
66. 服务器性能与容器服务部署优化指南

目录
点击展开目录
一、为什么部署了服务却还是慢
很多人一看到服务性能差,第一反应就是:
- 服务器配置太低;
- Docker 有损耗;
- 程序写得不行;
- 数据库扛不住。
这些判断都可能对,但往往只对了一部分。
一个部署到服务器上的服务,尤其是部署在 Docker 容器 里的服务,真实性能受影响的链路通常是:
客户端请求 -> 域名解析 -> 网络链路 -> 宿主机资源 -> 容器资源限制 -> 应用线程池/连接池 -> 中间件/数据库 -> 磁盘与日志 -> 返回响应
所以,线上性能问题的本质不是“某一个指标高”,而是:
整条请求路径上,哪个环节先变成了瓶颈。
这篇文档的目标不是泛泛讲“CPU、内存、带宽很重要”,而是把下面几件事讲清楚:
- 一个容器服务到底会被哪些资源限制;
- 每种资源不足时会出现什么现象;
- 为什么有时监控看起来正常,用户却觉得服务慢;
- 在业务排查里,应该按什么顺序定位问题。
二、影响服务性能的整体链路
2.1 请求从哪里开始变慢
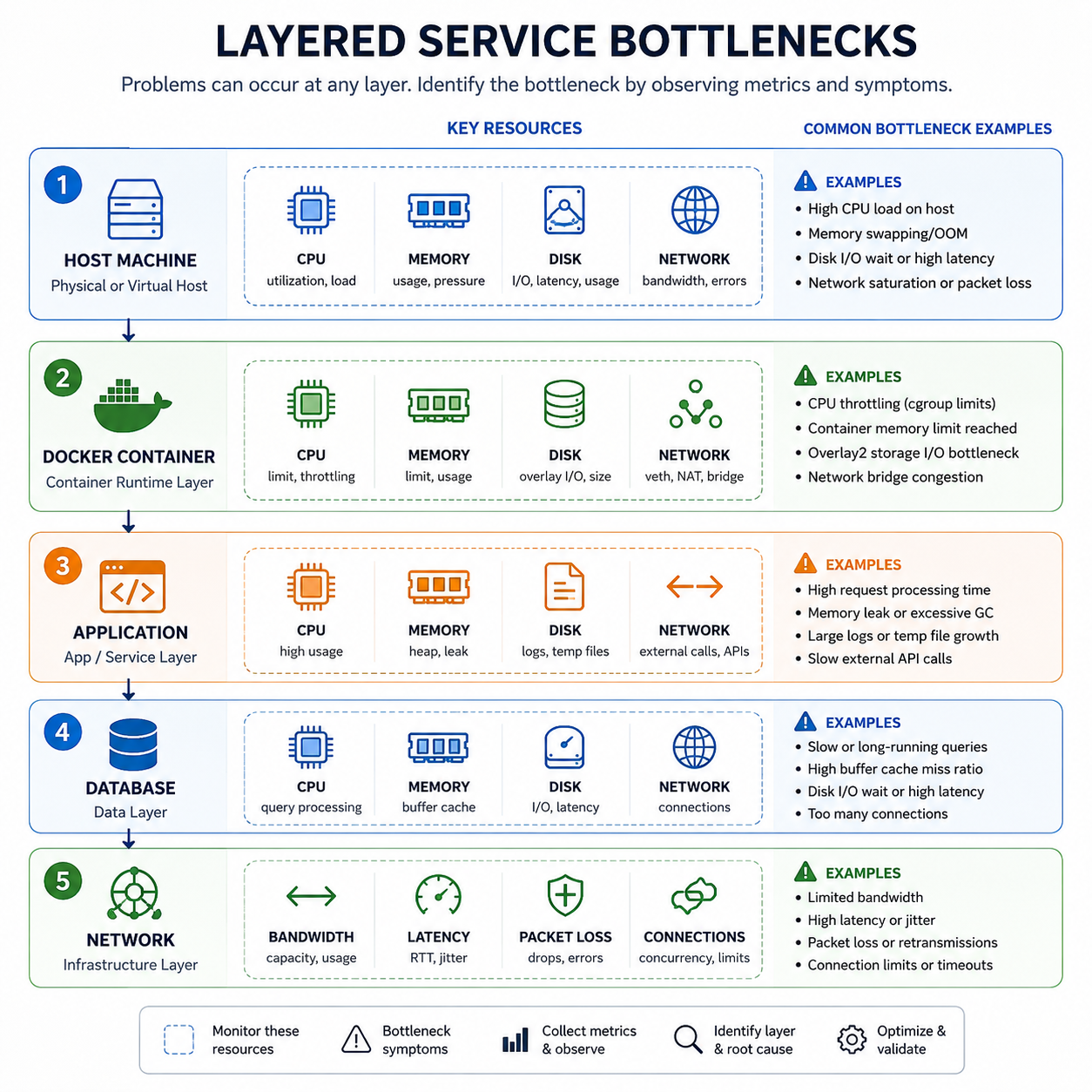
可以先用一张图建立整体认识:
这张图有两个重点:
- 慢不一定发生在应用代码里
- 容器只是中间一层,不是全部
2.2 容器慢不等于只有 Docker 慢
部署在 Docker 里的服务,看起来像“一个独立世界”,但它最终还是依赖宿主机:
| 层级 | 典型问题 | 说明 |
|---|---|---|
| 宿主机层 | CPU 抢占、内存紧张、磁盘打满、网卡拥塞 | 所有容器共享宿主机底层资源 |
| 容器层 | cpu quota、memory limit、ulimit、overlay2 I/O | Docker 的资源隔离和存储/网络机制会额外影响性能 |
| 应用层 | 线程池太小、连接池打满、GC 频繁、缓存命中率低 | 应用自己的配置问题 |
| 依赖层 | MySQL 慢查询、Redis 阻塞、外部 API 变慢 | 服务本身没满,但依赖拖慢整体响应 |
所以排查时必须形成一个意识:
用户感知到的“服务慢”,本质上是整条链路里最短木板在发作。
三、CPU:最容易被忽略的第一资源
3.1 CPU 不够时会出现什么现象
CPU 不足时,不一定表现为“服务直接挂掉”,更常见的是:
- 平均响应时间上升;
- 高峰期超时增多;
- 请求排队加长;
- 单核打满但总 CPU 看起来不高;
- 上下文切换过多;
- Java 服务 GC 时间拉长;
- Nginx / 网关 accept 很快,但上游处理慢。
CPU 问题的核心不是只看使用率,而是看 CPU 时间被谁拿走了。
常见维度包括:
| 指标 | 含义 | 风险 |
|---|---|---|
| user | 用户态 CPU | 应用本身计算量大 |
| system | 内核态 CPU | 网络、I/O、系统调用多 |
| iowait | 等待 I/O 的时间 | 表面看像 CPU 问题,实际常是磁盘问题 |
| steal | 被虚拟化宿主机偷走的 CPU 时间 | 云主机超卖或宿主资源竞争 |
