and software specification. There are four primary types of nonfunctional requirements that can be important in designing the architecture. A operational requirements specify the operating environment(s) in which the system must perform and how those may change over time. Performance requirements focus on the nonfunctional requirements issues such as response time, capacity, and reliability. Security requirements are the abilities to protect the information system from disruption and data loss, whether caused by an intentional act. Cultural and political requirements are specific to the countries in which the system will be used.
架构设计指定了将要使用的软件和硬件的总体架构和布局。架构设计是一个非常复杂的过程,往往留给经验丰富的架构设计师和顾问。第一步是将非功能需求细化为更详细的要求,然后用于帮助选择要使用的体系结构以及要放置在每个设备上的软件组件。在基于客户端的架构中,还必须决定是使用两层、三层还是 $n$ 层架构。然后使用需求和体系结构设计来开发硬件和软件规范。有4种主要的非功能需求类型可能在设计架构时非常重要。操作要求指定系统必须执行的操作环境以及这些操作环境如何随时间变化。性能要求侧重于非功能性需求问题,如响应时间、容量和可靠性。安全要求是指是否有能力保护信息系统免受故意行为造成的破坏和数据丢失。文化和政治要求明确了特定系统将被使用的国家。
25.3 应用架构
【基础知识点】
An application architecture specifies the technologies to be used to implement one or more information systems. It serves as an outline for detailed design, construction, and implementation. Given the models and details, include logical DFD and ERD, we can distribute data and processes to create a general design of application architecture. The design will normally be constrained by architecture standards, project objectives, and the feasibility of techniques used. The first physical DFD to be drawn is the network architecture DFD. The next step is to distribute data stores to different processors. Data partitioning and replication are two types of distributed data which most RDBMSs support. There are many distribution options used in data distribution. In the case of storing specific tables on different servers we should record each table as a data store on the physical DFD and connect each to the appropriate server.
应用架构说明了实现一个或多个信息系统所使用的技术,它作为详细设计、构造和实现的一个大纲。通过给定的包括逻辑数据流图和实体联系图在内的模型和详细资料,我们可以分配数据和过程以创建应用架构的一个概要设计。概要设计通常会受到架构标准、项目目标和所使用技术的可行性的制约。需要绘制的第一个物理数据流图是网络架构数据流图。接下来是分配数据存储到不同的处理器。数据分区和复制是大多数关系型数据库支持的两种分布式数据形式。有许多分配方法用于数据分布。在不同服务器上存储特定表的情况下,我们应该将每个表记为物理数据流图中的一个数据存储,并将其连接到相应的服务器。
25.4 软件架构重用
【基础知识点】
Software architecture reconstruction is an interpretive, interactive, and iterative process including many activities. Information extraction involves analyzing a system’s existing design and implementation artifacts to construct a model of it. The result is used in the following activities to construct a view of the system. The database construction activity converts the elements and relations contained in the view into a standard format for storage in a database. The view fusion activity involves defining and manipulating the information stored in database to reconcile, augment, and establish connections between the elements. Reconstruction consists of two primary activities: visualization and interaction, pattern definition and recognition. The former provides a mechanism for the user to manipulate architectural elements, and the latter provides facilities for architecture reconstruction.
软件架构重用是一个解释性、交互式和反复迭代的过程,包括了多项活动。信息提取通过分析系统现有设计和实现工件来构造它的模型。其结果用于在后续活动中构造系统的视图。数据库构建活动把视图中包含的元素和关系转换为数据库中的标准存储格式。视图融合活动包括定义和操作数据库中存储的信息,理顺、加强并建立起元素之间的连接。重构由两个主要活动组成:可视化和交互式及模式定义与识别。前者提供了一种让用户操作架构元素的机制,后者则提供了用于架构重构的设施。
25.5 练习题
A system’s architecture is a representation of a system in which there is a mapping of (1) onto hardware and software components, a mapping of the (2) onto the hardware architecture, and a concern for the human interaction with these components. That is, system architecture is concerned with a total system, including hardware, software, and humans. Software architectural structures can be divided into three major categories, depending on the broad nature of the elements they show. (3) embody decisions as a set of code or data units that have to be constructed or procured. (4) embody decisions as to how the system is to be structured as set of elements that have run- time behavior and interactions. (5) embody decisions as to how the system will relate to non- software structures in its environment (such as CPUs, file systems, networks, development teams, etc.).
(1) A. attributes B. constraint C. functionality D. requirements
(2) A. physical components B. network architecture C. software architecture D. interface architecture
(3) A. Service structures B. Module structures C. Deployment structures D. Work assignment structures
(4) A. Decomposition structures B. Layer structures C. Implementation structures D. Component and connector structures
(5) A. Allocation structures B. Class structures C. Concurrency structures D. Uses structures
解析:系统架构是一个系统的一种表示,包含了功能到软硬件构件的映射、软件架构到硬件架构的映射以及对于这些组件人机交互的关注。也就是说,系统架构关注于整个系统,包括硬件、软件和使用者。
软件架构结构根据其所展示元素的广义性质,可以分为3个主要类别。
(1)模块结构将决策体现为一组需要被构建或采购的代码或数据单元。(2)构件连接器结构将决策体现为系统如何被结构化为一组具有运行时行为和交互的元素。(3)分配结构将决策体现为系统如何在其环境中关联到非软件结构,如CPU、文件系统、网络、开发团队等。
答案:(1)C (2)C (3)B (4)D (5)A
第26小时 论文写作
26.0 章节考点分析
第26小时主要学习论文写作。根据考试大纲,论文满分为75分,为考试的压轴科目,俗话说“得论文者得天下”,其重要程度不言而喻。但是,“唯者不会,会者不难”,考生应当正确面对、积极准备。
【导读小贴士】
系统架构设计师考试论文题目一般是四选一,范围覆盖系统建模、软件架构设计、系统设计、系统可靠性分析与设计、系统安全性和保密性设计等方面。只要考生积极提前准备、掌握论文写作框架、有针对性地训练,往往会水到渠成,顺利过关。
26.1 论文目的
我们研读考试大纲可以发现,论文最能体现“高级”两个字的真实含义。我们认为,考试设置论文的目的有四:一是考查考生是否具备足够的实践经验;二是考查考生是否具备足够的分析问题的能力;三是考查考生是否具备足够的解决问题的能力;四是考查考生是否具备足够的书面表达能力。简言之,丰富的实践经验、较强的分析问题能力、扎实的解决问题能力、流畅的书面表达能力,构成了系统架构设计师这一“高级工程师”的基本素养。
26.2 论文要求
我们试图从形式、内容两个方面来阐述论文的要求。
(1)形式方面的要求。首先,内容要丰满,即字数要够,其中摘要字数为 $290\sim 320$ ,正文字数为 $2200\sim 2800$ ;其次,卷面要整洁,字迹至少要容易辨认,最好不要有错别字;再次,无明显的语法、文法纰漏,行文要清晰,要有逻辑。
(2)内容方面的要求。内容要求主要包含5个方面:一是实践性强,切忌夸大其词、自我标榜、过分吹嘘;二是契合题意,不跑题,切忌漏洞百出、离题万里;三是具备较高的深度和水平,切忌理论堆砌、泛泛而谈;四是要体现较强的综合分析能力;五是要能体现较好的书面表达能力,要求文字流畅、条理分明、逻辑清晰、表达严谨。形式是表,也是数量的要求;内容是里,也是质量的要求。一篇合格的论文既要有正确的形式展现,又要有丰满内容的支撑,要求数量、质量两个方面均过关。
下述情况之一的论文,不能给予及格:
(1)虚构情节、论文中有较严重的不真实或者不可信的内容出现。(2)没有项目开发的实际经验,通篇都是浅层次、纯理论的叙述。(3)所讨论的内容与方法过于陈旧,或者项目的水准非常低下。(4)内容不切题意,或者内容相对很空洞,基本上是泛泛而谈且没有体现参与人的深入体会的。(5)正文与摘要的篇幅过于短小的。(6)文理很不通顺、错别字很多、条理与思路不清晰、字迹过于潦草等情况相对严重的。
26.3 论文框架
- 摘要
顾名思义,摘要是论文的浓缩和精华,通过阅读摘要,读者就能大概知晓论文的内容。一般来说,摘要由下面3个部分组成:一是项目背景介绍,内容包括项目缘由、时间、项目名称、项目建设内容等,作者的工作角色和工作内容介绍;二是项目技术简介,结合题目要求简单介绍论文采用什么技术、方法、措施、手段等,解决了什么问题,是正文理论与实践的浓缩;三是项目效果简述。注意,摘要语言要精炼、概括,阐述要综合、浓缩,不宜详细展开,好的摘要是成功的一半。摘要不建议分段。
- 项目背景
项目背景这部分约 $400\sim 500$ 字。项目背景建议使用“5W2H”模式来展开,具体如下:
(1)Why:项目的由来、缘起、项目定位、项目目标等。(2)When:何时,为体现技术先进性建议选近三年的项目,工期建议半年至一年。(3)Where:何地,介绍项目发生地,不能出现实际的城市名,建议形式:某省/某市。
(4)Who:项目的甲乙双方,甲方名称需脱敏处理,乙方称“我司/我单位/我厂/我公司”。
(5)What:项目名称、项目的建设内容、作者的工作内容等。
(6)How much:项目规模、项目预算等。
(7)How:项目采用的技术、框架、方法、工具、措施等。
如果摘要写得好,就可以基于摘要的脉络,进一步细化展开阐述,这不失为一种好的实践方法。注意,项目背景选择非常重要,务必重点准备,不管考试出什么题目,项目背景都可以复用。关于项目选择,我们建议首选自己参与过、亲历过、深有体会的项目,其次选未参与但熟悉或能理解的项目,最后选不熟悉但通过阅读相关文档能理解的项目。简言之,越熟悉的项目,论文的材料就越充实,论述越能充分,行文时才能思如泉涌、一气呵成。
- 过渡部分
过渡这部分约100字,为了避免论文上下文语义断层,需要适当加入过渡语句,起承上启下的作用。在项目背景介绍完毕,考生需要识别出项目的关键需求、项目特征、项目约束等主客观因素,提出满足这些因素需采取哪些理论、技术、措施、工具、手段,从而引出下文。
- 理论部分
理论部分约 $400\sim 600$ 字。论文题干针对理论部分有明确的要求,翻看历年的真题试卷,这一要求出现在第二小问比较常见。因此,作者需要单独并且完整地逐一应答,理论部分又称分论点,要注意紧扣题干,问什么答什么,无关内容不要赘述。理论部分决定了论文的水平高低,着重论述分论点的基本概念、基本原理、应用场景,适当简单举例。而基本概念、基本原理不必死记硬背,可以用自己的语言或自己的理解阐述,当然要注意阐述要严谨、科学、正确,否则有贻笑大方的可能。注意控制好字数,切忌洋洋洒洒上千字。
- 实践部分
实践部分约 $1000\sim 1200$ 字,是论文最重要的部分,也是最能体现作者水平高低的部分。结构上,建议与理论部分前后呼应、保持一致,做到紧扣分论点。为了便于读者阅读,建议提炼小标题,小标题需要好好斟酌,要能统领全段内容。针对每个分论点,建议采用“Why+How”来阐述,首先分析问题,然后解决问题。深入浅出,切忌纸上谈兵,实践部分不能写成干巴巴的理论堆砌。注意扬长避短,不能把实践部分写成产品介绍。
- 结尾
结尾约 $300\sim 400$ 字。结尾部分首先需要呼应论点,然后可以介绍项目出现的小问题、项目效果、下一步计划、作者的收获等内容。注意首尾呼应,避免前后矛盾,另外在阐述问题时简单带过即可,切忌滔滔不绝。
26.4 论文写作常见问题
(1)摘要部分常见问题:
1)项目背景介绍缺失。2)项目主要功能简介缺失。3)理论介绍缺失或不足。4)摘要草草收尾。5)字数不够,或写得太琐细。6)摘要分段。
(2)项目背景部分常见问题:
1)只在摘要里介绍,而在正文里不介绍项目背景。2)选择非软件项目,如硬件、网络、采购。3)项目太陈旧。4)项目采用的技术太陈旧。5)虚构项目,明显不真实,违背常识。6)“帽子”戴得太多。7)项目与理论不匹配、不适合。
(3)过渡部分常见问题:
1)项目背景与理论之间缺少过渡句。2)理论部分与实践部分缺少过渡句。3)过渡生硬。
(4)理论部分常见问题:1)篇幅太长,超过700字。2)理论部分缺失。3)未响应题干要求,或响应不足。4)与实践部分揉在一起,未单独介绍。5)基本概念、基本原理不清楚,介绍理论不严谨、不科学。6)简单罗列,没有深入体会。7)一个分论点没讲完,又讲到另一个。8)与实践部分完全脱节。
(5)实践部分常见问题:1)篇幅太短,阐述太单薄,浅尝辄止,泛泛而谈。2)简单罗列,纯理论空谈。3)自曝其短:知识点不懂、水平低下。4)阐述框架末围绕论点/分论点,自创一套。5)只阐述Why,不阐述How。6)未从宏观/大局出发,过于强调微观细节。7)使用不合适的、错误的技术手段去解决问题。
(6)结尾部分常见问题:
1)未呼应论点/分论点。2)说起“问题”来滔滔不绝。3)过于单薄,或过于冗长。4)首尾不一致,甚至前后矛盾。
26.5 备考建议
26.5 备考建议关于理论部分,建议与科目一、科目二协同准备,在理解的基础上记住要点,千万不要死记硬背。对于项目背景,建议考生选择自己熟悉的、亲历过的,技术与理论方面选择自己熟悉的、擅长的领域。建议先精写一篇论文练习,购买一点文具店里都有售的方格子作文纸(单页400字),用硬笔先抽空练起来。写完一篇,自己大声朗读一遍,然后修改;再请家人读一读,然后修改,一直修改到满意为止,有条件的请专业老师批改。精心练习一篇之后,若时间允许,再把近三年的历年真题都写一遍。
26.6 范文赏析
论软件架构评估
摘要
26.6 范文赏析论软件架构评估摘要我所在单位是国内某商业银行,2017年1月我行决定开发全新一代绩效考核平台系统,我担任本次系统开发的架构师,主要负责整个系统的架构设计工作。该系统是既要满足内控管理的绩效考核,又要满足银行粉丝客户参与营销的综合性绩效平台,是银行应对互联网金融变革和笃行普惠金融的重要系统。本文结合我的实践,以绩效考核平台系统建设为例,论述软件系统架构评估。首先分析了软件架构评估所普遍关注的质量属性并阐述其具体含义,然后详细说明本次项目软件架构评估采用的ATAM评估方法、实施过程,评估小组经过对系统中的风险点、敏感点、权衡点进行分析后生成质量效用树。通过ATAM架构评估保证了绩效考核平台系统的顺利完成,目前系统已经稳定运行一年多,得到了领导、员工、客户的一致好评。
正文
我所在的单位是长三角地区某城市商业银行,机构覆盖全国多个省、直辖市。目前银行业正面临互联网金融浪潮的冲击,银行需要积极转型、自我变革,不仅要服务好优质客户,还要抓住普通大众客户,发展新零售拓展小微企业客户业务成为当下银行的战略要点。绩效考核将成为银行战略转型的有效指挥棒。正是在这一背景下我行提出建设全新一代绩效考核平台,既对传统的绩效考核做出调整,又结合互联网化的“粉丝及员工”理念,搭建多维度、多渠道、多群体的绩效考核平台。
银行绩效考核涵盖传统存贷款考核、产品营销考核、专项考核几大方面,对银行员工管辖的存贷款计价模型计算员工创造利润、产品营销结果、专项产品达标情况等可量化的指标来考核员工,对客户为银行推销的产品进行量化统计并给予奖励,银行总部通过不同的计价系数和组合策略引导全体员工向政策目标迈进,将绩效考核形成指挥棒。
本绩效考核平台系统采用J2EE技术开发的B/S架构系统,使用SOA架构设计方法,数据库使用IBM DB2 10.5,Redis内存数据库,服务器操作系统采用Redhat 7.2等。
软件质量特性是软件架构设计关注的一个重点,在软件架构评估中的质量属性包含性能、可用性、安全性、可修改性、可靠性、易用性、可测试性等,其中前4个质量属性是质量效应树的重要组成部分。具体含义如下。
(1)性能是指系统响应能力,即系统多久才能对某个事件做出响应,或在某段时间内能处理事件的个数。(2)可用性是指系统能正常运行的时间比。(3)安全性是指系统除了能对合法用户提供服务,还能阻止非授权用户使用的企图或拒绝服务能力。(4)可修改性是指能快速地并以较高性价比对系统进行变更的能力。(5)可靠性是指软件系统在应用或错误面前、在意外或错误使用情况下维持系统的功能特性的基本能力。(6)易用性是衡量一个用户使用软件产品完成指定任务的难易程度。
常用的架构评估方法有基于问卷调查的评估方法、基于度量的评估方法、基于场景的评估方法。基于问卷调查的方法具有主观性,不太适合本项目;基于度量的方法虽然评价比较客观,但需要评价者对系统架构有精确的了解,所以也不太适合本项目;而基于场景的方法要求评估者对系统较为了解,评价比较客观,故本项目采用了基于场景的评估方法。基于场景的评估方法又分为架构分析法(SAAM)、架构权衡分析法(ATAM)和成本效益分析法(CBAM)。本项目根据不同质量属性使用了ATAM作为系统架构评估的方法。
在进行架构评估时,按照需要确定了评估参与者,评估小组由总行业务人员、支行行长代表、主办会计代表、客户经理和柜员代表、客户代表等;项目决策组成员包含总行行长、首席信息官、业务部主管、系统架构师、项目经理、员工代表等。架构涉众还包含项目开发人员、测试人员、运维人员等。架构评估经历了描述和介绍阶段、调查和分析阶段、测试阶段、报告阶段。下面我分别对这四个阶段进行介绍:
(一)描述和介绍阶段,由于参与评估的人员有一部分对ATAM评估不了解,我首先介绍了ATAM架构评估的方法和目的。项目决策组组长、业务主管等人介绍了绩效考核平台的业务动机。最后我作为系统架构设计师描述了整个系统采用SOA架构实现,如何将系统划分为若干独立子系统,各个子系统包含的功能及细节,如何与银行内的其他系统协作,怎么进行安全规划。
(二)在调查和分析阶段,结合场景不同角色的需求方都基于各自立场提出了相关需求,需求及质量场景如下:
A)在正常网络负载情况下,系统必须在2秒内响应用户的操作请求。B)服务端与客户端、微信端的交互,使用SSL证书,实现HTTPS安全加密访问。C)系统能够抵御 $99.99%$ 的黑客攻击。D)微信端客户绑定认证使用客户在银行预留的身份证、姓名、手机号等信息。E)支行用户和客户代表提出Web页面要简洁美观,各功能简单易用,尽可能让用户少输入数据项。F)网络失效后,系统需要在1分钟内发现错误并启用备用网络。G)主机房断电后,必须在3秒内将请求重定向到灾备机房服务器。H)对查询请求的处理时间的要求将影响到系统的集群方式和处理过程的设计。I)微信端的异常和员工的操作失误,不影响系统功能的正常使用。J)科技信息部提出的更改系统加密的级别将对安全性和性能产生影响。K)更改系统的Web页面必须在2人·天内完成,修改绩效考核计算规则必须在1周内完成。L)目前对系统使用“统一的绩效认领中心”业务逻辑描述尚未达成共识,这可能导致部分业务功能模块的重复和绩效计算不准确,影响系统的可修改性。
经过分析总结我们获得了系统质量效用树,属于性能的有A,属于可用性的有F和G,属于安全性的有B和C,属于可修改性的有K,属于可靠性的有I,属于易用性的有E。在这些场景分析中评估人员分析了系统的架构风险、敏感点、权衡点。架构风险是指系统设计过程中潜在的、存在问题的架构决策所带来的隐患,其中L描述的是架构风险;敏感点是指为了实现某个特定质量属性,一个或多个构建具有的特性,其中H属于敏感点;权衡点是指影响多个质量属性的特性,且每个质量属性都属于敏感点,其中J属于权衡点。
(三)在测试阶段,结合银行的特殊性,经过项目干系人集体讨论后,确定了不同场景的优先级:系统安全性、可用性、可靠性最高,性能、可修改性其次,易用性优先级较低。在保障系统安全方面使用SSL数字证书的HTTPS访问协议,网络设备使用网闸、多层异构防火墙、入侵防护系统,数据访问使用分级授权和数据加密存储。可用性方面使用VMware虚拟化平台加心跳技术,当服务器出现问题的时候VMware虚拟机自动迁移到冗余主机。可靠性方面使用服务单独拆分、分层解耦设计,降低一个模块错误对全系统的影响,使用Spring拦截器对用户操作引起的错误进行统一容错处理。性能方面采用Web中间件集群,针对高并发读写操作数据库使用DB2pureScale磁盘共享集群技术加SSD盘存储阵列。可修改方面系统对功能服务进行拆分,通过接口调用实现便捷修改。易用性方面采用界面设计的八大黄金法则,设计出多种风格让用户自由选择。
(四)报告阶段,经过架构的评估,将评估的过程和结果都汇总整理成文档。其中包括架构分析方法文档、不同场景及各自的优先级、质量效用树、风险点决策、非风险点决策、每次评估会议的记录。经过实践证明,实施软件架构评估能正确地识别项目风险点、敏感点、权衡点,提前预判并做好应对措施,做出合理的架构决策,从而提高项目开发的成功率和质量。经过7个月的开发,绩效考核平台顺利上线并稳定运行一年多,充分发挥了绩效激励、赛马式营销、政策指挥棒的作用,目前已在全行推广使用,得到了领导、员工、客户的一致好评。
第6篇 架构设计模拟试题
第27小时 模拟试题I(上午基础知识)
$\bullet$ 系统总线中不包括 (1)
(1)A.数据总线 B.地址总线 C.进程总线 D.控制总线
试题解析 总线包括数据总线、地址总线与系统总线。
参考答案:(1)C
$\bullet$ 目前处理器市场中存在CPU和DSP两种类型的处理器,分别用于不同的场景,这两种处理器具有不同的体系结构,DSP采用(2)。
(2)A.冯·诺依曼结构 B.哈佛结构 C.FPGA结构 D.与GPU相同的结构
试题解析 编程DSP芯片是一种具有特殊结构的微处理器,为了达到快速进行数字信号处理的目的,DSP芯片一般都采用特殊的软硬件结构:哈佛结构。哈佛结构将存储器空间划分成两个,分别存储程序和数据。它们由两组总线连接到处理器核,允许同时对它们进行访问,每个存储器独立编址,独立访问。这种安排将处理器的数据吞吐率加倍,更重要的是同时为处理器核提供数据与指令。在这种布局下,DSP得以实现单周期的MAC指令。在哈佛结构中,由于程序和数据存储器在两个分开的空间中,因此取指和执行能完全重叠运行。
参考答案:B
$\bullet$ 分布式数据库系统除了包含集中式数据库系统的模式结构之外,还增加了几个模式级别,其中,(3)定义分布式数据库中数据的整体逻辑结构,使得数据使用方便,如同没有分布一样。
(3)A.分片模式 B.全局外模式 C.分配模式 D.全局概念模式
试题解析 在分布式数据库中,局部DBMS中的内模式与概念模式与集中数据库是完全一致的,不同之处在于新增的全局DBMS,而整个全局DBMS可以看作是相对于局部概念模式的外模式。由于外模式部分有一系列的分布模式、分片模式、全局概念模式和全局外模式,以及多级映射使得用户在使用分布式数据库时,可以使用集中式数据库同样的方式。具体模式表述如下:
1)全局外模式。全局外模式是全局应用的用户视图,是全局概念模式的子集,该层直接与用户(或应用程序)交互。
2)全局概念模式。全局概念模式定义分布式数据库中数据的整体逻辑结构,数据就如同根本没有分布一样,可用传统的集中式数据库中所采用的方法进行定义。
3)分片模式。在某些情况下,需要将一个关系模式分解成为几个数据片,分片模式正是用于完成此项工作的。
4)分配模式。分布式数据库的本质特性就是数据分布在不同的物理位置。分配模式的主要职责是定义数据片段(即分片模式的处理结果)的存放节点。
5)局部概念模式。局部概念模式是局部数据库的概念模式。
6)局部内模式。局部内模式是局部数据库的内模式。
参考答案:(3)D
$\bullet$ 某计算机系统页面大小为2K,进程P1的页面变换表如下所示,若P1要访问数据的逻辑地址为十六进制1B1AH,那么该逻辑地址经过变换后,其对应的物理地址应为十六进制(4)。
| 页号 | 物理块号 |
| 0 | 1 |
| 1 | 6 |
| 2 | 3 |
| 3 | 4 |
(4)A.1B1AH B.231AH C.6B1AH D.4B1AH
试题解析 本题考查页式存储中的逻辑地址转物理地理。逻辑地址为二进制1101100011010,由于页面大小为2K,所以页内地址长度为11个二进制位,即31BH,而逻辑页号为二进制11,即十进制3。通过查询页表可知对应物理块号为4,所以物理地址为二进制10001100011010,即十六进制231AH。
参考答案:(4)B
$\bullet$ 在嵌入式系统的存储部件中,存取速度最快的是(5)。
(5)A.内存 B.寄存器组 C. Flash D. Cache
试题解析 存储速度从快到慢分别是:寄存器组、Cache、内存、Flash。
参考答案:(5)B
$\bullet$ 以下描述中,(6)不是嵌入式操作系统的特点。
(6)A.面向应用,可以进行裁剪和移植B.用于特定领域,不需要支持多任务C.可靠性高,无须人工干预独立运行,并处理各类事件和故障D.要求编码体积小,能够在嵌入式系统的有效存储空间内运行
试题解析 嵌入式操作系统是应用于嵌入式系统,实现软硬件资源的分配,任务调度,控制、协调并发活动等的操作系统软件。它除了具有一般操作系统最基本的功能如多任务调度、同步机制等之外,通常还会具备以下适用于嵌入式系统的特性:面向应用,可以进行检查和移植,以支持开放性和可伸缩性的体系结构;强实时性,以适应各种控制设备及系统;硬件适用性,对于不同硬件平台提供有效的支持并实现统一的设备驱动接口;高可靠性,运行时无须用户过多干预,并处理各类事件和故障;编码体积小,通常会固化在嵌入式系统有限的存储单元中。
参考答案:(6)B
$\bullet$ 为了适应软件运行环境的变化而修改软件的活动称为(7);根据用户在软件使用过程中提出的建设性意见而进行的维护活动称为(8)。
(7)A.纠错性维护 B.适应性维护 C.改善性维护 D.预防性维护
(8)A.纠错性维护 B.适应性维护 C.改善性维护 D.预防性维护
试题解析 软件维护的类型有4种:改正性维护、适应性维护、完善性维护和预防性维护。改正性维护是要改正在特定的使用条件下暴露出来的一些潜在的程序错误或设计缺陷。
适应性维护是要在软件使用过程中数据环境发生变化或处理环境发生变化时修改软件以适应这种变化。
完善性维护是在用户和数据处理人员使用软件过程中提出改进现有功能,增加新的功能,以及改善总体性能的要求后,修改软件以把这些要求纳入到软件之中。
预防性维护是为了提高软件的可维护性、可靠性等,事先采用先进的软件工程方法对需要维护的软件或软件中的某一部分(重新)进行设计、编制和测试,为以后进一步改进软件打下良好基础。
参考答案:(7)B (8)C
$\bullet$ ERP中的企业资源包括(9)
(9)A.物流、资金流和信息流 B.物流、工作流和信息流 C.物流、资金流和工作流 D.资金流、工作流和信息流
试题解析企业的所有资源包括三大流:物流、资金流和信息流。而ERP也就是对这3种资源进行全面集成管理的管理信息系统。
参考答案:(9)A
$\bullet$ ERP(Enterprise Resource Planning)是建立在信息技术的基础上,利用现代企业的先进管理思想,对企业的物流、资金流和(10)流进行全面集成管理的管理信息系统,为企业提供决策、计划、控制与经营业绩评估的全方位和系统化的管理平台。在ERP系统中,(11)管理模块主要是对企业物料的进、出、存进行管理。
(10)A.产品 B.人力资源 C.信息 D.加工(11)A.库存 B.物料 C.采购 D.销售
试题解析企业资源计划(Enterprise Resource Planning,ERP)是建立在信息技术的基础上,利用现代企业的先进管理思想,对企业的物流、资金流和信息流进行全面集成管理的管理信息系统,为企业提供决策、计划、控制与经营业绩评估的全方位和系统化的管理平台。
$\bullet$ ERP 系统主要包括:生产预测、销售管理、经营计划、主生产计划、物料需求计划、能力需求计划、车间作业计划、采购与库存管理、质量与设备管理、财务管理、有关扩展应用模块等内容。显然对企业物料的进、出、存进行管理的模块是库存管理模块。
参考答案:(10)C (11)A
$\bullet$ 电子政务是对现有的政府形态的一种改造,利用信息技术和其他相关技术,将其管理和服务职能进行集成,在网络上实现政府组织结构和工作流程优化重组。与电子政务相关的行为主体有三个,即政府、(12)及居民。国家和地方人口信息的采集、处理和利用,属于(13)的电子政务活动。
(12)A.部门 B.企(事)业单位 C.管理机构 D.行政机关
(13)A.政府对政府 B.政府对居民 C.居民对居民 D.居民对政府
试题解析 电子政务是对现有的政府形态的一种改造,利用信息技术和其他相关技术,将其管理和服务职能进行集成,在网络上实现政府组织结构和工作流程优化重组。与电子政务相关的行为主体有三个,即政府、企(事)业单位及居民。国家和地方人口信息的采集、处理和利用,属于政府对政府的电子政务活动。
参考答案:(12)B (13)A
$\bullet$ 电子政务的主要应用模式中不包括(14)(14)A.政府对政府(Government To Government)B.政府对客户(Government To Customer)C.政府对居民(Government To Citizen)D.政府对企业(Government To Business)
试题解析 电子政务是政府机构应用现代信息和通信技术,将管理和服务通过网络技术进行集成,在因特网上实现政府组织结构和工作流程的优化重组,超越时间和空间及部门之间的分隔限制,向社会提供优质和全方位的、规范而透明的、符合国际水准的管理与服务。电子政务的主要模式包括G2G、G2B、G2C、B2G、C2G,但不包括政府对客户(Government To Customer)。
参考答案:(14)B
$\bullet$ 给定关系R(A,B,C,D,E)和关系S(D,E,F,G),对其进行自然连接运算 $\mathrm{R}\bowtie \mathrm{S}$ 后结果集的属性列为(15)。
(15)A.R.A,R.B,R.C,R.D,R.E,S.D,S.E B.R.A,R.B,R.C,R.D,R.E,S.F,S.G C.R.A,R.B,R.C,R.D,R.E,S.E,S.F D.R.A,R.B,R.C,R.D,R.E,S.D,S.E,S.F,S.G
试题解析 自然连接是在笛卡儿积中把两个关系中相同的属性组进行比较,并且在结果中将重复的属性去掉。该题的笛卡儿积有9个属性,R.A,R.B,R.C,R.D,R.E,S.D,S.E,S.F,S.G,去掉重复的属性,剩余R.A,R.B,R.C,R.D,R.E,S.F,S.G。
参考答案:(15)B
$\bullet$ 设关系模式 $\mathrm{R(U,F)}$ $\mathrm{U} = {\mathrm{A1}$ ,A2,A3,A4},函数依赖集 $\mathrm{F} = {\mathrm{A1}\rightarrow \mathrm{A2}$ , $\mathrm{A1}\rightarrow \mathrm{A3}$ , $\mathrm{A2}\rightarrow \mathrm{A4}}$ 关系R的候选码是(16)。下列结论错误的是(17)。
(16)A.A1 B.A2 C.A1A2 D.A1A3
(17)A. $\mathrm{Al}\rightarrow \mathrm{A2A3}$ 为F所蕴含 B. $\mathrm{Al}\rightarrow \mathrm{A4}$ 为F所蕴含 C. $\mathrm{AlA2}\rightarrow \mathrm{A4}$ 为F所蕴含 D. $\mathrm{A2}\rightarrow \mathrm{A3}$ 为F所蕴含
试题解析 通过A1可以得到A2、A3,通过A2又可以得到A4,因此A1属于候选键。A3只能由A1得到,A2无法得到A3。
参考答案:(16)A (17)D
$\bullet$ 给定学生关系S(学号,姓名,学院名,电话,家庭住址)、课程关系C(课程号,课程名,选修课程号)、选课关系SC(学号,课程号,成绩)。查询“张晋”选修了“市场营销”课程的学号、学生名、学院名、成绩的关系代数表达式为: $\Pi_{1,2,3,7}(\Pi_{1,2,3}$ (18)(19)
(18)A. $\sigma 2 =$ 张晋(S) B. $\sigma 2 =$ ‘张晋’(S) C. $\sigma 2 =$ 张晋(SC) D. $\sigma 2 =$ ‘张晋’(SC)
(19)A. $\Pi_{2,3}(\sigma 2 =$ ‘市场营销’(C))SC B. $\Pi_{2,3}(\sigma 2 =$ 市场营销(SC))SC C. $\Pi_{1,2}(\sigma 2 =$ ‘市场营销’(C))SC D. $\Pi_{1,2}(\sigma 2 =$ 市场营销(SC))SC
试题解析 完整的表达式为:
$\Pi_{1,2,3,7}((\Pi_{1,2,3}(\sigma 2 = \mathrm{}^{\prime}\mathrm{}$ 张晋(S)))SC)表达式 $\Pi_{1,2,3}(\sigma 2 = \mathrm{~}^{\prime}$ 张晋(S)),在关系S中选择姓名为张晋的学生,投影出学号、姓名、学院名三个属性。
表达式 $\Pi_{1,2}(\sigma 2 = \mathrm{~}^{\prime}$ 市场营销’(C))SC,在关系C中选择课程名是市场营销的元组,投影出课程号、课程名两个属性。之后再与关系SC进行自然连接,可以得出学号、课程号、课程名、成绩五个属性。
将上述两个表达式 $\Pi_{1,2,3}(\sigma 2 = \mathrm{}^{\prime}$ 张晋’(S))与 $\Pi_{1,2}(\sigma 2 = \mathrm{}^{\prime}$ 市场营销’(C))SC进行自然连接后投影1,2,3,7列,即投影出学号、姓名、学院名、成绩。
参考答案:(18)B (19)C
$\bullet$ 在数据库设计的需求分析阶段应当形成(20),这些文档可以作为(21)阶段的设计依据。
(20)A.程序文档、数据字典和数据流图 B.需求说明文档、程序文档和数据流图 C.需求说明文档、数据字典和数据流图 D.需求说明文档、数据字典和程序文档
(21)A.逻辑结构设计 B.概念结构设计 C.物理结构设计 D.数据库运行和维护
试题解析 数据库设计主要分为用户需求分析、概念结构、逻辑结构和物理结构设计4个阶段。其中,在用户需求分析阶段中,数据库设计人员采用一定的辅助工具对应用对象的功能、性能、限制等要求所进行的科学分析,并形成需求说明文档、数据字典和数据流程图。用户需求分析阶段形成的相关文档用以作为概念结构设计的设计依据。
参考答案:(20)C (21)B
$\bullet$ 基于软件架构的设计(Architecture Based Software Development,ABSD)强调由商业、质量和功能需求的组合驱动软件架构设计。它强调采用(22)来描述软件架构,采用(23)来
描述需求。
(22)A.类图和序列图 B.视角与视图 C.构件和类图 D.构件与功能
(23)A.用例与类图 B.用例与视角 C.用例与质量场景 D.视角与质量场景
试题解析 根据基于软件架构的设计的定义,基于软件架构的设计(Architecture Based Software Development,ABSD)强调由商业、质量和功能需求的组合驱动软件架构设计。它强调采用视角与视图来描述软件架构,采用用例与质量属性场景来描述需求。
参考答案:(22)B (23)C
$\bullet$ 以下关于鸿蒙操作系统的叙述中,不正确的是(24)。
(24)A.鸿蒙操作系统整体架构采用分层的层次化设计,从下向上依次为:内核层、系统服务层、框架层和应用层 B.鸿蒙操作系统内核层采用宏内核设计,拥有更强的安全特性和低时延特点 C.鸿蒙操作系统架构采用了分布式设计理念,实现了分布式软总线、分布式设备系统的虚拟化、分布式数据管理和分布式任务调度等四种分布式能力 D.架构的系统安全性主要体现在搭载 HarmonyOS 的分布式终端上,可以保证“正确的人,通过正确的设备,正确地使用数据”
试题解析 鸿蒙操作系统采用微内核架构,整体采用层次式架构,采用分布式理念且实现了分布式安全框架。
参考答案:(24)B
$\bullet$ 某公司欲开发一个在线交易系统,在架构设计阶段,公司的架构师识别出3个核心质量属性场景。其中“在并发用户数量为1000人时,用户的交易请求需要在0.5秒内得到响应”主要与(25)质量属性相关,通常可采用(26)架构策略实现该属性;“当系统由于软件故障意外崩溃后,需要在0.5小时内恢复正常运行”主要与(27)质量属性相关,通常可采用(28)架构策略实现该属性;“系统应该能够抵挡恶意用户的入侵行为,并进行报警和记录”主要与(29)质量属性相关,通常可采用(30)架构策略实现该属性。
(25)A.性能 B.吞吐量 C.可靠性 D.可修改性(26)A.操作串行化 B.资源调度 C.心跳 D.内置监控器(27)A.可测试性 B.易用性 C.可用性 D.互操作性(28)A.主动冗余 B.信息隐藏 C.抽象接口 D.记录/回放(29)A.可用性 B.安全性 C.可测试性 D.可修改性(30)A.内置监控器 B.记录/回放 C.追踪审计 D.维护现有接口
试题解析 对于题干的描述:“在并发用户数量为1000人时,用户的交易请求需要在0.5秒内得到响应”,主要与性能这一质量属性相关,实现该属性的常见架构策略包括:增加计算资源、减少计算开销、引入并发机制、采用资源调度等。“当系统由于软件故障意外崩溃后,需要在0.5小时内恢复正常运行”主要与可用性质量属性相关,通常可采用心跳、Ping/Echo、主动冗余、被动冗余、选举等架构策略实现该属性;“系统应该能够抵挡恶意用户的入侵行为,并进行报警和记录”主要与安全性质量属性相关,通常可采用入侵检测、用户认证、用户授权、追踪审计等架构策略实现该属性。
参考答案:(25)A (26)B (27)C (28)A (29)B (30)C
$\bullet$ 下列关于软件可靠性的叙述,不正确的是(31)
(31)A.由于影响软件可靠性的因素很复杂,软件可靠性不能通过历史数据和开发数据直接测量和估算出来B.软件可靠性是指在特定环境和特定时间内,计算机程序无故障运行的概率C.在软件可靠性的讨论中,故障指软件行为与需求的不符,故障有等级之分D.排除一个故障可能会引入其他的错误,而这些错误会导致其他的故障
试题解析 软件可靠性是软件系统在规定的时间内及规定的环境条件下,完成规定功能的能力,也就是软件无故障运行的概率。这里的故障是软件行为与需求的不符,故障有等级之分。软件可靠性可以通过历史数据和开发数据直接测量和估算出来。在软件开发中,排除一个故障可能会引入其他的错误,而这些错误会导致其他的故障,因此,在修改错误以后,还需要进行回归测试。
参考答案:(31)A
$\bullet$ 在一个典型的电子商务应用中,三层架构(即表现层、商业逻辑层和数据访问层)常常是架构师的首选。常见的电子商务应用——网上书城的主要功能是提供在线的各种图书信息的查询和浏览,并且能够订购相关图书。用户可能频繁地进行书目查询操作,网站需要返回众多符合条件的书目并且分页显示;网站管理员需要批量对相关书目信息进行修改,并且将更新信息记录到数据库。针对前一个应用要求,架构师在数据访问层设计时,最可能考虑采用(32);针对后一个应用要求,架构师最可能考虑采用(33)
(32)A.在线访问模式和DAO模式相结合 B.在线访问模式和离线数据模式相结合C.DAO模式和DTO模式相结合 D.DTO模式和O/R映射模式相结合
(33)A.在线访问模式 B.DAO模式C.离线数据模式 D.O/R映射模式
试题解析 在线访问模式、DataAccessObject(DAO)模式、DataTransferObject(DTO)模式、离线数据模式和对象/关系映射(Object/RelationMapping)模式是数据持久层(数据访问层)架构设计中常用的数据访问模式。
在网上书城应用中,用户根据查询条件查询相关的书目,返回符合条件的书目列表,可能内容非常多,而且可能每次查询的内容都不一样。针对用户书目查询的应用,如果查询返回的数据量并不是很大,同时也不频繁,则可以考虑采用在线访问的模式;如果返回的数据量较大(例如返回众多符合条件的书目并且分页显示)而且较为频繁,则可以考虑在线访问模式和离线模式相结合,通过离线数据的缓存来提高查询的性能。
网站管理员可能需要批量对相关书目信息进行修改,并且需要将更新信息返回至数据库。此类数据应用的特点表现为:与数据库交互的次数并不频繁,但是每次的数据量相对较大;同时,也希望能够使得本地操作有较好的交互体验。针对这种情况,往往适合采用离线数据访问的模式,DTO
模式也是不错的选择。如果该网上书城应用系统采用的是 IBM WebSphere 平台,则可以使用 SDO 技术,或者使用 Java 中的 CachedRowSet 技术;如果采用的是基于微软的应用系统平台,则可以采用 ADO.NET 技术。
参考答案:(32)B (33)C
$\bullet$ 螺旋模型在(34)的基础上扩展而成。
(34)A.瀑布模型 B.原型模型 C.快速模型 D.面向对象模型
试题解析 螺旋模型是在原型模型的基础上扩展而成的。
参考答案:B
$\bullet$ (35)适用于程序开发人员在地域上分布很广的开发团队。(36)中,编程开发人员分成首席程序员和“类”程序员。
(35)A.水晶系列(Crystal)开发方法 B.开放式源码(Open Source)开发方法 C.SCRUM 开发方法 D.功用驱动开发方法(FDD)
(36)A.自适应软件开发(ASD) B.极限编程(XP)开发方法 C.开放统一过程开发方法(OpenUP) D.功用驱动开发方法(FDD)
试题解析
1)极限编程(Extreme Programming,XP)在所有的敏捷型方法中,XP 是最引人瞩目的。它源于 Smalltalk 圈子,特别是 Kent Beck 和 Ward Cunningham 在 20 世纪 80 年代末的密切合作。XP 在一些对费用控制严格的公司中的使用,已经被证明是非常有效的。