| load average | 运行队列长度 | 反映 CPU 调度压力,不等于 CPU 使用率 |
3.2 容器场景下 CPU 的常见坑
容器里看 CPU,最常见的误判有三种:
- 宿主机 CPU 足够,但容器被 quota 限流
- 应用按宿主机核心数建线程池,但容器实际只分到少量 vCPU
- 多个高计算容器跑在同一宿主机,互相抢占
例如:
- 宿主机
16核 - 容器限制
2核 - Java 进程却按
16核配置并行 GC 或线程池
这种场景下,应用会出现:
- 线程很多;
- 抢 CPU 严重;
- 上下文切换频繁;
- 实际吞吐反而下降。
3.3 CPU 排查重点
排查顺序建议:
- 看宿主机
top/htop/mpstat - 看容器
docker stats - 看进程级热点
- 看应用线程池与运行队列
常用命令:
top
htop
mpstat -P ALL 1
pidstat -u -p <pid> 1
docker stats
业务经验:
- 单核打满 比 总 CPU 高 更危险,因为很多服务仍然有单线程热点。
load average持续高于可用核数时,通常已经存在调度拥堵。- 容器服务的线程池参数不能只看宿主机核数,必须结合 容器实际分配 CPU。
四、内存:很多服务不是慢,而是被挤压
4.1 内存不足的典型表现
内存问题常常不表现为立刻 OOM,而是:
- 页缓存被挤掉,磁盘读变多;
- JVM / Python 频繁回收;
- Linux 开始 swap;
- 容器频繁被 OOMKilled;
- 数据库缓存命中率下降;
- 服务抖动明显,高峰期延迟尾部变长。
也就是说,内存问题更像一种 “性能被挤压”,不是非黑即白的“活着或死了”。
4.2 容器内存相关问题
容器下要特别注意三件事:
| 问题 | 说明 | 结果 |
|---|---|---|
| 容器 limit 太小 | 堆、缓存、线程栈空间都不够 | 容器频繁 OOM |
| 应用不感知 cgroup 限制 | 仍按宿主机内存估算可用空间 | JVM / Python / Node 参数失真 |
| 多容器共享宿主机 | 单个容器看似不高,总体已经吃满 | 互相挤压,宿主机进入内存紧张状态 |
Java 场景尤其典型:
-Xmx配得过大,接近容器 limit;- 堆外内存、Metaspace、线程栈、DirectBuffer 没留余量;
- 结果不是“内存利用率高”,而是“容器被杀掉”。
4.3 内存排查重点
常见排查项:
free -h
vmstat 1
cat /proc/meminfo
docker stats
docker inspect <container_id>
容器内重点看:
memory limit- 当前 RSS
- cache 使用情况
- 是否触发 OOM
- 应用自身堆内 / 堆外内存分布
经验总结:
- 如果服务延迟波动大、CPU 不算高、磁盘读却上来了,往往要怀疑 内存导致的缓存失效。
- 线上不要把容器内存 limit 配到“刚好够跑”,要留 突发流量和 GC 抖动余量。
五、磁盘与 I/O:日志、数据库、镜像层都会拖慢服务
5.1 磁盘慢会让哪些服务先出问题
不是只有数据库才怕磁盘慢。
这些场景都很敏感:
- MySQL / PostgreSQL 刷盘;
- Redis AOF / RDB;
- Java 日志大量落盘;
- Nginx access log 高并发写入;
- Docker overlay2 层频繁写小文件;
- 上传下载服务写临时文件;
- 消息积压后消费者批量写盘。
磁盘 I/O 的问题常表现为:
- CPU 的
iowait上升; - 请求响应时间抖动;
- 吞吐下降但 CPU 没满;
- 日志写入拖住主流程;
- 数据库 checkpoint / flush 期间延迟尖刺。
5.2 容器场景下 I/O 的特殊问题
容器部署时,磁盘性能经常被这几种方式拖慢:
- 大量写容器层
- 日志直接打到 json-file 驱动,文件暴涨
- overlay2 处理小文件读写时有额外开销
- 把数据库直接放在低性能云盘或共享盘上
原则上:
- 高频持久化数据优先使用 volume / bind mount
- 日志要有 轮转
- 数据库不要把关键 I/O 绑在慢盘或混合盘上
5.3 磁盘排查重点
常见命令:
iostat -x 1
iotop
df -h
du -sh /var/lib/docker
docker system df
重点看:
awaitsvctm%util- 磁盘队列长度
- Docker 目录是否膨胀
业务经验:
- 很多“接口变慢”最终不是代码问题,而是日志刷盘把 I/O 打满。
- 如果
iowait明显上升,优先看磁盘,不要急着怀疑 CPU。
六、网络与带宽:不只是“网慢”这么简单
6.1 网络性能包含哪些维度
网络问题至少分成四类:
| 维度 | 含义 | 常见影响 |
|---|---|---|
| 带宽 | 每秒能传多少数据 | 大文件下载、镜像分发、视频流 |
| 延迟 | 单次往返耗时 | API 调用、数据库跨机访问 |
| 抖动 | 延迟是否稳定 | 实时系统、交易系统、语音视频 |
| 丢包 | 数据包是否丢失 | 重传、超时、连接不稳定 |
所以“带宽没满”不代表网络没有问题。
6.2 容器网络的常见影响因素
Docker 网络常见模式包括:
- bridge
- host
- overlay
- macvlan
其中最常见的性能影响点是:
- NAT 转发开销;
- iptables 规则过多;
- 容器 DNS 解析慢;
- 跨主机 overlay 网络抖动;
- 上游服务连接数过高导致 backlog 堵塞。
6.3 网络排查重点
常见命令:
ss -s
ss -lntp
sar -n DEV 1
iftop
curl -w '%{time_namelookup} %{time_connect} %{time_starttransfer} %{time_total}\n'
经验总结:
- 如果 TTFB 高、DNS / connect 时间低,问题大概率在应用或上游。
- 如果 connect 时间高,优先查网络链路、防火墙、连接队列。
- 高频短连接服务要重点看
TIME_WAIT和端口耗尽。
七、连接数、文件描述符与端口资源
7.1 为什么连接数会成为瓶颈
一个服务再轻量,只要连接处理不过来,也会变慢甚至拒绝请求。
常见瓶颈点包括:
- 监听队列满;