2)Cockburn 的水晶系列方法。水晶系列方法是由 Alistair Cockburn 提出的。它与 XP 方法一样,都有以人为中心的理念,但在实践上有所不同。Alistair 考虑到人们一般很难严格遵循一个纪律约束很强的过程,因此,与 XP 的高度纪律性不同,Alistair 探索了用最少纪律约束而仍能成功的方法,从而在产出效率与易于运作上达到一种平衡。也就是说,虽然水晶系列不如 XP 那样的产出效率,但会有更多的人能够接受并遵循它。
3)开放式源码。这里提到的开放式源码指的是开放源码界所用的一种运作方式。开放式源码项目有一个特别之处,就是程序开发人员在地域上分布很广,这使得它和其他敏捷方法不同,因为一般的敏捷方法都强调项目组成员在同一地点工作。开放源码的一个突出特点就是查错排障(Debug)的高度并行性,任何人发现了错误都可将改正源码的“补丁”文件发给维护者。然后由维护者将这些“补丁”或是新增的代码并入源码库。
4)SCRUM。SCRUM 已经出现很久了,像前面所论及的方法一样,该方法强调这样一个事实,即明确定义了的可重复的方法过程只限于在明确定义了的可重复的环境中,为明确定义了的可重复的人员所用,去解决明确定义了的可重复的问题。
5)Coad 的功用驱动开发方法(Feature Driven Development,FDD)。FDD 是由 Jeff De Luca 和 Peter Coad 提出来的。像其他方法一样,它致力于短时的迭代阶段和可见可用的功能。在 FDD 中,一个迭代周期一般是两周。
6)在 FDD 中,编程开发人员分成两类:首席程序员和“类”程序员(Class Owner)。首席程
序员是最富有经验的开发人员,他们是项目的协调者、设计者和指导者,而“类”程序员则主要做源码编写。
7)自适应软件开发方法,(Adaptive Software Development,ASD)。ASD方法由Jim Highsmith提出,其核心是三个非线性的、重叠的开发阶段:猜测、合作与学习。
参考答案:(35)B (36)D
$\bullet$ 需求管理是一个对系统需求变更、了解和控制的过程。以下活动中,(37)不属于需求管理的主要活动。
(37)A.文档管理 B.需求跟踪 C.版本控制 D.变更控制
试题解析 需求管理的活动包括变更控制、版本控制和需求跟踪等。
参考答案:A
$\bullet$ 软件测试一般分为两个大类:动态测试和静态测试。前者通过运行程序发现错误,包括(38)等方法;后者采用人工和计算机辅助静态分析的手段对程序进行检测,包括(39)等方法。
(38)A.边界值分析、逻辑覆盖、基本路径 B.桌面检查、逻辑覆盖、错误推测 C.桌面检查、代码审查、代码走查 D.错误推测、代码审查、基本路径
(39)A.边界值分析、逻辑覆盖、基本路径 B.桌面检查、逻辑覆盖、错误推测 C.桌面检查、代码审查、代码走查 D.错误推测、代码审查、基本路径
试题解析 本题考查测试的分类,测试可以分为动态测试与静态测试。
动态测试是通过运行程序发现错误,包括黑盒测试(等价类划分、边界值分析法、错误推测法)与白盒测试(各种类型的覆盖测试)。
静态测试是人工测试方式,包括桌前检查(桌面检查)、代码走查、代码审查。
参考答案:(38)A (39)C
$\bullet$ 在系统开发中,原型可以划分为不同的种类。从原型是否实现功能来分,可以分为水平原型和垂直原型;从原型最终结果来分,可以分为抛弃式原型和演化式原型。以下关于原型的叙述中,正确的是(40)。
(40)A.水平原型适合于算法较为复杂的项目 B.垂直原型适合于Web项目 C.抛弃式原型适合于需求不确定、不完整、含糊不清的项目 D.演化式原型主要用于界面设计
试题解析 本题考查原型开发方法的相关概念。
水平原型主要用在界面上。
垂直原型主要用在复杂的算法实现上,抛弃式原型主要用于界面设计。
抛弃式原型的基本思路就是开始就做一个简单的界面设计,用来让用户有直观感受,从而可以提得出需求,等需求获取到之后,可以把这个界面原型抛弃不用。
演化式原型主要用在必须易于升级和优化的场合,适合于Web项目。
参考答案:(40)C
$\bullet$ 快速应用开发(Rapid Application Development,RAD)通过使用基于。(41)的开发方法获得快速开发,当(42)时,最适合采用RAD方法。
(41)A. 用例 B. 数据结构 C. 剧情 D. 构件
(42)A. 一个新系统要采用很多新技术 B. 新系统与现有系统有较高的互操作性 C. 系统模块化程度较高 D. 用户不能很好地参与到需求分析中
试题解析 快速应用开发是一种比传统生存周期法快得多的开发方法,它强调极短的开发周期。RAD模型是瀑布模型的一个高速变种,通过使用基于构件的开发方法获得快速开发。如果对需求理解得很好且约束了项目范围,利用这种模型可以很快地开发出功能完善的信息系统。但是RAD也具有以下局限性:
1)并非所有应用都适合RAD,RAD对模块化要求比较高。如果有哪一项功能不能被模块化,那么RAD所需要的构件就会有问题;如果高性能是一个指标且该指标必须通过调整接口使其适应系统构件才能获得,则RAD也可能不能奏效。
2)开发者和客户必须在很短的时间完成一系列的需求分析,任何一方配合不当都会导致RAD项目失败。
3)RAD只能用于管理信息系统的开发,不适合技术风险很高的情况。例如,当一个新系统要采用很多新技术,或当新系统与现有系统有较高的互操作性时就不适合使用RAD。
参考答案:(41)D (42)C
$\bullet$ 软件架构维护过程不包括(43)
(43)A. 架构知识管理 B. 架构修改管理 C. 架构版本管理 D. 架构构件管理
试题解析 软件架构维护过程包括架构知识管理、架构修改管理、架构版本管理等。
参考答案:(43)D
$\bullet$ 下列软件架构演化时期,(44)是在系统设计时规定了演化的具体条件,将系统置于“安全”模式下,演化只发生在某些特定约束满足时,可以进行一些规定好的演化操作。
(44)A. 设计时演化 B. 运行前演化 C. 有限制运行时演化 D. 运行时演化
试题解析 设计时演化:发生在体系结构模型与之相关的代码编译之前;运行前演化:发生在执行之前、编译之后;有限制运行时演化:只发生在某些特定约束满足时;运行时演化:发生在运行时不能满足要求时。
参考答案:(44)C
$\bullet$ 根据所修改的内容不同,软件的动态演化不包括(45)
(45)A. 属性改名 B. 行为变化 C. 拓扑结构改变 D. 格式变化
试题解析 动态演化的内容:属性改名、行为变化、拓扑结构改变、风格变化。
参考答案:(45)D
$\bullet$ 架构权衡分析方法(Architecture Tradeoff Analysis Method,ATAM)是在基于场景的架构分析方法(Scenarios- Based Architecture Analysis Method,SAAM)基础上上发展起来的,主要包括场景和需求收集、(46)属性模型构造和分析、属性模型折中等4个阶段。ATAM方法
要求在系统开发之前,首先对这些质量属性进行(47)和折中。
(46)A.架构视图和场景实现 B.架构风格和场景分析 C.架构设计和目标分析 D.架构描述和需求评估
(47)A.设计 B.实现 C.测试 D.评价
试题解析 ATAM是在基于场景的架构分析方法基础之上发展起来的,主要包括场景和需求收集、架构视图和场景实现、属性模型构造和分析、属性模型折中等4个阶段。该方法要求在系统开发之前,首先对这些质量属性进行评价和折中。
参考答案:(46)A(47)D
$\bullet$ 某公司内部的库存管理系统和财务系统均为独立开发且具有C/S结构,公司在进行信息系统改造时,明确指出要采用最小的代价实现库存系统和财务系统的一体化操作与管理。针对这种应用集成需求,以下集成方法中,最适合的是(48)。
(48)A.数据集成 B.界面集成 C.方法集成 D.接口集成
试题解析根据题干条件,库存管理系统和财务系统都是独立开发且具有C/S结构,并且集成时要求采用最小的代价实现库存系统和财务系统的一体化操作与管理,因此只需要将两个系统的用户界面集成在一起即可在最小代价的条件下满足集成要求。
参考答案:B
$\bullet$ CPS技术体系的四大核心技术要求中,“一平台”是(49)。
(49)A.感知和自动控制 B.工业软件 C.工业网络 D.工业云和智能服务平台
试题解析CPS技术分为4大核心技术要素:“一硬”(感知和自动控制,是CPS实现的硬件支撑)、“一软”(工业软件,CPS核心)、“一网”(工业网络,是网络载体)、“一平台”(工业云和智能服务平台,是支撑上层解决方案的基础)。
参考答案:(49)D
$\bullet$ 人工智能的关键技术包括自然语言处理、计算机视觉、知识图谱、机器学习。机器学习分类中,(50)是利用已标记的有限训练数据集,通过某种学习策略/方法建立一个模型,从而实现对新数据/实例标记/映射。
(50)A.监督学习 B.无监督学习 C.半监督学习 D.强化学习
试题解析按学习模式不同分为监督学习(需提供标注的样本集)、无监督学习(不需提供标注的样本集)、半监督学习(需提供少量标注的样本集)、强化学习(需反馈机制)。
参考答案:(50)A
$\bullet$ 云计算的服务方式不包括(51)。
(51)A.软件即服务 B.计算即服务 C.平台即服务 D.基础设施即服务
试题解析 云计算的服务方式包括:
1)软件及服务(SaaS):服务提供商将应用软件统一部署在云计算服务器上。2)平台即服务(PaaS):服务提供商将分布式开发环境与平台作为一种服务来提供。
3)基础设施即服务(IaaS):服务提供商将多台服务器组成“云端”基础设施作为计量服务提供给客户。
参考答案:(51)B
$\bullet$ 以下属于主动攻击的是(52)
(52)A.网络监听 B.信息截取 C.非法登录 D.假冒身份
试题解析主动攻击会对信息进行修改、伪造,而被动攻击只是非法获取信息,不会对信息进行任何修改。
参考答案:(52)D
$\bullet$ 信息安全策略应该全面地保护信息系统整体的安全,网络安全体系设计是网络逻辑设计工作的重要内容之一,可从物理线路安全、网络安全、系统安全、应用安全等方面来进行安全体系的设计与规划。其中,数据库的容灾属于(53)的内容。
(53)A.物理线路安全与网络安全 B.网络安全与系统安全C.物理线路安全与系统安全 D.网络安全与应用安全
试题解析依据信息安全体系架构,物理安全包括环境、设备和媒体;系统安全包括网络结构、操作系统、应用系统;网络安全包括访问控制、通信保密、入侵检测、网络安全扫描、防病毒;应用安全包括资源共享和信息存储。数据库的容灾属于对信息存储方面的安全和网络方面的安全。
参考答案:(53)D
$\bullet$ (54)模型为数据规划机密性,依据机密性划分安全级别,按安全级别强制访问控制。
(54)A.BLP模型 B.状态机模型 C.Biba模型 D.CWM模型
试题解析Bell- LaPadula模型(BLP模型)为数据规划机密性,依据机密性划分安全级别,按安全级别强制访问控制。
参考答案:(54)A
$\bullet$ “在某个系统或某个部件中设置了‘机关’,使得当提供特定的输入数据时,允许违反安全策略。”是属于哪一种安全威胁?(55)
(55)A.特洛伊木马 B.陷阱门 C.窃取 D.非法使用
试题解析陷阱门是在某个系统或某个部件中设置了“机关”,使得当提供特定的输入数据时,允许违反安全策略。
参考答案:(55)B
$\bullet$ 软件脆弱性是软件中存在的弱点(或缺陷),利用它可以危害系统安全策略,导致信息丢失、系统价值和可用性降低。嵌入式系统软件架构通常采用分层架构,它可以将问题分解为一系列相对独立的子问题,局部化在每一层中,从而有效地降低单个问题的规模和复杂性,实现复杂系统的分解。但是,分层架构仍然存在脆弱性。常见的分层架构的脆弱性包括(56)等两方面。
(56)A.底层发生错误会导致整个系统无法正常运行、层与层之间功能引用可能导致功能失效 B.底层发生错误会导致整个系统无法正常运行、层与层之间引入通信机制势必造成性
能下降
C. 上层发生错误会导致整个系统无法正常运行、层与层之间引入通信机制势必造成性能下降D. 上层发生错误会导致整个系统无法正常运行、层与层之间的功能引用可能导致功能失效
试题解析 层次式架构的软件脆弱性主要表现在层间脆弱性和层间通信脆弱性两个方面,层间脆弱性体现在某个底层的错误会导致整个系统都无法正常工作,层间通信脆弱性表现在层次间引入通信机制会造成大量消息交互,从而造成系统性能下降。
参考答案:(56)B
$\bullet$ 局域网网络架构有4种类型,以下说法错误的是(57)
(57)A.单核心架构使用单台核心二层或三层交换设备作为网络核心B.单核心架构的优点是结构简单,设备投资节约,接入方便C.双核心架构采用两台核心三层及以上交换机作为网络核心D.环型架构的缺点是投资较单核心高,核心端口密度要求较高
试题解析双核心架构的缺点是投资较单核心高,核心端口密度要求较高。
参考答案:(57)D
以下不属于网络安全协议的是(58)
(58)A.FTP B.SSL C.HTTPS D.SET
试题解析文件传输协议(File Transport Protocol,FTP)是网络上两台计算机传送文件的协议,运行在TCP之上,是通过Internet将文件从一台计算机传输到另一台计算机的一种途径。
参考答案:(58)A
$\bullet$ 以下关于层次化网络设计原则的叙述中,错误的是(59)
(59)A.一般将网络划分为核心层、汇聚层、接入层三个层次B.应当首先设计核心层,再根据必要的分析完成其他层次的设计C.为了保证网络的层次性,不能在设计中随意加入额外连接D.除去接入层,其他层次应尽量采用模块化方式,模块间边界应非常清晰
试题解析按照层次式网络设计原则,首先要控制网络层次,一般将网络划分为核心层、汇聚层、接入层三个层次;其次从接入层开始向上分析规划;再次尽量采用模块化设计,除去接入层,其他层次应尽量采用模块化方式;还要严格控制网络结构,模块间边界应非常清晰;最后严格控制层次化结构,为了保证网络的层次性,不能在设计中随意加入额外连接。
参考答案:(59)B
$\bullet$ 以下关于大数据的说法中,错误的是(60)
(60)A.大数据拥有体量大、构造单调、时效性强等特点B.处理大数据需要采用新式计算架构和智能算法等新技术C.大数据的应用着重相关剖析,而不是因果剖析
D. 大数据的目的在于发现新的知识,洞悉并进行科学决策
试题解析 大数据具有体量大、时效性强的特征,并非构造单调,而是类型多样;处理大数据时,传统数据处理系统因数据过载、来源复杂、类型多样等诸多原因性能低下,需要采用以新式计算架构和智能算法为代表的新技术;大数据的应用重在发掘数据间的相关性,而非传统逻辑上的因果关系。因此,大数据的目的和价值就在于发现新的知识,洞悉并进行科学决策。
参考答案:(60)A
$\bullet$ Lambda架构分为三层:(61)的核心功能是存储主数据集。(62)的核心功能是处理增量实时数据、生成实时视图、快速执行即席查询。(63)的核心功能是响应用户请求,合并批视图和实时视图中的结果数据集得到最终数据集。
(61)A.批处理层 B.流处理层 C.加速层 D.存储层(62)A.批处理层 B.服务层 C.加速层 D.视图层(63)A.视图层 B.流处理层 C.服务层 D.存储层
试题解析 Lambda架构分为三层:
1)批处理层。该层核心功能是存储主数据集,主数据集数据具有原始、不可变、真实的特征。批处理层周期性将增量数据存储至主数据集,并在主数据集上执行批处理,生成批视图。架构实现方面可以使用Hadoop HDFS或HBase存储主数据集,再利用Spark或Map/Reduce执行周期批处理,之后使用Map/Reduce创建批视图。
2)加速层。该层的核心功能是处理增量实时数据、生成实时视图、快速执行即席查询。架构实现方面可以使用Hadoop HDFS或HBase存储实时数据,利用Spark或Storm实现实时数据处理和实时视图。
3)服务层。该层的核心功能是响应用户请求,合并批视图和实时视图中的结果数据集得到最终数据集。具体来说就是接收用户请求,通过索引加速访问批视图,直接访问实时视图,然后合并两个视图的结果数据集生成最终数据集,响应用户请求。架构实现方面可以使用HBase或Cassandra作为服务层,通过Hive创建可查询的视图。
参考答案:(61)A(62)C(63)C
$\bullet$ 微服务架构将一个大型的单个应用或服务拆分成多个微服务,可扩展单个组件而不是整个应用程序堆栈,从而满足服务等级协议。微服务架构围绕业务领域将服务进行拆分,每个服务可以(64),彼此之间使用统一接口进行交流,实现了在分散组件中的部署、管理与服务功能,使产品交付变得更加简单,从而达到有效拆分应用,实现敏捷开发与部署的目的。
(64)A.独立进行开发、管理、迭代 B.独立进行部署、运维、升级 C.独立进行测试、交付、验收 D.独立进行发布、发现、访问
试题解析 微服务架构围绕业务领域将服务进行拆分,每个服务可以独立进行开发、管理和迭代,彼此之间使用统一接口进行交流,实现了在分散组件中的部署、管理与服务功能。
参考答案:(64)A
MD5是一种(65)算法。
(65)A.共享密钥 B.公开密钥 C.报文摘要 D.访问控制
试题解析MD5的全称是Message- Digest Algorithm5,是计算机安全领域广泛使用的一种散列函数,用以提供消息的完整性保护。
参考答案:(65)C
$\bullet$ SQL是一种数据库结构化查询语言,SQL注入攻击的首要目标是(66)。(66)A.破坏Web服务 B.窃取用户口令等机密信息C.攻击用户浏览器,以获得访问权限D.获得数据库的权限
试题解析所谓SQL注入,就是通过把SQL命令插入到Web表单递交或输入域名或页面请求的查询字符串,最终欺骗服务器执行恶意的SQL命令,目标就是为了获得数据库的权限,从而非法获得数据。
参考答案:(66)D
$\bullet$ 在数据库的安全机制中,通过提交(67)供第三方开发人员使用进行数据更新,从而保证数据库的关系模式不被第三方所获取。
(67)A.索引 B.视图 C.触发器 D.存储过程
试题解析存储过程提供类似函数的编程接口,可以屏蔽数据库的关系模式,不被第三方所获取。
参考答案:(67)D
$\bullet$ 根据历史统计情况,某超市某种面包的日销量为100、110、120、130、140个的概率相同,每个面包的进价为4元,销售价为5元,但如果当天没有卖完,剩余的面包次日将以每个3元处理。为取得最大利润,该超市每天应进货这种面包(68)个。
(68)A.110 B.120 C.130 D.140
试题解析每种面包进货和销售情况如下表所示。可以得出超市每天进货面包120个时,利润最大。
| 销售量/个 | 100 | 110 | 120 | 130 | 140 | 平均收益 |
| 概率/% | 20 | 20 | 20 | 20 | 20 | |
| 进110个 | 90 | 110 | 110 | 110 | 110 | 106 |
| 进120个 | 80 | 100 | 120 | 120 | 120 | 108 |
| 进130个 | 70 | 90 | 110 | 130 | 130 | 106 |
| 进140个 | 60 | 80 | 100 | 120 | 140 | 100 |
参考答案:(68)B
$\bullet$ 下表记录了六个节点:A、B、C、D、E、F之间的路径方向和距离,从A到F的最短距离是(69)。
| 到 从 | B | C | D | E | F |
| A | 11 | 16 | 24 | 36 | 54 |
| B | 13 | 16 | 21 | 29 | |
| C | 14 | 17 | 22 | ||
| D | 14 | 17 | |||
| E | 15 |
(69)A. 38 B. 40 C. 44 D. 46
试题解析此题不建议根据表格画出各节点的网络图,而建议采用试算 $^+$ 穷举法。试算 $\mathrm{A}\to \mathrm{F}$ 路径的下列路径:
$①\mathrm{A}\rightarrow \mathrm{B}\rightarrow \mathrm{F}$ : $11 + 29 = 40$ $②\mathrm{A}\rightarrow \mathrm{C}\rightarrow \mathrm{F}$ : $16 + 22 = 38$ $③\mathrm{A}\rightarrow \mathrm{D}\rightarrow \mathrm{F}$ : $24 + 17 = 41$ $④\mathrm{A}\rightarrow \mathrm{E}\rightarrow \mathrm{F}$ : $36 + 15 = 51$ 不难看出 $\mathrm{A}\to \mathrm{C}\to \mathrm{F}$ 是最短距离。
参考答案:(69)A
$\bullet$ 某项目的双代号网络图如下所示,该项目的工期为(70)。
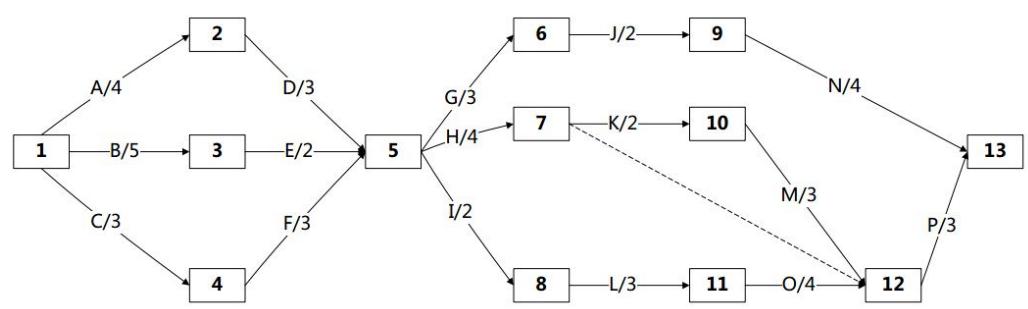
(70)A. 17 B. 18 C. 19 D. 20
试题解析双代号网络图亦称“箭线图法”。关键路径即持续时间最长的线路,网络图中至少有一条关键路径。项目的工期就是找图中的关键路径,本题中关键路径有多条,例如:ADHKMP、ADILOP、BEHKMP、BEILOP,它们的工期都是19,因此本项目的工期为19。
参考答案:(70)C
$\bullet$ The objective of (71)is to determine what parts of the application software will be assigned to what hardware. The major software components of the system being developed have to be identified and then allocated to the various hardware components on which the system will operate. All
software systems can be divided into four basic functions. The first is (72). Most information systems require data to be stored and retrieved, whether a small file, such as a memo produced by a word processor, or a large database, such as one that stores an organization’s accounting records. The second function is the (73),the processing required to access data, which often means database queries in Structured Query Language. The third function is the (74),which is the logic documented in the DFDs, use cases, and functional requirements. The fourth function is the presentation logic, the display of information to the user and the acceptance of the user’s commands. The three primary hardware components of a system are (75).
(71)A.architecture design B.modular design C.physical design D.distribution design (72)A.data access components B.database management system C.data storage D.data entities (73)A.data persistence B.data access objects C.database connection D.data access logic (74)A.system requirements B.system architecture C.application logic D.application program (75)A.computers,cables and network B.clients,servers,and network C.CPUs,memories and I/O devices D.CPUs,hard disks and I/O devices
试题解析架构设计的目标是确定应用软件的哪些部分将分配到何种硬件,识别出正在开发系统的主要软件构件并分配到系统将要运行的硬件构件。所有软件系统可分为4项基本功能,第1项是数据存储。大多数信息系统需要数据进行存储并检索,不论是一个小文件,如一个字处理器产生的一个备忘录,还是一个大型数据库,如存储一个企业会计记录的数据库;第2项功能是数据接口逻辑,处理过程需要访问数据,这通常是指用SQL进行数据库查询;第3项功能是应用逻辑,这些逻辑通过数据流图,用例和功能需求来记录;第4项功能是表示逻辑,为用户显示信息并接收用户命令。一个系统的3类主要硬件构件是客户机、服务器、网络。
参考答案:(71)A(72)C(73)D(74)C(75)B
第28小时 模拟试题I(下午案例分析)
试题一(25分)
请详细阅读有关数据架构方面的描述,回答问题。
【说明】某互联网公司拟开发用户通信软件系统,向用户提供即时通信服务。公司主要人员经过讨论之后,一致认为该项目的核心功能是:必须要做好识别消息内容,做好内容防护工作,要防止恶意用户利用该软件进行非法内容传输的工作。对于正常的消息,则采用消息封装、正常转发等处理,对于一般有害的辱骂、恐吓消息内容进行改写处理,对国家、社会有重大危害的消息内容做过滤处理,并对用户进行封号处理。在需求分析与架构设计阶段,公司提出的需求和质量属性描述如下:
(a)管理员能够在后台对用户进行封号和解封,设置后即可生效。
(b)系统应该具备完整的安全防护措施,支持对恶意攻击行为进行检测与报警。
(c)在正常负载情况下,系统应在0.3秒内对用户的发送消息请求进行响应。
(d)消息体以汉字、英文字母、数字以及普通的标点符号为主,不超过1024字节。
(e)在正常负载情况下,用户发送新消息后,对方应在1秒内收到该消息。
(f)系统主服务异常中断后,应在5秒内将用户请求重定向到备用服务。
(g)系统支持横向用户及消息的存储扩展,要求在2人·天内完成所有的扩展与测试工作。
(h)系统宕机后,需要在10秒内感知错误,并自动启动热备份系统服务。
(i)系统需要对内提供接口函数,支持开发团队进行信息收集、功能调试与系统诊断。
(j)系统需要为所有的用户发送的消息进行备份至少7天,便于后期查阅与审计。
(k)支持对聊天软件的外观进行调整和配置,调整工作需要在4人·天内完成。
在对系统需求、质量属性描述和架构特性进行分析的基础上,系统架构师给出了两种候选的架
构设计方案,公司目前正在组织相关专家对系统架构进行评估。
【问题1】(12分)
在架构评估过程中,质量属性效用树(Utility Tree)是对系统质量属性进行识别和优先级排序的重要工具。请将合适的质量属性名称填入图1.1中(1)、(2)空白处,并选择题干描述的(a)~(k)填入(3)~(6)空白处,完成该系统的效用树。
图1.1 通信软件系统效用树
参考答案:
(1)安全性 (2)可修改性 (3)(e) (4)(j) (5)(h) (6)(k)
【问题2】(13分)
针对该系统的有害信息过滤功能,李工建议采用黑板系统风格,将客户端发来的消息作为共享数据,内容信息识别、处理消息的各构件则视为知识源,分别对共享数据进行响应,以便决定是否改写、屏蔽、封号还是消息封装、正常转发。王工认为李工的方案存在问题,即负责消息封装、正常转发的构件需要等待其他有害消息处理构件处理之后,才能开始自己的工作,所以提出采用管道- 过滤器风格,将新消息作为数据流,依次通过有害消息处理构件、普通消息封装、转发构件,对消息进行变换或处理。经公司讨论之后,决定综合采用李工和王工的方案,来取长补短。
请针对王工和李工的方案,分析和对比黑板系统风格和管道- 过滤器风格的各自优缺点,并说明如何综合两种风格,来更好地实现软件功能。
参考答案:
(1)黑板风格。优点:可用于非确定性问题求解,启发式解决过程,可维护性,可重用。缺点:不能确保期望结果,效率低下,回退,不支持并行,共享空间的访问需要同步。(2)管道-过滤器风格。优点:简单性、支持复用、系统具有可扩展性、系统并发性(每个过
滤器可以独立运行,不同子任务可以并行执行,提高效率)。
缺点:不适合用来设计交互式应用系统。
在内容识别、有害信息处理的构件之间采用黑板风格;对于可转发的消息可以采用管道- 过滤器风格,交给后续的消息封装、正常转发的构件。
试题二(25分)
阅读以下关于系统架构设计的叙述,回答问题
【说明】某互联网公司欲建设一套面向互联网的商品交易平台,该平台可以方便用户和商户之间的咨询和交易。参考目前的电子商务模式,该平台的主要性能需求描述如下:
(1)平台会邀请大牌商户入驻,所以后期该平台要承担比较大的全国用户请求流量,以及较高的并发用户数,被认为是最重要的性能需求。
(2)重要节日会有商户进行秒杀促销活动,所以平台需要承担流量尖峰,且保证较低的访问延时。
(3)平台需要达到一定的可用性。
(4)由于平台涉及金融支付领域,所以对用户的订单及支付数据存储有较高的安全性、可靠性要求。
目前公司正在组织技术部进行方案调研,讨论该平台的实现方案。在技术讨论时,王工给出了方案:接入层采用工作在七层的Nginx来作为负载均衡器,并在应用层采用SOA来整合公司目前可复用的网络服务程序,集成在一起来处理该平台的业务功能,可以达到很高的复用并快速上线争取市场,存储层则采用传统的Oracle来承担数据存储。李工给出了不同的意见,认为应该采用工作在四层的LVS来作为接入层的负载均衡器,应用层应采用微服务来实现每个子功能,通过微服务之间的协作来完成整体功能,存储层则应采用MySQL开源组件,实行主从模式、分库分表来组成分布式数据库,并进行读写分离的设计,来更好地达到性能和可用性的提升。之后张工补充了方案,根据平台即将面对的全国流量,应该在全国设立4个机房,分别部署一套平台服务,来平摊用户流量。
【问题1】(10分)
请用200字以内的文字简述王工的SOA方案和李工的微服务方案的不同点,根据该项目应该选择哪个方案?
参考答案:
SOA方案与微服务方案的不同点如下所述:
(1)SOA的设计思路是把一些组件和服务,通过服务总线组装,形成更大的应用系统(从小到大);而微服务的设计思路是把应用拆分成独立自治的小的服务(从大到小)。
(2)SOA很大程度上依赖于基于XML的消息格式和基于SOAP的通信协议,微服务架构大量地依赖于REST和JSON。
(3)SOA架构中需要存在ESB总线,负责服务之间的通信转发和接口适配。在微服务架构中,强调更轻量级、更迅速、去中心化的技术。
(4)SOA 设计架构强调分层,通常会分为展现层、业务层、总线层和数据层。微服务架构中的服务更松散,更容易扩展。
(5)SOA 中的服务不强调业务领域的自治性,微服务架构强调基于领域的服务自治性。
由于该平台业务规模体量会比较大,而考虑到微服务的伸缩性、去中心化和自治性,采用李工的方案更容易提升性能,并能更好地适应研发团队的解耦。
【问题2】(10分)
【问题2】(10分)经深入讨论公司支持了李工的方案,请阐述针对存储层采用MySQL来进行分库分表、主从结构的设计的原因。
参考答案:
参考答案:采用MySQL开源组件本身是可以降低成本的。将两个MySQL设计成主从模式,可以提高平台要求的可用性,主节点有异常,从节点可及时代替主节点继续提供服务。以主从模式为基础,设计多套MySQL主从,实现分库分表,每一个节点都能平摊数据存储量,进一步提升总体性能和系统容量。
【问题3】(5分)
【问题3】(5分)公司也同时认可了张工补充的开设多个机房方案,但该方案需要依赖其他技术,请简述其中一种关键性技术,并说明其作用。
参考答案:
参考答案:DNS解析,根据用户的IP解析到该用户距离最近的机房,减少该用户访问平台的时延和拥挤程度。
试题三(25分)
请详细阅读有关嵌入式软件架构设计方面的描述,回答问题
【说明】服务型智能扫地机器人因其低廉的价格和高效的工作能力,越来越受到消费者的认可,目前已逐渐进入家庭生活代替人们的清洁工作,具有广阔的市场。
服务型智能扫地机器人需要具有自主运动规划和导航功能,在其工作过程中,需要通过对环境信息的融合感知进行行为决策。扫地机器人一般具备的主要功能包括:
(1)紧急状态感知:包括碰撞检测、跌落检测和离地检测等功能,防止与障碍物碰撞、前方台阶跌落危险以及扫地机器人离地等,实现扫地机器人运动中的自我保护。
(2)姿态感知:包括运动里程计数和航向测量等功能,需要获取扫地机器人的运动速度、行走距离、航向角度等信息。
(3)视觉感知:包括单目视觉避障系统和单目视觉定位系统等,需要通过视觉信息探测障碍物,视觉信息来自两个单目摄像头系统。在某些设计中。也可结合红外测距传感器进行障碍物探测。
(4)自动充电:在工作过程中,需要实时监控扫地机器人的电量,且在电量少于一定阀值时自动返回电源处进行充电。
(5)扫地及吸尘单元:使用电机控制刷子实现清扫,使用抽灰电机实现吸尘。
(6)运动执行:对机器人的运动进行控制。
(7)监控系统:通过无线网络传递扫地机器人的状态数据及视频图像等信息到远程客户端,客户端参与到扫地机器人的运动监视及控制中,实现信息交互,监控扫地机器人的实时状态。客户端包括PC客户端和手机客户端两种。
(8)信息处理中心:用于接收各种传感器信息和视觉信息,通过分析处理进行扫地机器人的运动控制,且负责和后台监控中心通信。
服务型智能扫地机器人选用ARM+STM32双核架构模式,分别处理数据量较大的图像信息和短促型的非图像信息。STM32选用STM32F103VET6芯片,用于实现非图像以外的众多传感器的驱动以及数据采集,并控制车轮电机的运动;ARM选用S5PV210处理器实现摄像头图片的采集、在监控系统中接入无线网络、对STM32串口传过来的传感器数据以及图像定位和避障信息做综合处理,生成运动决策,发送给STM32,执行扫地机的前进、后退、转弯等。
【问题1】(15分)
图3.1是本题的服务型智能扫地机器人典型的功能结构图,请根据说明的描述,完成该功能结构图,将(1)~(5)的内容填在答题纸上相应的位置中。
图3.1 功能结构图
参考答案:
(1)紧急状态感知 (2)跌落检测 (3)航向测量
(4)单目视觉避障系统 (5)扫地及吸尘单元
【问题2】(6分)
为了实现服务型智能扫地机器人的功能,就需要多种传感器来感知工作环境信息。王工在对传感器进行选型时,选择了如下类型的传感器:
(1)USB摄像头。(2)开关式传感器。
(3)槽型光耦模块。
(4)数字式防跌落传感器。
(5)GGPM01A单轴角度陀螺仪(传感器)。
(6)红外测距传感器。
(7)霍尔码盘传感器。
请根据传感器的功能完成表3.1,将(1)~(6)的内容填在答题纸上相应的位置中。
表3.1 传感器的类别功能及参数
| 序号 | 传感器类别 | 功能 | 参数 |
| 1 | (1) | 用于障碍物规避 | 输出模拟电压量 |
| 2 | (2) | 平台防跌落 | 输出数字量 |
| 3 | (3) | 车身离地检测 | 输出数字量 |
| 4 | (4) | 碰撞检测 | 输出数字量 |
| 5 | (5) | 检测航向角度 | 检测角度+180° |
| 6 | (6) | 测速和计里程 | 脉冲输出 |
| 7 | USB 摄像头 | 采集环境图像信息 | YUV 和 MJPG 格式 |
参考答案:
(1)红外测距传感器 (2)数字式防跌落传感器 (3)开关式传感器(4)槽型光耦模块 (5)GGPM01A单轴角度陀螺仪(6)霍尔码盘传感器
【问题3】(4分)
由于该服务型智能扫地机器人的硬件采用双处理器架构,即ARM+STM32双核架构模式,选用串口方式在处理器之间传递数据,如图3.2所示。假设在本串行传输中的数据格式为:
8位数据位、1位起始位、1位停止位,无校验位。
(1)当波特率为 $9600\mathrm{b / s}$ 时,每秒钟传送的有效数据是多少字节?
(2)为保证数据收发正确(每个字节数据传输中的累计误差不大于1/4bit),试分析发送方和接收方时钟允许的误差范围,并以百分比形式给出最大误差。请将答案填写在答题纸的对应栏中。

图3.2 ARM+STM32双核架构模式
参考答案:
(1) $9600\div (8 + 1 + 1) = 960$ 字节。
(2)根据题意,每个字节数据传输的累计误差最大为1/4bit,而每个字节数据含有 $8 + 1 + 1 =$
10 个 bit, 因此, 每个 bit 的最大误差为 $(1 / 4) \div 10 = 0.025$ , 所以最大误差为 $0.025 \times 100% = 2.5%$ .
试题四(25分)
阅读以下关于分布式技术的叙述,回答问题。
【说明】某软件企业开发了一套新闻社交类软件,提供常见的新闻发布、用户关注、用户推荐、新闻点评、新闻推荐、热点新闻等功能,项目采用MySQL数据库来存储业务数据。系统上线后,随着用户数量的增加,数据库服务器的压力不断加大。
为此,该企业设立了专门的工作组来解决此问题。张工提出对MySQL数据库进行扩展,采用读写分离,主从复制的策略,好处是程序改动比较小,可以较快完成,后续也可以扩展到MySQL集群,其方案如图4.1所示。李工认为该系统的诸多功能,并不需要采用关系数据库,甚至关系数据库限制了功能的实现,应该采用NoSQL数据库来替代MySQL,重新构造系统的数据层。而刘工认为张工的方案过于保守,对该系统的某些功能,如关注列表、推荐列表、热搜榜单等实现困难,且性能提升不大;而李工的方案又太激进,工作量太大,短期无法完成,应尽量综合二者的优点,采用Key- Value数据库+MySQL数据库的混合方案。
经过组内多次讨论,该企业最终决定采用刘工提出的方案。
图4.1 张工方案示意图
【问题1】(8分)
张工方案中采用了读写分离,主从复制策略。简述主从复制给系统带来的好处。
参考答案:
(1)避免数据库单点故障:主服务器实时、异步复制数据到从服务器,当主数据库宕机时,可在从数据库中选择一个升级为主服务器,从而防止数据库单点故障。
(2)提高查询效率:根据系统数据库访问特点,可以使用主数据库进行数据的插入、删除及更新等写操作,而从数据库则专门用来进行数据查询操作,从而将查询操作分担到不同的从服务器
以提高数据库访问效率。
【问题2】(8分)
MySQL数据库中,主从复制通过binarylog来实现主从服务器的数据同步。请简述主从复制的过程。
参考答案:当在从库上启动复制时,首先创建I/O线程连接主库,主库随后创建BinlogDump线程读取数据库事件并发送给I/O线程,I/O线程获取到事件数据后更新到从库的中继日志RelayLog中去,之后从库上的SQL线程读取中继日志RelayLog中更新的数据库事件并应用。
【问题3】(9分)
主从复制可以采用同步、异步、半同步复制。请简述每种复制技术的特点。
(1)同步复制:主数据库需要等待所有备数据库均操作成功才可以响应用户,影响用户体验。这种方式保证了系统的一致性,但牺牲了数据的可用性。
(2)异步复制:当用户请求更新数据时,主数据库处理完请求后可直接给用户响应,而不必等待备数据库完成同步,备数据库会异步进行数据的同步,用户的更新操作不会因为备数据库未完成数据同步而导致阻塞。这种方式保证了系统的可用性,但牺牲了数据的一致性。
(3)半同步复制:用户发出写请求后,主数据库会执行写操作,并给备数据库发送同步请求,但主数据库不用等待所有备数据库回复数据同步成功便可响应用户,也就是说主数据库可以等待一部分备数据库同步完成后响应用户写操作执行成功。
试题五(25分)
阅读以下关于Web架构设计的叙述,回答问题
【说明】某互联网金融集团依托微服务技术研发互联网金融交易信息系统,全面整合原分布于各省地方分公司的区域系统,实现统一的用户账户管理、转账汇款、理财投资、贷款管理、网上交易、网上支付、财务共享、财务统计分析等业务功能。
在讨论过程中,王工建议采用面向服务的体系结构(SOA),可以通过ESB充分整合各地现有业务,并可支持Web、智能手机等多种前端应用形式接入相同的后端服务;而张工提出采用分布式微服务体系结构,整合业务的同时,可以利用云服务提高体系结构的性能、可用性和可扩展性,又可以提高整体的可变性和可维护性,且有利于适应当下和未来技术的高速发展和快速变更。
经过综合分析和讨论,集团领导最终决定同时采纳两位架构师的建议,结合使用,制定基于分布式微服务的前后端分离体系结构。
【问题1】(8分)
请简要叙述微服务架构的含义和关键原则
参考答案:微服务是一种软件开发技术,是面向服务的体系结构(SOA)架构风格的一种变体。微服务将应用程序构造为一组松散耦合的服务,微服务中单个应用程序由许多松散耦合且可独立部署的较小组件或服务组成。
微服务风格的关键原则如下:
微服务风格的关键原则如下:(1) 每一个URI代表1种资源。(2) 客户端使用HTTP Verb表示操作方式的动词对服务端资源进行操作。(3) 通过操作资源的表现形式来操作资源。(4) 资源的表现形式是XML或者HTML。(5) 客户端与服务端之间的交互是无状态的,客户端每个请求必须包含理解请求所必需的所有信息。
【问题2】(8分)
根据该信息系统整合的实际需求,项目组完成了微服务风格的金融交易信息系统体系结构设计方案,该体系结构设计图如图5.1所示。
图5.1 金融交易信息系统体系结构图
请从 $(\mathbf{a})\sim (\mathbf{n})$ 中选择合适的内容填入图5.1的(1)~(8)中,补充完善体系结构设计图。
(a)页面缓存 (b)网关层 (c)数据层 (d)主数据库
(e)Web服务器 (f)反向代理服务器 (g)事务中心 (h)服务层
(i)数据访问组件 (j)CDN (k)展示层 (l)数据中心
(m)从数据库 (n)分布式数据缓存
参考答案:(1)(j) (2)(e) (3)(n) (4)(1) (5)(d)
(6) (m) (7) (h) (8) (c)
【问题3】(9分)
项目组在进行需求调研时,发现用户界面部分的变动可能会比较频繁,因此需要降低系统界面与业务逻辑之间的耦合度。MVVM模式是由MVC模式派生出的一种设计模式,请从组件耦合度、组件分工及对开发工程化支持等3个方面说明MVVM模式与MVC模式的主要区别。
参考答案:
MVVM模式与MVC模式的主要区别见表5.1。
表5.1MVVM模式与MVC模式的主要区别
| 项目 | 组件分工 | 组件耦合度 | 对开发工程化支持 |
| MVC | M:数据模型或仓库抽象 V:视图抽象 C:控制,处理控制逻辑 | 耦合度低 重用度高 | 通过模板引擎技术实现了代码工程的分离 |
| MVVM | M:数据模型或仓库抽象 V:视图抽象 VM:视图模型,双向绑定 事件传递,逻辑下沉 | 耦合度低 Binder双向绑定 提高可重用度 | 通过Ajax技术实现了静态工程与动态工程的分离 |
第29小时 模拟试题I(下午论文)
试题一 论软件系统架构评估
对于软件系统,尤其是大规模的复杂软件系统来说,软件的系统架构对于确保最终系统的质量具有十分重要的意义,不恰当的系统架构将给项目开发带来高昂的代价和难以避免的灾难。对一个系统架构进行评估,是为了:分析现有架构存在的潜在风险,检验设计中提出的质量需求,在系统被构建之前分析现有系统架构对于系统质量的影响,提出系统架构的改进方案。架构评估是软件开发过程中的重要环节。请围绕“论软件系统架构评估”论题,依次从以下三个方面进行论述。
(1)概要叙述你所参与的架构评估软件系统,以及在评估过程中所担任的主要工作。(2)分析软件系统架构评估中所普遍关注的质量属性有哪些?详细阐述每种质量属性的具体含义。(3)详细说明你所参与的软件系统架构评估中,采用了哪种评估方法,具体实施过程和效果如何。
解析:架构所关注的质量属性主要包括:性能、可用性、安全性、可修改性。
(1)性能。性能(Performance)是指系统的响应能力,即要经过多长时间才能对某个事件做出响应,或者在某段时间内系统所能处理的事件的个数。
(2)可用性。可用性(Availability)是系统能够正常运行的时间比例。经常用两次故障之间的时间长度或在出现故障时系统能够恢复正常的速度来表示。
(3)安全性。安全性(Security)是指系统在向合法用户提供服务的同时能够阻止非授权用户使用的企图或拒绝服务的能力。安全性又可划分为机密性、完整性、不可否认性及可控性等特性。
(4)可修改性。可修改性(Modifiability)是指能够快速地以较高的性能价格比对系统进行变更的能力。通常以某些具体的变更为基准,通过考察这些变更的代价衡量可修改性。
架构评估方法主要从SAAM与ATAM中选择。