ulimit -n太小;- 数据库连接池打满;
- Nginx
worker_connections太小; - Redis / MySQL 最大连接数太低;
- 短连接太多导致临时端口耗尽。
7.2 容器部署时常见限制项
| 限制项 | 宿主机层 | 容器层 | 影响 |
|---|---|---|---|
| 文件描述符 | ulimit -n | 容器继承或单独设置 | 连接、文件、socket 打不开 |
| backlog | somaxconn | 应用监听参数 | 高并发接入阶段丢连接 |
| 端口范围 | ip_local_port_range | 宿主机统一生效 | 短连接压测时端口耗尽 |
| 连接池大小 | 应用配置 | 应用配置 | 上游打满后请求排队 |
7.3 连接类问题排查重点
重点观察:
- ESTABLISHED 数量
- TIME_WAIT 数量
- CLOSE_WAIT 数量
- accept backlog
- 各类连接池等待时间
常用命令:
ulimit -n
ss -tan | head
ss -tan state time-wait | wc -l
cat /proc/sys/net/core/somaxconn
cat /proc/sys/net/ipv4/ip_local_port_range
八、Docker 部署对性能的实际影响
8.1 Docker 不是性能问题的唯一来源
Docker 本身确实有少量额外开销,但在绝大多数业务系统里,真正的瓶颈通常不是容器化本身,而是:
- 资源配额不合理;
- 存储方式不合理;
- 网络模式不合理;
- 应用配置不合理;
- 依赖组件慢。
8.2 Docker 真正会影响性能的地方
Docker 更真实的影响点在这里:
8.3 容器性能调优的核心思路
容器调优并不是“把限制放大”这么简单,而是:
- 给到合理但不过量的 CPU / memory limit;
- 让应用参数感知容器资源;
- 高频写入走 volume;
- 网络路径尽量简单;
- 日志、连接、线程池、缓存一起调。
九、应用层因素:线程池、连接池、缓存、队列长度
9.1 为什么资源够用服务还是慢
线上经常会出现这种情况:
- CPU 不高;
- 内存没满;
- 磁盘也正常;
- 但接口就是慢。
这类问题通常在应用层。
9.2 应用层常见性能瓶颈
| 模块 | 问题 | 现象 |
|---|---|---|
| 线程池 | 太小或拒绝策略不合理 | 请求排队、超时 |
| 数据库连接池 | 池太小或连接泄漏 | 获取连接慢 |
| 缓存 | 命中率低 | 数据库压力升高 |
| 队列 | 消费速度跟不上 | 延迟持续累积 |
| GC | Full GC 频繁 | 服务抖动 |
| 锁竞争 | 热点锁 / 大对象同步 | 单接口慢 |
结论很重要:
系统资源只是上限,应用参数决定你能不能把这部分资源用好。
十、性能排查的推荐顺序
10.1 先看现象,再定层级
不要一上来就 SSH 上去看 top,应该先问:
- 是全部接口慢,还是某几个接口慢?
- 是全天慢,还是高峰期慢?
- 是单实例慢,还是所有实例都慢?
- 是用户访问慢,还是内部调用也慢?