(1)SAAM评估方法(Scenario-Based Architecture Analysis Method):目的是验证基本的体系结构假设和原则,评估体系结构固有的风险。SAAM指导对体系结构的检查,使其主要关注潜在的问题点,如需求冲突。SAAM不仅能够评估体系结构对于特定系统需求的使用能力,也能被用
来比较不同的体系结构。这种评估方法的评估参与者有风险承担者、记录人员、软件体系结构设计师。SAAM 分析评估体系结构的过程包括 6 个步骤,即形成场景、描述体系结构、场景的分类和优先级确定、间接场景的单个评估、场景相互作用的评估、总体评估。
(2)ATAM 评估方法(Architecture Tradeoff Analysis Method):即构架权衡分析方法的评估目的是依据系统质量属性和商业需求评估设计决策的结果。ATAM 希望揭示出构架满足特定质量目标的情况,使我们更清楚地认识到质量目标之间的联系,即如何权衡多个质量目标。
评估参与者有:
1)评估小组。该小组是所评估构架项目外部的小组,通常由 $3 \sim 5$ 人组成。ATAM 小组的每个成员都要扮演大量的特定角色。他们可能是开发组织内部的,也可能是外部的。
2)项目决策者,对开发项目具有发言权,并有权要求进行某些改变,他们包括项目管理人员,重要的客户代表,构架设计师等。
3)构架涉众。包括关键模块开发人员、测试人员、用户等。
现代的 ATAM 评估过程包括 9 个步骤,按其编号顺序分别是描述 ATAM 方法、描述商业动机、描述体系结构、确定体系结构方法、生成质量属性效用树、分析体系结构方法、讨论和分级场景、描述评估结果。
试题二 论软件架构的复用
软件复用是系统化的软件开发过程即开发一组基本的软件构件模块,以覆盖不同的需求/体系结构之间的相似性,提高系统开发的效率、质量和性能。软件架构复用可以减少开发工作、减少开发事件、降低开发成本、提高生产力、提高产品质量,有更好的互操作性。请围绕“论软件架构的复用”论题,依次从以下三个方面进行论述。
(1)概要叙述你参与分析和开发的软件系统,以及你在项目中所担任的主要工作。
(2)阐述软件架构复用的基本过程。
(3)详细说明你所参与的软件系统开发项目中,是如何进行软件复用工作的。
解析:软件架构复用的基本过程如下:
(1)构建/获取可复用的软件资产是复用前提。首先需要构造恰当的、可复用的资产,并且这些资产必须是可靠的、可被广泛使用的、易于理解和修改的。
(2)管理可复用资产。用构件库对可复用的构件进行存储与管理。构件库应提供的主要功能包括构件的存储、管理、检索以及库的浏览与维护等,以及支持使用者有效地、准确地发现所需的可复用构件。构件库中的构件来源有:
1)从现有构件中获得符合要求的构件,直接使用或作适应性修改,得到可复用的构件。
2)通过遗留工程(Legacy Engineering),将具有潜在复用价值的构件提取出来,得到可复用的构件。
3)从市场上购买现成的商业构件。
4)开发新的符合要求的构件。
构件分类与检索的方法有:关键字分类法、刻面分类法、超文本方法。
(3)使用可复用资产。通过获取需求,检索复用资产库,获取可复用资产,并定制这些可复用资产进行修改、扩展、配置等,最后将它们组装与集成,形成最终系统。
试题三 论分布式存储系统架构设计
分布式存储系统(Disributed Storage System)通常将数据分散存储在多台独立的设备上。传统的网络存储系统采用集中的存储服务器存放所有数据,存储服务器成为系统性能的瓶颈,也是可靠性和安全性的焦点,不能满足大规模存储应用的需要。分布式存储系统采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,它不但提高了系统的可靠性、可用性和存取效率,还易于扩展。请围绕“分布式存储系统架构设计”论题,依次从以下三个方面进行论述。
(1)概要叙述你参与分析和开发的分布式存储系统项目以及你所承担的主要工作。
(2)简要说明在分布式存储系统架构设计中所使用的分布式存储技术及其实现机制,详细叙述你在具体项目中选用了哪种分布式存储技术,说明其原因和实施效果。
(3)冗余是提高分布式存储系统可靠性的主要方法,通常在分布式存储系统设计中可采用哪些冗余技术来提升系统的可靠性?你在具体项目中选用了哪种冗余技术?说明其原因和实施效果。
解析:在分布式存储系统架构设计中所使用的分布式存储技术主要包括4类:
(1)集群存储技术。集群存储系统是指架构在一个可扩充服务器集群中的文件系统,用户不需要考虑文件是存储在集群中什么位置,仅仅需要使用统一的界面就可以访问文件资源。当负载增加时,只需在服务器集群中增加新的服务器就可以提高文件系统的性能。集群存储系统能够保留传统的文件存储系统的语义,增加了集群存储系统必须的机制,可以向用户提供高可靠性、高性能、可扩充的文件存储服务。
(2)分布式文件系统。分布式文件系统是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连。分布式文件系统的设计基于客户机/服务器模式。一个典型的网络可能包括多个供多用户访问的服务器。另外,对等特性允许一些系统扮演客户机和服务器的双重角色。分布式文件系统以透明方式链接文件服务器和共享文件夹,然后将其映射到单个层次结构,以便可以从一个位置对其进行访问,而实际上数据却分布在不同的位置。用户不必再转至网络上的多个位置以查找所需的信息。
(3)网络存储技术。网络存储系统就是将“存储”和“网络”结合起来,通过网络连接各存储设备,实现存储设备之间、存储设备和服务器之间的数据在网络上的高性能传输。为了充分利用资源,减少投资,存储作为构成计算机系统的主要架构之一,就不再仅仅担负附加设备的角色,逐步成为独立的系统。利用网络将此独立的系统和传统的用户设备连接,使其以高速、稳定的数据存储单元存在。用户可以方便地使用浏览器等客户端进行访问和管理。
(4)P2P网络存储技术。P2P网络存储技术的应用使得内容不是存在几个主要的服务器上,而是存在所有用户的个人电脑上。这就为网络存储提供了可能性,可以将网络中的剩余存储空间利用起来,实现网络存储。人们对存储容量的需求是无止境的,提高存储能力的方法有更换能力更强
的存储器,或把多个存储器用某种方式连接在一起,实现网络并行存储。相对于现有的网络存储系统而言,应用P2P技术将会有更大的优势。P2P技术的主体就是网络中的Peer,也就是各个客户机,数量是很大的,这些客户机的空闲存储空间是很多的,把这些空间利用起来实现网络存储。
冗余是提高分布式存储系统可靠性的主要方法,冗余的存储结构可以保证部分服务器失效时,数据服务仍可正常访问。常用的冗余技术包括:数据备份、数据分割、门限方案、纠错编码和纠删编码等。考生可根据所参与的实际项目,指出采用了何种冗余技术,并说明其原因和实施效果。
试题四 论微服务架构及其应用
近年来,随着互联网行业的迅猛发展,公司或组织业务的不断扩张,需求的快速变化以及用户量的不断增加,传统的单块(Monolithic)软件架构面临着越来越多的挑战,已逐渐无法适应互联网时代对软件的要求。在这一背景下,微服务架构模式(Microservice Architecture Pattern)逐渐流行,它强调将单一业务功能开发成微服务的形式,每个微服务运行在一个进程中;采用HTTP等通用协议和轻量级API实现微服务之间的协作与通信。这些微服务可以使用不同的开发语言以及不同的数据存储技术,能够通过自动化部署工具独立发布,并保持最低限制的集中式管理。请围绕“论微服务架构及其应用”论题,依次从以下三个方面进行论述。
(1)概要叙述你参与管理和开发的、采用微服务架构的软件开发项目及在其中所担任的主要工作。
(2)微服务架构有哪些优势与挑战?请列举并进行说明。
(3)结合你参与管理和开发的软件开发项目,描述该软件的架构,说明该架构是如何采用微服务架构模式的,并说明在采用微服务架构后,在软件开发过程中遇到的实际问题和解决方案。
解析:微服务有以下优势:
(1)通过分解巨大单体式应用为多个服务方法解决了复杂性问题。它把庞大的单一模块应用分解为一系列的服务,同时保持总体功能不变,但整体并发却得到极大提升。
(2)让每个服务能够独立开发,开发者能够自由选择可行的技术,提供API服务。
(3)微服务架构模式是每个微服务独立的部署。开发者不再需要协调其他服务部署对本服务的影响。这种改变可以加快部署速度。
(4)微服务使得每个服务独立扩展。开发者可以根据每个服务的规模来部署满足需求的规模。甚至可以使用更适合于服务资源需求的硬件。
微服务架构带来的挑战如下:
(1)并非所有的系统都能转成微服务。
(2)部署较以往架构更加复杂:系统由众多微服务搭建,每个微服务需要单独部署,从而增加部署的复杂度,容器技术能够解决这一问题。
(3)性能问题:由于微服务注重独立性,互相通信时只能通过标准接口,可能产生延迟或调用出错。
(4)数据一致性问题:作为分布式部署的微服务,在保持数据一致性方面需要比传统架构更加困难。
第30小时 模拟试题Ⅱ(上午基础知识)
数据库系统与文件系统的区别不包括(1)
(1)A. 对应用程序的高度独立性 B. 数据的充分共享性 C. 文件组织形式的多样化 D. 操作方便性
试题解析 数据库对数据的存储是按照同一种数据结构进行的,不同的应用程序都可以直接操作这些数据(即对应用程序的高度独立性)。数据库系统对数据的完整性、一致性和安全性都提供了一套有效的管理手段(数据的充分共享性)。数据库系统还提供管理和控制数据的各种简单操作命令,容易掌握,使用户编写程序简单(即操作方便性)。
参考答案:(1)C
(2)描述的是DBMS向用户提供数据操纵语言,实现对数据库中数据的基本操作,如检索、插入、修改和删除。
(2)A. 数据定义 B. 数据库操作 C. 数据库运行管理 D. 数据组织、存储与管理
试题解析 DBMS的功能主要包括数据定义、数据库操作、数据库运行管理、数据组织、存储和管理、数据库的建立和维护。其中数据库操作是DBMS向用户提供数据操纵语言,实现对数据库中数据的基本操作,如检索、插入、修改和删除。
参考答案:(2)B
●给定关系模式 $\mathrm{R(U,F)}$ ,其中:属性集 $\mathrm{U} = {\mathrm{A1,A2,A3,A4,A5,A6}}$ ;函数依赖集 $\mathrm{F} = {\mathrm{A1}\rightarrow \mathrm{A2}$ $\mathrm{A1}\rightarrow \mathrm{A3}$ , $\mathrm{A3}\rightarrow \mathrm{A4}$ , $\mathrm{A1A5}\rightarrow \mathrm{A6}}$ 。关系模式R的候选码为(3),由于R存在非主属性对码的部分函数依赖,所以R属于(4)。
(3)A.A1A3 B.A1A4 C.A1A5 D.A1A6 (4)A.1NF B.2NF C.3NF D.BCNF
试题解析 判断候选码有一种比较快速的方式,就是看哪个属性只在依赖集F中“ $\rightarrow$ ”的
左边出现过,那么该关系的候选码就必定包含那个属性。很显然选项C中A1和A5都是满足要求的,所以题干给定关系模式的候选码就是A1A5。对于(4),“R存在非主属性对码的部分函数依赖”说明不满足2NF的要求,那么该关系模式只能是1NF。
参考答案:(3)C (4)A
$\bullet$ 下列选项(5)不是关于SOA的服务架构。
(5)A.业务逻辑服务 B.中间件服务C.连接服务 D.控制服务
试题解析 SOA 的参考架构中包括业务逻辑服务(Business Logic Service)、控制服务(Control Service)、连接服务(Connectivity Service)、业务创新和优化服务(Business Innovation and Optimization Service)、开发服务(Development Service)、IT 服务管理(IT Service Management)。
参考答案:(5)B
$\bullet$ Web 服务描述语言(Web Services Description Language,WSDL),是一个用来描述Web服务和说明如何与Web服务通信的XML语言。描述了Web服务的三个基本属性,分别为(6)。a.服务做些什么 b.如何访问服务 c.服务位于何处 d.服务是否可用(6)A.abc B.acd C.bcd D.abd
试题解析 服务做些什么:服务所提供的操作(方法)。如何访问服务:和服务交互的数据格式以及必要协议。服务位于何处:协议相关的地址,如URL。
参考答案:(6)A
$\bullet$ SOA的设计原则为无状态、单一实例、明确定义的接口、(7)、粗粒度、服务之间的松耦合性、重用能力、互操作性。
(7)A.复用性和构件化 B.自包含和模块化C.独立性和构件化 D.隔离性和归一化
试题解析 SOA 的设计原则为无状态、单一实例、明确定义的接口、自包含和模块化、粗粒度、服务之间的松耦合性、重用能力、互操作性。
参考答案:(7)B
$\bullet$ 微服务架构将一个大型的单个应用或服务拆分成多个微服务,可扩展单个组件而不是整个应用程序堆栈,从而满足服务等级协议。微服务架构围绕业务领域将服务进行拆分,每个服务可以(8),彼此之间使用统一接口进行交流,实现了在分散组件中的部署、管理与服务功能,使产品交付变得更加简单,从而达到有效拆分应用,实现敏捷开发与部署的目的。
(8)A.独立进行开发、管理、迭代 B.独立进行部署、运维、升级C.独立进行测试、交付、验收 D.独立进行发布、发现、访问
试题解析 微服务架构围绕业务领域将服务进行拆分,每个服务可以独立进行开发、管理和迭代,彼此之间使用统一接口进行交流,实现了在分散组件中的部署、管理与服务功能。
参考答案:(8)A
$\bullet$ 在软件系统的生命周期里,软件的演化速率趋于稳定,如相邻版本的更新率相对稳定。此描
述是软件架构演化的(9)原则。
(9)A. 主体维持原则 B. 系统总体结构优化原则 C. 平滑演化原则 D. 目标一致原则
试题解析 主体维持原则:软件演化的平均增量的增长须保持平稳,保证软件系统主体行为稳定。系统总体结构优化原则:使演化后的软件系统整体结构(布局)更加合理。平滑演化原则:软件的演化速率趋于稳定。目标一致原则:架构演化的阶段目标和最终目标要一致。
参考答案:(9)C
$\bullet$ 软件架构维护过程不包括(10)
(10)A. 架构知识管理 B. 架构修改管理 C. 架构版本管理 D. 架构构件管理
试题解析 软件架构维护过程包括架构知识管理、架构修改管理、架构版本管理等。
参考答案:(10)D
$\bullet$ 下列软件架构演化时期,(11)是在系统设计时规定了演化的具体条件,将系统置于“安全”模式下,演化只发生在某些特定约束满足时,可以进行一些规定好的演化操作。
(11)A. 设计时演化 B. 运行前演化 C. 有限制运行时演化 D. 运行时演化
试题解析 设计时演化:发生在体系结构模型与之相关的代码编译之前;运行前演化:发生在执行之前、编译之后;有限制运行时演化;只发生在某些特定约束满足时;运行时演化;发生在运行时不能满足要求时。
答案:(11)C
$\bullet$ 根据所修改的内容不同,软件的动态演化不包括(12)
(12)A. 属性改名 B. 行为变化 C. 拓扑结构改变 D. 格式变化
试题解析 动态演化的内容:属性改名、行为变化、拓扑结构改变、风格变化。
参考答案:(12)D
$\bullet$ 采用检错设计技术要着重考虑4个要素:检测对象、(13)、实现方法和处理方式。
(13)A. 检测延时 B. 测试结果 C. 性能测试 D. 功能测试
试题解析 该题目是对软件可靠性管理的检错技术的考查。采用检错设计技术要着重考虑4个要素:检测对象、检测延时、实现方法和处理方式。
参考答案:(13)A
$\bullet$ (14)是通常所说的Active/Standby方式,Active服务器处于工作状态,Standby服务器处于监控准备状态,服务器数据包括数据库数据同时往两台或多台服务器写入,保证数据的即时同步。
(14)A. 双机热备 B. 双机互备 C. 双机双工 D. 服务器集群
试题解析 该题目是对软件可靠性管理的检错技术的考查。一台服务器处于工作状态,另一台处于后备状态,是双机热备模式。
参考答案:(14)A
$\bullet$ 识别风险、非风险、敏感点和权衡点是进行软件架构评估的重要过程。“改变业务数据编码方式会对系统的性能和安全性产生影响”是对(15)的描述,“假设用户请求的频率为每秒1个,业务处理时间小于30毫秒,则将请求响应时间设定为1秒钟是可以接受的”是对(16)的描述。
(15)A.风险 B.非风险 C.敏感点 D.权衡点(16)A.风险 B.非风险 C.敏感点 D.权衡点
试题解析风险是某个存在问题的架构设计决策,可能会导致问题;非风险与风险相对,是良好的架构设计决策;敏感点是一个或多个构件的特性;权衡点是影响多个质量属性的特性,是多个质量属性的敏感点。根据上述定义,可以看出“改变业务数据编码方式会对系统的性能和安全性产生影响”是对权衡点的描述,“假设用户请求的频率为每秒1个,业务处理时间小于30毫秒,则将请求响应时间设定为1秒钟是可以接受的”是对非风险的描述。
参考答案:(15)D (16)B
$\bullet$ 特定领域软件架构(Domain Specific Software Architecture,DSSA)是在一个特定应用领域中,为一组应用提供组织结构参考的标准软件体系结构。DSSA通常是一个具有三个层次的系统模型,包括(17)环境、领域特定应用开发环境和应用执行环境,其中(18)主要在领域特定应用开发环境中工作。
(17)A.领域需求 B.领域开发 C.领域执行 D.领域应用
(18)A.操作员 B.领域架构师 C.应用工程师 D.程序员
试题解析本题主要考查特定领域软件架构的基础知识。特定领域软件架构是在一个特定应用领域中,为一组应用提供组织结构参考的标准软件体系结构。DSSA通常是一个具有3个层次的系统模型,包括领域开发环境、领域特定应用开发环境和应用执行环境,其中应用工程师主要在领域特定应用开发环境中工作。
答案:(17)B (18)C
$\bullet$ 某公司拟开发一个VIP管理系统,系统需要根据不同的商场活动,不定期更新VIP会员的审核标准和VIP折扣标准。针对上述需求,采用(19)架构风格最为合适。
(19)A.规则系统 B.过程控制 C.分层 D.管道-过滤器
试题解析根据题目中的描述,VIP管理系统会根据不同的商场活动,不定期更新VIP会员的审核标准和折扣标准,属于典型的规则系统应用场景。
参考答案:(19)A
$\bullet$ 以下叙述中,(20)不是软件架构的主要作用。
(20)A.在设计变更相对容易的阶段,考虑系统结构的可选方案B.便于技术人员与非技术人员就软件设计进行交互C.展现软件的结构、属性与内部交互关系
D. 表达系统是否满足用户的功能性需求
试题解析 本题主要考查软件架构基础知识。软件架构能够在设计变更相对容易的阶段,考虑系统结构的可选方案;便于技术人员与非技术人员就软件设计进行交互,能够展现软件的结构、属性与内部交互关系。但是软件架构与用户对系统的功能性需求没有直接的对应关系。
参考答案:(20)D
$\bullet$ 软件架构风格描述某一特定领域中的系统组织方式和惯用模式,反映了领域中众多系统所共有的(21)特征。对于语音识别、知识推理等问题复杂、解空间很大、求解过程不确定的这一类软件系统,通常会采用(22)架构风格。对于因数据输入某个构件,经过内部处理,产生数据输出的系统,通常会采用(23)架构风格。
(21)A.语法和语义 B.结构和语义 C.静态和动态 D.行为和约束
(22)A.管道-过滤器 B.解释器 C.黑板 D.过程控制
(23)A.事件驱动系统 B.黑板 C.管道-过滤器 D.分层系统
试题解析 体系结构风格反映了领域中众多系统所共有的结构和语义特性,并指导如何将各个模块和子系统有效地组织成一个完整的系统。对软件体系结构风格的研究和实践促进对设计的重用,一些经过实践证实的解决方案也可以可靠地用于解决新的问题。例如,如果某人把系统描述为客户/服务器模式,则不必给出设计细节,我们立刻就会明白系统是如何组织和工作的。
语音识别是黑板风格的经典应用场景
输入某个构件,经过内部处理,产生数据输出的系统,正是管道- 过滤器中过滤器的职能,把多个过滤器使用管道相联的风格为管道- 过滤器风格。
参考答案:(21)B (22)C (23)C
$\bullet$ 事务必须服从ISO/IEC所制定的ACID原则。关于ACID以下说法有错误的是(24)。
(24)A.事务的原子性表示事务执行过程中的任何失败都将导致事务所做的任何修改失效 B.一致性表示当事务执行失败时,所有被该事务影响的数据都应该恢复到事务执行前的状态 C.隔离性表示在事务执行过程中对数据的修改,在事务提交之后对其他事务不可见 D.持久性表示已提交的数据在事务执行失败时,数据的状态都应该正确
试题解析 隔离性表示在事务执行过程中对数据的修改,在事务提交之“前”对其他事务不可见。
参考答案:(24)C
$\bullet$ 物联网的感知层用于识别物体、采集信息。下列(25)不属于感知层设备。
(25)A.摄像头 B.GPS C.扫描仪 D.指纹
试题解析 感知层的主要功能是识别对象、采集信息,与人体结构中皮肤和五官的作用类似。但指纹是人的特征属性,不是感知层设备。
参考答案:(25)D
软件著作权的保护对象不包括(26)