10.2 一套适合线上故障的排查流程
这套顺序的核心价值:
- 避免被单个监控指标误导;
- 先缩小层级,再深入细查;
- 能更快判断问题是在应用、容器、宿主机还是依赖。
十一、常见部署场景的性能重点
11.1 Nginx / 网关类服务
重点关注:
worker_processesworker_connections- keepalive
- backlog
- access log 写盘
- 上游连接复用
11.2 Java / Spring Boot 服务
重点关注:
- JVM 堆与容器 limit 的关系
- GC 停顿
- Tomcat / Undertow 线程池
- 数据库连接池
- DirectBuffer / 堆外内存
11.3 Python / Node.js Web 服务
重点关注:
- 单进程还是多 worker
- GIL 或事件循环阻塞
- 协程调度
- 大 JSON 序列化
- 日志与同步 I/O
11.4 MySQL / PostgreSQL / Redis
重点关注:
- 磁盘 I/O
- buffer / page cache 命中率
- 慢查询
- checkpoint / flush
- 最大连接数
十二、监控指标应该怎么建
12.1 主机层指标
- CPU 使用率
- load average
- 内存使用率
- swap
- 磁盘使用率
- 磁盘
await/%util - 网卡吞吐
- 网络错误包
12.2 容器层指标
- 容器 CPU
- 容器内存 RSS / cache
- 容器重启次数
- OOM 次数
- 容器网络收发
- 容器文件系统写入量
12.3 应用层指标
- QPS
- P95 / P99 延迟
- 错误率
- 线程池队列长度
- 连接池等待时间
- 缓存命中率
- GC 时间
- 慢 SQL 数量
推荐认知:
主机层看“底座”,容器层看“隔离”,应用层看“用户真实感知”。
三层指标缺一不可。
十三、业务与工作中的经验总结
在真实工作里,服务性能问题经常有这几个规律:
- 最先被怀疑的地方,往往不是根因
- 高峰期问题通常和队列、连接池、缓存命中率更相关
- 容器限制不合理,比“Docker 开销”更常见
- 日志、监控、链路追踪本身配置不当,也会反过来拖慢服务
- 数据库与外部 API 是最常见的隐藏瓶颈
尤其在交易、量化、实时数仓类业务中,还要额外注意:
- 延迟抖动比平均延迟更危险;
- 高峰期尾延迟会直接影响业务体验;
- “资源够不够”必须结合峰值,不是只看日常均值。
十四、常见误区
| 误区 | 为什么不对 |
|---|---|
| CPU 不高就说明服务没问题 | 可能是 I/O、锁、连接池、上游慢 |
| 容器性能差就是 Docker 的锅 | 更多时候是 limit、存储、网络、应用参数问题 |
| 内存没打满就不需要关注 | page cache 被挤掉、swap、GC 抖动都会先发生 |
| 带宽够用就说明网络没问题 | 连接延迟、丢包、DNS、NAT 一样会拖慢 |
| 监控都绿就说明用户没问题 | 监控可能只看平均值,用户感知的是尾延迟 |
十五、面试题与标准回答
15.1 基础理解类
1. 问:影响服务器上一个 Docker 服务性能的核心因素有哪些?
答:
影响一个 Docker 服务性能的因素,可以分成 宿主机资源、容器资源限制、应用自身实现、依赖组件性能 四层。宿主机层主要包括 CPU、内存、磁盘 I/O、网络带宽与延迟;容器层主要包括 CPU quota、memory limit、文件描述符限制、容器网络模式、overlay2 存储开销;应用层主要是 线程池、连接池、缓存命中率、GC、锁竞争;依赖层主要是 数据库、Redis、MQ、外部 API。线上排查时不能只盯某一个指标,而要沿着请求链路找真正的瓶颈点。
15.2 排查实战类
2. 问:如果用户反馈接口变慢,你会怎么排查?
答:
我会先确认问题范围,是单接口慢、全部接口慢,还是高峰期慢。然后按层排查:先看 应用指标,如 P95、错误率、线程池、连接池、GC;再看 容器指标,确认 CPU、内存、重启、OOM 是否异常;然后看 宿主机指标,包括 CPU、load、I/O、网络、文件描述符;最后看 依赖组件,如数据库慢查询、Redis 阻塞、外部 API 超时。我的原则是先缩小问题层级,再针对性深入,而不是一上来就只看 top。
15.3 容器部署类
3. 问:Docker 会不会明显影响服务性能?
答:
通常不会有决定性影响。Docker 带来的额外开销大多出现在 容器网络转发、overlay2 存储、小文件写入、日志驱动 这些地方,而不是“所有服务都天然变慢”。在实际生产环境里,更常见的问题不是 Docker 本身,而是 容器 limit 配置不合理、应用没有感知 cgroup、日志打满磁盘、连接数与线程池配置失衡。所以 Docker 是性能链路中的一个因素,但很少是唯一根因。
十六、总结
如果把这篇文档压缩成一句话,那就是:
一个部署在 Docker 中的服务,性能好不好,不取决于某一个指标,而取决于宿主机资源、容器限制、应用配置和依赖链路能否共同支撑峰值流量。
真正实用的排查方法也不是背参数,而是建立顺序:
- 先看现象;
- 再分层定位;
- 最后针对资源、容器、应用、依赖分别优化。
只要把这条思路建立起来,不管是排查 Web 服务、网关、Java 应用、Python 服务,还是数据库容器,都会更快找到真正的瓶颈。