(26)A.源程序 B.目标程序 C.软件文档 D.软件开发思想
试题解析 软件著作权的保护对象是指受著作权法保护的计算机软件,包括计算机程序及其相关文档。计算机程序通常包括源程序和目标程序。同一程序的源程序文本和目标程序文本视为同一程序,无论是用源程序形式还是目标程序形式体现,都可能得到著作权法保护。软件文档是指用自然语言或者形式化语言所编写的文字资料和图表,以用来描述程序的内容、组成、设计、功能、开发情况、测试结果及使用方法等。我国《计算机软件保护条例》第六条规定:“本条例对软件著作权的保护不延及开发软件所用的思想、处理过程、操作方法或者数学概念等。”思想和思想表现形式(表现形式、表现)分别属于主客观两个范畴。思想属于主观范畴,是无形的,本身不受法律的保护。软件开发者的开发活动可以明确地分为两个部分:一部分是存在开发者大脑中的思想,即在软件开发过程中对软件功能、结构等的构思;另一部分是开发者的思想表现形式,即软件完成的最终形态(程序和相关文档)。著作权法只保护作品的表达,不保护作品的思想、原理、概念、方法、公式、算法等,因此对计算机软件来说,只有程序和软件文档得到著作权法的保护,而程序设计构思、程序设计技巧等不能得到著作权法的保护。
参考答案:(26)D
$\bullet$ 以下关于软件著作权产生时间的叙述中,正确的是(27)
(27)A.软件著作权产生自软件首次公开发表时B.软件著作权产生自开发者有开发意图时C.软件著作权产生自软件开发完成之日起D.软件著作权产生自软件著作权登记时
试题解析根据《计算机软件保护条例》第十四条规定,软件著作权自软件开发完成之日起产生。
参考答案:(27)C
$\bullet$ 无服务器技术的特点之一是全托管的计算服务:客户只需要编写代码构建应用,无须关注同质化的、负担繁重的基于服务器等基础设施的(28)等工作。
(28)A.开发、测试、发布、交付B.开发、运维、安全、高可用C.机房建设、服务器装机、操作系统安装、软件安装D.资源调度、性能压测、负载均衡、数据统计
试题解析无服务器技术的特点如下:全托管的计算服务——客户只需要编写代码构建应用,无须关注同质化的、负担繁重的基于服务器等基础设施的开发、运维、安全、高可用等工作;通用性——结合云BaaSAPI的能力,能够支撑云上所有重要类型的应用;自动弹性伸缩——让用户无须为资源使用提前进行容量规划;按量计费——让企业使用成本有效降低,无须为闲置资源付费。
参考答案:(28)B
$\bullet$ 容器作为标准化软件单元,它将应用及其所有依赖项打包,使应用不再受(29)限制,在不同计算环境间快速、可靠地运行。
(29)A.环境 B.操作系统 C.硬件 D.网络
试题解析在容器的帮助下,应用程序无须关注操作系统及更加低层的硬件、网络、存储的限制,因此选项B、C、D的说法有局限性,选项A更贴切。
参考答案:(29)A
$\bullet$ 假设员工关系EMP(员工号,姓名,性别,部门,部门电话,部门负责人,家庭住址,家庭成员,成员关系)如下表所示。如果一个部门只能有一部电话和一位负责人,一个员工可以有多个家庭成员,那么关系EMP属于(30),且(31)问题;为了解决这一问题,应该将员工关系EMP分解为(32)。
| 员工号 | 姓名 | 性别 | 部门 | 部门电话 | 部门负责人 | 家庭住址 | 家庭成员 | 成员关系 |
| 0011 | 张晓明 | 男 | 开发部 | 808356 | 0012 | 北京海淀区1号 | 张大军 | 父亲 |
| 0011 | 张晓明 | 男 | 开发部 | 808356 | 0012 | 北京海淀区1号 | 胡敏铮 | 母亲 |
| 0011 | 张晓明 | 男 | 开发部 | 808356 | 0012 | 北京海淀区1号 | 张晓丽 | 妹妹 |
| 0012 | 吴俊 | 男 | 开发部 | 808356 | 0012 | 上海昆明路15号 | 吴胜利 | 父亲 |
| 0012 | 吴俊 | 男 | 开发部 | 808356 | 0012 | 上海昆明路15号 | 王若垚 | 母亲 |
| 0021 | 李立丽 | 女 | 市场部 | 808358 | 0021 | 西安雁塔路8号 | 李国庆 | 父亲 |
| 0021 | 李立丽 | 女 | 市场部 | 808358 | 0021 | 西安雁塔路8号 | 罗明 | 母亲 |
| 0022 | 王学强 | 男 | 市场部 | 808358 | 0021 | 西安太白路2号 | 王国钧 | 父亲 |
| 0031 | 吴俊 | 女 | 财务部 | 808360 | 0031 | 西安科技路18号 | 吴鸿翔 | 父亲 |
(30)A.1NF B.2NF C.3NF D.BCNF
(31)A.无冗余、无插入异常和删除异常B.无冗余,但存在插入异常和删除异常C.存在冗余,但不存在修改操作的不一致D.存在冗余、修改操作的不一致,以及插入异常和删除异常
(32)A.EMP1(员工号,姓名,性别,家庭住址)EMP2(部门,部门电话,部门负责人)EMP3(员工号,家庭成员,成员关系)B.EMP1(员工号,姓名,性别,部门,家庭住址)EMP2(部门,部门电话,部门负责人)EMP3(员工号,家庭成员,成员关系)C.EMP1(员工号,姓名,性别,家庭住址)EMP2(部门,部门电话,部门负责人,家庭成员,成员关系)
D. EMP1(员工号,姓名,性别,部门,部门电话,部门负责人,家庭住址)EMP2(员工号,家庭住址,家庭成员,成员关系)
试题解析 (30)空主键是(员工号、家庭成员),部门名等非主属性对其存在部分依赖,不符合2NF。
(31)空存在冗余、修改操作的不一致,以及插入异常和删除异常。
(32)空因为对一个给定的关系模式进行分解,使得分解后的模式是否与原来的模式等价有如下3种情况: $①$ 分解具有无损连接性; $(2)$ 分解要保持函数依赖; $(3)$ 分解既要无损连接性,又要保持函数依赖。
选项A是错误的,因为将原关系模式分解成EMP1(员工号,姓名,家庭住址)、EMP2(部门,部门电话,部门负责人)和EMP3(员工号,家庭成员,成员关系)3个关系模式,分解后的关系模式既具有有损连接,又不能保持函数依赖。因为此时给定员工号已无法查找所在的部门。
选项B是正确的,因为将原关系模式分解成EMP1(员工号,姓名,部门,家庭住址)、EMP2(部门,部门电话,部门负责人)和EMP3(员工号,家庭成员,成员关系)既具有无损连接性,又保持了函数依赖。
选项C是错误的,因为将原关系模式分解成EMP1(员工号,姓名,家庭住址)和EMP2(部门,部门电话,部门负责人,家庭成员,成员关系)两个关系模式,分解后的关系模式既具有有损连接,又不能保持函数依赖。例如,给定员工号无法查找所在的部门,无法查找其家庭成员等信息。
选项D是错误的,因为将原关系模式分解成EMP1(员工号,姓名,部门,部门电话,部门负责人,家庭住址)和EMP2(员工号,家庭住址,家庭成员,成员关系)两个关系模式后,所得的关系模式存在冗余和修改操作的不一致性。例如,EMP1中某员工的家庭住址从“西安太白路2号”修改为“西安雁塔路18号”,而EMP2中该员工的家庭住址未修改,导致修改操作的不一致性。又如,EMP2中某员工的家庭成员有5个,那么其家庭住址就要重复出现5次,导致数据的冗余。
参考答案:(30)A (31)D (32)B
$\bullet$ 螺旋模型在(33)的基础上扩展而成。
(33)A.瀑布模型 B.原型模型 C.快速模型 D.面向对象模型
试题解析 螺旋模型是在原型模型的基础上扩展而成的。
参考答案:(33)B
$\bullet$ 关于微服务的描述,错误的是(34)
(34)A.微服务是将后端单体应用拆分为松耦合的多个子应用,每个子应用负责一组子功能B.微服务相对独立,通过解耦研发、测试与部署流程,提高整体迭代效率C.微服务与数据层之间的纵向约束的含义是:在合理划分好微服务间的边界后,主要从微服务的可发现性和可交互性处理服务间的关系D.驾驭微服务的前提是:高效运维整个系统,从技术上要准备全自动化的CI/CD流水线满足对开发效率的诉求,并在这个基础上支持蓝绿、金丝雀等不同发布策略
试题解析 选项 C“在合理划分好微服务间的边界后,主要从微服务的可发现性和可交互性处理服务间的关系”属于微服务之间的横向关系。正确的纵向约束是:对于微服务的私有数据的访问都必须通过当前微服务提供的 API 来进行。
参考答案:(34)C
$\bullet$ 下列关于云原生架构原则的选项,有错误的是(35)。(35)A.服务化原则、弹性原则、韧性原则B.可观测原则、所有过程自动化原则C.零信任原则、接口隔离原则 D.架构持续演进原则
试题解析接口隔离原则是面向对象设计原则,其含义是使用多个专门的接口比使用单一的总接口好。它不是云原生架构原则。
参考答案:(35)C
$\bullet$ 云的时代需要新的技术架构,来帮助企业应用能够更好地利用云计算优势,充分释放云计算的技术红利。云计算无法为企业带来的改进是(36)。
(36)A.通过DevSecOps应用开发模式,业务功能开发更加敏捷,提升迭代速度,成本更低B.企业软件架构可以获得强大的可伸缩性和高可用性C.结合云平台全方位企业级安全服务和安全合规能力,保障企业应用在云上安全构建,业务安全运行D.企业的开发人员只需关注业务代码部分的开发,非业务功能可以完全委托给云原生架构来解决
试题解析云原生架构旨在将云应用中的非业务代码部分进行最大化地剥离,从而让云设施接管应用中原有的大量非功能特性(如弹性、韧性、安全、可观测性、灰度等),但无法接管所有的非功能特性。
参考答案:(36)D
$\bullet$ 在软件需求工程中,需求管理贯穿整个过程。需求管理最基本的任务是明确需求,并使项目团队和用户达成共识,即建立(37)。
(37)A.需求跟踪说明 B.需求变更管理文档C.需求分析计划 D.需求基线
试题解析需求是软件项目成功的核心所在,它为其他许多技术和管理活动奠定了基础。在软件需求工程中,需求管理贯穿整个过程。需求管理最基本的任务是明确需求,并使项目团队和用户达成共识,即建立需求基线。
参考答案:(37)D
$\bullet$ 某服务器软件系统能够正确运行并得出计算结果,但存在“系统出错后不能在要求的时间内恢复到正常状态”和“对系统进行二次开发时总要超过半年的时间”两个问题,上述问题依次与质量属性中的(38)相关。
(38)A.可用性和性能 B.性能和可修改性C.性能和可测试性 D.可用性和可修改性
试题解析“系统出错后不能在要求的时间内恢复到正常状态”,这是对系统错误恢复能力的描述,属于系统可用性的范畴。“对系统进行二次开发时总要超过半年的时间”,这是对系统进行调整和维护方面能力的描述,属于系统可修改性的范畴。
参考答案:(38)D
$\bullet$ 在Cache一主存层次结构中,主存单元到Cache单元的地址转换由(39)完成。
(39)A.硬件 B.寻址方式C.软件和少量的辅助硬件 D.微程序
试题解析在由Cache一主存构成的层次式存储系统中,为了提高地址转换速度,主存单元到Cache单元的地址转换采用硬件完成。
参考答案:(39)A
$\bullet$ 如果要清除上网痕迹,必须(40)
(40)A.禁用ActiveX控件 B.查杀病毒C.清除Cookie D.禁用脚本
试题解析ActiveX是微软对于一系列策略性面向对象程序技术和工具的统称,其中主要的技术是组件对象模型。ActiveX是微软为抗衡Sun Microsystems的Java技术而提出的,其功能和JavaApplet功能类似。ActiveX控件的使用并不保留上网痕迹。
参考答案:(40)C
$\bullet$ 下列关于交换机的说法中,正确的是(41)
(41)A.以太网交换机可以连接运行不同网络层协议的网络B.从工作原理上讲,以太网交换机是一种多端口网桥C.集线器是一种特殊的交换机D.通过交换机连接的一组工作站形成一个冲突域
试题解析三层交换机(具有路由功能的交换机)可以连接不同网络层的网络。而以太网交换机属于二层交换机,因此A错误。集线器只有信号放大功能。实质上相当于一个中继器,没有数据交换功能,因此C错误。只有通过二层交换机连接的一组工作站才形成一个冲突域,因此D错误。
参考答案:(41)B
$\bullet$ 以下关于复杂指令集计算机(ComplexInstructionSetComputer,CISC)和精简指令集计算机(ReducedInstructionSetComputer,RISC)的叙述中,错误的是(42)。(42)A.在CISC中,复杂指令都采用硬布线逻辑来执行B.一般而言,采用CISC技术的CPU,其芯片设计复杂度更高C.在RISC中,更适合采用硬布线逻辑执行指令D.采用RISC技术,指令系统中的指令种类和寻址方式更少
试题解析复杂指令集计算机(ComplexInstructionSetComputer,CISC)的基本思想是进一步增强原有指令的功能,用更为复杂的新指令取代原先由软件子程序完成的功能,实现软件功能的硬件化,导致机器的指令系统越来越庞大而复杂。CISC计算机一般所含的指令数目至少300条
以上,有的甚至超过500条。
CISC的主要缺点如下: $①$ 微程序技术是CISC的重要支柱,每条复杂指令都要通过执行一段解释性微程序才能完成,这就需要多个CPU周期,从而降低了机器的处理速度; $(2)$ 指令系统过分庞大,从而使高级语言编译程序选择目标指令的范围很大,并使编译程序本身长而复杂,从而难以优化编译使之生成真正高效的目标代码; $(3)$ CISC强调完善的中断控制,势必导致动作繁多,设计复杂,研制周期长; $(\widehat{\Delta})$ CISC给芯片设计带来很多困难,使芯片种类增多,出错几率增大,成本提高而成品率降低。
精简指令集计算机(ReducedInstructionSetComputer,RISC)的基本思想是通过减少指令总数和简化指令功能,降低硬件设计的复杂度,使指令能单周期执行,并通过优化编译,提高指令的执行速度,采用硬线控制逻辑,优化编译程序。
实现RISC的关键技术有: $(1)$ 重叠寄存器窗口(OverlappingRegisterWindows)技术,首先应用在伯克利的RISC项目中; $(2)$ 优化编译技术,RISC使用了大量的寄存器,合理分配寄存器、提高寄存器的使用效率,减少访存次数等,都应通过编译技术的优化来实现; $(3)$ 超流水及超标量技术是RISC为了进一步提高流水线速度而采用的新技术; $(4)$ 硬线逻辑与微程序相结合在微程序技术中。
参考答案:(42)A
$\bullet$ 基于SOA和WebServices技术的企业应用集成(EAI)模式是(43)。
(43)A.面向信息的集成技术 B.面向过程的集成技术C.面向计划的集成技术 D.面向服务的集成技术
试题解析面向信息的集成技术采用的主要数据处理技术有数据复制、数据聚合和接口集成等。其中,接口集成仍然是一种主流技术。它通过一种集成代理的方式实现集成,即为应用系统创建适配器作为自己的代理,适配器通过其开放或私有接口将信息从应用系统中提取出来,并通过开放接口与外界系统实现信息交互,而假如适配器的结构支持一定的标准,则将极大地简化集成的复杂度,并有助于标准化,这也是面向接口集成方法的主要优势来源。标准化的适配器技术可以使企业从第三方供应商获取适配器,从而使集成技术简单化。
面向过程的集成技术其实是一种过程流集成的思想,它不需要处理用户界面开发、数据库逻辑、事务逻辑等,而只是处理系统之间的过程逻辑和核心业务逻辑相分离。在结构上,面向过程的集成方法在面向接口的集成方案之上,定义了另外的过程逻辑层;而在该结构的底层,应用服务器、消息中间件提供了支持数据传输和跨过程协调的基础服务。对于提供集成代理、消息中间件及应用服务器的厂商来说,提供用于业务过程集成是对其产品的重要拓展,也是目前应用集成市场的重要需求。
$\bullet$ 基于SOA(面向服务的架构)和WebServices技术的面向服务的集成技术是业务集成技术上的一次重要的变化,被认为是新一代的应用集成技术。集成的对象是一个个的Web服务或者是封装成Web服务的业务处理。WebServices技术由于是基于最广为接受的、开放的技术标准(如HTTP、XML等),支持服务接口描述和服务处理的分离、服务描述的集中化存储和发布、服务的自动查找和动态绑定及服务的组合,成为新一代面向服务的应用系统的构建和应用系统集成的基础设施。
参考答案:(43)D
$\bullet$ (44)是互联网时代信息基础设施与应用服务模式的重要形态,是新一代信息技术集约化发展的必然趋势。它以资源聚合和虚拟化、应用服务和专业化、按需供给和灵便使用的服务模式,提供高效能、低成本、低功耗的计算与数据服务,支撑各类信息化的应用。
(44)A.物联网 B.云计算 C.智慧城市 D.商业智能
试题解析云计算是互联网时代信息基础设施与应用服务模式的重要形态,是新一代信息技术集约化发展的必然趋势。它以资源聚合和虚拟化、应用服务和专业化、按需供给和灵便使用的服务模式,提供高效能、低成本、低功耗的计算与数据服务,支撑各类信息化的应用。
$\bullet$ 云计算具有重要特征:资源、平台和应用专业服务,使用户摆脱对具体设备的依赖,专注于创造和体验业务价值;资源聚集与集中管理,实现规模效应与可控质量保障;按需扩展与弹性租赁,降低信息化成本等特征。
参考答案:(44)B
$\bullet$ 用户界面设计的“黄金规则”不包含(45)
(45)A.为用户提供更多的信息和功能 B.减少用户的记忆负担 C.保持界面一致性 D.置用户于控制之下
试题解析TheoMandel在关于界面设计的著作中,提出了3条“黄金规则”: $①$ 置用户于控制之下; $(2)$ 减少用户的记忆负担; $(3)$ 保持界面一致性。这些“黄金规则”实际上形成了用于指导人机界面设计活动的一组设计原则的基础。
参考答案:(45)A
$\bullet$ 软件架构需求是指用户对目标软件系统在功能、行为、性能和设计约束等方面的期望。以下活动中,不属于软件架构需求过程中标识构件范畴的是(46)。
(46)A.生成类图 B.对类图进行分组 C.对类图进行测试 D.将类合并打包
试题解析软件架构需求过程主要是获取用户需求,标识系统中所要用到的构件,并进行架构需求评审。其中,标识构件又详细地分为生成类图、对类图进行分组和将类合并打包成构件3个步骤。
参考答案:(46)C
$\bullet$ 下列协议中,属于安全远程登录协议的是(47)
(47)A.TLS B.TCP C.SSH D.TFTP
试题解析TLS用于在两个通信应用程序之间提供保密性和数据完整性。TCP是传输层的通信协议,TFTP是文件传输协议,只有SSH是安全远程登录协议。
参考答案:(47)C
$\bullet$ 通常可以将计算机系统中执行一条指令的过程分为取指令,分析和执行指令3步。若取指令时间为 $4\Delta t$ ,分析时间为 $2\Delta t$ 。执行时间为 $3\Delta t$ ,按顺序方式从头到尾执行完600条指令所需时间为(48) $\Delta t$ ;若按照执行第 $i$ 条,分析第 $i + 1$ 条,读取第 $i + 2$ 条重叠的流水线方式执行
指令,则从头到尾执行完600条指令所需时间为(49) $\Delta t$ 。
(48)A.2400 B.3000 C.3600 D.5400 (49)A.2400 B.2405 C.3000 D.3009
试题解析按顺序方式需要执行完一条指令之后再执行下一条指令,执行1条指令所需的时间为 $4\Delta t + 2\Delta t + 3\Delta t = 9\Delta t$ ,执行600条指令所需的时间为 $9\Delta t\times 600 = 5400\Delta t$
若采用流水线方式,执行完600条指令所需要的时间为 $4\Delta t\times 600 + 2\Delta t + 3\Delta t = 2405\Delta t$
参考答案:(48)D (49)B
$\bullet$ 软件开发团队欲开发一套管理信息系统,在项目初期,用户提出了软件的一些基本功能,但是没有详细定义输入、处理和输出需求。在这种情况下,该团队在开发过程应采用(50)。
(50)A.瀑布模型 B.增量模型 C.原型开发模型 D.快速应用程序开发(RAD)
试题解析在软件开发过程中,如果用户仅仅提出软件的一些基本功能,但是没有详细定义输入、处理和输出需求,则该软件开发团队采取原型开发方法最为合适。因此本题应该选C。
参考答案:(50)C
$\bullet$ 在客户关系管理(Customer Relationship Management,CRM)中,管理的对象是客户与企业之间的双向关系,那么在开发过程中,(51)是开发的主要目标。
(51)A.客户关系的生命周期管理 B.客户有关系的培育和维护 C.最大程度地帮助企业实现其经营目标 D.为客户扮演积极的角色,树立企业形象
试题解析CRM是一种以客户为中心的商业策略,注重的是与客户的交流,企业的经营是以客户为中心,而不是传统的以产品或以市场为中心。在注重提高客户的满意度的同时,一定要把帮助企业提高获取利润的能力作为重要指标。CRM的实施要求企业对其业务功能进行重新设计,并对工作流程进行重组,将业务的中心转移到客户,同时要针对不同的客户群体有重点地采取不同的策略。
参考答案:(51)C
$\bullet$ 某服务器软件系统能够正确运行并得出计算结果,但存在“系统出错后不能在要求的时间内恢复到正常状态”和“对系统进行二次开发时总要超过半年的时间”两个问题,上述问题依次与质量属性中的(52)相关。
(52)A.可用性和性能 B.性能和可修改性 C.性能和可测试性 D.可用性和可修改性
试题解析“系统出错后不能在要求的时间内恢复到正常状态”,这是对系统错误恢复能力的描述,属于系统可用性的范畴。“对系统进行二次开发时总要超过半年的时间”,这是对系统进行调整和维护方面能力的描述,属于系统可修改性的范畴。
参考答案:(52)D
$\bullet$ 管道- 过滤器模式属于(53)
(53)A.数据为中心的体系结构 B.数据流体系结构C.调用和返回体系结构 D.层次式体系结构
试题解析 体系结构风格有:
1)数据流系统:包括顺序批处理、管道和过滤器。2)调用和返回系统:包括主程序和子程序、面向对象系统、层次结构。3)独立部件:包括通信进程、事件隐式调用。4)虚拟机:包括解释器、基于规则的系统。5)以数据为中心的系统:包括数据库、超文本系统、黑板系统。
参考答案:(53)B
$\bullet$ CPU中的数据总线宽度会影响(54)
(54)A.内存容量的大小 B.系统的运算速度C.指令系统的指令数量 D.寄存器的宽度
试题解析CPU与其他部件交换数据时,用数据总线传输数据。数据总线宽度指同时传送的二进制位数,内存容量、指令系统中的指令数量和寄存器的位数与数据总线的宽度无关。数据总线宽度越大,单位时间内能进出CPU的数据就越多,系统的运算速度越快。
参考答案:(54)B
$\bullet$ (55)是一种信息分析工具,能自动地找出数据仓库中的模式及关系。
(55)A.数据集市 B.数据挖掘 C.预测分析 D.数据统计
试题解析自动地找出数据仓库中的模式及关系是数据挖掘的基本概念。
参考答案:(55)B
$\bullet$ 某公司欲开发一套窗体图形界面类库。该类库需要包含若干预定义的窗格(Pane)对象,例如TextPane、ListPane等,窗格之间不允许直接引用。基于该类库的应用由一个包含一组窗格的窗口组成,并需要协调窗格之间的行为。基于该类库,在不引用窗格的前提下实现窗格之间的协作,应用开发者应采用(56)最为合适。
(56)A.备忘录模式B.中介者模式 C.访问者模式 D.迭代器模式
试题解析根据题干描述,应用系统需要使用某公司开发的类库,该应用系统由一组窗格组成,应用需要协调窗格之间的行为,并且不能引用窗格自身,在这种要求下,对比4个候选项,其中中介者模式用一个中介对象封装一系列的对象交互。中介者使用的各对象不需要显式地相互调用,从而使其耦合松散。可以看出该模式最符合需求。
参考答案:(56)B
$\bullet$ 网络故障需按照协议层次进行分层诊断,找出故障原因并进行相应处理。查看端口状态、协议建立状态和EIA状态属于(57)诊断。
(57)A.物理层 B.数据链路层 C.网络层 D.应用层
试题解析网络故障需按照协议层次进行分层诊断,找出故障原因并进行相应处理。物理
层是 OSI 分层结构体系中最基础的一层,它建立在通信媒体的基础上,实现系统和通信媒体的物理接口,为数据链路实体之间进行透明传输,为建立、保持和拆除计算机和网络之间的物理连接提供服务。物理层的故障主要表现在设备的物理连接方式是否恰当;连接电缆是否正确。确定路由器端口物理连接是否完好的最佳方法是使用 show interface 命令,检查每个端口的状态,解释屏幕输出信息,查看端口状态、协议建立状态和 EIA 状态。
参考答案:(57)A
$\bullet$ 假设磁盘块与缓冲区大小相同,每个盘块读入缓冲区的时间为 $16\mu \mathrm{s}$ ,由缓冲区送至用户区的时间是 $5\mu \mathrm{s}$ ,在用户区内系统对每块数据的处理时间为 $1\mu \mathrm{s}$ 。若用户需要将大小为 10 个磁盘块的 Doc1 文件逐块从磁盘读入缓冲区,并送至用户区进行处理,那么采用单缓冲区需要花费的时间为(58) $\mu \mathrm{s}$ ;采用双缓冲区需要花费的时间为(59) $\mu \mathrm{s}$ 。
(58)A.160 B.161 C.166 D.211 (59)A.160 B.161 C.166 D.211
试题解析 本题可视为对流水线题型的考查。
当采用单缓冲区时,由于将盘块读入缓冲区与将数据从缓冲区转到用户区,都要用到同一个缓冲区,所以只能把这两步作为流水线的一个段。所以计算方式为: $16 + 5 + 1 + (10 - 1)\times (16 + 5) = 211\mu \mathrm{s}$ 。
当采用双缓冲区时,读入缓冲区与将数据从缓冲区转到用户区可以作为流水线的两个段,所以计算方式为: $16 + 5 + 1 + (10 - 1)\times 16 = 166\mu \mathrm{s}$ 。
参考答案:(58)D (59)C
$\bullet$ 网络系统设计过程中,逻辑网络设计阶段的任务是(60)。
(60)A.依据逻辑网络设计的要求,确定设备的物理分布和运行环境B.分析现有网络和新网络的资源分布,掌握网络的运行状态C.根据用户需求,描述网络行为和性能D.理解网络应该具有的功能和性能,设计出符合用户需求的网络
试题解析 在逻辑网络设计阶段,需要描述满足用户需求的网络行为以及性能,详细说明数据是如何在网络上阐述的,此阶段不涉及网络元素的具体物理位置。此阶段最后应该得到一份逻辑网络设计文档。
参考答案:(60)C
$\bullet$ 嵌入式系统中采用中断方式实现输入/输出的主要原因是(61)。在中断时,CPU断点信息一般保存到(62)中。
(61)A.速度最快 B.CPU不参与操作C.实现起来比较容易 D.能对突发事件做出快速响应
(62)A.通用寄存器 B.堆 C.栈 D.I/O接口
试题解析 CPU利用中断方式完成数据的 I/O,当 I/O 系统与外设交换数据时,CPU 无须等待也不必去查询 I/O 的状态,当 I/O 系统完成了数据传输后则以中断信号通知 CPU。然后 CPU 通过栈保存正在执行程序的现场,转入 I/O 中断服务程序完成与 I/O 系统的数据交换。再返回原主程
序继续执行。与程序控制方式相比,中断方式因为CPU无须等待而提高了效率。
参考答案:(61)D (62)C
$\bullet$ 成本是信息系统生命周期内各阶段的所有投入之和,按照成本性态分类,可以分为固定成本、变动成本和混合成本。其中(63)属于固定成本,(64)属于变动成本。
(63)A.固定资产折旧费 B.直接材料费C.产品包装费 D.开发奖金(64)A.员工培训费 B.房屋租金C.技术开发经费 D.外包费用
试题解析1)固定成本。固定成本是指其总额在一定期间和一定业务量范围内,不受业务量变动的影响而保持固定不变的成本。例如,管理人员的工资、办公费、固定资产折旧费、员工培训费等。固定成本又可分为酌量性固定成本和约束性固定成本。酌量性固定成本是指管理层的决策可以影响其数额的固定成本,例如,广告费、员工培训费、技术开发经费等;约束性固定成本是指管理层无法决定其数额的固定成本,即必须开支的成本,例如,办公场地及机器设备的折旧费、房屋及设备租金、管理人员的工资等。
2)变动成本。变动成本也称为可变成本,是指在一定时期和一定业务量范围内其总额随着业务量的变动而成正比例变动的成本。例如,直接材料费、产品包装费、外包费用、开发奖金等。变动成本也可以分为酌量性变动成本和约束性变动成本。开发奖金、外包费用等可看作是酌量性变动成本;约束性变动成本通常表现为系统建设的直接物耗成本,以直接材料成本最为典型。
参考答案:(63)A (64)D
$\bullet$ 软件过程是制作软件产品的一组活动以及结果,这些活动主要由软件人员来完成,主要包括(65)。软件过程模型是软件开发实际过程的抽象与概括,它应该包括构成软件过程的各种活动。软件过程有各种各样的模型,其中(66)的活动之间存在因果关系,前一阶段工作的结果是后一段阶段工作的输入描述。
(65)A.软件描述、软件开发和软件测试B.软件开发、软件有效性验证和软件测试C.软件描述、软件设计、软件实现和软件测试D.软件描述、软件开发、软件有效性验证和软件进化
(66)A.瀑布模型 B.原型模式 C.螺旋模型 D.基于构建的模型
试题解析软件过程是制作软件产品的一组活动以及结果,这些活动主要由软件人员来完成,软件活动主要包括如下内容。
1)软件描述:定义软件功能,以及使用的限制。
2)软件开发:软件的设计和实现,软件工程人员制作出能满足描述的软件。
3)软件有效性验证:软件必须经过严格的验证,以保证能够满足客户的需求。
4)软件进化:软件随着客户需求的变化不断地改进。
瀑布模型的特点是因果关系紧密相连,前一个阶段工作的结果是后一个阶段工作的输入。或者
说每一个阶段都建立在前一个阶段的正确结果之上,前一个阶段的错漏会隐蔽地带到后一个阶段,这种错误有时甚至是灾难性的。因此每一个阶段工作完成后都要进行审查和确认,这是非常重要的。历史上,瀑布模型起到了重要作用,它的出现有利于人员的组织管理,以及软件开发方法和工具的研究。
参考答案:(65)D (66)A
$\bullet$ 面向对象的分析模型主要由顶层架构图、用例与用例图和(67)_构成,设计模型则包含以(68)_表示的软件体系结构图、以交互图表示的用例实现图、完整精确的类图、描述复杂对象的(69)_和用于描述流程化处理过程的活动图等。
(67)A.数据流模型 B.领域概念模型 C.功能分解图 D.功能需求模型
(68)A.模型视图控制器 B.组件图 C.包图 D.2层、3层或N层
(69)A.序列图 B.协作图 C.流程图 D.状态图
试题解析 面向对象的分析模型主要由顶层架构图、用例与用例图和领域概念模型构成。设计模型则包含以包图表示的软件体系结构图、以交互图表示的用例实现图、完整精确的类图、描述复杂对象的状态图和用于描述流程化处理过程的活动图等。
参考答案:(67)B (68)C (69)D
$\bullet$ 载重量限24吨的某架货运飞机执行将一批金属原料运往某地的任务。待运输的各箱原料的重量、运输利润如下表所示。
| 箱号 | 1 | 2 | 3 | 4 | 5 | 6 |
| 重量/吨 | 8 | 13 | 6 | 9 | 5 | 7 |
| 利润/元 | 3000 | 5000 | 2000 | 4000 | 2000 | 3000 |
经优化安排,该飞机本次运输可以获得的最大利润为(70)元。
(70)A.11000 B.10000 C.9000 D.8000
试题解析 在重量有限制的条件下,为取得最大的利润,显然应优先选择装载“利润重量比”大的货物。先列出每箱货物的利润/重量比,见下表。
| 箱号 | 1 | 2 | 3 | 4 | 5 | 6 |
| 重量/吨 | 8 | 13 | 6 | 9 | 5 | 7 |
| 利润/元 | 3000 | 5000 | 2000<fce>4000 | 2000 | 3000 | |
| 利润/重量/元每吨 | 375 | 385 | 333 | 444 | 400 | 429 |
根据利润重量比优先原则,应先装第4箱、第6箱货物。重量已达到16吨,离最大载重量还差8吨,只能再装第1箱,或第3箱,或第5箱。为取得最大利润,再装第1箱更好。
所以最优方案是装运箱号为1、4、6的三箱,总利润为 $3000 + 4000 + 3000 = 10000$ 元。
参考答案:(70)B
$\bullet$ System analysis is traditionally done top-down using structured analysis based on (71). Object-oriented analysis focuses on creation of models. The three types of the analysis model are (72). There are two substages of object-oriented analysis. (73) focuses on real-world things whose semantics the application captures. The object constructed in the requirement analysis shows the (74) of the real-world system and organizes it into workable pieces. (75) addresses the computer aspects of the application that are visible to users. The objects are those which can be expected to vary from time to time quite rapidly.
(71)A. functional decomposition B. object abstraction C. data inheritance D. information generalization
(72)A. function model, class model and state model B. class model, interaction model and state model C. class model, interaction model and sequence model D. function model, interaction model and state model
(73)A. Static analysis B. Semantic analysis C. Scope analysis D. Domain analysis
(74)A. static structure B. system components C. data flows D. program procedures
(75)A. Program analysis B. Function requirement C. Application analysis D. Physical model
试题解析 系统分析传统上以功能分解为基础,利用结构化分析自顶向下完成。面向对象分析关注于模型的创建。该分析模型有3种类型:类模型、交互模型和状态模型。面向对象分析有两个子阶段。领域分析侧重于现实世界中那些语义被应用程序获取的事物。在需求分析中所构造的对象说明了现实世界系统的静态结构并将其组织为可用的片段。应用分析处理应用系统中用户可见的计算机问题。所分析的对象预计可能会时不时地发生较快的变化。
参考答案:(71)A (72)B (73)D (74)A (75)C
第31小时 模拟试题Ⅱ(下午案例分析)
试题一(25分)
阅读以下关于软件体系结构方面的叙述,根据要求回答下列问题。
【说明】某大中型企业在全国各城市共有15个左右的分支机构,这些机构已经建设了相关的关系型数据库管理系统,每天负责独立地处理本区域内的业务并实时存储业务数据。PH软件公司承接了该大中型企业信息管理系统的升级改造开发任务。该软件公司的领域专家对需求进行深入分析后,得到的部分系统需求如下。
(1)开发一个网络财务程序,使各地员工能在Internet上通过VPN技术进行财务单据报销和处理。
(2)为了加强管理,实现对下属分支机构业务数据的异地存储备份,保证数据的安全及恢复,同时对全国业务数据进行挖掘分析,拟在该企业总部建设数据中心。
(3)PH公司在设计该财务程序的体系结构时,开发项目组产生了以下分歧:
架构师许工认为应该采用客户机/服务器(C/S)架构风格,各分支机构财务部要安装一个软件客户端,通过这个客户端连接到总公司财务部主机。如果员工在外地出差,需要报销账务的,也需要安装这个客户端才能进行。
架构师郭工认为应该采用浏览器/服务器(B/S)架构风格,各分支机构及出差员工直接通过Windows操作系统自带的IE浏览器就可以连接到总公司的财务部主机。
在架构评估会议上,专家对这两种方案进行综合评价,最终采用了C/S和B/S相结合的混合架构风格。
【问题1】(8分)
结合你的系统架构经验,请用400字以内的文字简要讨论C/S和B/S两种架构风格各自的优点
和缺点。
参考答案:(包括但不限于以下答案)。
C/S架构风格的优点: $①$ 客户机应用程序与服务器程序分离,二者的开发既可以分开进行,也可以同时进行; $(2)$ 技术成熟,允许网络分布操作,交互性强,具有安全的存取模式; $(3)$ 网络压力小,响应速度快,有利于处理大量数据; $(4)$ 模型思想简单,易于人们理解和接受等。
C/S架构风格的缺点: $①$ 客户机与服务器的通信依赖于网络,服务器的负荷过重; $(2)$ 无法实现快速部署和安装,维护工作量大,升级困难; $(3)$ 开发成本较高,客户端程序设计复杂,灵活性差; $(4)$ 用户界面风格不一,软件移植和数据集成困难; $(5)$ 数据库的安全性因客户机程序直接访问而降低等。
B/S架构风格的优点: $①$ 易于部署、维护和升级; $(2)$ 具有良好的开放性和可扩充性,可以应用在广域网上,方便了信息的全球传输、查询和发布; $(3)$ 可跨平台操作,无须开发客户端软件; $(4)$ 通过JDBC等数据库连接接口,提高了动态交互性、服务器的通用性与可移植性等。
B/S架构风格的缺点: $①$ 数据的动态交互性不强,不利于在线事务处理(OnLine Transaction Processing,OLTP)应用; $(2)$ 数据查询等响应速度较慢; $(3)$ 系统的安全性较难以控制等。
【问题2】(8分)
结合你的系统架构经验,请用600字以内的文字简要说明该工程项目采用C/S和B/S相结合的混合架构风格的设计要点及其优点。
参考答案:(包含但不限于以下内容)。
在该企业总部局域网上部署财务Web服务器及其相关的数据库服务器,两种服务器之间采用C/S架构:总部局域网上提供C/S和B/S两种并存的架构风格,根据不同的应用需求和客户需求进行灵活地选择。
若项目资金充裕,可在各分支机构局域网中也采用类似于企业总部的部署风格;若项目资金不足,则在各分支机构财务部门局域网中采C/S架构,部署应用服务器及相关的数据库服务器,然后将集中处理的后期财务数据通过VPN技术上传至总部局域网的相应服务器中。
在外出差的员工和各分支机构的普通员工可通过VPN技术访问企业总部局域网上的Web服务器,查看相关的信息。
采用C/S和B/S混合架构的优点如下(包含但不限于以下内容): $(1)$ 充分发挥了B/S与C/S体系结构的优势,弥补了二者的不足; $(2)$ 客户请求和信息发布采用B/S架构,保持了瘦客户端的优点,客户机只利用浏览器即可完成所有的应用需求; $(3)$ 数据库的请求和响应操作采用C/S架构,通过在Web应用程序和数据库之间建立ODBC/JDBC连接来完成数据库的连接和请求响应,能完成大量数据的批量录入请求; $(4)$ 系统的部署、维护及数据更新方便,不存在完全采用C/S结构带来的客户端维护工作量大等缺点; $(5)$ 将服务器端划分为Web服务器和Web应用程序两部分。Web应用程序采用组件技术实现三层体系结构中的商业逻辑部分,达到封装源代码、保护知识产权的目的; $(6)$ 对原基于C/S架构的应用,只需开发用于发布的Web界面,就能升级到这种混合架构系统中,从而最大限度地保护了原有投资。
【问题3】(9分)
为保证各分支机构可靠、高效地向数据中心汇总业务数据,避免单点故障,对该企业总部数据中心架构进行设计时,应该采用哪些相关的技术?
参考答案:包含但不限于以下内容:
1)采用双链路连接Internet的备份方式。
2)对数据中心的数据库服务器采用双机冗余热备方式(或多机集群Cluster和数据库并行处理技术等)。
3)对存储设备采用RAID10级别(或全冗余的SAN结构,或全冗余的存储结构)等。
试题二(25分)
阅读以下关于系统架构设计的叙述,在答题纸上回答问题1至问题3。
【说明】某公司拟开发一套基于边缘计算的智能门禁系统,用于如园区、新零售、工业现场等存在来访、被访业务的场景。来访者在来访前,可以通过线上提前预约的方式将自己的个人信息记录在后台,被访者在系统中通过此请求后,来访者在到访时可以直接通过“刷脸”的方式通过门禁,无须做其他验证。此外,系统的管理员可对正在运行的门禁设备进行管理。
基于项目需求,该公司组建项目组,召开了项目讨论会。会上,张工根据业务需求并结合边缘计算的思想,提出本系统可由访客注册模块、模型训练模块、端侧识别模块与设备调度平台模块等4项功能组成,李工从技术层面提出该系统可使用Flask框架与SSM框架为基础来开发后台服务器,将开发好的系统通过Docker进行部署,并使用MQTT协议对Docker进行管理。
【问题1】(8分)
请简述边缘计算的特点有哪些
参考答案:
(1)连接性:所连接物理对象的多样性及应用场景的多样性,需要边缘计算具备丰富的连接功能,如各种网络接口、网络协议等。
(2)数据第一入口:边缘计算拥有大量、实时、完整的数据,可基于数据全生命周期进行管理与价值创造,将更好地支撑预测性维护、资产效率与管理等创新应用。
(3)约束性:边缘计算产品需适配工业现场相对恶劣的工作条件与运行环境。在工业互联场景下,对边缘计算设备的功耗、成本、空间也有较高的要求。边缘计算产品需要考虑通过软硬件集成与优化,以适配各种条件约束,支撑行业数字化多样性场景。
(4)分布性:边缘计算实际部署天然具备分布式特征。这要求边缘计算支持分布式计算与存储、实现分布式资源的动态调度与统一管理、支撑分布式智能、具备分布式安全等能力。
【问题2】(5分)
边缘计算与云计算的区别与联系是什么?
参考答案:
区别:边缘计算与云计算各有所长,云计算擅长全局性、非实时、长周期的大数据处理与分析,能够在长周期维护、业务决策支撑等领域发挥优势;边缘计算更适用局部性、实时、短周期数据的处理与分析,能更好地支撑本地业务的实时智能化决策与执行。
联系:边缘计算与云计算之间不是替代关系,而是互补协同关系,边云协同将放大边缘计算与云计算的应用价值,边缘计算既靠近执行单元,也是云端所需高价值数据的采集和初步处理单元,可以更好地支撑云端应用;反之,云计算通过大数据分析优化输出的业务规则或模型可以下发到边缘侧,边缘计算基于新的业务规则或模型运行。
【问题3】(12分)
简述边缘计算与云计算的协同能力有哪些
参考答案:
(1)资源协同:边缘节点提供计算、存储、网络、虚拟化等基础设施资源、具有本地资源调度管理能力,同时可与云端协同,接受并执行云端资源调度管理策略,包括边缘节点的设备管理、资源管理以及网络连接管理。
(2)数据协同:边缘节点主要负责现场/终端数据的采集,按照规则或数据模型对数据进行初步处理与分析,并将处理结果以及相关数据上传给云端;云端提供海量数据的存储、分析与价值挖掘。边缘与云的数据协同,支持数据在边缘与云之间可控地有序流动,形成完整的数据流转路径,高效低成本地对数据进行生命周期管理与价值挖掘。
(3)智能协同:边缘节点执行推理,实现分布式智能;云端开展模型训练,并将模型下发边缘节点。
(4)应用管理协同:边缘节点提供应用部署与运行环境,并对本节点多个应用的生命周期进行管理调度;云端主要提供应用开发、测试环境,以及应用的生命周期管理能力。
(5)业务管理协同:边缘节点提供模块化、微服务化的应用/数字孪生/网络等应用实例;云端主要提供按照客户需求实现应用/数字孪生/网络等的业务编排能力。
(6)服务协同:边缘节点按照云端策略实现部分 ECSaaS 服务,通过 ECSaaS 与云端 SaaS 的协同实现面向客户的按需 SaaS 服务;云端主要提供 SaaS 服务在云端和边缘节点的服务分布策略,以及云端承担的 SaaS 服务能力。
试题三(25分)
【说明】阅读以下关于嵌入式软件体系架构的叙述,在答题纸上回答问题1至问题3。
某公司承担了一项宇航嵌入式设备的研制任务。本项目除对硬件设备环境有很高的要求外,还要求支持以下功能:
(1)设备由多个处理机模块组成,需要时外场可快速更换(即 LRM 结构)。
(2)应用软件应与硬件无关,便于软硬件的升级。
(3)由于宇航嵌入式设备中要支持不同功能,系统应支持完成不同功能任务间的数据隔离。
(4)宇航设备可靠性要求高,系统要有故障处理能力。
公司在接到此项任务后,进行了反复论证,提出三层栈(TLS)软件总体架构,如图3.1所示,并将软件设计工作交给了李工,要求其在三周内完成软件总体设计工作,给出总体设计方案。
图3.1宇航嵌入式设备软件架构
【问题1】(8分)
用150字以内的文字,说明公司制订的TLS软件架构的层次特点,并针对上述功能需求 $(1)\sim$ (4),说明架构中各层的内涵。
参考答案:
TLS结构框架的主要特点:
(1)应用软件仅与操作系统服务相关,不直接操作硬件。(2)操作系统通过模块支持原软件访问硬件,可与具体硬件无关。(3)模块支持层将硬件抽象成标准操作。(4)通过三层栈的划分可实现硬件的快速更改与升级,应用软件的升级不会引起硬件的变更。
TLS结构框架各层的内涵是:
(1)应用层主要完成宇航设备的具体工作,由多个功能任务组成,各功能任务间的隔离由操作系统层实现。
(2)操作系统层实现应用软件与硬件的隔离,为应用软件提供更加丰富的计算机资源服务。操作系统为应用软件提供标准的API接口(如POSIX),确保了应用软件的可升级性。
(3)模块支持层为操作系统管理硬件资源提供统一的管理方法,用一种抽象的标准接口实现软件与硬件的无关性,达到硬件的升级要求,便于硬件的外场快速更换。
【问题2】(10分)
在TLS软件架构的基础上,关于选择哪种类型的嵌入式操作系统问题,李工与总工程师发生了严重分歧。李工认为,宇航系统是实时系统,操作系统的处理时间越快越好,隔离意味着以时间为代价,没有必要,建议选择类似于VxWorks5.5的操作系统;总工程师认为,应用软件间隔离是宇航系统的安全性要求,宇航系统在选择操作系统时必须考虑这一点,建议选择类似于Linux的操作系统。
请说明两种操作系统的主要差异,完成表3.1中的空 $(1)\sim (5)$ ,并针对本任务要求,用200
字以内的文字说明你选择操作系统的类型和理由。
表3.1 两种操作系统的主要差异
| 比较类型 | VxWorks5.5 | Linux |
| 工作方式 | 操作系统与应用程序处于同一存储空间 | (1) |
| 多任务支持 | 支持多任务(线程)操作 | (2) |
| 实时性 | (3) | 实时系统 |
| 安全性 | (4) | (5) |
| 标准API | 支持 | 支持 |
参考答案:
两种操作系统的主要差异见下表。
| 比较类型 | VxWorks5.5 | Linux |
| 工作方式 | 操作系统与应用程序处于同一存储空间 | (1) 操作系统与应用程序处于不同的存储空间 |
| 多任务支持 | 支持多任务(线程)操作 | (2) 支持多进程、多线程操作 |
| 实时性 | (3) 硬实时系统 | 实时系统 |
| 安全性 | (4) 任务间无隔离保护 | (5) 支持进程间隔离保护 |
| 标准API | 支持 | 支持 |
我选择类似于Linux的嵌入式操作系统的理由如下:
(1)Linux操作系统是一种安全性较强的操作系统。内核工作在系统态,应用软件工作在用户态,可以有效防止应用软件对操作系统的破坏。
(2)Linux操作系统调度的最小单位是线程,线程归属于进程,进程具有自己独立的资源。进程通过存储器管理部件(MMU)实现多功能应用间隔离。
(3)嵌入式Linux操作系统支持硬件抽象,可有效实现TLS结构,并将硬件抽象与操作系统分离,可方便地实现硬件的外场快速更换。
【问题3】(7分)
故障处理是宇航系统软件设计中极为重要的组成部分。故障处理主要包括故障监视、故障定位、故障隔离和系统容错(重组)。用150字以内的文字说明嵌入式系统中的故障主要分哪几类?并分别给出两种常用的故障滤波算法和容错算法。
参考答案:
(1)嵌入式系统中的故障主要分为: $①$ 硬件故障:如CPU、存储器和定时器等; $(2)$ 应用软件故障:如数值越界、异常和超时等; $(3)$ 操作系统故障:如越权访问、死锁和资源枯竭等。
(2)滤波算法: $①$ 门限算法; $(2)$ 递减算法; $(3)$ 递增算法; $(4)$ 周期滤波算法。
(3)容错算法: $①N + 1$ 备份; $(2)$ 冷备; $(3)$ 温备; $(4)$ 热备。
试题四(25分)
【说明】阅读以下关于数据库的叙述,在答题纸上回答问题1至问题2。
某大中型企业采用Oracle数据库建立一个经济信息统计方面的大型数据库应用系统。尽管配置了比较良好的硬件和网络环境,但该数据库应用系统实施后的整体性能表现较差。特别是随着业务量与信息量的迅速扩大,数据库系统的存取速度显著减慢,存储效率也明显下降。
该企业通过反复实践与摸索,并邀请数据库专家一起讨论,认为可以从以下4个方面进一步优化数据库应用系统。
(1)由于数据库应用中最主要的查询与修改数据操作大多需通过I/O来完成,因此需要通过调整服务器配置(即对硬件设备进行升级)、操作系统配置与数据库管理系统的有关参数,优化系统的I/O性能,尤其是改进磁盘I/O的效率与性能。
(2)优化“索引”的建立与使用机制,尽可能提高数据查询的速度或效率。
(3)合理使用聚类(Cluster),改进查询响应时间和系统的综合性能。其中,“聚类”是指把单独组织的,但在逻辑上经常需要连接的,较为稳定的几个基本表聚集在一起(在物理上实现邻近存放),可以显著减少数据的搜索时间,从而提高性能。
(4)对应用系统中使用的SQL语句进行调优,针对每条SQL语句都建立对应的索引等。
【问题1】(13分)
在该企业所邀请的数据库专家讨论意见中,针对每条SQL语句都建立索引的建议是否合适?请简要说明理由。
参考答案:不适当,理由如下。
(1)如果建立索引不当,数据库管理系统将不利用已经建立的索引,而采取全表扫描。(2)当更新操作成为系统瓶颈,因为每次更新操作会重建表的索引,则需要考虑删除某些索引。(3)应该针对不同应用情况选择适当的索引类型。例如,如果经常使用范围查询,则B树索引比散列索引更加高效。(4)应该将有利于大多数数据查询和更新的索引设为聚类索引。(5)需要对建立的索引进行实际的测试,因为索引的使用是由数据库管理系统(数据库优化器)决定的。
【问题2】(12分)
结合你的经验,请列举出4条SQL语句优化的基本策略。
参考答案:SQL语句优化的常见策略如下(包含但不限于以下内容,列举出其中5个小点即可,每小点1分)。
(1)建立物化视图或尽可能减少多表查询。
(2)以不相干子查询替代相干子查询。
(3)只检索需要的列。
(4)用带 IN 的条件子句等价替换带 OR 的子句。(5)经常提交 COMMIT,以尽早释放锁。(6)避免嵌套的游标(Cursor)和多重循环等。
试题五(25分)
阅读以下关于Web系统架构设计的叙述,在答题纸上回答问题1至问题3。
【说明】E- Mall是一家电子商务公司,其主要业务是在线购物,包括书籍、服装、家电和日用品等。随着公司业务规模不断增大,公司决策层决定重新设计并实现其网上交易系统,公司负责系统开发的王工和李工分别给出了两种不同的设计方案,如图5.1和图5.2所示。
图5.1 王工的设计方案
图5.2 李工的设计方案
公司的架构师和开发者针对这两种设计方案,从服务器负载情况、业务逻辑的分离性、系统可靠性、实现简单性等方面进行讨论与评估,综合考虑最终采用了李工给出的方案。
【问题1】(8分)
请分析比较王工、李工两种方案的优点和不足,完成下表中的空白部分。
| 方案体系结构 评价因素 | 王工建议的体系结构方案 | 李工建议的体系结构方案 |
| 服务器负载 | Web 服务器需要同时处理业务逻辑与数据库访问,负担较重 | (1) |
| 业务逻辑的分离性 | (2) | 采用多个应用服务器专门进行业务逻辑处理,做到业务逻辑与其他代码分离 |
| 系统可靠性 | 多处采用单台 Web 服务器,整个系统的可靠性较差 | (3) |
| 实现简单性 | 主要采用 JSP、ASP 等脚本语言实现系统,比较简单 | (4) |
参考答案:
| 方案体系结构 评价因素 | 王工建议的体系结构方案 | 李工建议的体系结构方案 |
| 服务器负载 | Web 服务器需要同时处理业务逻辑与数据库访问,负担较重 | (1) Web 服务器处理用户请求,应用服务器处理业务逻辑与数据库访问,负载较为均衡 |
| 业务逻辑的分离性 | (2) 业务逻辑与数据库访问都位于 Web 服务器中,业务与逻辑没有分离 | 采用多个应用服务器专门进行业务逻辑处理,做到业务逻辑与其他代码分离 |
| 系统可靠性 | 多处采用单台 Web 服务器,整个系统的可靠性较差 | (3) 采用多台应用服务器,系统的可靠性较高 |
| 实现简单性 | 主要采用 JSP、ASP 等脚本语言实现系统,比较简单 | (4) 需要将脚本语言与面向对象编程语言相结合,相对复杂 |
【问题2】(9分)
对数据库的访问是该系统开发中需要特别注意的一个问题,O/R映射是一种常用的数据库访问编程技术。请用200字以内的文字说明O/R映射的含义,并指出采用O/R映射的3个主要好处。
参考答案:
O/R映射指的是对象/关系映射,是一种编程技术,将关系数据库中的关系型数据与面向对象编程语言中类型系统定义的数据进行格式转换。采用对象/关系映射主要有3点好处:
(1)可以将业务逻辑与数据逻辑分离。(2)可以使得开发人员采用面向对象的方式访问底层关系型数据库。(3)能够做到上层应用与底层的具体数据库无关,两者解耦合。
【问题3】(8分)
性能是Web应用系统的一个重要质量属性。请用200字以内的文字说明3个主要影响Web应用系统性能的因素,针对每个因素提出解决方案以提高系统性能。
参考答案:
影响Web应用系统性能的3个主要因素分别是:
(1)数据库的连接与销毁。可以采用数据池的方式缓存数据库连接,实现数据库连接复用,提高系统的数据访问效率。(2)构件或中间件的加载与卸载。可以采用分布式对象池的方式缓存创建开销大的对象,实现对象复用,用以提高效率。(3)线程的创建与销毁。可以采用线程池的方式缓存已经创建的线程,提高系统的反应速度。
第32小时 模拟试题Ⅱ(下午论文)
试题一 论软件架构风格
软件体系结构风格是描述某一特定应用领域中系统组织方式的惯用模式。体系结构风格定义一个系统家族,即一个体系结构定义一个词汇表和一组约束。词汇表中包含一些构件和连接件类型,而这组约束指出系统是如何将这些构件和连接件组合起来的。体系结构风格反映了领域中众多系统所共有的结构和语义特性,并指导如何将各个模块和子系统有效地组织成一个完整的系统。
请围绕“论软件架构风格”论题,依次从以下三个方面进行论述。
(1)概要叙述你参与分析和设计的软件系统开发项目以及你所担任的主要工作。(2)软件系统开发中常用的软件架构风格有哪些?详细阐述每种风格的具体含义。(3)详细说明你所参与分析和设计的软件系统是采用什么软件架构风格的,并分析采用该架构风格设计的原因。
解析:常见的、经典的架构风格有:
(1)数据流风格:包括批处理体系结构风格、管道-过滤器风格。(2)管道-过滤器风格:包括主程序/子程序风格、面向对象风格、层次型风格(C/S架构、B/S架构)。(3)以数据为中心的风格:包括仓库体系结构风格、黑板体系结构风格。(4)虚拟机风格:包括解释器风格、规则系统风格。(5)独立构件架构风格:进程通信风格、事件系统风格。(6)C2风格:C2风格也被认为是层次风格的一种。此外,一些现代的体系结构风格如微服务、SOA等也可以写在论文中。
试题二 论企业应用系统的层次式架构风格
层次式架构是软件体系结构设计中最为常用的一种架构形式,它为软件系统提供了一种在结
构、行为和属性方面的高级抽象,其核心思想是将系统组成为一种层次结构。每一层为上层服务,并作为下层客户。在一些层次系统中,除了一些精心挑选的输出函数外,内部的层接口只对相邻的层可见。层次式架构风格的每一层最多只影响两层,同时只要给相邻层提供相同的接口,也允许每层用不同的方法实现,这种方式也为软件重用提供了强大的支持。
大部分的应用会分成表现层(或称为展示层)、中间层(或称为业务层)、数据访问层(或称为持久层)和数据层。
请围绕“企业应用系统的层次式架构风格”论题,依次从以下三个方面进行论述。
(1)概要叙述你参与管理和开发的企业应用系统建设项目以及你在其中所承担的主要工作。(2)请结合项目实际情况,指出你参与开发的应用系统都有哪些层次以及每个层次的主要功能。(3)请结合项目实际情况,说明你的项目是如何使用层次式架构进行架构设计的。
解析:
(1)表现层。表现层主要负责接收用户的请求,对用户的输入、输出进行检查与控制,处理客户端的一些动作,包括控制页面跳转等,并向用户呈现最终的结果信息。可以使用MVC模式来设计表现层。
(2)中间层。中间层负责实现系统的业务功能,主要包括业务逻辑层组件、业务逻辑层工作流、业务逻辑层实体和业务逻辑层框架四个方面。业务逻辑层组件分为接口和实现类两个部分,接口用于定义业务逻辑组件,定义业务逻辑组件必须实现的方法。通常按模块来设计业务逻辑组件,每个模块设计为一个业务逻辑组件,并且每个业务逻辑组件以多个DAO组件作为基础,从而实现对外提供系统的业务逻辑服务。业务逻辑层工作流能够实现在多个参与者之间按照某种预定义的规则传递文档、信息或任务的过程自动进行,从而实现某个预期的业务目标,或者促进此目标的实现。业务逻辑层实体提供对业务数据及相关功能的状态编程访问,业务逻辑层实体数据可以使用具有复杂架构的数据来构建,这种数据通常来自数据库中的多个相关表。业务逻辑层实体数据可以作为业务过程的部分I/O参数传递,业务逻辑层的实体是可序列化的,以保持它们的当前状态。业务逻辑层是实现系统功能的核心组件,采用容器的形式,便于系统功能的开发、代码重用和管理。
(3)持久层。持久层主要负责数据的持久化存储,主要负责将业务数据存储在文件、数据库等持久化存储介质中。持久层可以使用在线访问、Data Access Object、Data Transfer Object、离线数据模式、对象/关系映射(Object/Relation Mapping)5种数据访问方式。
试题三 论面向服务的架构设计
在面向服务的架构(Service- Oriented Architecture,SOA)中,服务的概念有了延伸,泛指系统对外提供的功能集。例如,在一个大型企业内部,可能存在进销存、人事档案和财务等多个系统,在实施SOA后,每个系统用于提供相应的服务,财务系统作为资金运作的重要环节,也向整个企业信息化系统提供财务处理的服务,那么财务系统的开放接口可以看成是一个服务。
请围绕“面向服务的架构设计”论题,依次从以下三方面进行论述。
(1)概要叙述你参与分析和开发的软件系统开发项目以及你所担任的主要工作。
(2)说明面向服务架构的主要协议和规范、标准,详细阐述每种协议和规范、标准的具体内容。
(3)说明面向服务架构的设计原则,详细阐述每种设计原则的具体内容。
解析:
(1)UDDI协议:统一描述、发现和集成协议。包含了服务描述与发现的标准规范,它使得商业实体能够彼此发现;定义它们怎样在Internet上互相作用,并在一个全球的注册体系架构中共享信息。
(2)Web服务描述语言(Web Services Description Language,WSDL):是一个用来描述Web服务和说明如何与Web服务通信的XML语言。
(3)SOAP协议:SOAP是在分散或分布式的环境中交换信息的简单的协议,是一个基于XML的协议。
(4)REST规范:为了让不同的软件或者应用程序在任何网络环境下都可以进行信息的互相传递。微服务对外就是以REST API的形式暴露给调用者。RESTful即REST形式的,是对遵循REST设计思想同时满足设计约束的一类架构设计或应用程序的统称,这一类都可称为RESTful,可以理解为资源表述性状态转移。
(5)通信协议标准:SOA服务用消息进行通信,该消息通常使用XML Schema来定义(也称作XML Schema Definition,XSD)。
SOA的设计原则主要有:
(1)无状态。以避免服务请求者依赖于服务提供者的状态。(2)单一实例。以高内聚的实现方法,来避免功能冗余。(3)明确定义的接口。服务的接口由WSDL定义,用于指明服务的公共接口与其内部专用实现之间的界线。(4)自包含和模块化。服务封装了那些在业务上稳定、重复出现的活动和组件,实现服务的功能实体是完全独立自主的,独立进行部署、版本控制、自我管理和恢复。(5)粗粒度。服务数量不应该太大,依靠消息交互而不是远程过程调用(RPC),通常消息量较大,但是服务之间的交互频度较低。(6)服务之间的松耦合性。服务使用者看到的是服务的接口,其位置、实现技术和当前状态等对使用者是不可见的,服务私有数据对服务使用者是不可见的。(7)重用能力。服务应该是可以复用的。(8)互操作性、兼容和策略声明。为了确保服务规约的全面和明确,利用策略来定义可配置的互操作语义,来描述特定服务的期望、控制其行为。利用策略声明确保服务期望和语义兼容性方面的完整和明确。
试题四 论基于架构的软件设计方法及应用
基于架构的软件设计(Architecture- Based Software Design,ABSD)方法以构成软件架构的商
业、质量和功能需求等要素来驱动整个软件开发过程。ABSD 是一个自顶向下,递归细化的软件开发方法,它以软件系统功能的分解为基础,通过选择架构风格实现质量和商业需求,并强调在架构设计过程中使用软件架构模板。采用ABSD方法,设计活动可以从项目总体功能框架明确后就开始,因此该方法特别适用于开发一些不能预先决定所有需求的软件系统。如软件产品线系统或长生命周期系统等,也可为需求不能在短时间内明确的软件项目提供指导。
请围绕“基于架构的软件开发方法及应用”论题,依次从以下三个方面进行论述。
(1)概要叙述你参与开发的、采用ABSD方法的软件项目以及你在其中所承担的主要工作。
(2)结合项目实际,详细说明采用ABSD方法进行软件开发时,需要经历哪些开发阶段?每个阶段包括哪些主要活动?
(3)阐述你在软件开发的过程中都遇到了哪些实际问题及解决方法。
解析:
采用ABSD方法进行软件开发时,需要经历架构需求、架构设计、架构文档化、架构复审、架构实现和架构演化6个阶段:
(1)架构需求。架构需求阶段需要明确用户对目标软件系统在功能、行为、性能、设计约束等方面的期望。其主要活动包括需求获取、标识构件和架构需求评审。需求获取活动需要定义开发人员必须实现的软件功能,使得用户能够完成他们的任务,从而满足功能需求。与此同时,还要获得软件质量属性,满足一些非功能性需求。标识构件活动首先需要获得系统的基本结构,然后对基本结构进行分组,最后将基本结构进行打包成构件。架构需求评审活动组织一个由系统涉众(用户、系统分析师、架构师、设计实现人员等)组成的小组,对架构需求及相关构件进行审查。审查的主要内容包括所获取的需求是否真实反映了用户需求,构件合并是否合理等。
(2)架构设计。这个阶段是一个迭代过程,利用架构需求生成并调整架构决策。主要活动包括提出架构模型、将已标识的构件映射到架构中、分析构件之间的相互作用、产生系统架构和架构设计评审。
(3)架构文档化。主要活动是对架构设计进行分析与整理,生成架构规格说明书和测试架构需求的质量设计说明书。
(4)架构复审。在一个主版本的软件架构分析之后,需要安排一次由外部人员(客户代表和领域专家)参加的架构复审。架构复审需要评价架构是否能够满足需求,质量属性需求是否在架构中得以体现,层次是否清晰,构件划分是否合理等。从而标识潜在的风险,及早发现架构设计中的缺陷和错误。
(5)架构实现。主要是对架构进行实现的过程,主要活动包括架构分析与设计、构件实现、构件组装和系统测试。
(6)架构演化。这个阶段主要解决用户在系统开发过程中发生的需求变更问题。主要活动包括架构演化计划、构件变动、更新构件的相互作用、构件的组装与测试和技术评审。
在软件开发的过程中可能遇到的问题主要包括:在架构需求获取过程中如何对捕获的架构需求进行筛选和优先级排序;在架构复审过程中如何解决评审人员意见不一致的问题;在架构实现过程中如何根据项目组实际情况选择开发语言与开发平台;在架构演化过程中如何筛选并处理用户的需求变更等。